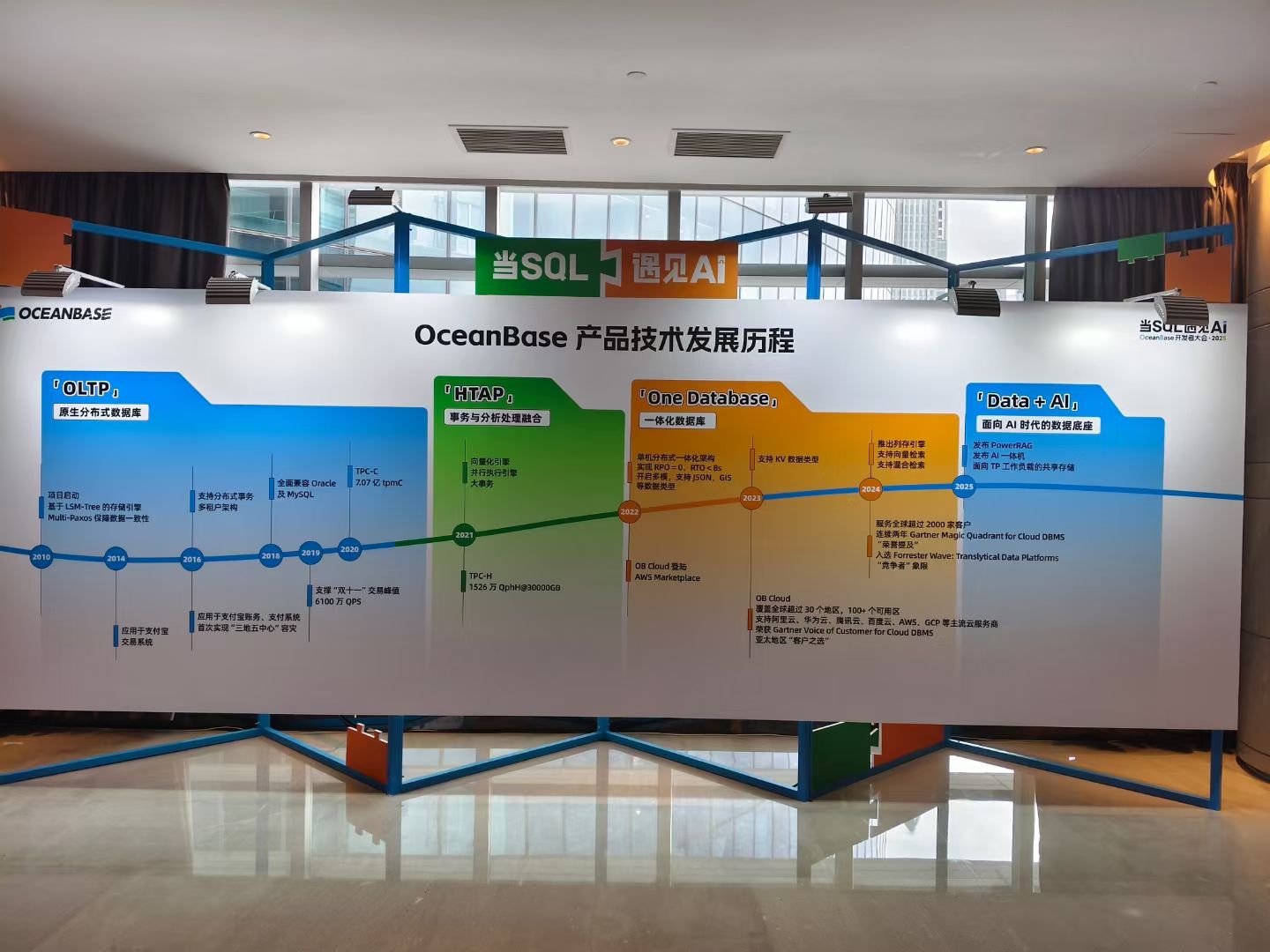
OceanBase 共享存储:云原生数据库的存储
目录
探会——第三届 OceanBase 开发者大会
重磅发布:OceanBase 4.3
开发者生态全面升级
实战演讲:用户案例与行业落地
OceanBase 共享存储架构解析
什么是共享存储架构?
云原生数据库的架构
性能、弹性与多云的统一
为何OceanBase能征服OLTP生产级挑战?
环境准备与基础配置
核心功能配置与优化
典型场景应用指南
运维与监控
OceanBase 共享存储使用步骤
ASCII字符示意图
整体布局(分层结构)
探会——第三届 OceanBase 开发者大会
2025年5月17日,第三届 OceanBase 开发者大会在广州州顺利举办。作为国内领先的原生分布式数据库解决方案提供者,OceanBase 本届大会以“数聚生态,智算未来”为主题,吸引了来自全国各地的数据库专家、开发者及生态合作伙伴齐聚一堂,共同探讨分布式数据库领域的最新技术演进与应用实践。
重磅发布:OceanBase 4.3
本次大会最受瞩目的焦点之一是 OceanBase 4.3 的正式发布。新版本在原有架构基础上实现了关键性能提升,支持更加复杂的多活部署场景,并大幅优化了存储引擎性能,进一步降低读写延迟。同时,在兼容性方面也向 Oracle、MySQL 更进一步,助力企业更加平滑地迁移和使用。
OceanBase 技术负责人表示,4.3 版本引入了更智能的资源调度机制与弹性算力架构,使得 OceanBase 在应对金融、政务等对一致性与高可用性有极高要求的场景中更为稳定与高效。
开发者生态全面升级
大会设置了多个技术专场,覆盖 数据库内核优化、SQL引擎调优、运维监控体系、多云部署实践 等议题。在“内核与架构专场”中,OceanBase 团队分享了有关 LSM Tree 引擎优化、写放大控制、分布式事务一致性协议等前沿技术。
此外,OceanBase 官方宣布了 开源社区生态激励计划升级,鼓励更多开发者参与到代码贡献、文档完善、插件开发中来。目前 OceanBase GitHub Star 数已突破 2 万,社区活跃度持续攀升,形成了更具凝聚力的开发者生态圈。
实战演讲:用户案例与行业落地
除了官方演讲等企业的技术专家也登台分享了 OceanBase 在各自业务中的落地经验。例如,在面对“双十一”亿级交易高并发场景时,OceanBase 通过弹性扩容和全局一致性保障,实现了毫秒级响应与零故障稳定运行,为电商业务保驾护航。
这些用户故事不仅验证了 OceanBase 的技术实力,也为其他企业提供了宝贵的参考范例。




第三届 OceanBase 开发者大会是一场技术与生态的双重盛会。从 4.3 版本的发布,到开源生态的深化,再到实践案例的展示,OceanBase 向业界展示了它作为国产数据库中坚力量的技术演进路径与未来愿景。
在“智算未来”的浪潮下,OceanBase 将继续深化分布式数据库底层能力的打磨,推动更多企业实现自主可控的数据基础设施建设,赋能数字中国的加速发展。
第三届 OceanBase 开发者大会,既是一场技术深耕的展示,也是一场生态共建的盛会。从 4.3 版本的功能跃迁,到 开源生态的全方位升级,再到 实际行业用户的成功落地案例,OceanBase 展现出其作为国产数据库中坚力量的技术进化路径与产业影响力。
站在“智算未来”的时代交汇点,OceanBase 将持续推进分布式数据库底层能力的打磨,深化计算与存储解耦、智能调度、跨云部署等核心能力,赋能企业实现 真正的云原生架构升级,并在自主可控的数字基础设施建设进程中发挥更大作用。
OceanBase 共享存储架构解析
什么是共享存储架构?
传统 OceanBase 采用的是“本地盘 + 多副本”的 Share-Nothing 架构:每个副本节点持有自己独立的存储和计算资源。虽然具备强一致性和高可用性,但也存在 数据复制开销大、写放大严重、资源利用率偏低 等问题。
OceanBase 共享存储架构引入了 计算与存储分离 的理念,多个计算节点可以访问同一个后端存储。其关键特征包括:多租户共享统一存储池,持久化数据只保存一份,副本间元数据分离,数据共享,支持即开即用,秒级弹性扩容。
这一转变实现了从 Share-Nothing 向 Share-Disk/Share-Storage 的跨越,尤其适用于资源紧张或高密度部署场景。
云原生数据库的架构
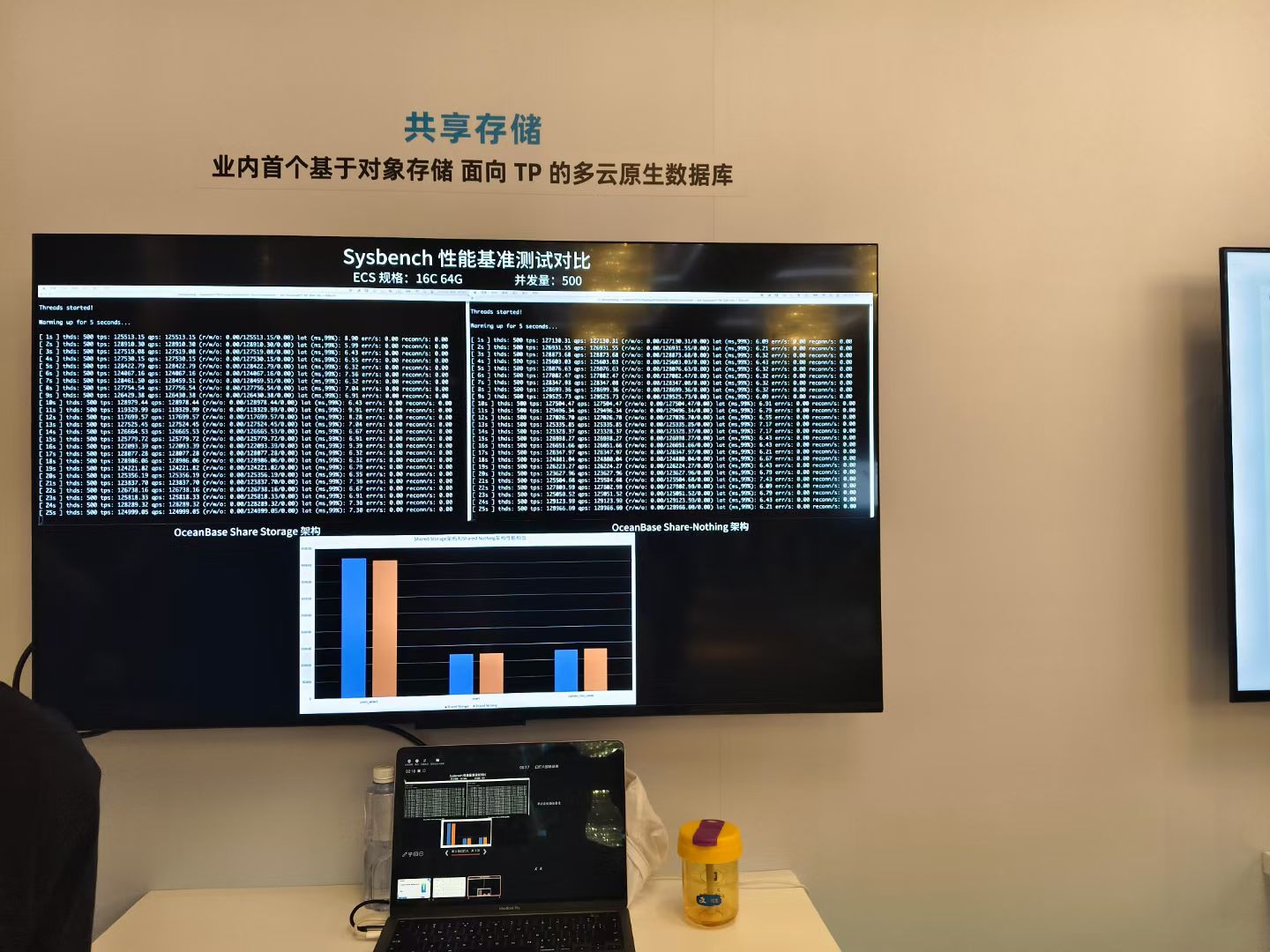
在云计算时代,对象存储凭借高可靠性、低成本、无限扩展的优势,已成为海量数据存储的核心方案,但其在事务型数据库(TP)领域的应用长期受限。传统TP数据库普遍采用Shared-Nothing架构,依赖本地磁盘或云盘保障低延迟与高并发性能,却也带来扩缩容低效、存储冗余度高、成本压力大等问题。
OceanBase作为原生分布式数据库的领军者,以存算解耦为核心突破,推出业内首个面向OLTP场景的共享存储产品。通过将计算层与存储层分离,OceanBase首次实现事务型数据库与对象存储(如Amazon S3、阿里云OSS等)的深度融合,在保持强一致性、毫秒级响应的同时,将TP场景的存储成本降低50%,AP场景成本甚至可降至原方案的1/10。
性能、弹性与多云的统一
极致性价比:性能无损,成本减半
通过“对象存储+多级缓存”架构,OceanBase将全量数据落地于低成本对象存储,仅需单副本即可保障跨可用区的高可用性;热数据通过本地SSD缓存实现快速访问,冷数据自动下沉至对象存储,存储成本直降50%。
Serverless弹性:计算与存储独立扩展
支持计算节点秒级扩缩容,存储层容量无限扩展。结合Spot实例技术,计算资源成本最高可降低70%,实现“存储不动、计算随需”的云原生体验。
多云原生:打破云厂商锁定
全面兼容Amazon S3、阿里云OSS等主流对象存储协议,覆盖阿里云、华为云、AWS等六大公有云平台,全球超100个可用区,为企业提供跨云、混合云的统一数据底座。
为何OceanBase能征服OLTP生产级挑战?
对象存储的高延迟与低IOPS特性曾是其适配OLTP场景的“死穴”,OceanBase通过四项核心技术实现破局:
多级缓存架构:
内存缓存:承载最热数据,保障毫秒级响应;
本地持久化缓存+分布式缓存:通过预读预热、节点间同步机制,弥补对象存储访问延迟;
对象存储:作为无限容量的冷数据底座。
自研LSM-Tree引擎:
针对对象存储“只追加、不修改”的特性,优化写入路径,聚合小I/O为顺序大块写入,降低写放大与存储压力,提升IOPS效率。
动态弹性缓存:
本地缓存空间随负载自动扩缩,智能识别热点数据,避免资源浪费,应对业务流量波动。
全链路优化:
从I/O调度、预取策略到跨可用区同步机制,全面压低延迟波动,确保TP业务稳定性。
环境准备与基础配置
云平台接入
OceanBase 共享存储已支持阿里云、华为云、腾讯云、百度云、AWS、Google Cloud 六大公有云平台,覆盖全球超 100 个可用区。用户需在目标云平台创建 OceanBase 实例,并绑定兼容 S3 协议的对象存储服务(如 Amazon S3、阿里云 OSS)作为持久化存储层。
存储与计算资源规划
存储层:将全量数据落地至对象存储,仅需单副本即可保障跨可用区高可用性。
计算层:按需分配计算节点,支持秒级弹性扩缩容,结合 Spot 实例可节省最高 70% 计算成本。
核心功能配置与优化
多级缓存架构设置
内存缓存:自动缓存最热数据(如近 30 天订单),保障毫秒级响应。
本地持久化缓存:将高频访问数据缓存在本地 SSD,通过预读预热机制减少对象存储访问延迟。
分布式缓存:支持节点间数据同步,确保容灾恢复能力。
冷热数据分层策略
自动识别冷热数据(如淘宝订单场景中,近 30 天为热数据,历史数据为冷数据),热数据缓存在本地,冷数据自动下沉至对象存储。
配置示例:通过 SQL 或管理控制台设置数据生命周期策略,例如按时间阈值(如 30 天)自动迁移冷数据。
LSM-Tree 引擎优化
写入优化:聚合小 I/O 为顺序大块写入,适配对象存储“只追加、不修改”特性,降低写放大。
异步落盘:通过后台任务处理 Compaction、备份等重 I/O 操作,减少对实时事务的影响。
典型场景应用指南
核心 TP 与历史库
场景示例:电商订单系统将全量数据存入对象存储,仅缓存近期热数据,存储成本降低 50%,历史数据查询仍保持秒级响应。
操作步骤:
创建历史表并设置冷热分离策略。
通过 OceanBase 控制台配置自动缓存规则,指定热数据保留周期。
时序数据(IoT/智能制造)
场景示例:智能设备监控数据写入频繁,短期查询为主,长期存储成本需优化。
配置方法:
启用自动冷热识别,将超过指定时间(如 7 天)的数据标记为冷数据。
结合分布式缓存提升写入吞吐量。
HBase 兼容与流水型业务
迁移方案:将 HBase 冷数据迁移至 OceanBase 共享存储,保留强一致性事务能力,存储成本降至原方案的 1/10。
流水型数据管理:
配置流水表按时间分区,自动归档旧分区至对象存储。
使用 Serverless 计算节点按需处理高频写入。
运维与监控
弹性伸缩管理
计算层:通过控制台或 API 动态调整计算节点数量,支持业务高峰期的资源弹性。
缓存层:启用持久化缓存弹性伸缩功能,本地缓存空间随负载自动扩缩。
全链路监控
通过 OceanBase 内置监控工具,实时跟踪对象存储访问延迟、缓存命中率及 I/O 压力。
设置告警阈值(如延迟超过 10ms),及时
优化缓存策略或调整资源分配。
OceanBase 共享存储使用步骤
1、环境准备
支持平台:阿里云、AWS、华为云等(需开通对象存储服务,如 OSS/S3)
操作:获取对象存储的 Access Key 和 Bucket 名称
在 OceanBase 控制台创建 共享存储卷,绑定对象存储地址
2、 创建数据库与表
示例:电商订单表(自动冷热分离)
-- 创建数据库
CREATE DATABASE orders_db STORAGE_POLICY = 'HOT_COLD'; -- 启用冷热分层策略-- 创建订单表(按时间分区)
CREATE TABLE orders (order_id BIGINT PRIMARY KEY,order_time DATETIME,data JSON
) PARTITION BY RANGE(order_time) (PARTITION p_hot VALUES LESS THAN (CURRENT_DATE - INTERVAL 30 DAY), -- 热数据分区PARTITION p_cold VALUES LESS THAN (MAXVALUE) -- 冷数据自动存对象存储
);3、冷热数据管理
自动策略:
数据写入时自动按分区规则分离(如超过30天的订单自动存对象存储)
手动迁移:
-- 将历史数据批量迁移至对象存储
ALTER TABLE orders MOVE PARTITION p_old TO STORAGE 'S3';4、弹性与监控
计算节点扩容:
# 从2节点扩展到4节点(10秒完成)
obd cluster scale-out ob_shared --servers=2查看存储状态:
-- 查看冷热数据分布
SELECT partition_name, storage_type, total_size
FROM information_schema.table_storage
WHERE table_name = 'orders';-- 监控缓存命中率
SHOW STATUS LIKE 'cache_hit_ratio%';5、注意
首次使用建议开启 自动缓存伸缩(SET GLOBAL auto_cache_scaling=ON;)
高频写入场景可调整 I/O块大小(SET GLOBAL s3_block_size='64MB';)
免费工具:OceanBase 冷热迁移助手
ASCII字符示意图
+-------------------+ +-------------------+
| 计算节点集群 | | 计算节点集群 |
| (无状态,弹性伸缩) | <--> | (秒级扩容/释放) |
+-------------------+ +-------------------+↓
+--------------------------------+
| 多级缓存层 |
| ---------------------------- |
| [内存缓存]🔥热数据(毫秒级) |
| [本地SSD]⚡高频访问数据 |
| [分布式缓存]🌐节点间同步 |
+--------------------------------+↓
+--------------------------------+
| 共享对象存储 |
| (S3/OSS,单副本跨AZ) |
| ▼ 存储成本降低50% |
+--------------------------------+整体布局(分层结构)
+------------------------------+
| 计算层 |
| [无状态节点集群] |
| - 支持秒级扩缩容 |
| - Spot实例节省70%成本 |
+--------------|---------------+↓
+------------------------------+
| 多级缓存层 |
| +---------+ +---------+ |
| | 内存缓存 | | 本地SSD | | ← 热数据(自动缓存)
| +---------+ +---------+ |
| +---------------------+ |
| | 分布式缓存集群 | | ← 跨节点同步
| +---------------------+ |
+--------------|---------------+↓
+------------------------------+
| 共享存储层 |
| [对象存储 S3/OSS] |
| - 单副本跨AZ高可用 |
| - 存储成本降低50% |
+------------------------------+