recurrent neural network(rnn)
slot filling,给一段话,把相关信息丢到对应slot里面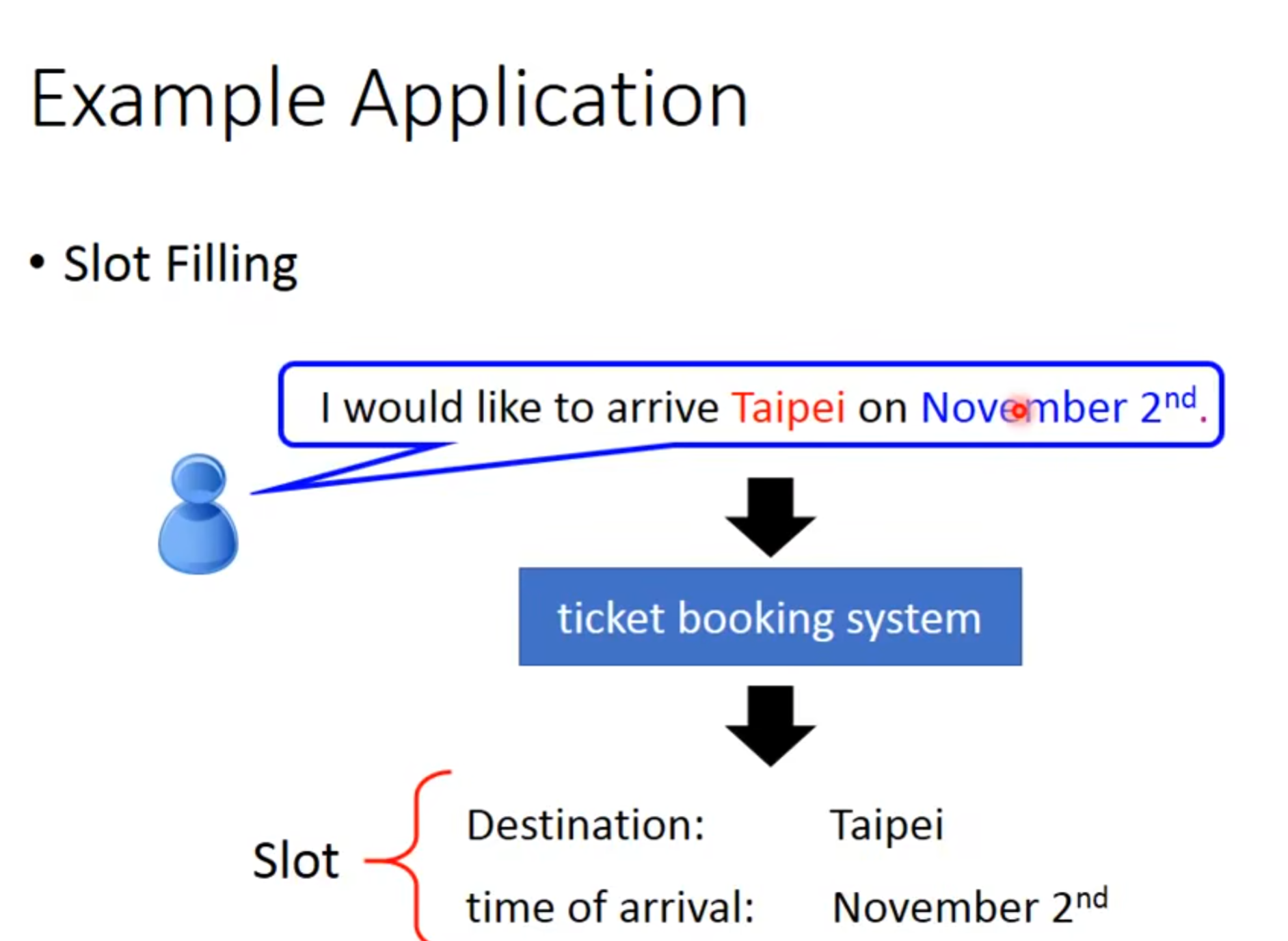
可以这样,用feedforward network来解决,输入时向量
输出就是可能被分到哪个slot里的概率
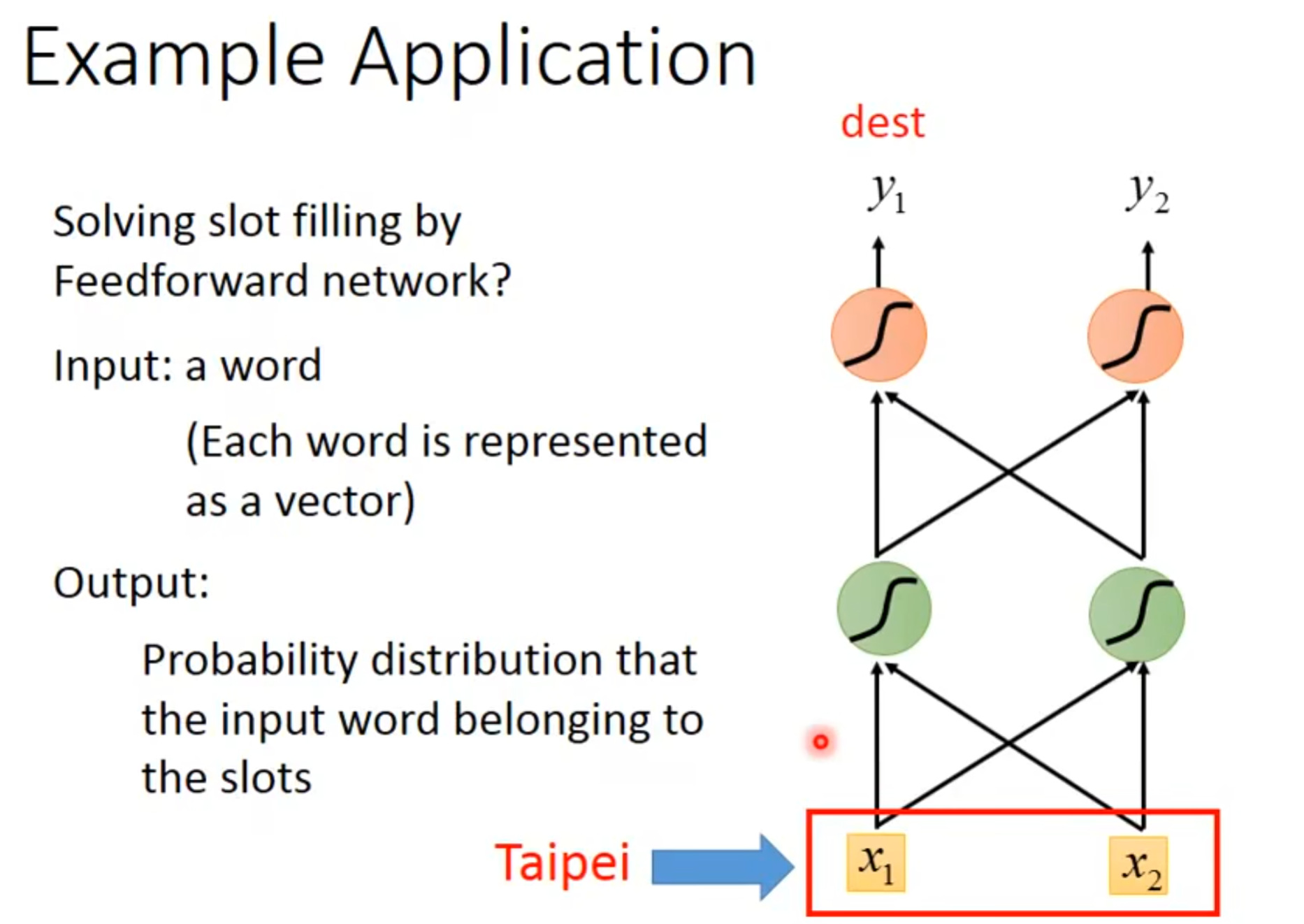
但这会有问题,因为同样的词汇,在不同上下文中可能会有不同含义,比如说,第一句话中,taipei被分到了目的地里,但是第二句话中.taipei其实是出发地,但是因为feedforward network没办法辨识出来,所以还是会被分到目的地中
这个时候,我们就想要我们的network具有记忆能力,可以联系上下文进行推理,这就引出了rnn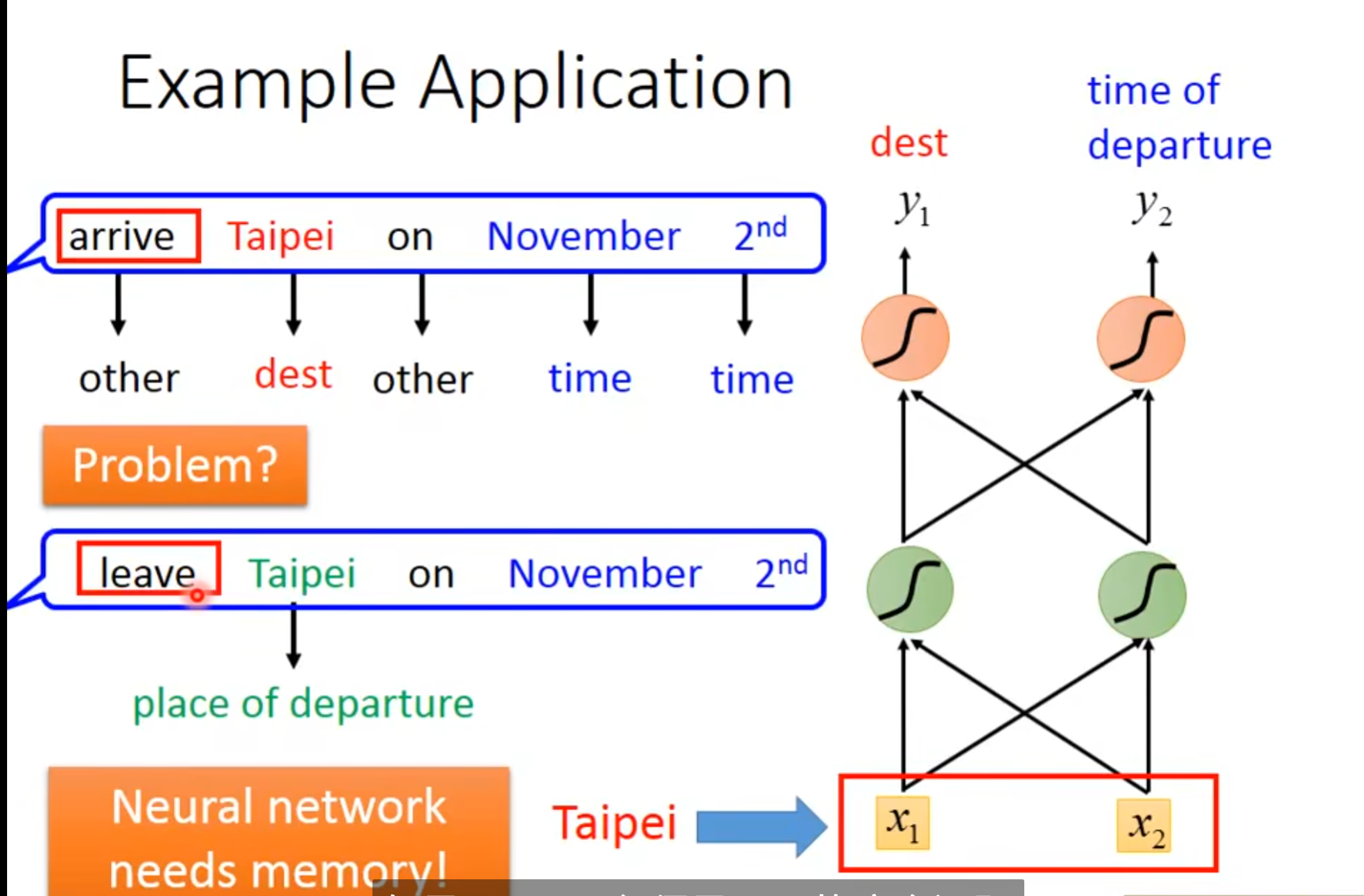
就像这样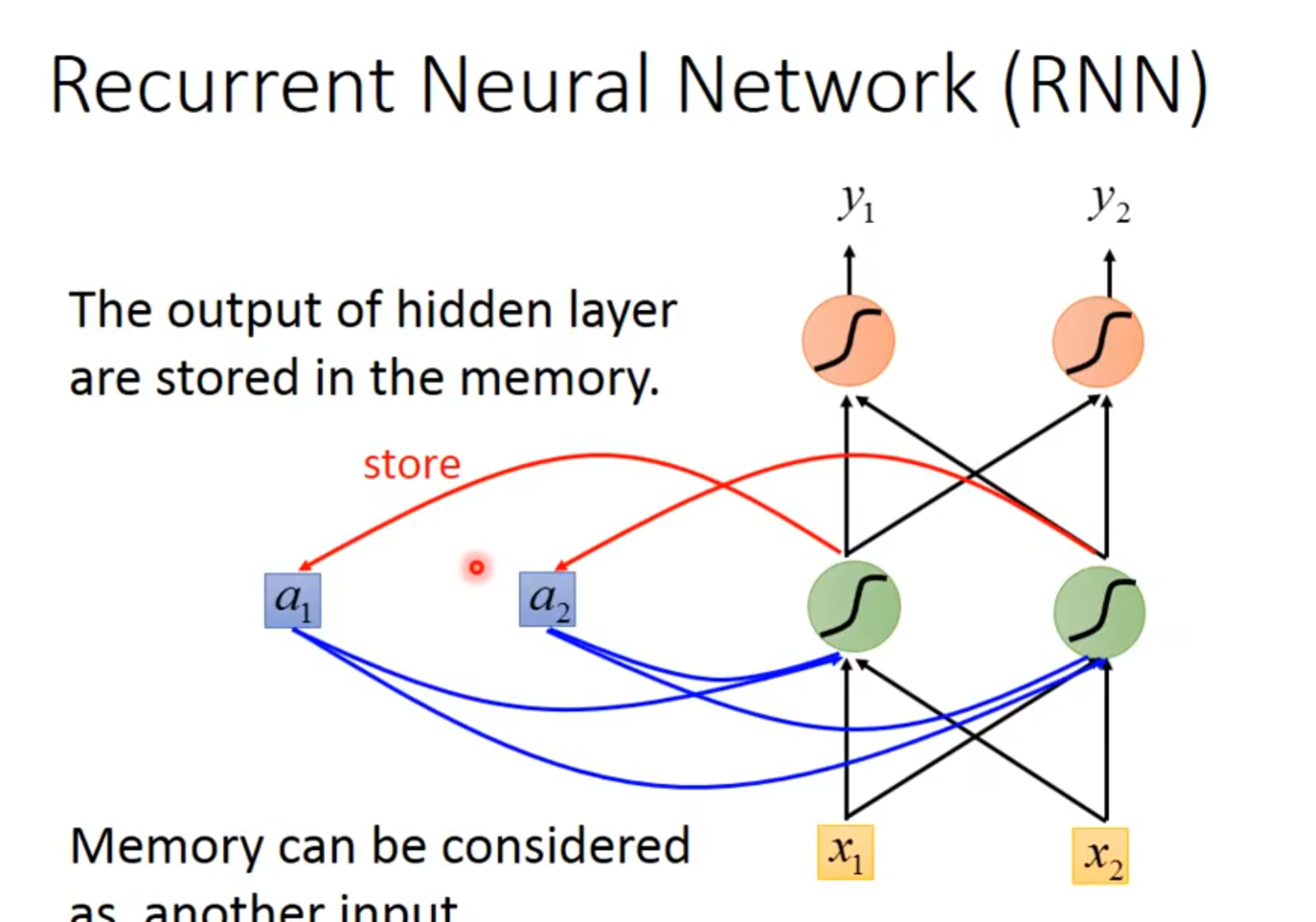
我们一开始要给内存设定一个值,假设是0,为了简化model,我们的激活函数就是简单的直线,w都设定为1,在rnn中,sequence的顺序是很重要的,改变了这个顺序,就会改变输出,即使只是改变顺序,没有改变值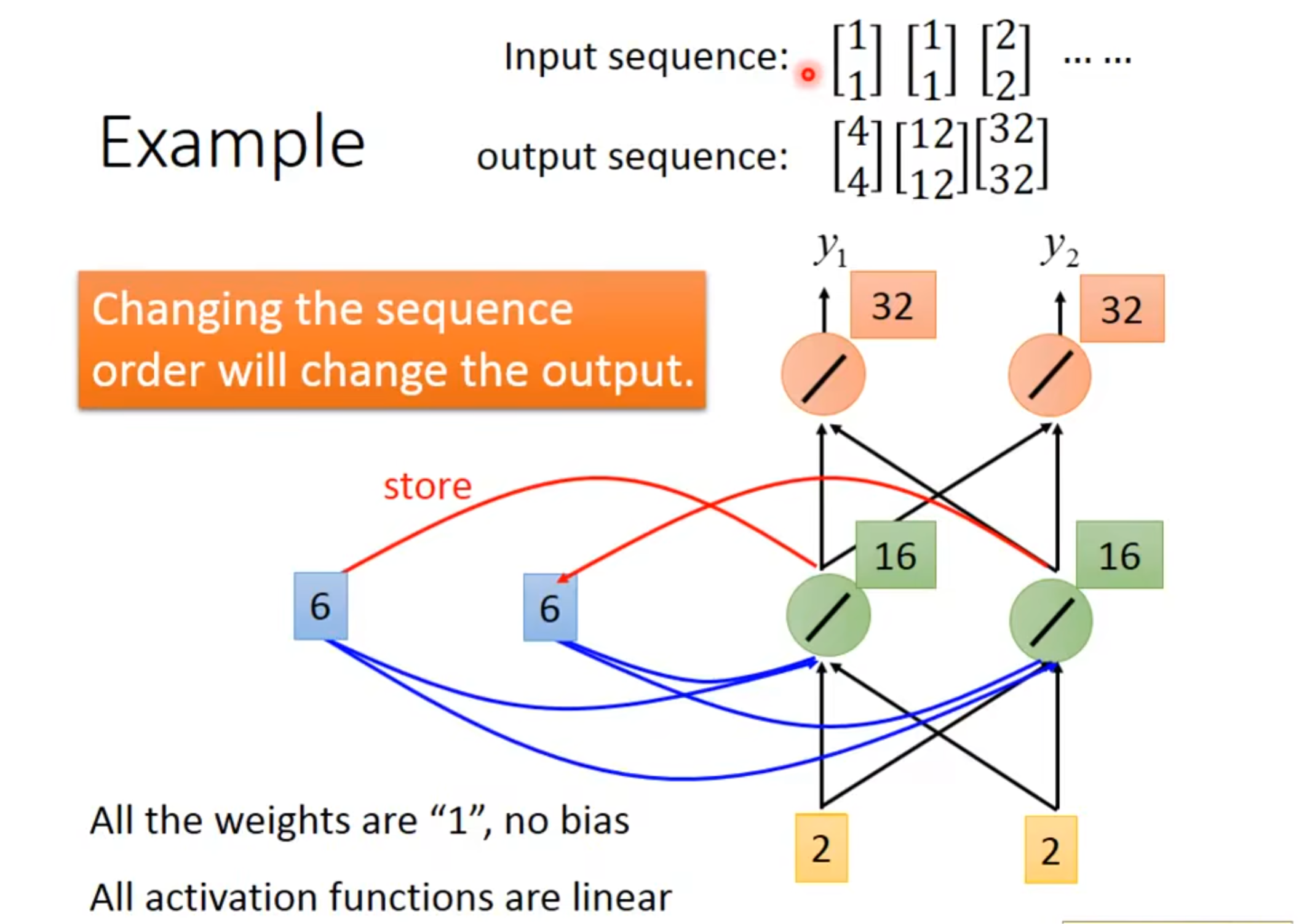
直观点的流程图是这样的,看起来是三个model,实际上只有1个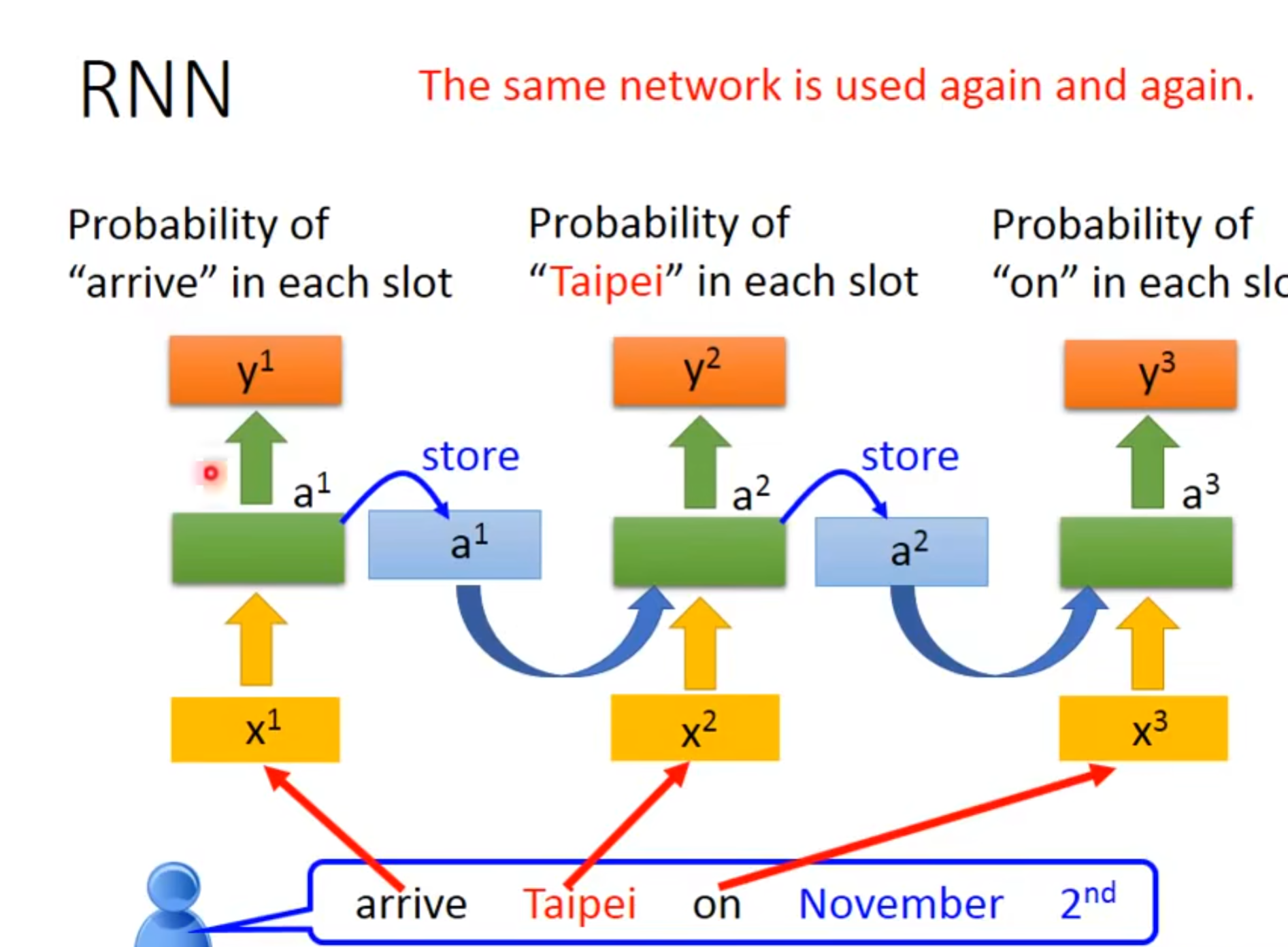
以上就是elman network(把hidden layer的output当作输入),还有一个叫做Jordan network(把最终的output当作输入,通常表现地更好)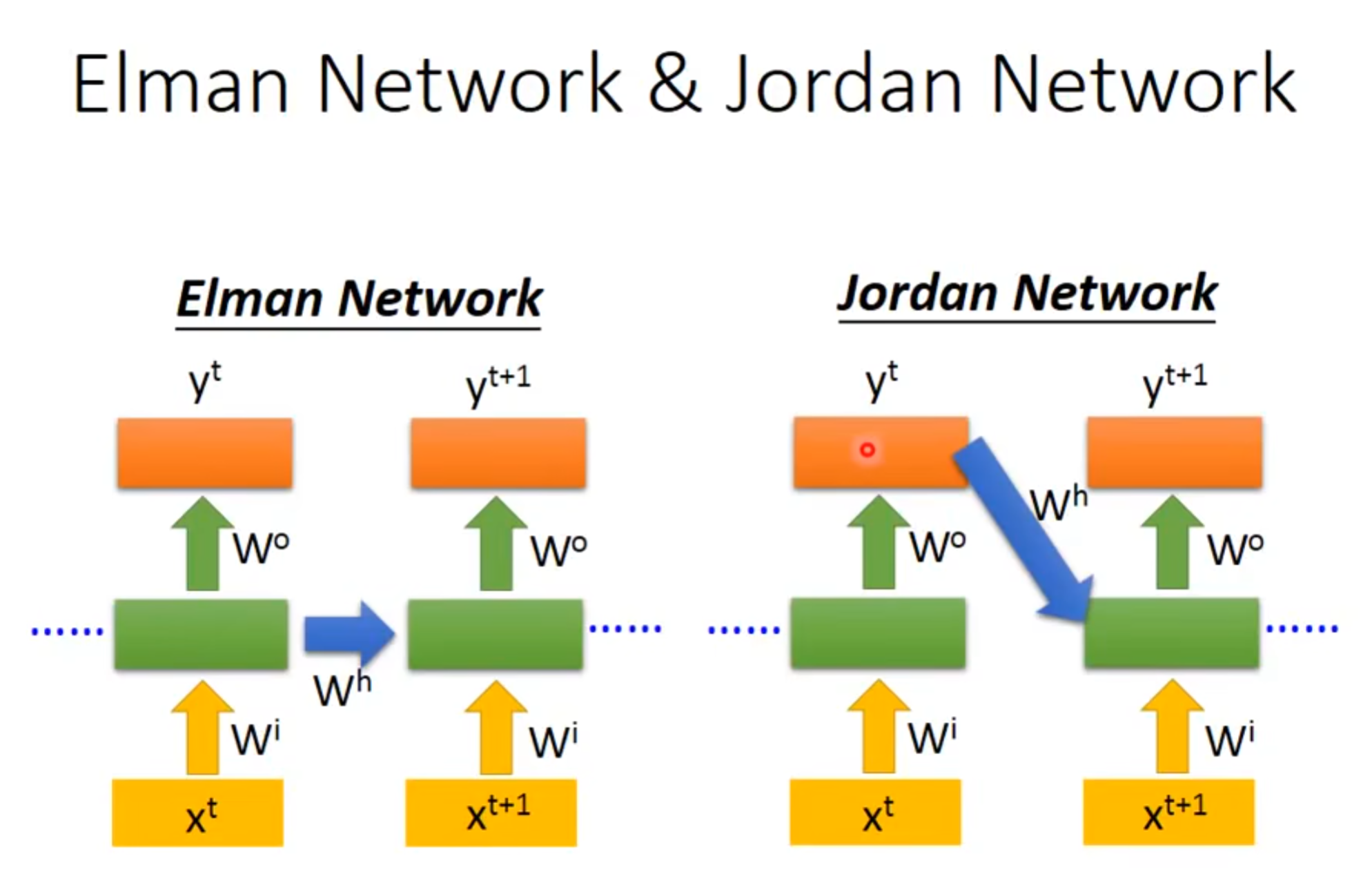
rnn是有双向地,就是bidirectional rnn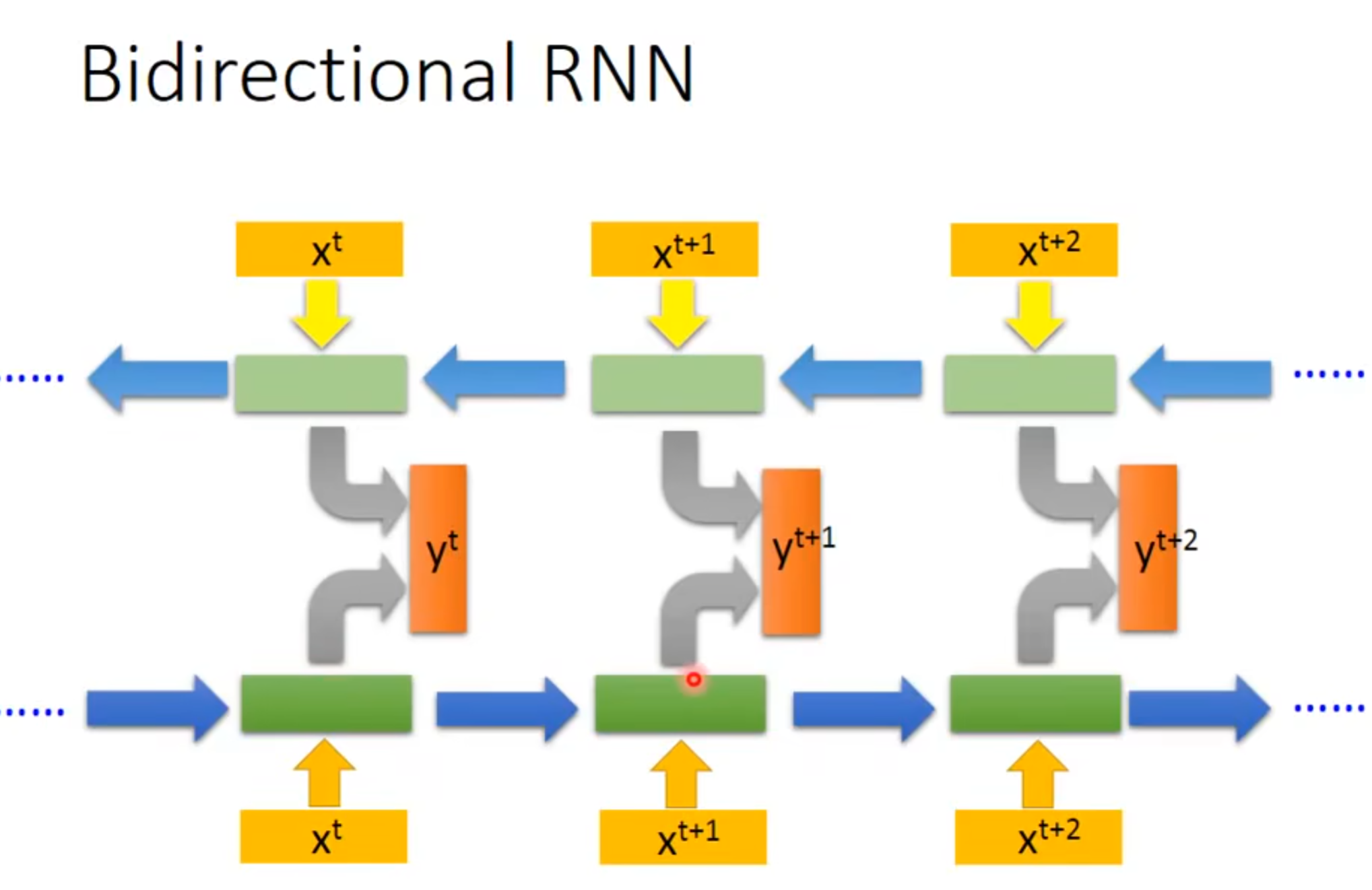
以上就是最简单地rnn版本
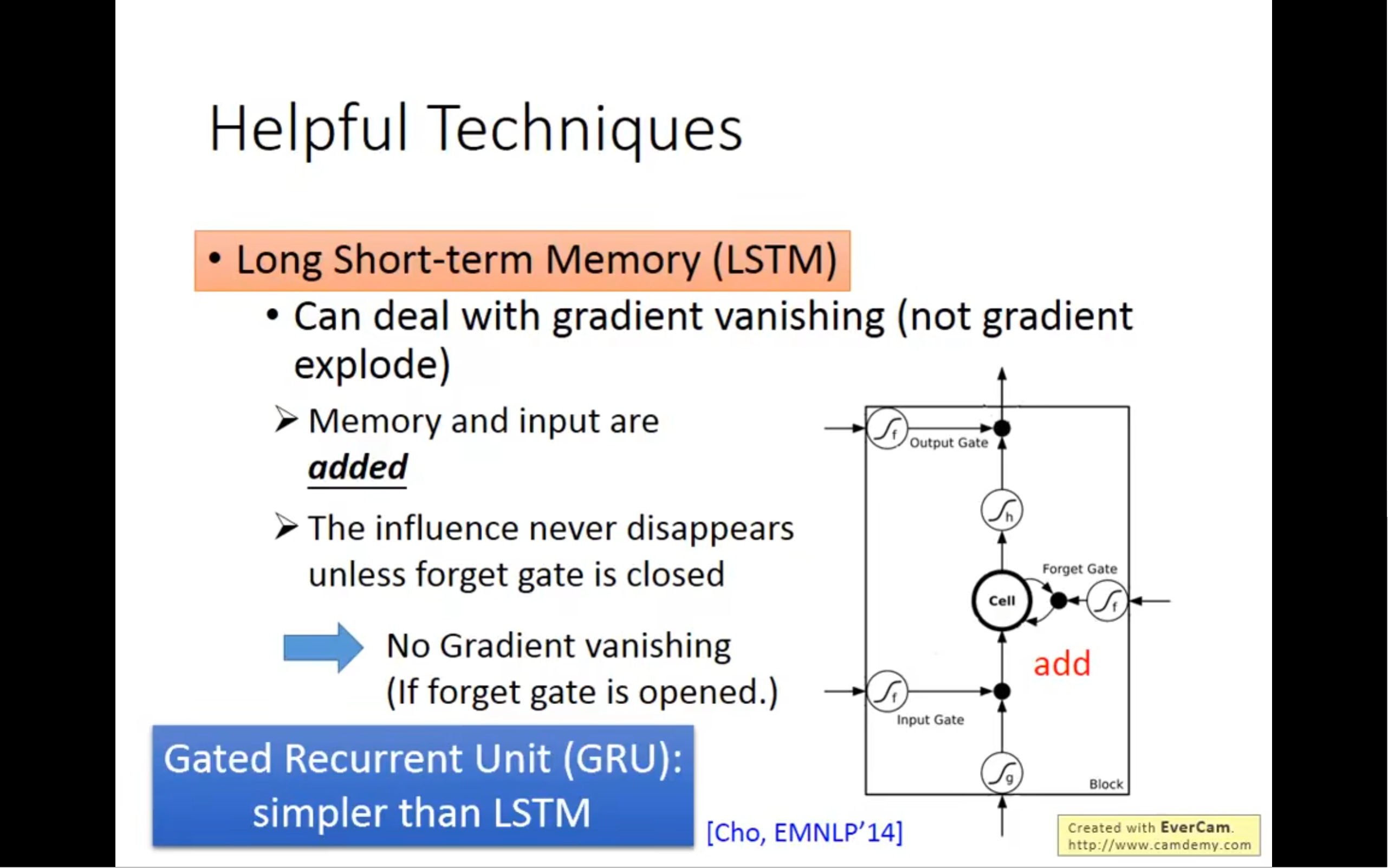
接下来是long short-term memory(lstm),它对memory cell做出了改变,不是什么时候都能存入值,也不是什么时候都能输出值,也添加了忘记机制,当然,这些需要控制的东西,也不是我们来控制,而是机器从数据中学习出来去控制,这个cell有四个输入,一个输出,四个输入分别是neuron地输出,控制input gate地信号,控制output gate地信号,和控制forget gate地信号

接下来是例子,x2表示这个input gate(1是写入,0是不写入,-1的时候是memory 的reset),x3是输出的gate
假设我们的model是简单model,每一个gate看起来是这样实现的,其中绿色的方块代表着bias,然后第二个黄色方块的weight是100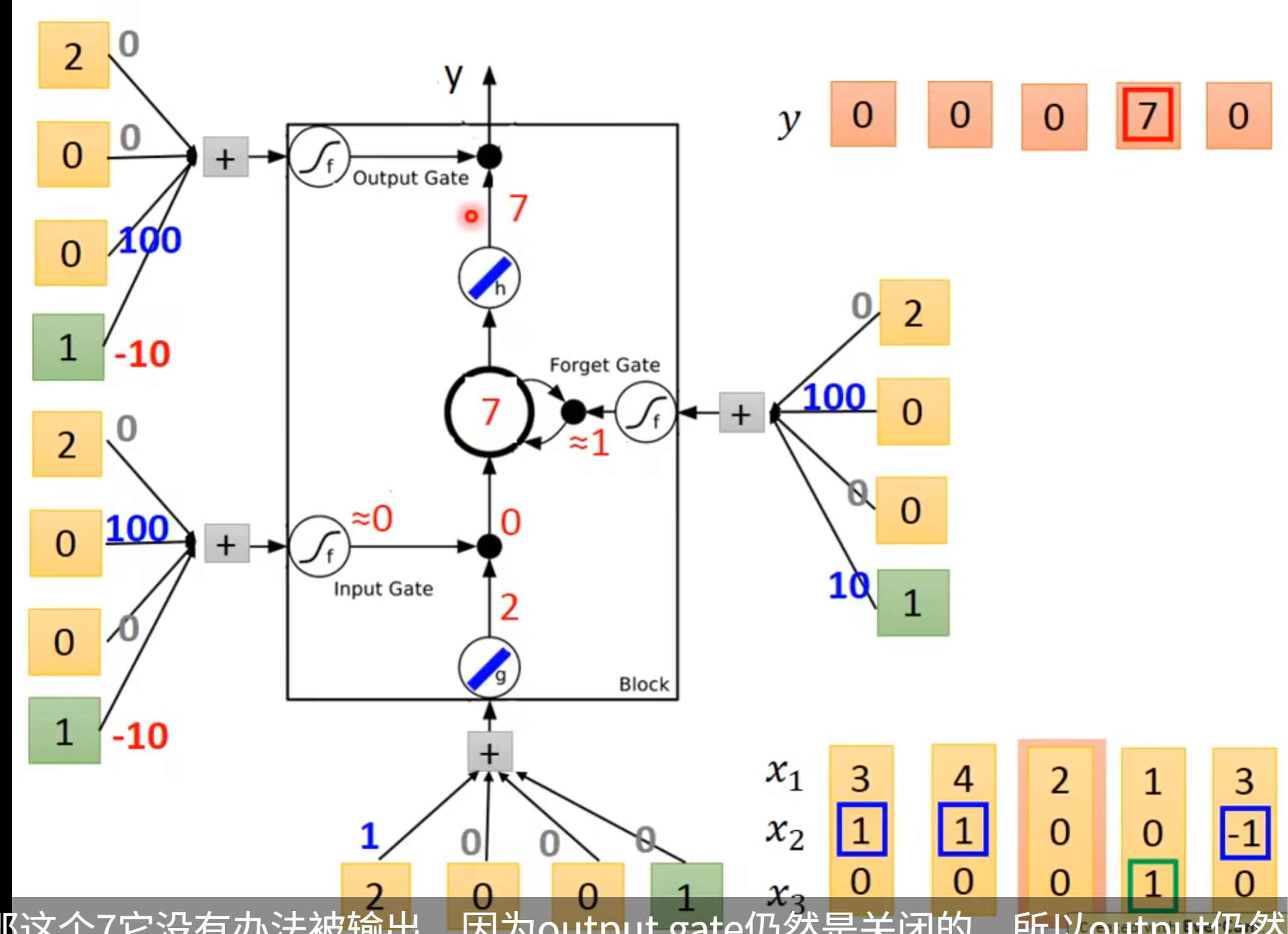
memory cell其实可以当作一个neuron来输入输出
每个gate的输入都是这个neuron的输入乘上不同weight
参数量是一般neuron的四倍
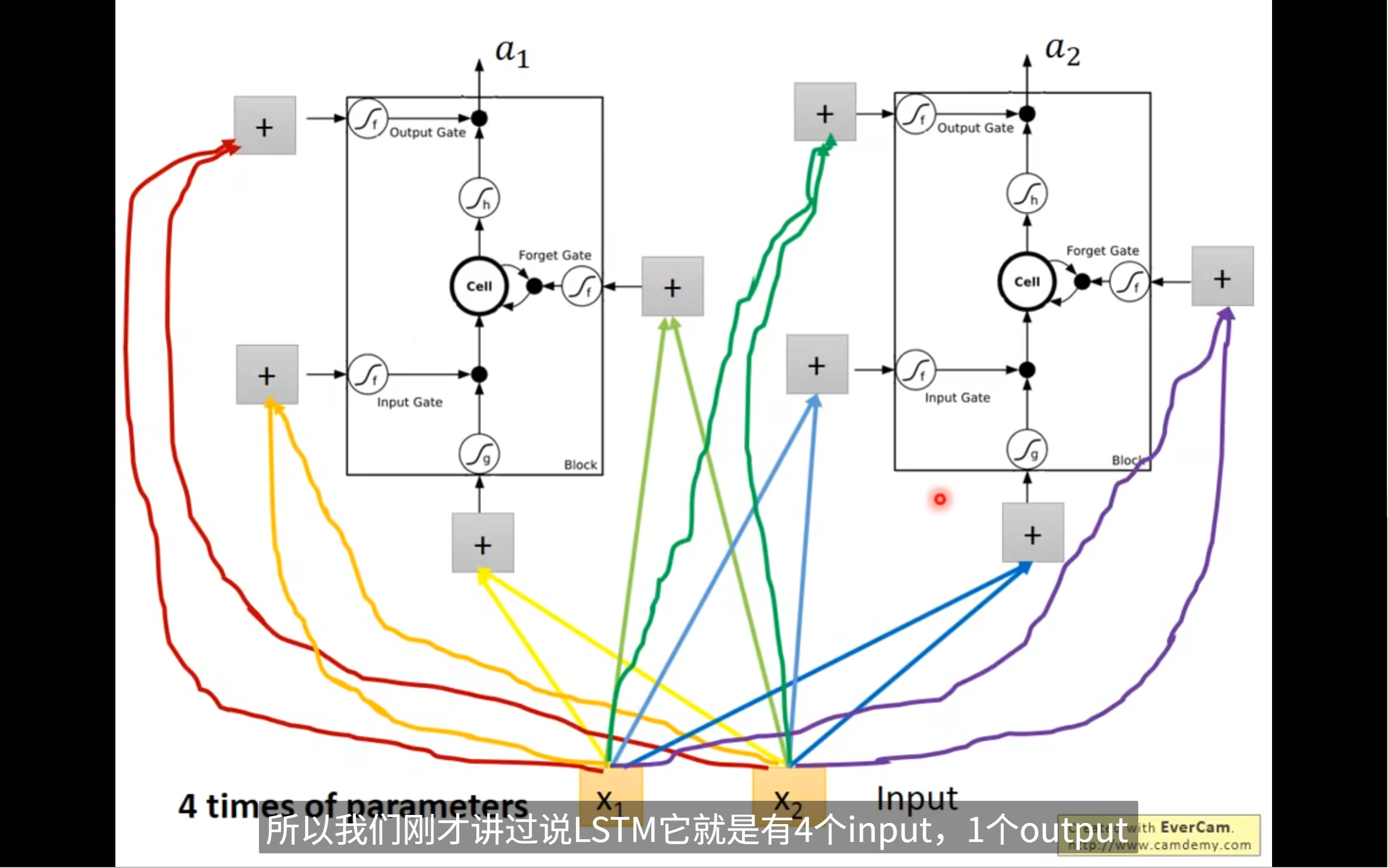
自然而然,我们知道可以用matrix/vector来表示,当然,每一次输入的只是matrix中的一个dimension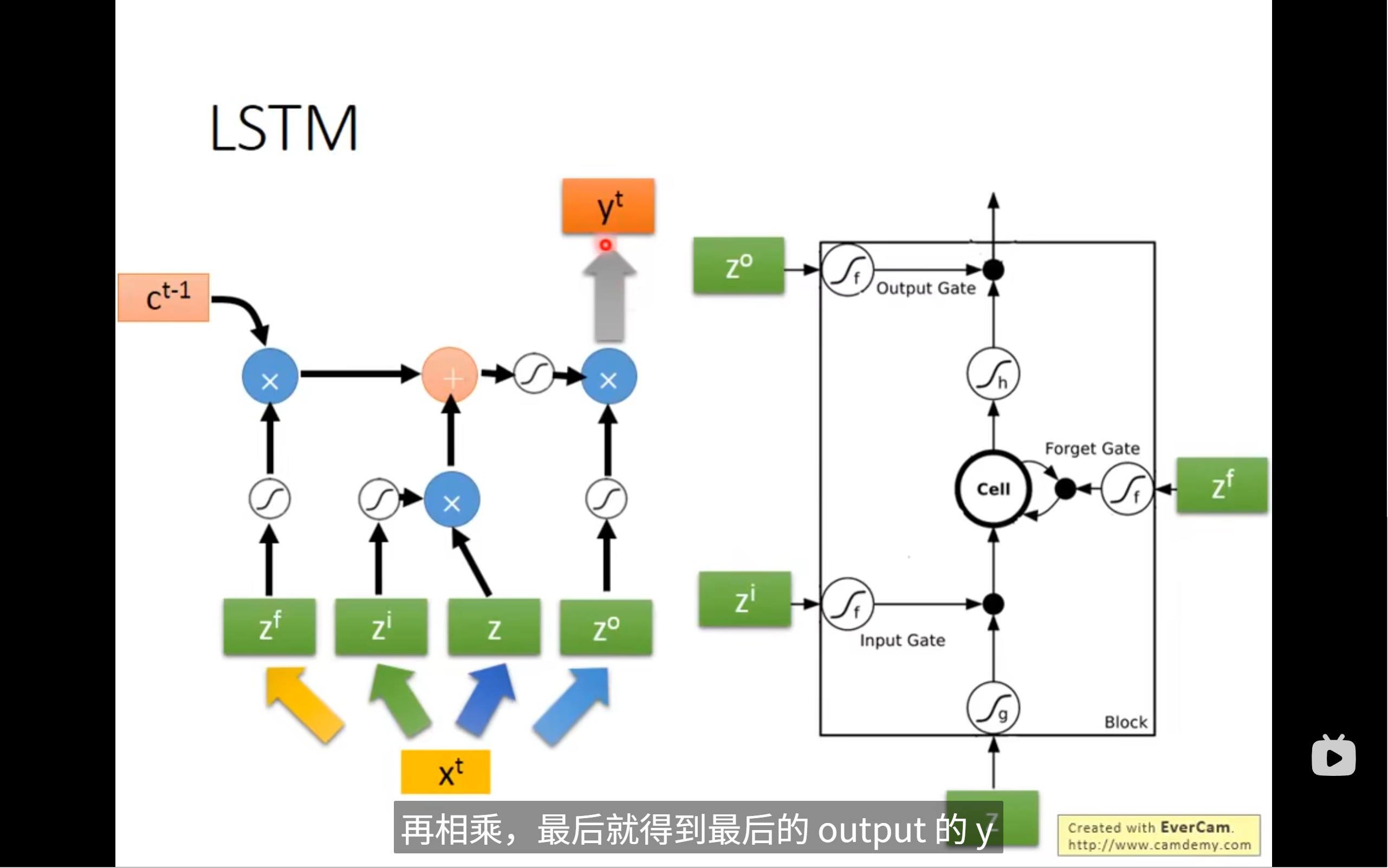
其实以上的都还是简化版的lstm,真正的lstm是下面这样,你可以看到这个memory cell的输入多了几个,有上一个neuron的输出,上一个memory的值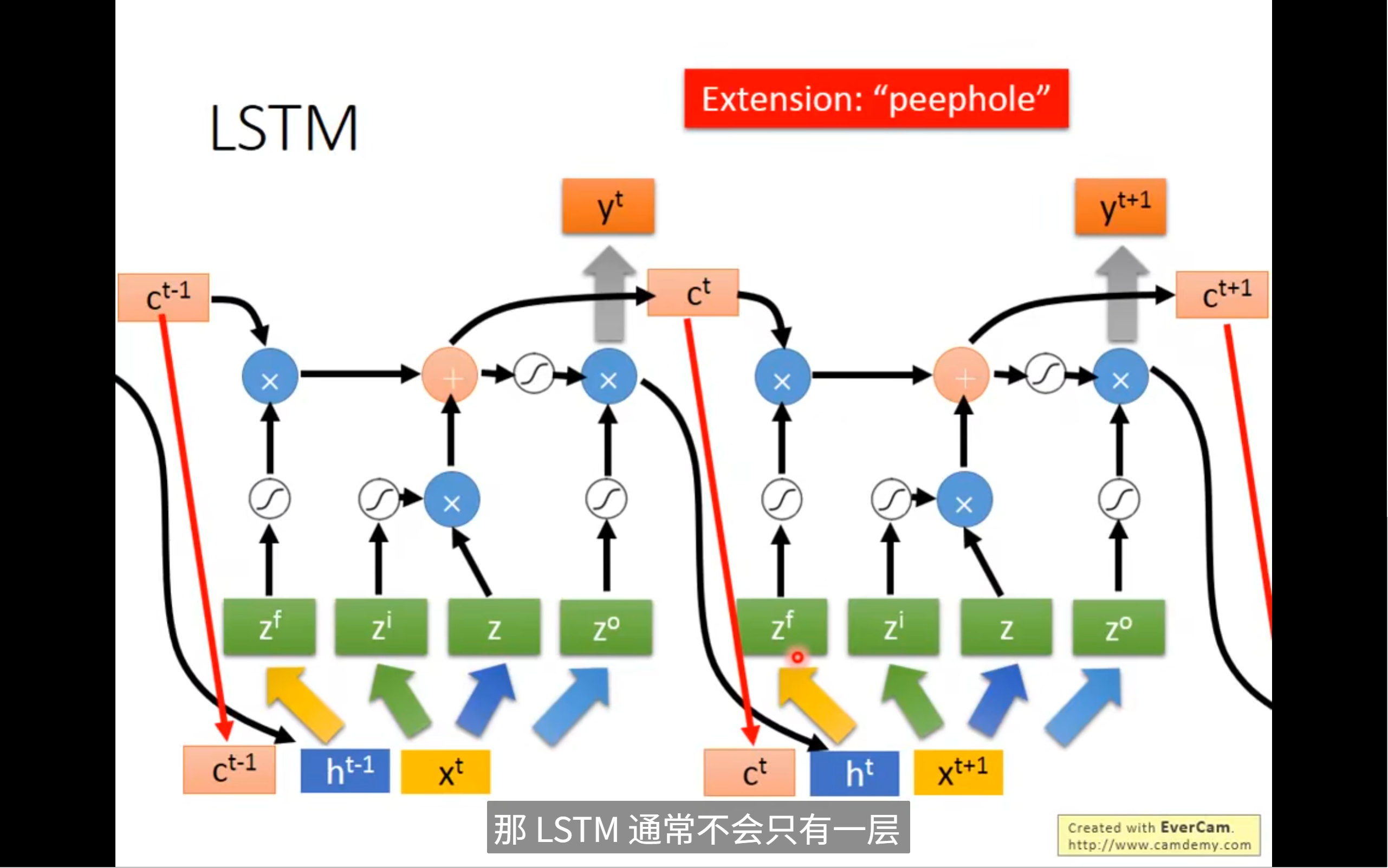
而且,现在一般叠lstm都是不止一层的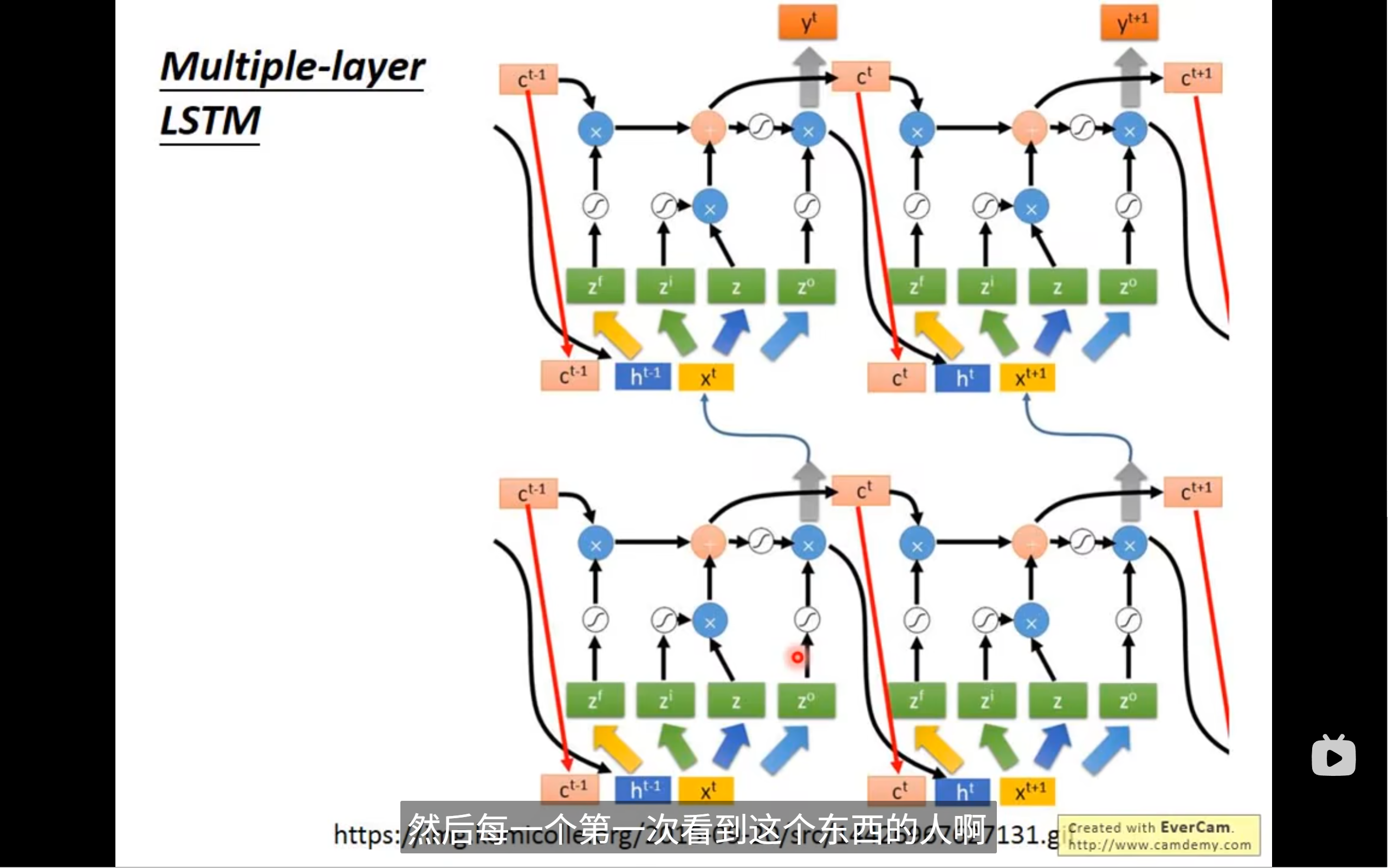
那我们具体怎么用这个rnn(lstm)呢,又回到slot filling中,我们输入sequence,然后把第一个单词作为输入,通过rnn得到输出,这个输入呢,会根据reference vector,找到自己的slot,这个vector的长度就是slot的数量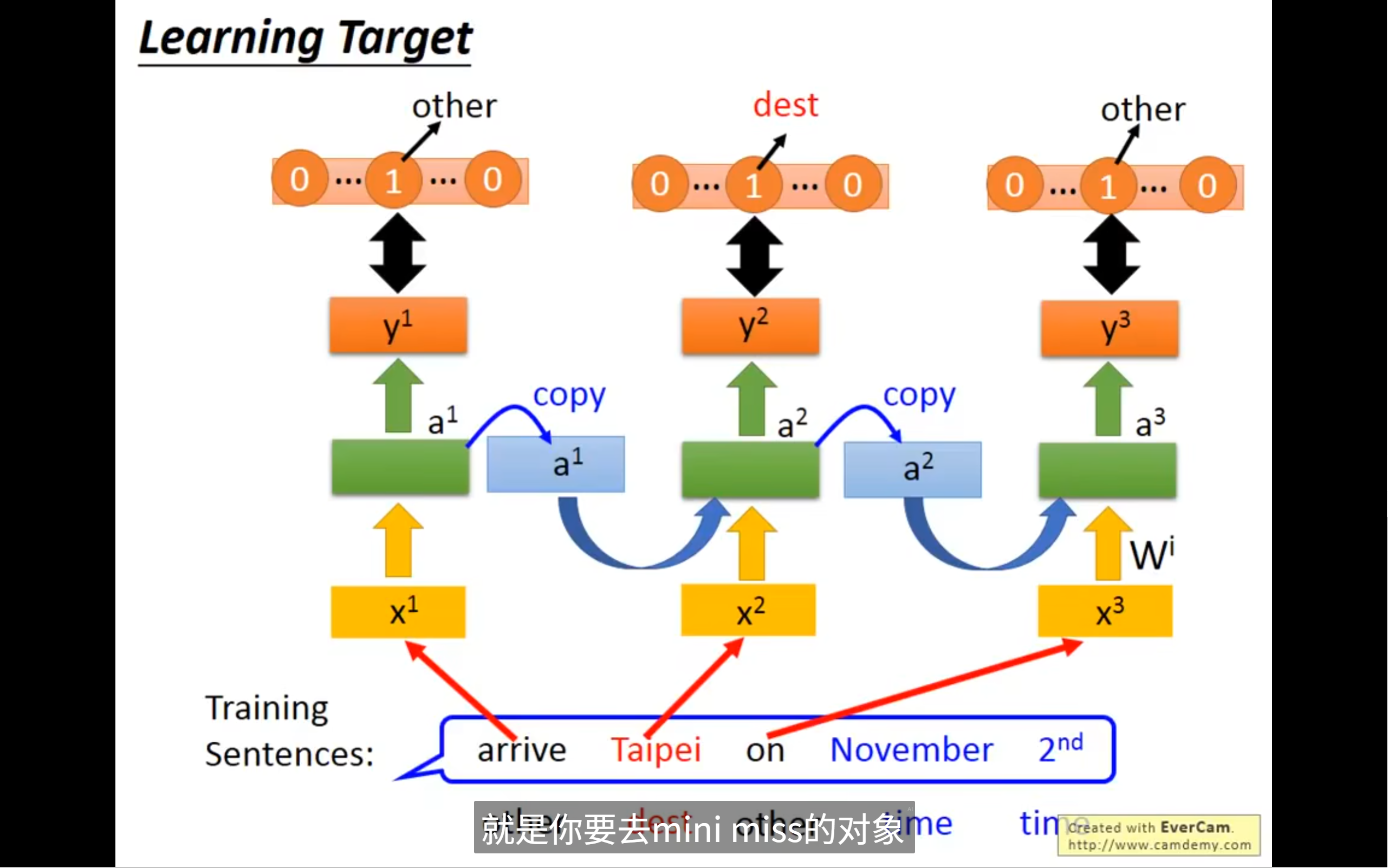
我们的training依旧是gradient descent,一般用的是bptt,也就是在原本的backpropagation上加入了time的信息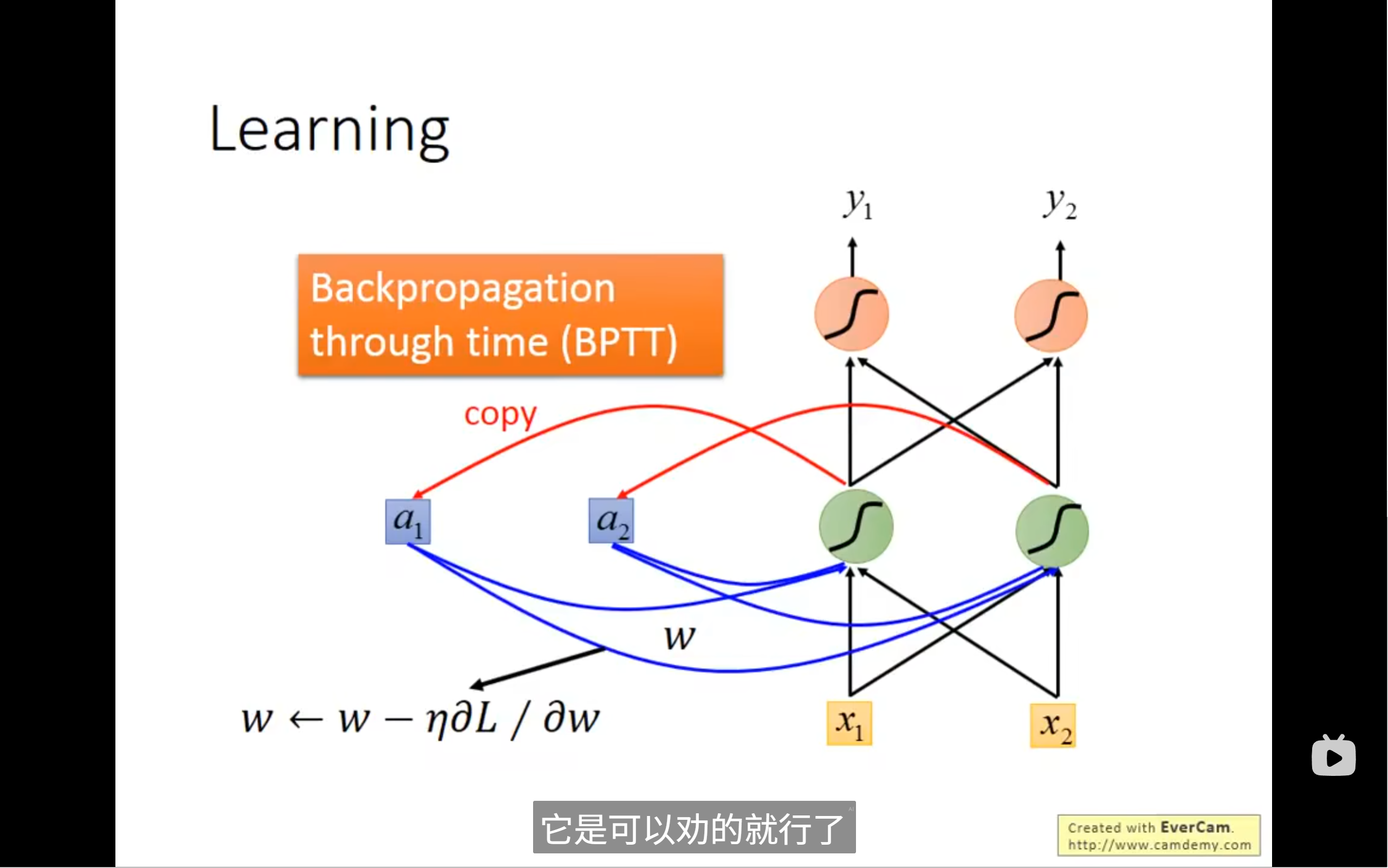
但是rnn是不好train起来的,就算代码没有bug,也会出现这种现象,我们可以猜测是不是rnn这个network本身存在的一些问题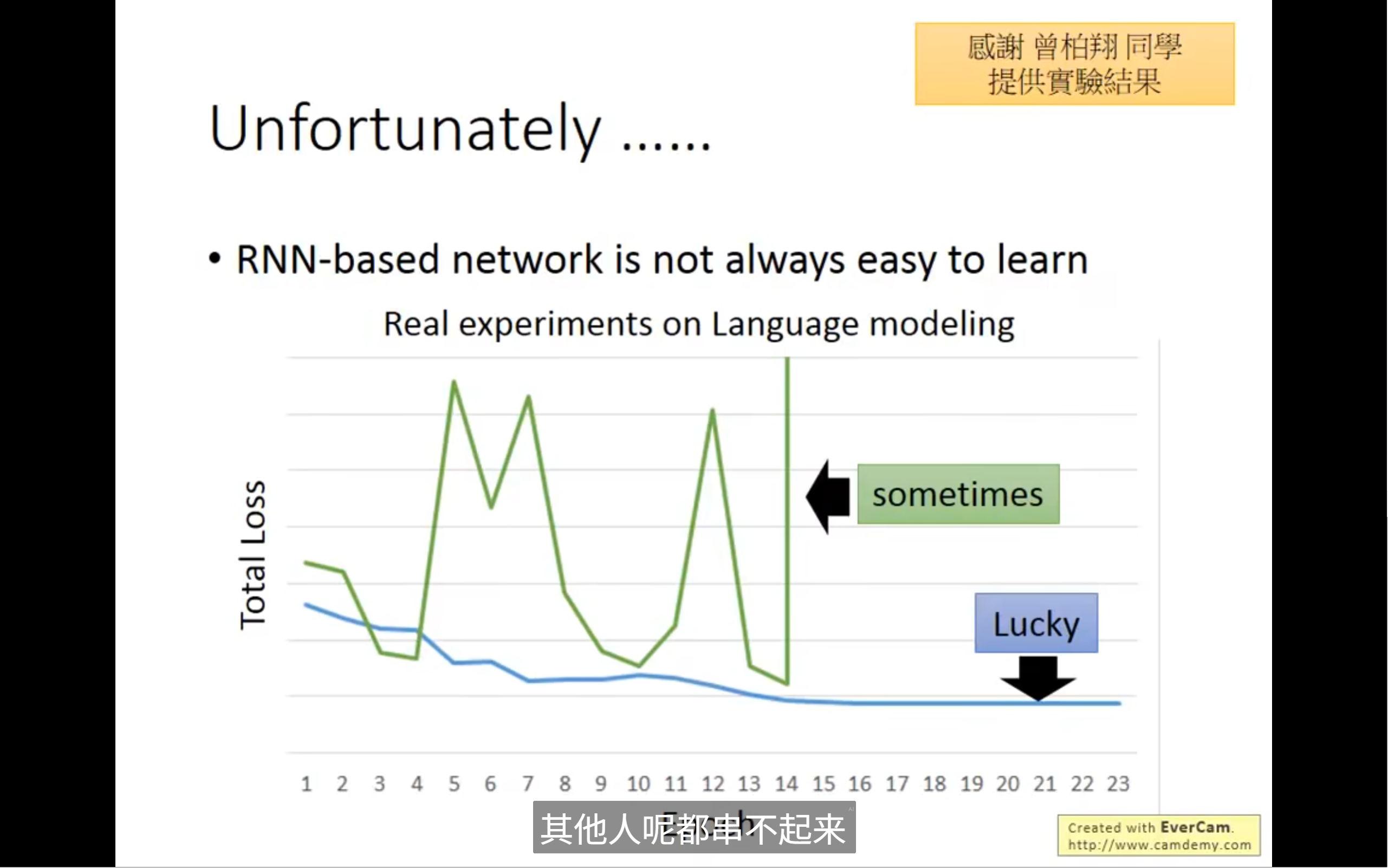
通过对rnn的研究,可以发现它的error surface竟然是长这样的,有些地方很崎岖,有些地方很平坦
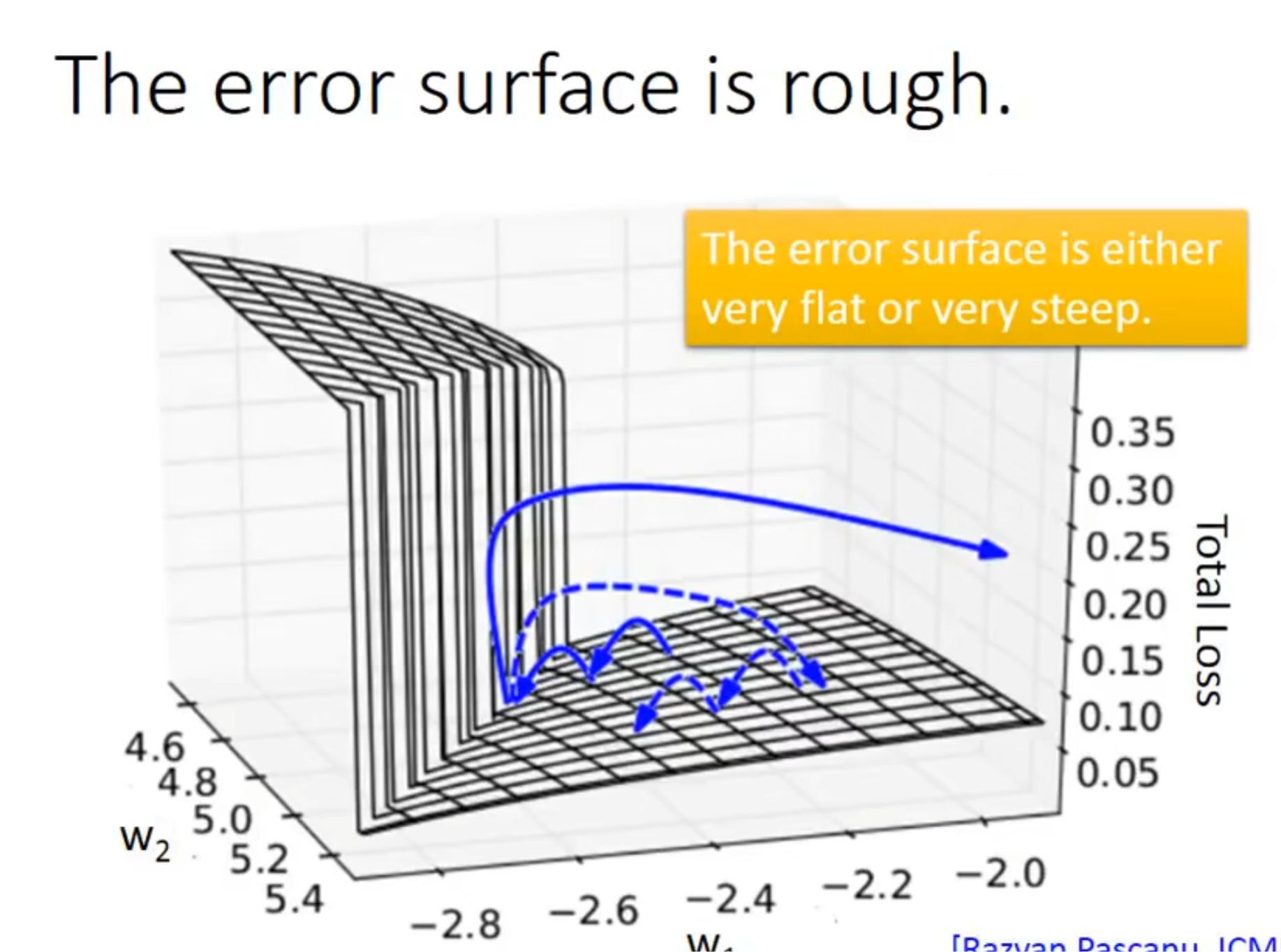
解决办法就是限制gradient,让它大于某个值是就以这个值结束
为什么会产生这样的error surface呢,我们分析可得激活函数跟这个没啥关系,那么我们可以试着改变这个w,进行微调,看loss有什么样的变化
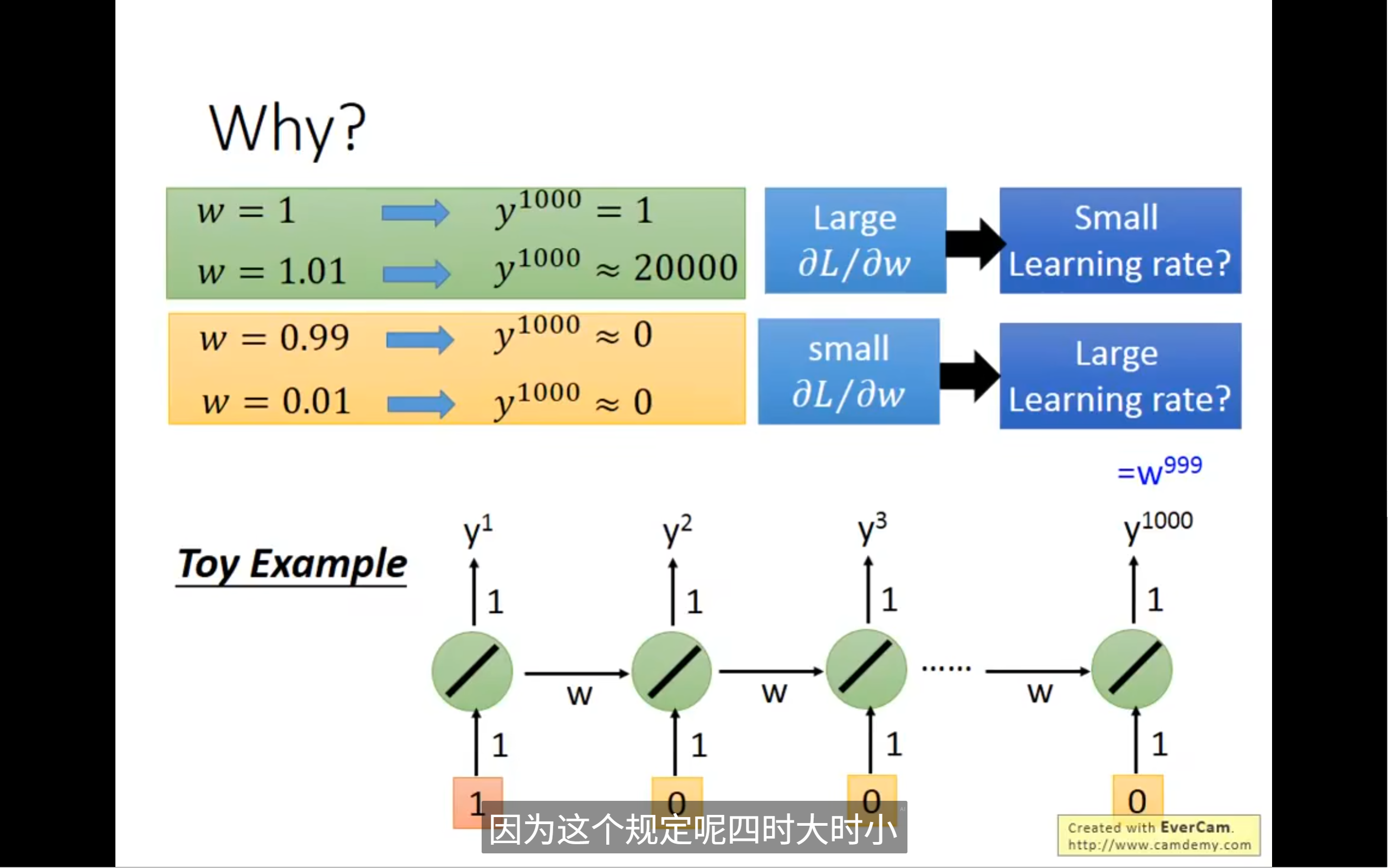
rnn的问题主要出现在它把同样的东西,做transition的时候,在时间和时间转换的时候,反复使用,从memory接到neuron的那一组,会在不同的时间点反复使用,所以这个w只要一有变化,产生的结果就会有很大变化
有什么技巧可以让我们减少这种的影响,其实就是lstm.
那么为什么lstm可以解决这个rnn的潜在影响呢,首先,memory和input是加起来的,不想rnn中直接拿来用,而且一旦这个影响产生了,除非被forget掉,不然影响会一直存在,rnn则是memory会被format,所以lstm不会gradient vanishing.
gru是相对简单的rnn,对于lstm来说,因为只有两个gate,其中input 和forget是关联的,input gate开的时候,forget gate就会关,也可以说成:旧的不去,新的不来
还有其他的技巧
应用:输入一个sequence, 输出一个vector,这样可以做情感分析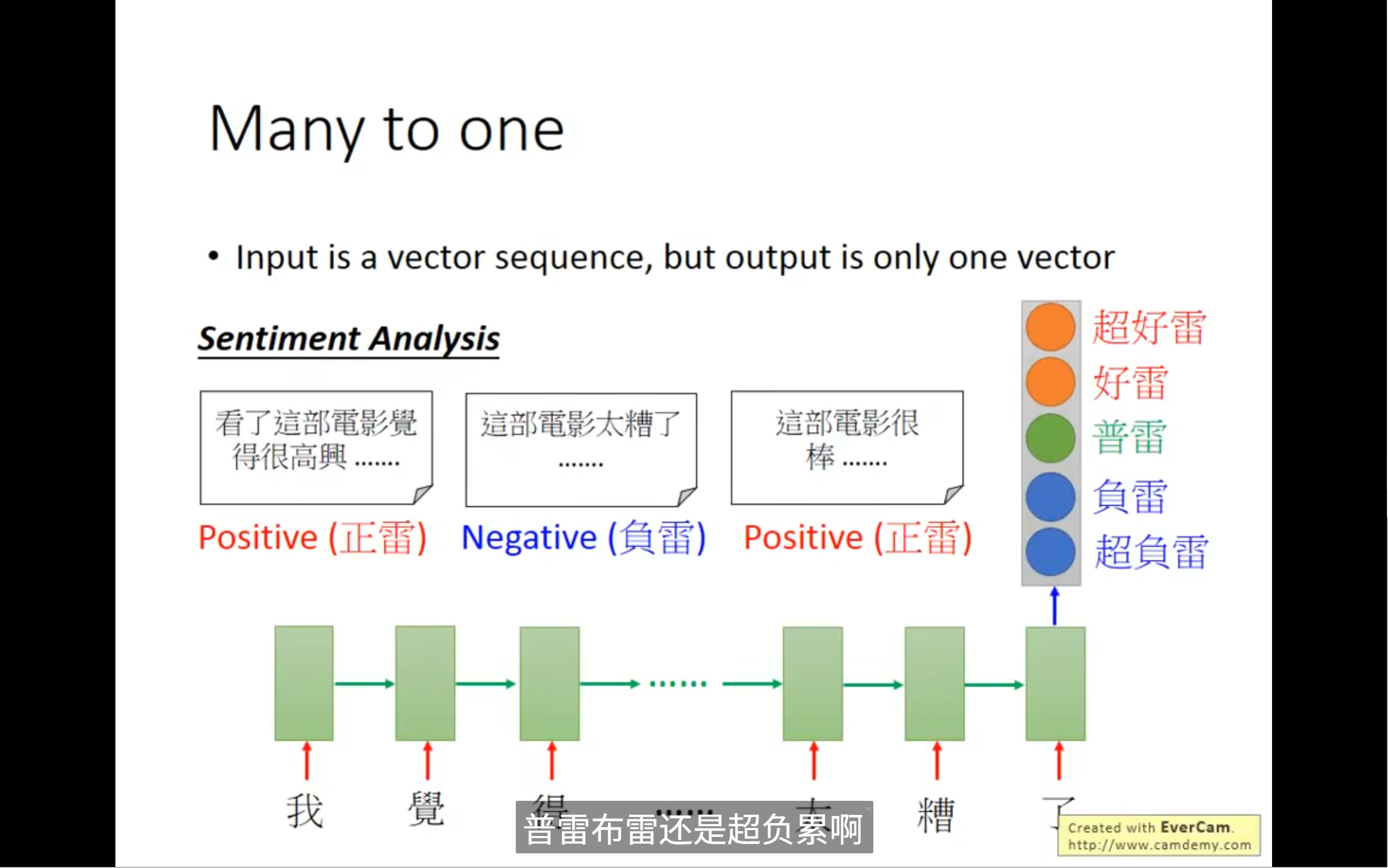
输入输出多对多的情况,语音辨识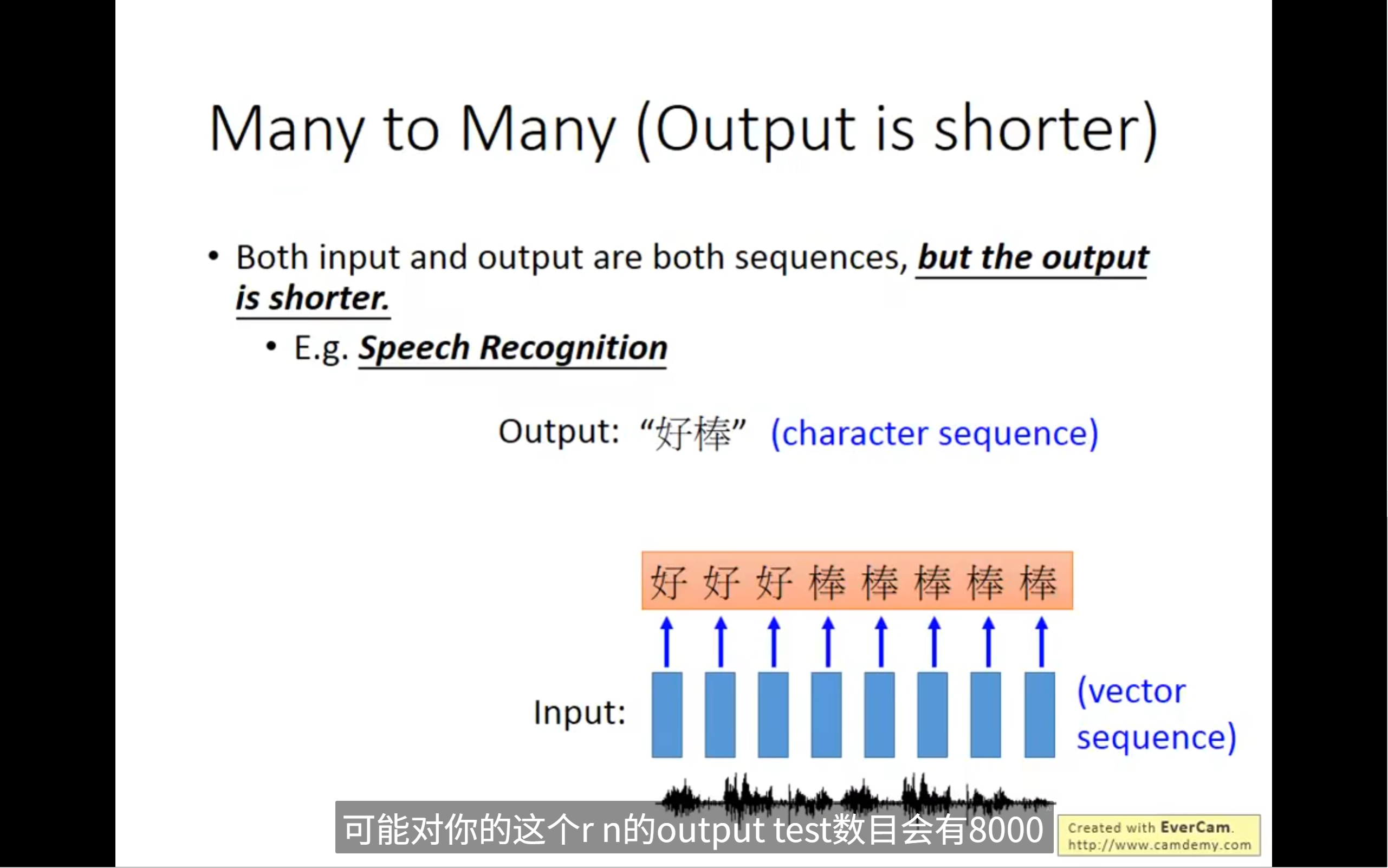
如果语音辨识出现叠字情况怎么办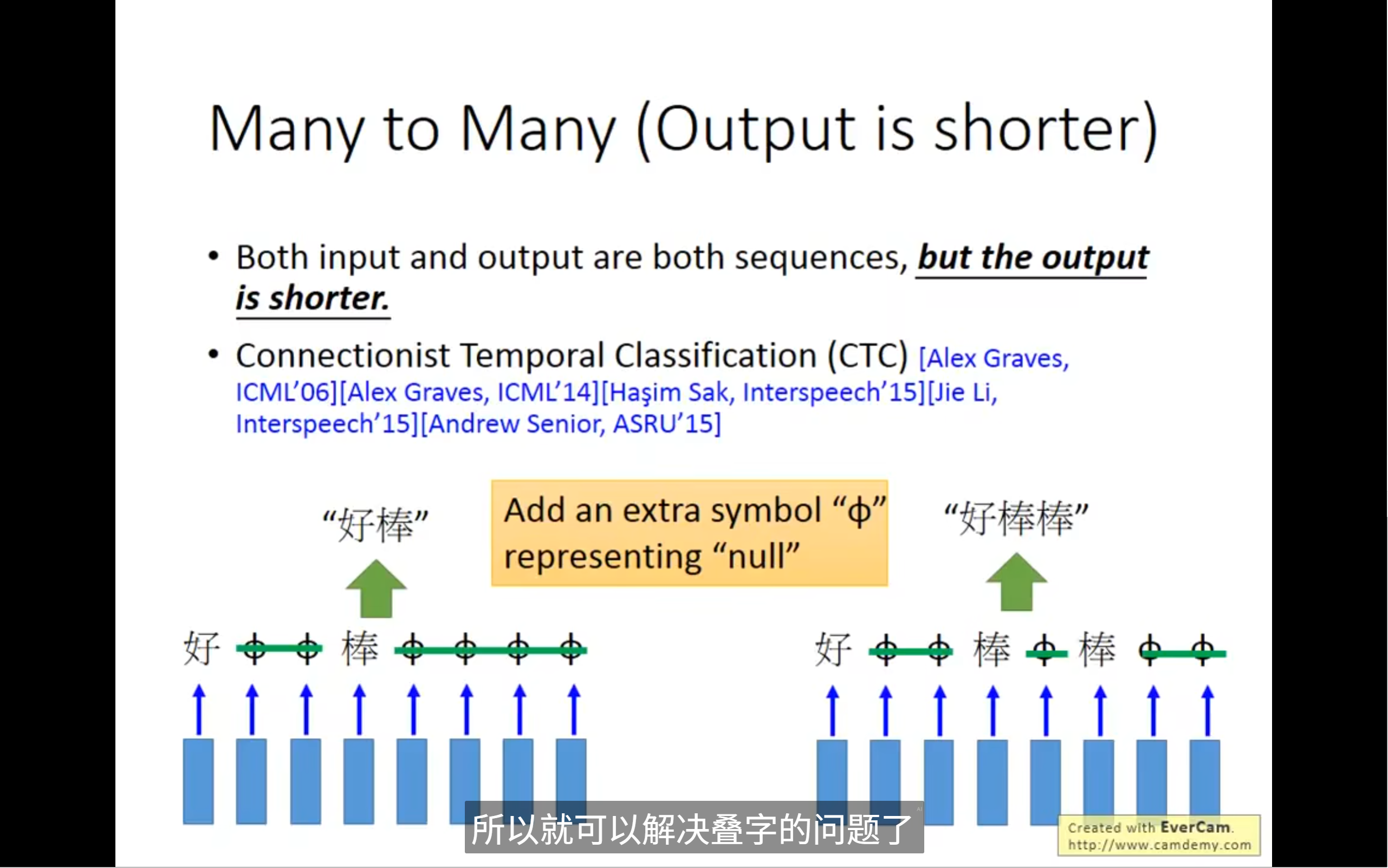
ctc使用穷举法来得到的
我们就算不知道这个词汇到底是什么样的,通过ctc,还是有可能得到答案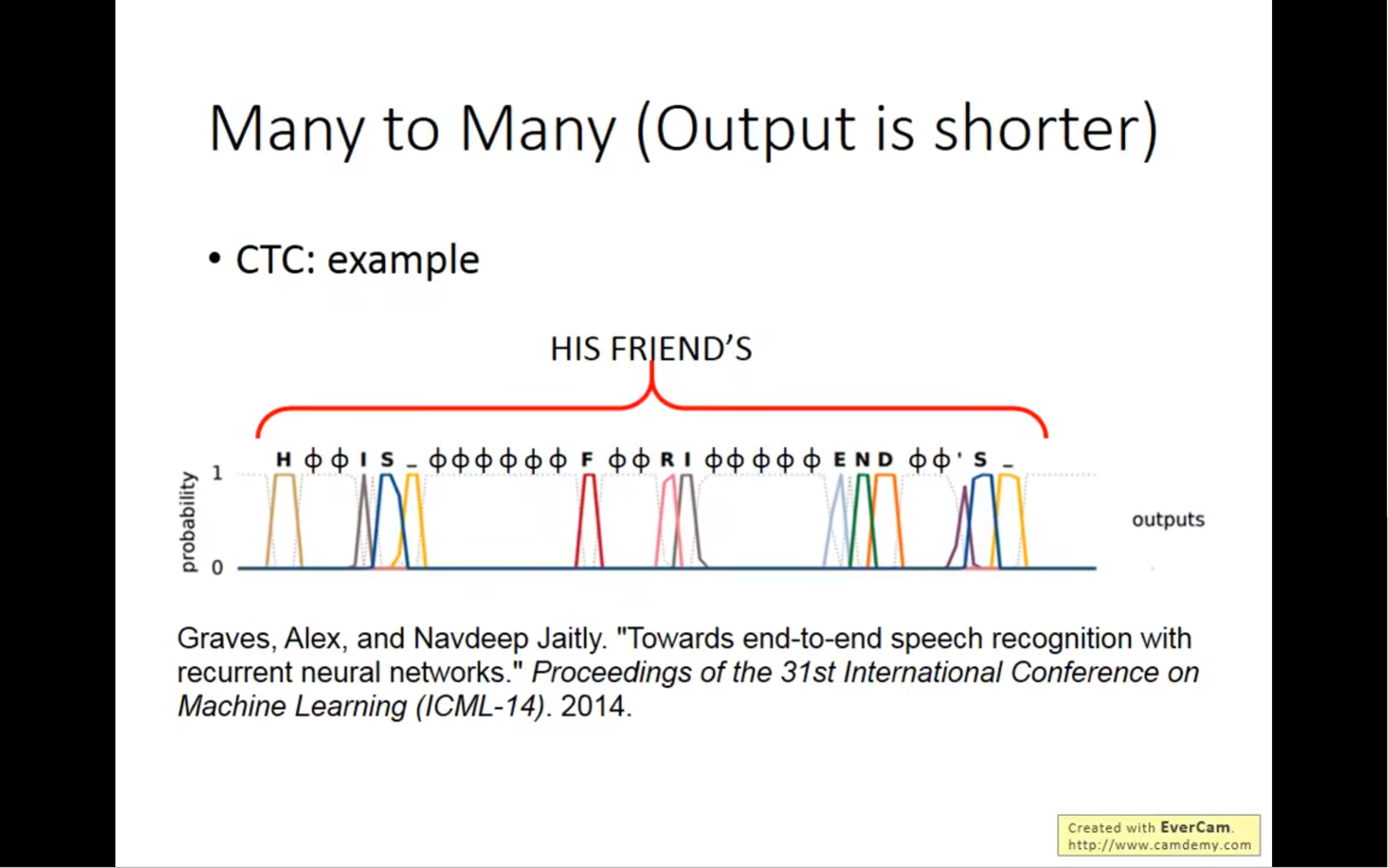
不确定input和output哪个长,比如说中英文翻译,如果输入machinelearning进去,在输入完learning后,得到机这个字,然后逐渐得出器,学,习三个字,但是,它还会继续工作,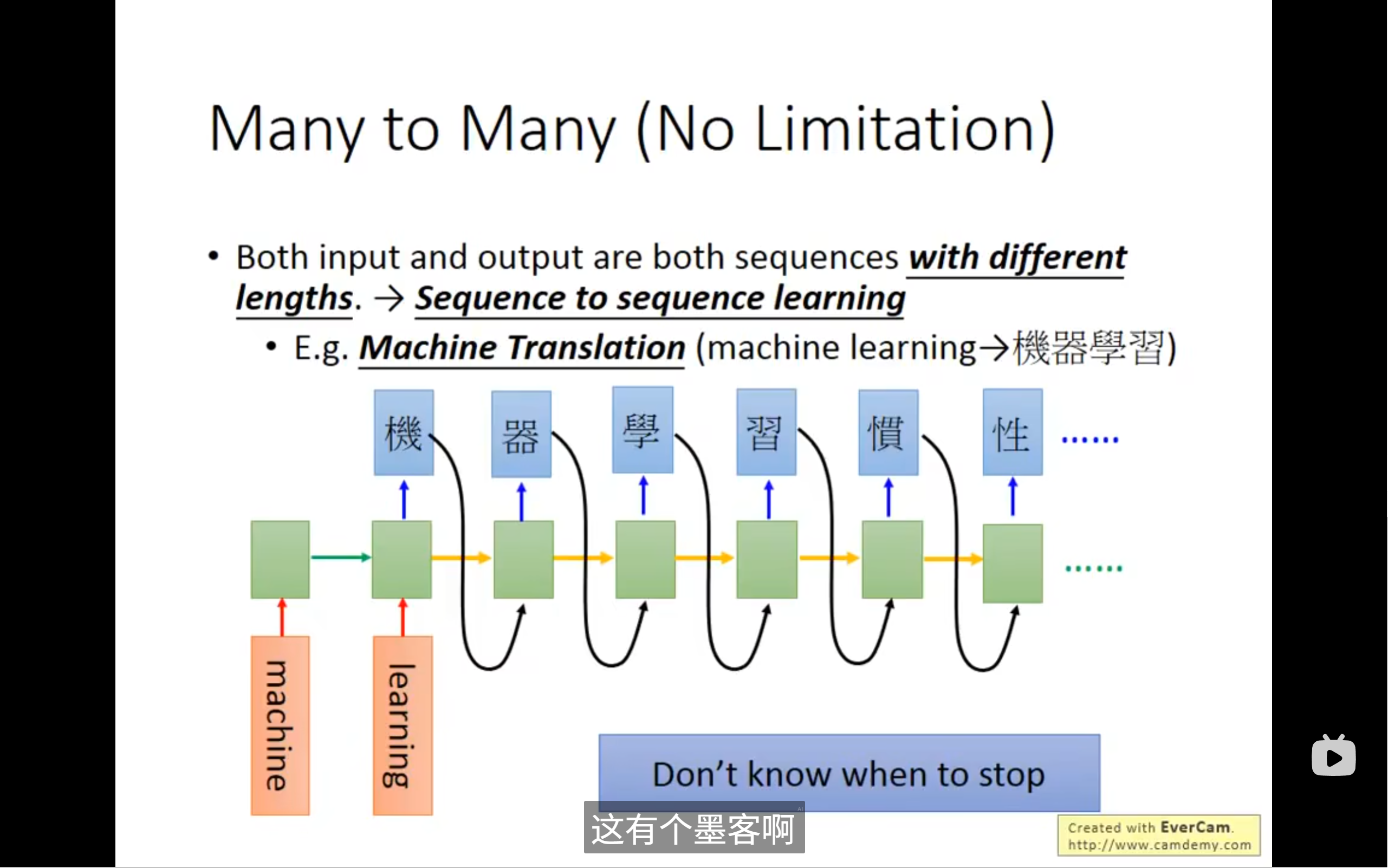
有办法可以让机器停下来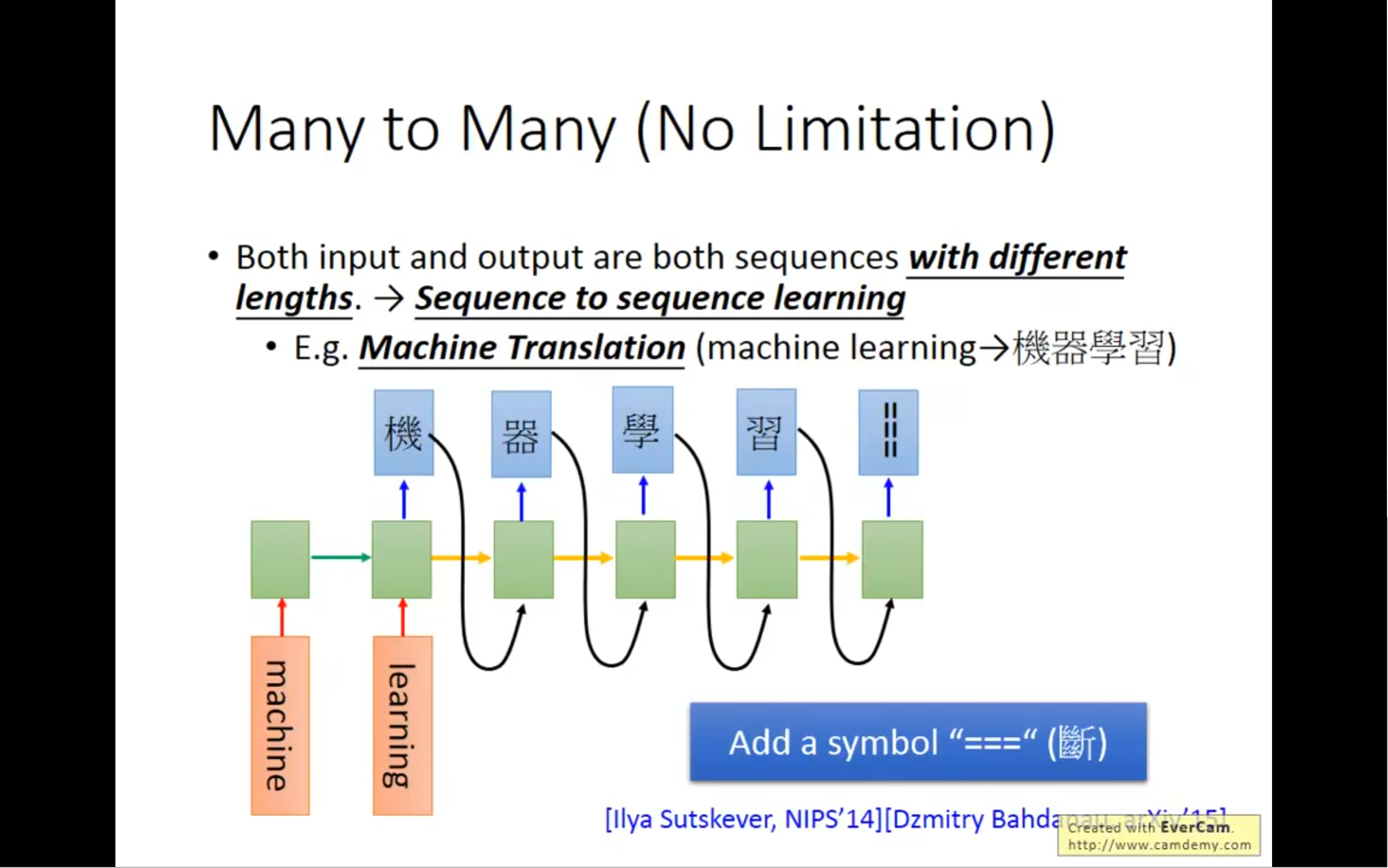
有时候我们甚至不用做语音辨识就可以直接翻译,比如说,扔一大堆英文句子和对应的中文翻译给机器,然后输入一段英文语音,直接输出中文翻译,这个可以应用在各种方言,特别是这些方言并没有文字的情况下去翻译

我们可以用rnn输出结构树, 结构树使用sequence来表示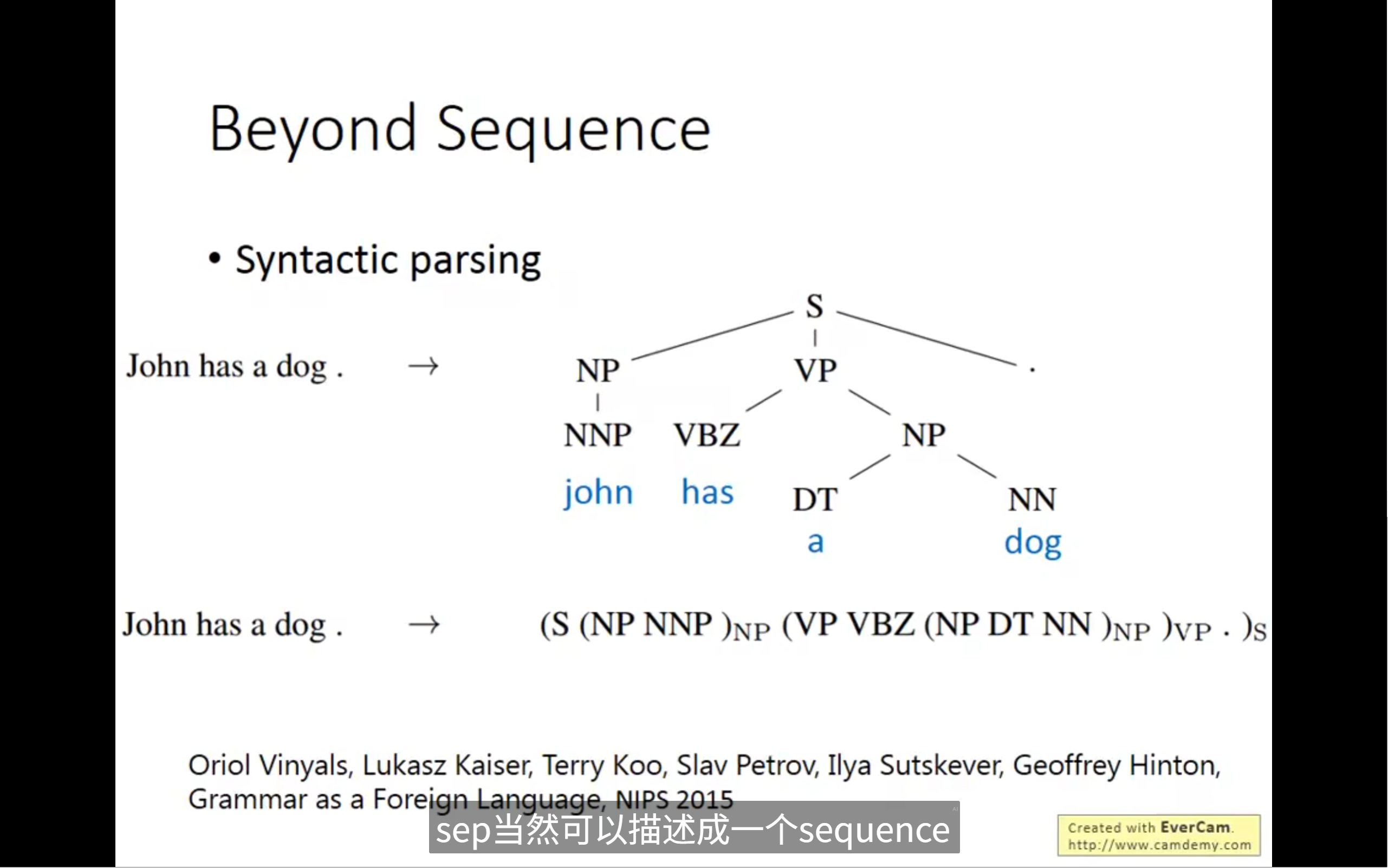
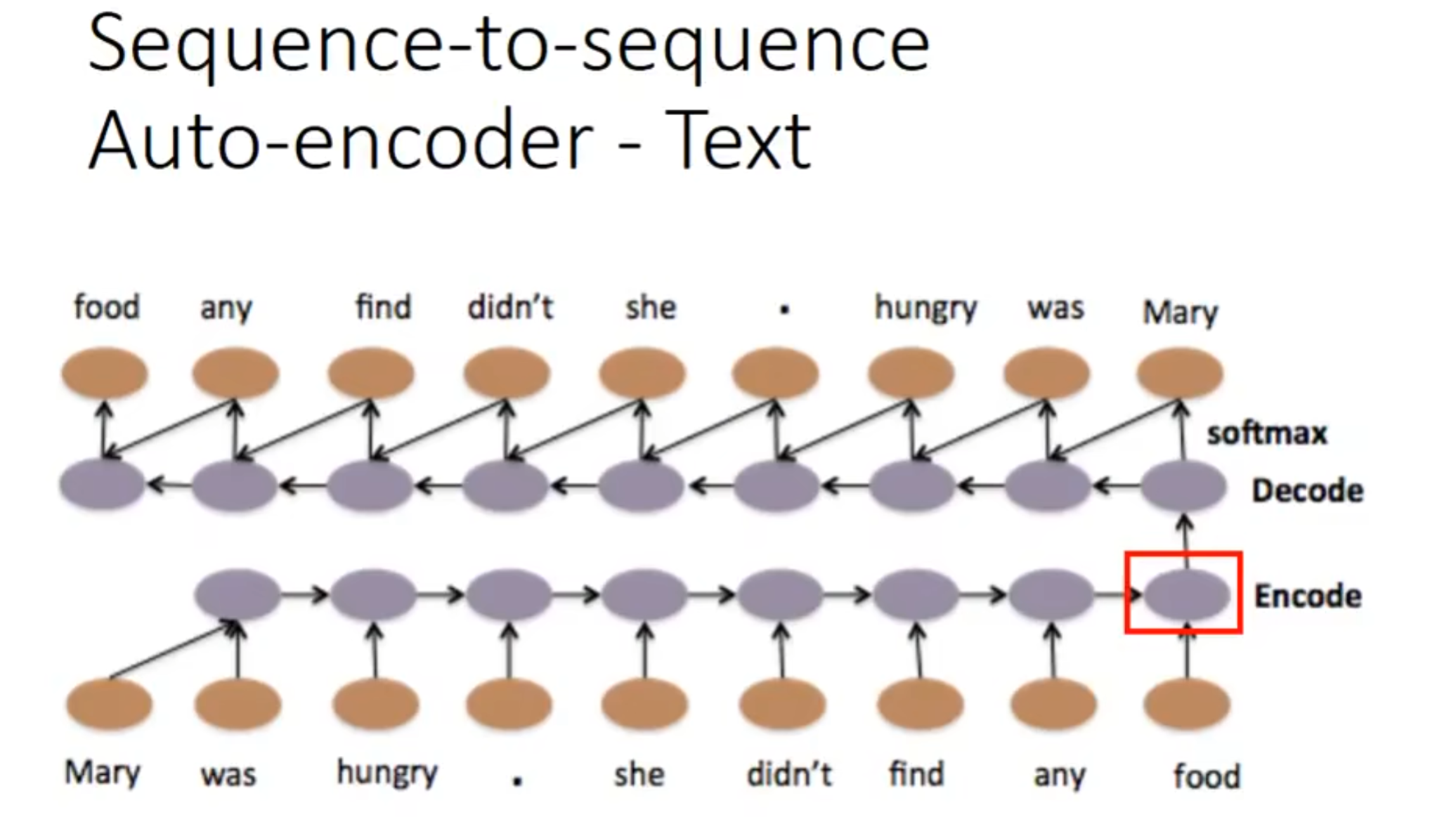
我们可以用sequence to sequence auto-encoder来做这个辨识句子顺序,因为下面的两个sequence是有同样的词汇,但是order不一样,导致意思不一样,但rnn无法认出他们不一样
那么我们会用seq2seq的auto-encoder来解决,
这个encoder其实就是把你输入的这句话,打包压缩了(语义向量vector),就像看书时提炼了中心思想一样,不然,像这种翻译类工作,rnn很难凭借前面输入得到的隐藏状态来进行翻译,但有了中心思想,就可以顺利进行翻译了(decoder)
我们也可以分为几句话进行输入,得到多个encode的vector再加起来输入到decode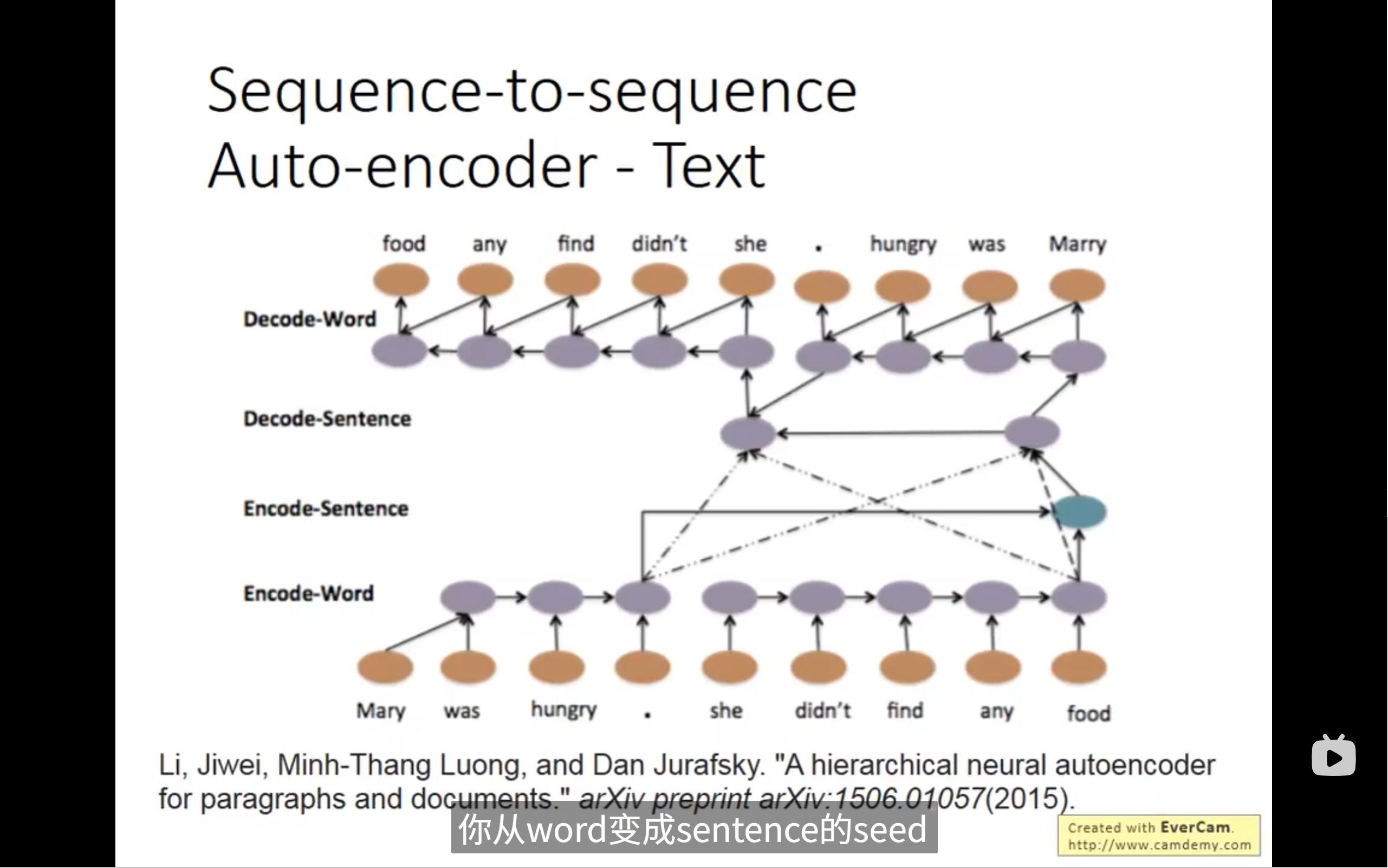
我们也可以用这个encoder来做语音搜寻,就是从一句话中找到那个词的语音(不需要做语音辨识,直接拿到语音就可以通过判断相似度来找到目标语音)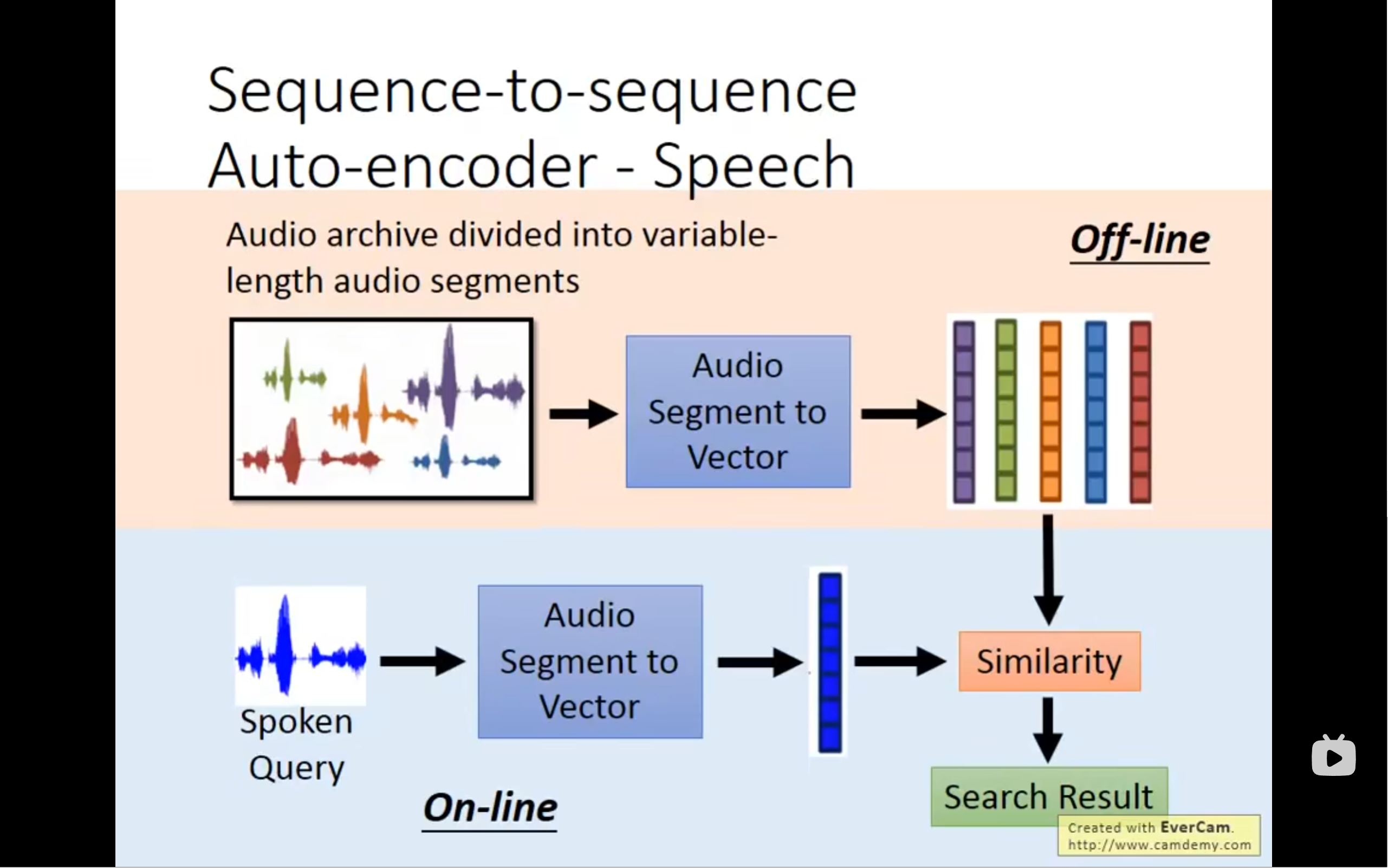
具体是怎么做的呢,怎么把声音信号变成vector呢?我们首先将audio segment转化为acoustic features输入到rnn中,rnn就是我们的encoder,然后最后一个audio segment中的memory的值就代表了整个声音信号的信息(vector),encoder和decoder是一起train的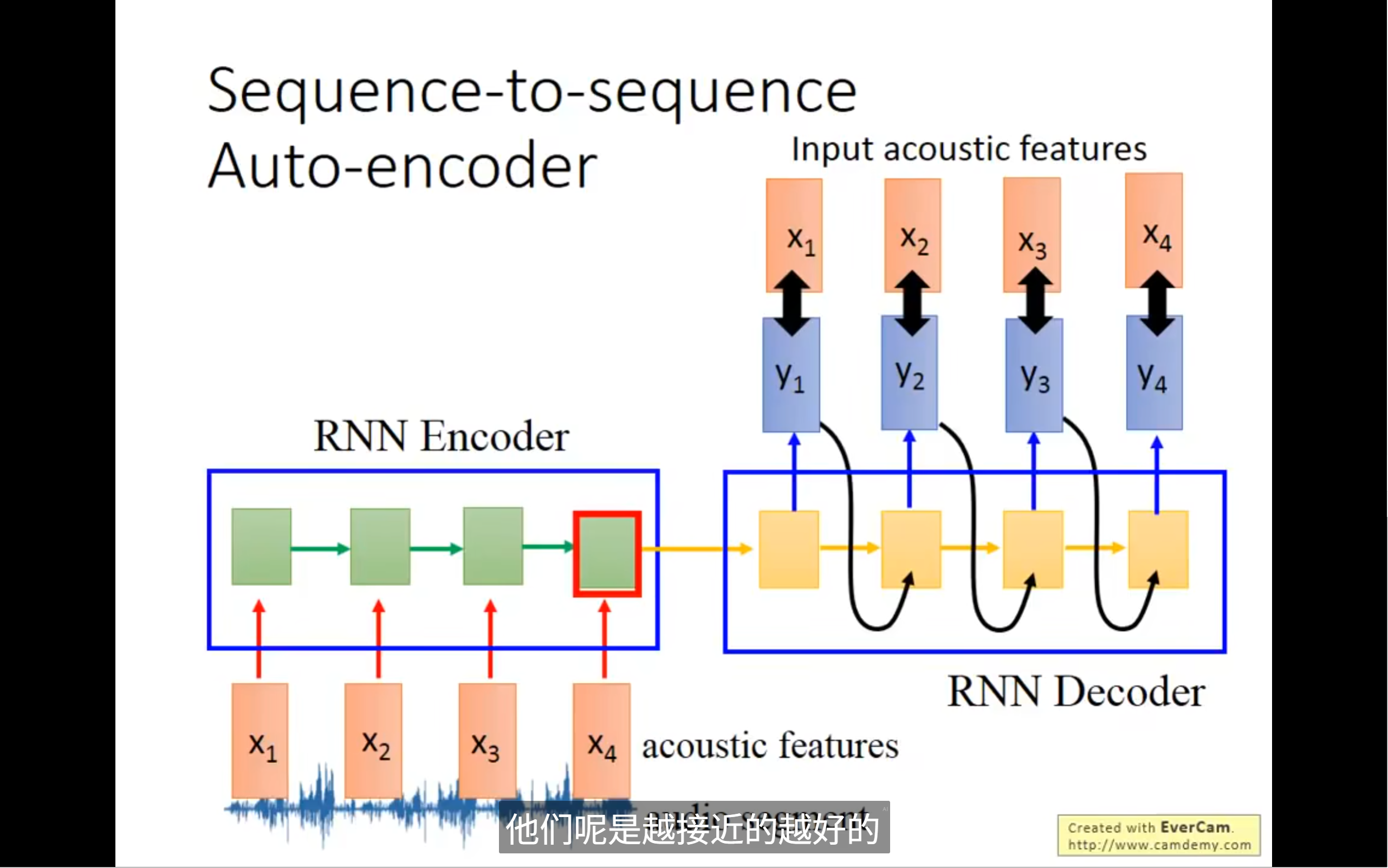
这里有一个聊天机器人的例子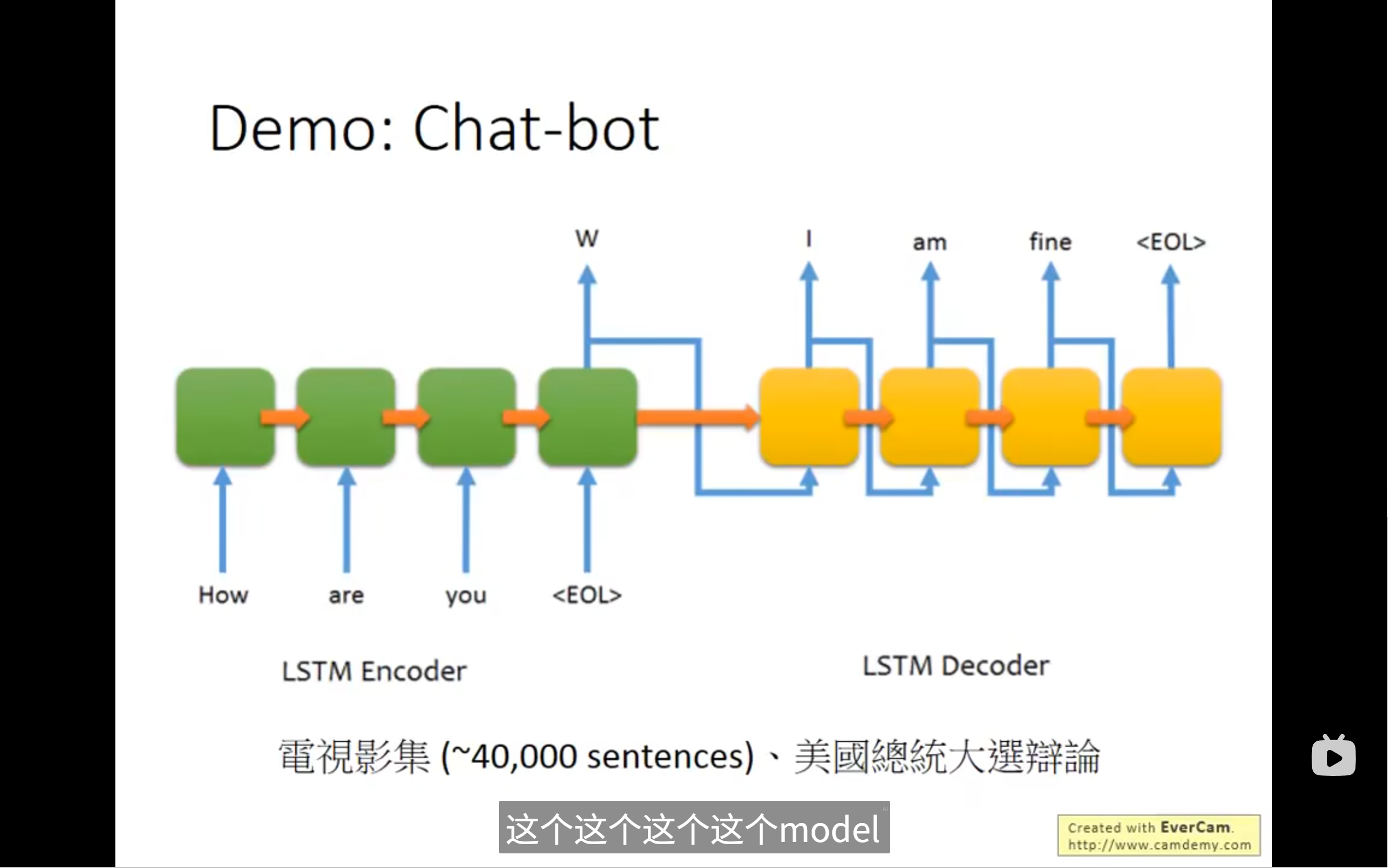
attention based model可以看作时rnn的进阶版本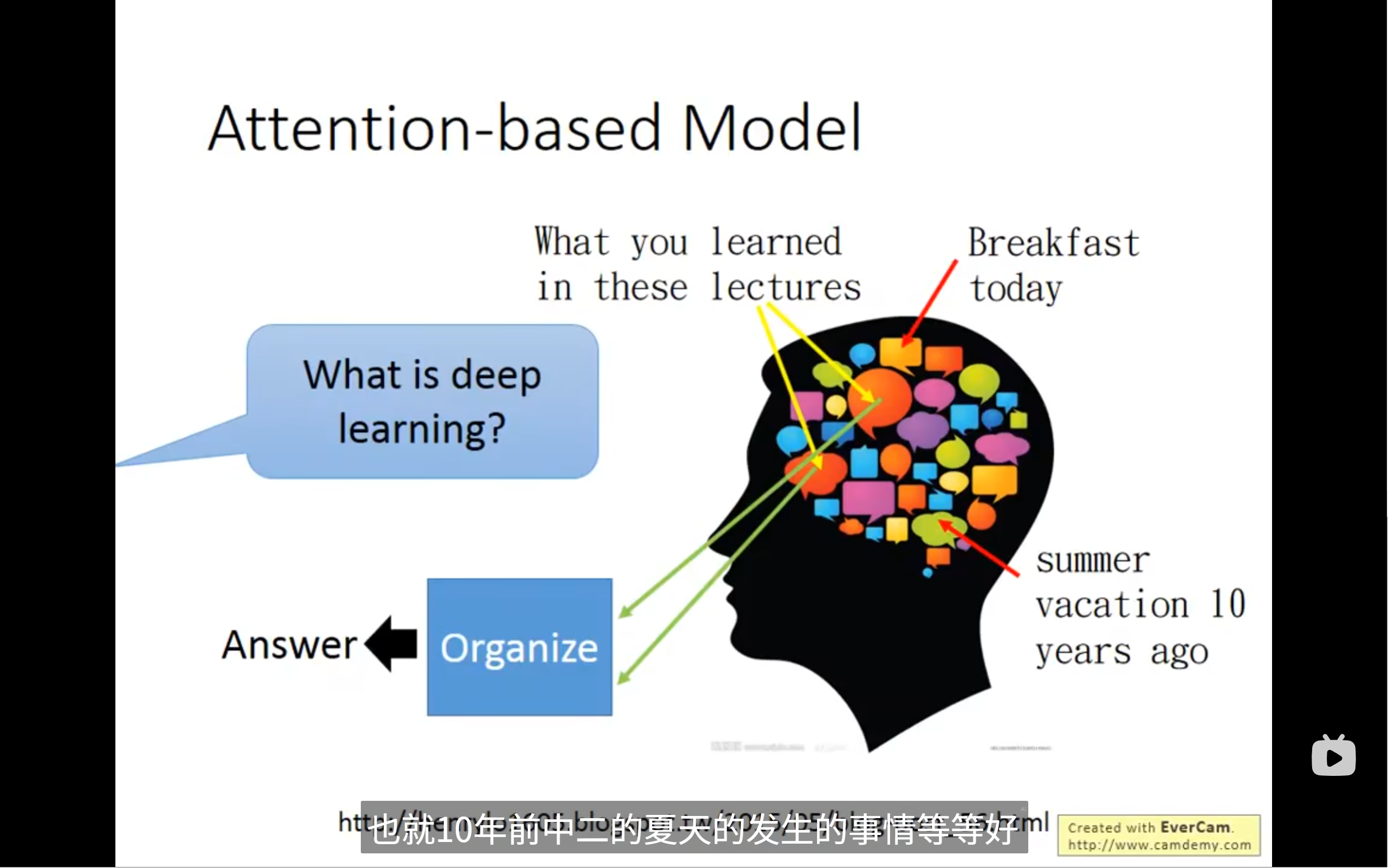
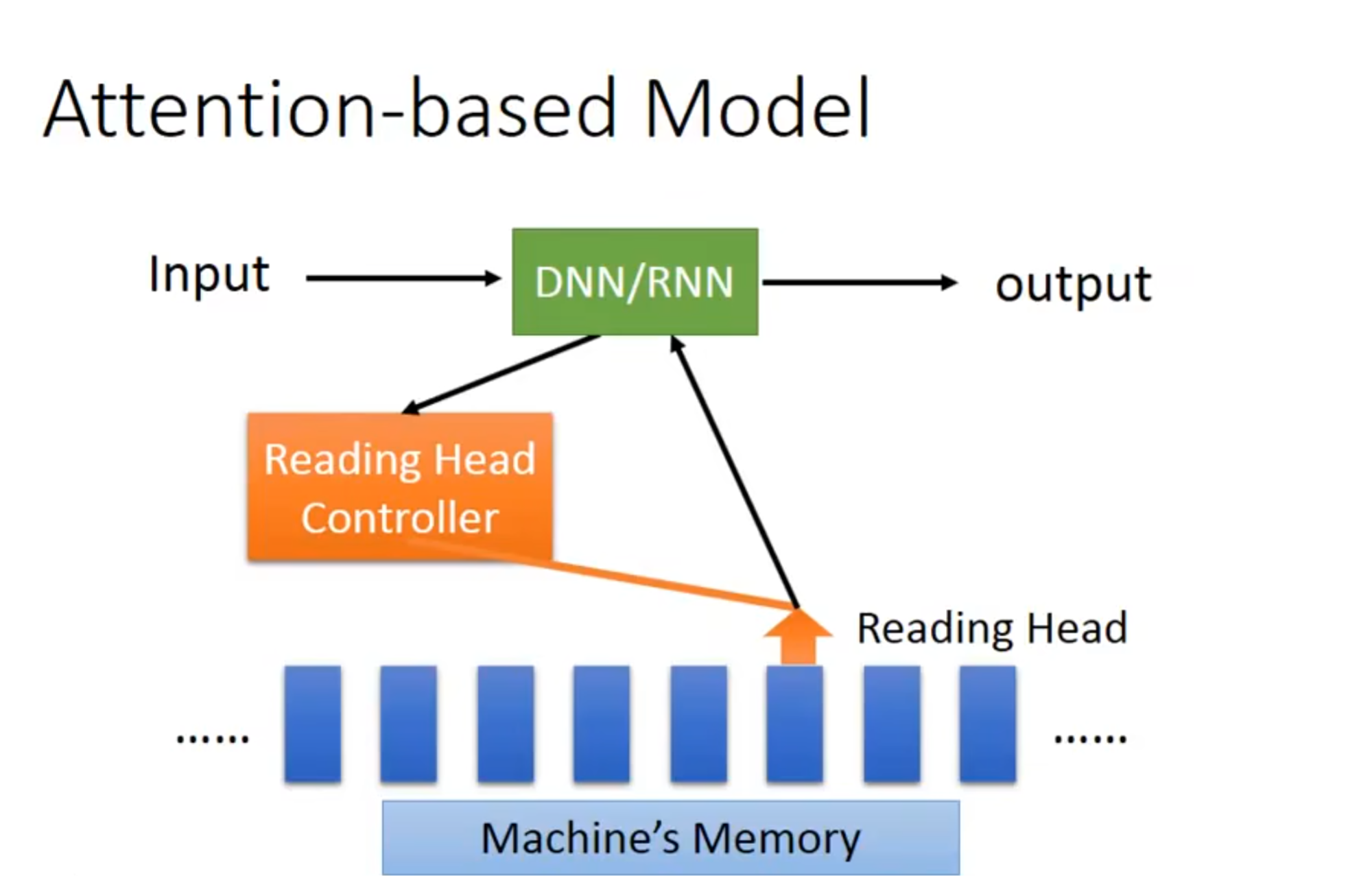
机器自己通过训练来控制读写头放置在哪里(无顺序)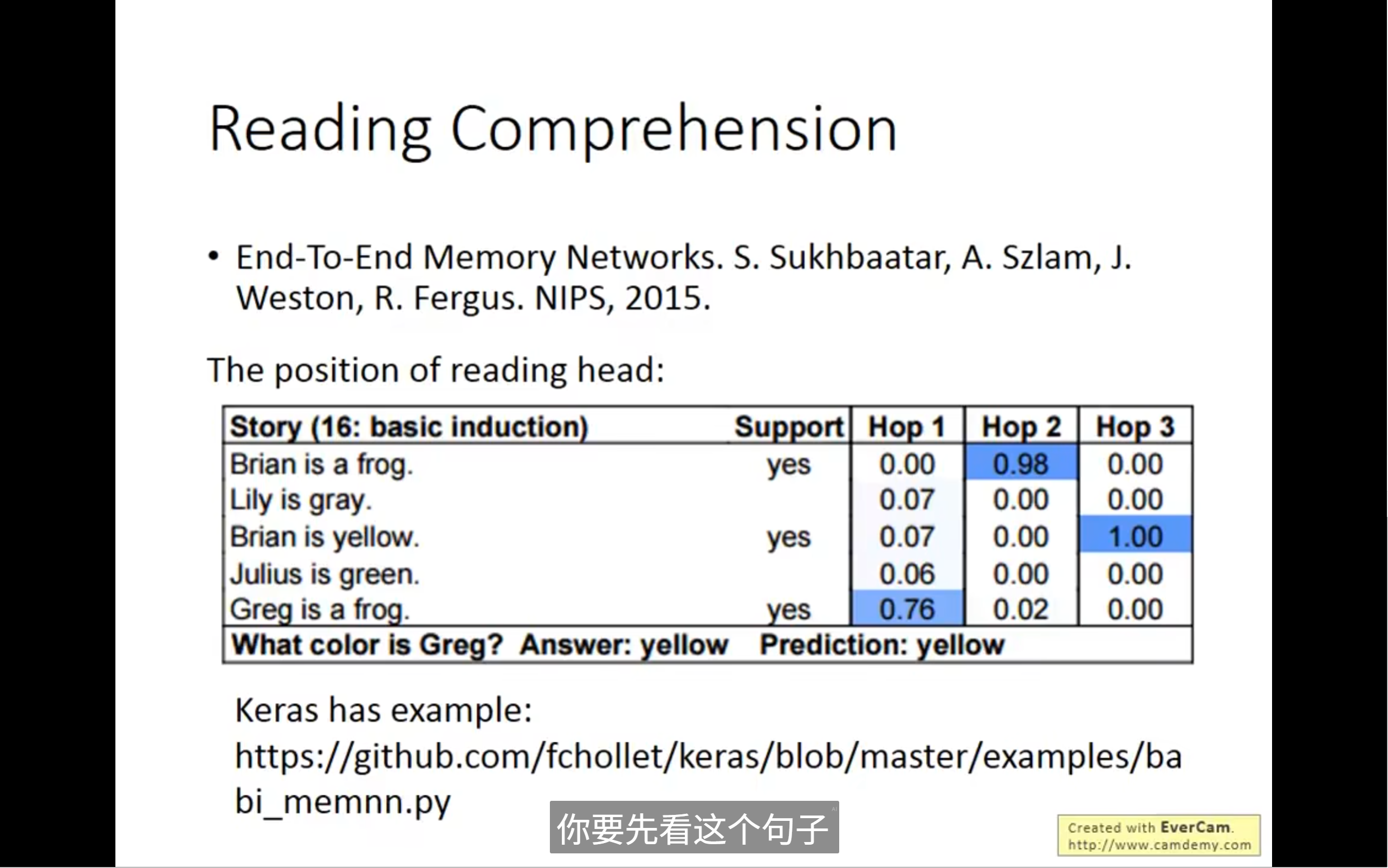
也可以做其他东西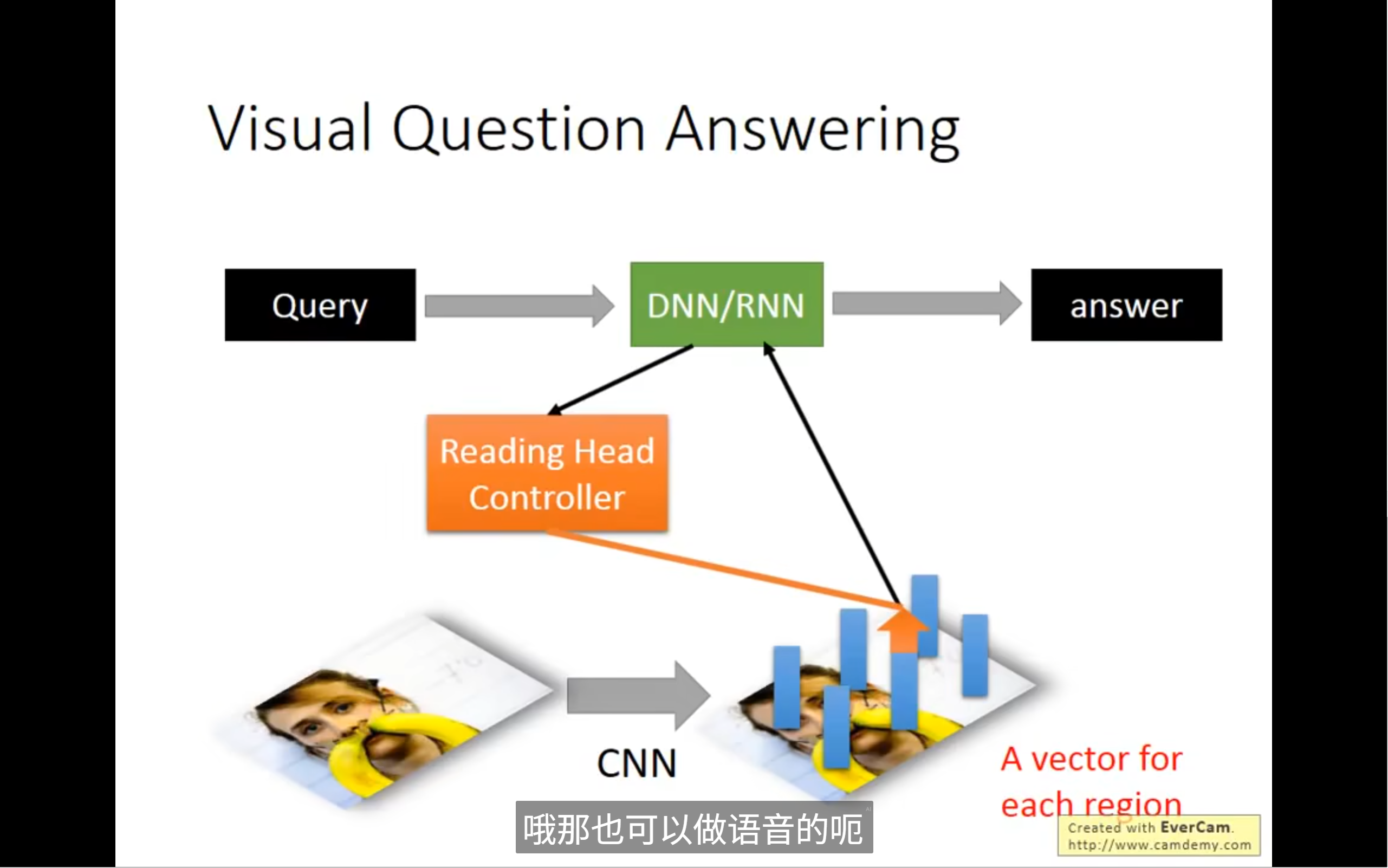
deep learning和structured learning有什么区别呢
结构化学习是机器学习的一个分支,它的核心思想是:我们要预测的输出,不仅仅是一个简单的数字或一个类别(比如“是”或“否”),而是一个具有内在“结构”的东西
这个“结构”可以是一个序列(比如一个句子中每个词的词性),一棵树(比如句子的语法树),一个图(比如社交网络中的关系),甚至是一张图片中的像素排列。
HMM (隐马尔可夫模型), CRF (条件随机场), Structured Perceptron/SVM (结构化感知机/支持向量机) 都是经典的结构化学习模型。它们擅长处理序列标注、句法分析等任务。
两者可以相互结合使用

可以先用rnn再将其输出作为输入丢进structured learning
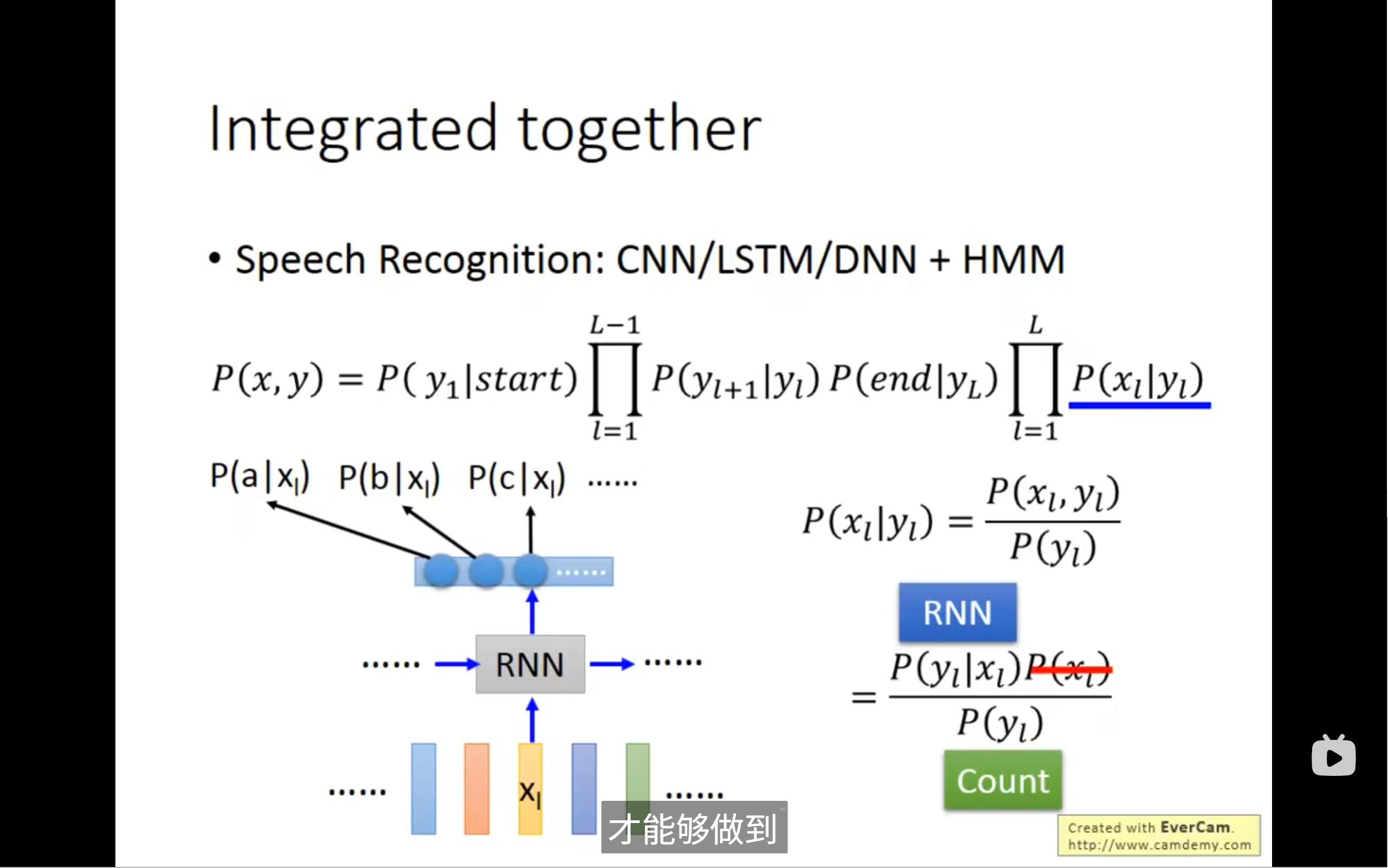
深度学习(CNN/LSTM/DNN)负责“听清”: 它充当 HMM 中的“发射概率”(Emission Probability)部分,负责把原始的语音信号(声学特征 x)转化成各种音素或词的概率 (P(y|x))
HMM 负责“理解”并“组合”: 它充当“语言模型”(Language Model)和“解码器”(Decoder)部分,负责考虑音素/词之间的顺序关系和转移概率 (P(y_l+1|y_l)),并利用维特比算法(Viterbi Algorithm)从所有可能的音素/词序列中,找到最符合语音规律和语言规律的那个序列。
- 深度学习模型(如RNN)被训练来预测声学特征
x_l对应的音素/词语y_l的后验概率P(y_l|x_l)。 - 这些由深度学习模型输出的概率,经过贝叶斯转换后,作为 HMM 的“发射概率”部分。
- HMM 仍然负责其自身的状态转移(语言模型)和最终的解码(使用维特比算法寻找最佳路径)。
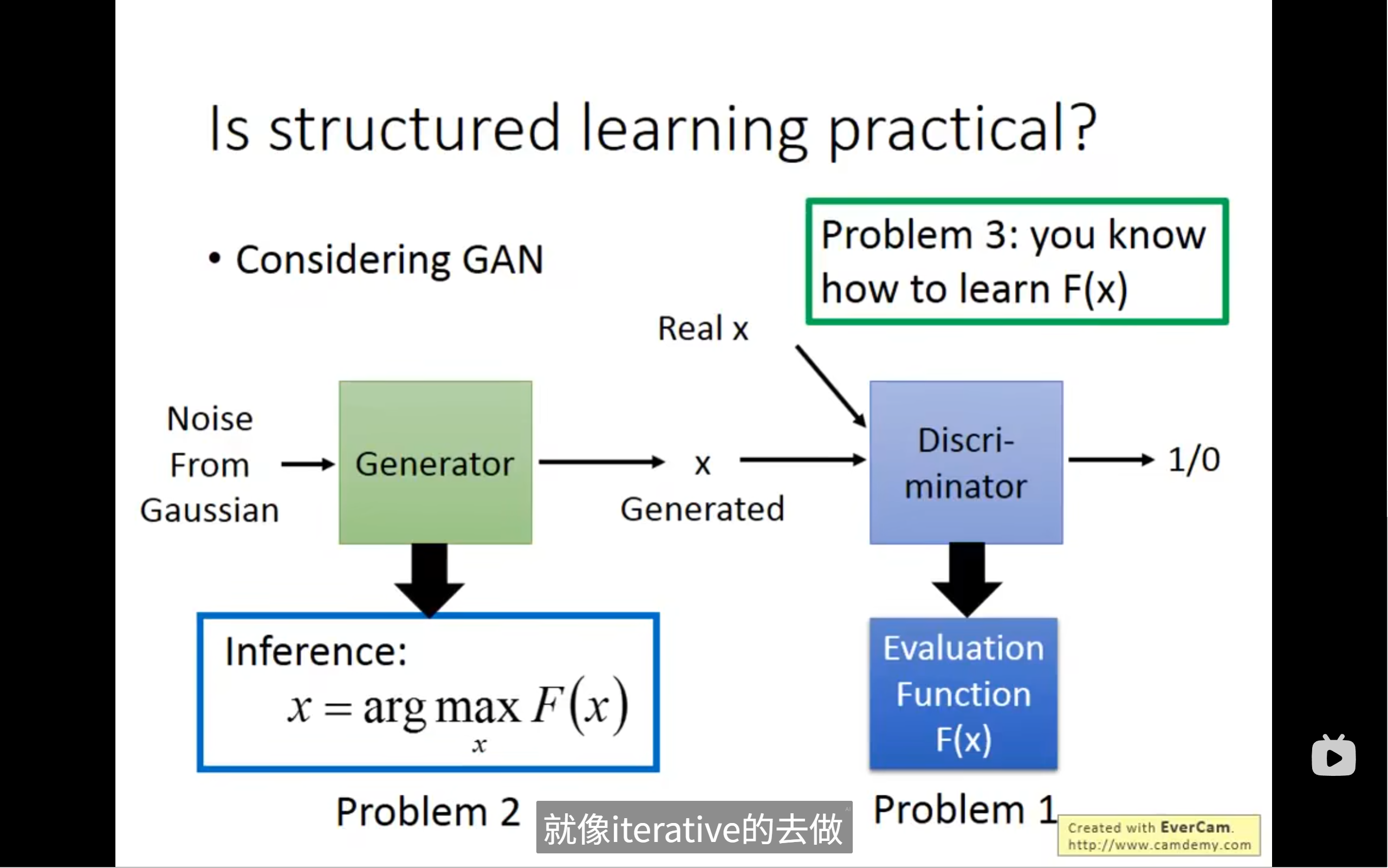
GAN(生成对抗网络)是什么?
你可以把 GAN 理解为一场“造假者”和“鉴别者”之间的猫鼠游戏。
- Generator (生成器,绿色方块): 就像一个造假者。它的任务是接收一些随机的噪声(比如从高斯分布中取出的随机数),然后把这些噪声转换成看起来非常真实的假数据(比如假图像、假文本、假语音)。它希望自己造出来的假数据能以假乱真。
- Discriminator (鉴别器,蓝色方块): 就像一个鉴别专家或者警察。它的任务是接收两种数据:一种是真实的原始数据(Real x),另一种是生成器造出来的假数据(Generated x)。它的目标是准确地判断哪个是真,哪个是假,输出一个 1(真)或 0(假)。
它们的对抗过程:
- 生成器努力提高自己的造假水平,让鉴别器分不清真假。
- 鉴别器努力提高自己的鉴别能力,争取能区分出生成器造的假。
- 这个“对抗”过程会不断迭代,最终目标是让生成器造出的假数据无限接近真实数据,以至于鉴别器也无法分辨。
2. 这张图如何用 GAN 来解释“结构化学习的实践性”?
关键在于图中的两个蓝色框:
-
右下方的 Evaluation Function F(x):
- 这个
F(x)函数是从鉴别器 (Discriminator) 来的。 - 它代表了鉴别器对一个输入
x(无论是真实的还是生成的)给出的一个**“真假评分”**。F(x)的值越高,鉴别器认为x是真实数据的可能性就越大。 - 你可以把它看作是一种“质量评估函数”,它评估
x是否符合真实数据的分布和结构。
- 这个
-
左下方的 Inference: x = arg max F(x):
- 这个公式描述的是生成器 (Generator) 的目标。
arg max F(x)的意思是:生成器要找到一个x(也就是它生成的假数据),使得这个x能够最大化鉴别器给出的“真假评分”F(x)。- 换句话说,生成器在尝试生成一个能让鉴别器“误以为是真”的数据
x。
3. 连接到“结构化学习”:
在之前的结构化学习讲解中,我们提到结构化学习的目标是找到一个最优的结构化输出 y(比如一个序列标签)。这个寻找过程通常也是通过最大化一个评分函数来实现的,例如: y_最优 = arg max F(x, y) 这里 F(x, y) 是一个评分函数,它评估在输入 x 的情况下,输出 y 这个结构有多合理。
所以,这张图是在类比:
- 结构化学习的“推断(Inference)”过程: 就像生成器要找到一个让
F(x)最大的x一样,结构化学习也要找到一个让F(x, y)最大的y。两者都是在寻找一个能够最大化某个“评估函数”的“结构”(GAN中是生成的“数据结构x”,结构化学习中是“标签结构y”)。 - “Problem 1”和“Problem 2”:
- “Problem 1”通常指的是在训练 GAN 时,如何让 Discriminator 变得足够好,能够准确评估数据的真假(即
F(x)要能提供好的梯度)。 - “Problem 2”指的是在给定
F(x)的情况下,Generator 如何有效地找到那个能最大化F(x)的x。这通常是一个优化问题,特别是在F(x)复杂或不可导时会非常困难。幻灯片中的中文批注“不是就是可以让discriminator分辨不出来的”正是对生成器目标的一个通俗解释。
- “Problem 1”通常指的是在训练 GAN 时,如何让 Discriminator 变得足够好,能够准确评估数据的真假(即
幻灯片想表达的意思可能是:
尽管结构化学习(如CRF、结构化SVM)在推断时需要执行一个 arg max 操作(寻找最优结构),这在数学上可能很复杂,但如果我们能像 GAN 训练那样,让生成器不断地学习如何生成最大化鉴别器评分的数据,那么这种复杂优化问题在实践中是可以解决的。
通过将 GAN 的生成器与结构化学习的推断过程联系起来,这张图可能是在暗示:即使寻找最优结构看起来很困难,但通过类似对抗学习的机制,或者将评价函数(Discriminator/Evaluation Function)与生成过程(Generator/Inference)解耦,并迭代优化,是使得结构化学习在实践中变得可行的思路。
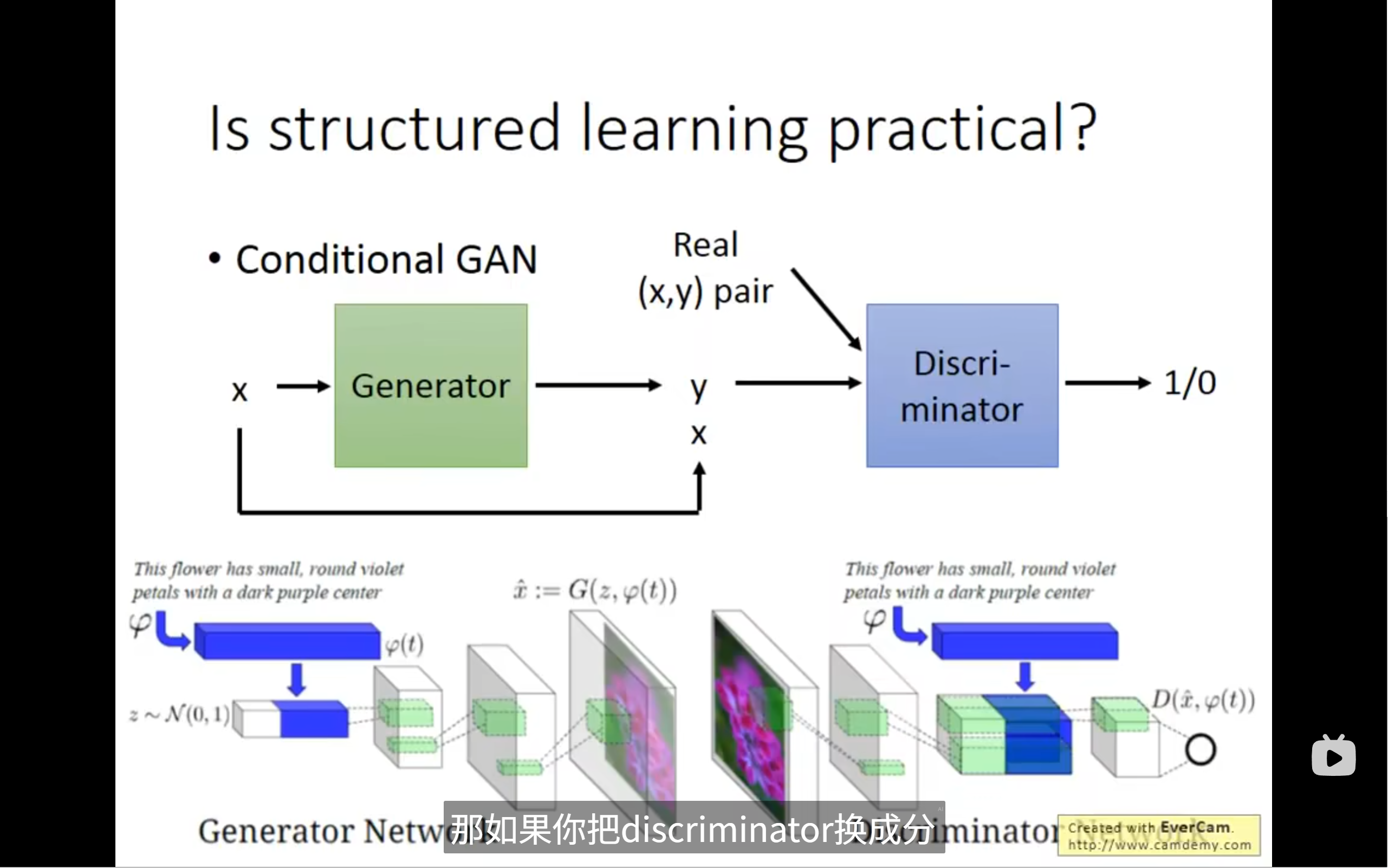
Conditional GAN (条件生成对抗网络) 是什么?
在普通的 GAN 中,生成器只是随机生成数据(比如随机生成一张人脸,你无法控制这张人脸是男是女,是年轻还是老)。
而 Conditional GAN (cGAN) 的核心思想是:给生成器和鉴别器都提供一个“条件信息”,从而让生成器能够根据这个条件来生成指定类型的数据,鉴别器也能根据这个条件来判断数据的真实性。
类比:
- 普通 GAN: 你让画家画一幅画,他随机画,可能是山水,也可能是人物。
- Conditional GAN: 你告诉画家:“请画一幅有小船在湖上的山水画。” 画家会根据你的指令(条件)来画。同时,鉴赏家在判断这幅画好不好时,也会考虑到你给画家的指令,判断它是否符合“有小船在湖上的山水画”的条件。
这张图的构成与解释:
1. 顶部的抽象图:
x:代表条件信息(Condition)。它可以是任何形式的信息,比如一个文本描述、一个类别标签、另一张图片等。- Generator (生成器,绿色方块): 接收
x(条件信息) 和随机噪声(这里没有明确画出噪声,但通常是有的)。它根据x来生成一个数据y。所以,它生成的是y,但受x的控制。 - Discriminator (鉴别器,蓝色方块): 接收两部分信息:
- Real (x, y) pair: 真实的条件
x及其对应的真实数据y。 - Generated (x, y) pair: 生成器根据条件
x生成的假数据y,以及原始的条件x。
- Real (x, y) pair: 真实的条件
- 鉴别器根据
x来判断接收到的y是否是真实的。例如,它会判断“给定描述X,生成图片Y是否真实”。 - 最终,鉴别器输出 1(真实)或 0(虚假)。
2. 中间的具体示例图:
这个示例展示的是一个 Text-to-Image (文本到图像) 的 cGAN,即根据文本描述生成图像。
- 条件
x: 在这个例子中是文本描述,例如:“This flower has small, round violet petals with a dark purple center.” (这种花有小的、圆形的紫色花瓣,中间是深紫色。) φ(phi): 通常代表一个文本编码器(Text Encoder),它把原始文本(如上面的描述)转换成一个机器能理解的数值向量φ(t)。这个向量捕捉了文本的语义信息。
a) 生成器 Generator (G) 的工作流程:
- 输入:
z ~ N(0,1):一些从标准正态分布中采样的随机噪声。这保证了生成图像的多样性。φ(t):文本描述经过编码后的向量(条件信息)。
- 生成: 生成器
G将随机噪声z和条件向量φ(t)结合起来,生成一张图像x̂(x̂ := G(z, φ(t)))。- 注意: 图中的
x̂在这个上下文中代表生成的图像,而顶层抽象图中的y代表生成的数据。这里的x是条件,有点容易混淆,但整体逻辑是相同的:x作为条件,y作为基于x生成的数据。
- 注意: 图中的
- 结果: 生成器会试图生成一张真实且符合文本描述的假图像,例如图中显示的紫色花朵。
b) 鉴别器 Discriminator (D) 的工作流程:
- 输入:
- 真实对: 一张真实的图片,以及它对应的真实文本描述(编码后的
φ(t))。鉴别器会训练自己识别这些是“真实”的。 - 虚假对: 生成器生成的假图片
x̂,以及生成这张假图片时使用的文本描述(编码后的φ(t))。鉴别器会训练自己识别这些是“虚假”的。
- 真实对: 一张真实的图片,以及它对应的真实文本描述(编码后的
- 判断: 鉴别器
D接收图像(x或x̂)和条件向量φ(t)。它判断这对 (图像, 文本描述) 是真实配对还是虚假配对。- 例如,它会检查:这张图片看起来真实吗?并且,这张图片真的符合“有小的、圆形的紫色花瓣,中间是深紫色”这个描述吗?
- 输出: 鉴别器输出一个分数,表示它认为这对 (图像, 条件) 是真实的概率。
为什么引入 Conditional GAN?
- 可控性: 普通 GAN 只能随机生成,cGAN 允许我们控制生成内容的属性。例如,可以生成指定类别的图像、指定风格的文本、或者根据描述生成图片。这大大增加了 GAN 的实用性。
- 解决结构化学习问题: 这张幻灯片仍然在探讨“结构化学习的实践性”。cGAN 提供了一个很好的例子:
- 问题: 结构化学习常常需要我们根据输入
x来预测一个复杂的结构y。例如,根据文本x生成图片y。 - cGAN 如何解决? 通过训练一个生成器
G(x, z)来直接生成结构化数据y,并使用一个鉴别器D(x, y)来判断生成的y是否足够好(是否真实且符合x的条件)。 - 这种方法提供了一个学习复杂映射(从输入
x到结构化输出y)的框架,而不需要显式地设计复杂的损失函数或人工特征。鉴别器隐式地学习了衡量(x, y)对质量的“评价函数”,并驱动生成器去优化它。
- 问题: 结构化学习常常需要我们根据输入
所以,cGAN 在文本到图像、图像到图像转换(如风格迁移、图像修复)、语音合成等多种需要根据特定条件生成结构化数据的场景中非常有用。它展示了如何通过对抗学习的思想,来让模型学会生成复杂的、有条件的结构化输出。