MySQL索引事务
索引
通过索引可以对查询操作进行优化,通过减少全表扫描,快速定位数据,原本的查询操作是对表进行遍历,如果是大表效率较低
1)注意事项
- 占用了更多的空间,由于生成索引需要依赖于数据结构和额外数据,占用了硬盘空间
- 可能会影响到插入删除操作的效率
- 索引一般默认结构为B+树
- 常见的有:
自动创建的主键索引与外键索引
主动指定名字的索引 - 创建索引是危险操作,对大表创建索引可能会出现问题
对大表创建索引的合理操作:
另外再取一个机器,部署服务器。也创建同样的表,并且把表上的索引创建好
再把之前的机器上的数据给控制节奏的导入到新的服务器上
2)索引相关操作
- 查看索引
show index from tb_name;
- 创建索引
-- 单列索引
CREATE INDEX index_name ON table_name (column_name);-- 组合索引(多列索引)
CREATE INDEX index_name ON table_name (col1, col2, ...);
注意:
组合索引仅在查询操作包含col1时生效(最左前缀原则)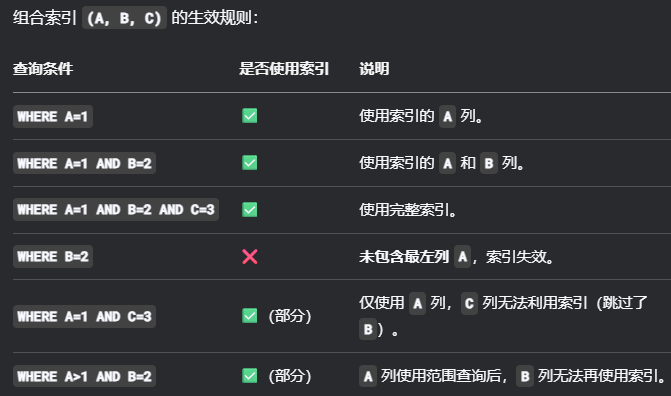
- 删除索引
drop index on tb_name;
注意:索引的删除仅能删除手动创建的索引
3)对B树与B+树的简单理解
1.B树
- 是一个N叉树
- 一个节点如果有M个键,那么它会有M+1个子节点
第1个子节点中的键值 < 当前节点的第1个键;
第2个子节点中的键值介于当前节点的第1个键和第2个键之间;
…
第M+1个子节点中的键值 > 当前节点的第M个键
[10 | 20 | 30] ← 节点存储键和数据/ | \ \
[5|8] [15|18] [25|28|] [31|35|...]
- 每个节点都存于硬盘不同区域硬盘IO开销大
2. B+树
- 是一个N叉树
- 一个节点如果有M个键,那么它会有M+1个子节点
- 第1个子节点中的键值 <= 当前节点的第1个键(即包含第一个键);
第2个子节点中的键值介于当前节点的第1个键和第2个键之间并包含第二个键;
…
第M个子节点中的键值 <= 当前节点的第M个键(包含第M个键) - 当达到最后一层时,叶子节点有着链表连接
[10 | 20 | 30] ← 节点存储键和数据/ | \
[5|8|10]→ [15|18|20] →[25|28|30]
- 非叶子节点仅存储键,单个节点可容纳更多键,树高度更低,减少磁盘访问次数
事务
事务用于确保数据操作的完整性和一致性。事务将一系列操作组合成一个不可分割的工作单元,保证这些操作要么全部成功提交,要么全部失败回滚。
1)事务的特性
-
原子性(Atomicity)
定义:事务中的所有操作要么全部完成,要么全部不执行。
实现方式:通过 Undo Log 等记录事务操作前的数据状态,若事务失败,根据日志回滚到初始状态(简单来说,可以类比Ctrl+Z的撤销操作,尝试能否执行事务,不能则撤销操作——回滚)
示例:转账操作中,A账户扣款和B账户入账必须同时成功或失败。 -
一致性(Consistency)
定义:事务执行后,数据库从一个有效状态转换到另一个有效状态,满足预定义的业务规则(如唯一约束、外键约束)。
依赖:原子性、隔离性和持久性共同保障一致性。
示例:转账后,A和B的总金额保持不变。 -
隔离性(Isolation)
定义:并发执行的事务之间互不干扰,每个事务感知不到其他事务的存在。
实现方式:通过锁机制或多版本并发控制(MVCC)实现。
隔离级别:读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)、串行化(Serializable)。 -
持久性(Durability)
定义:事务一旦提交,对数据的修改永久保存,即使系统崩溃也不丢失。
实现方式:通过 Redo Log 记录事务操作后的数据状态,确保数据持久化到磁盘。
注意:回滚指的是在事务执行中有错误时,可正确部分也回到未执行状态
2) 常见并发问题:
-
脏读(Dirty Read):读取到其他事务未提交的数据。
例子:你和小明同时操作数据库。
小明开始转账事务:从A账户转100元到B账户(A账户先扣100元,但事务还没提交)。
此时你读取A账户余额:发现A账户已经少了100元。
结果:小明突然反悔,回滚了事务,A账户恢复原金额。你看到的数据是假的!这就是脏读 -
不可重复读(Non-Repeatable Read):同一事务内多次读取同一数据,结果不同
例子:你和小明同时操作数据库。
你第一次查询A账户余额:显示500元。
小明提交了一个事务:给A账户加了100元,余额变成600元。你再次查询A账户余额:显示600元。
同一个事务中,两次查询结果不一致!这就是不可重复读。 -
幻读(Phantom Read):同一事务内多次查询同一范围,返回的行数不同(因其他事务插入/删除数据)。.
例子:你和小明同时操作数据库。
你第一次统计用户表,有10条数据。
小明插入了一条新用户数据并提交。
你再次统计用户表,发现变成了11条。
就像幻觉一样,数据凭空出现!这就是幻读
3)事务隔离级别
- 读未提交(Read Uncommitted)
定义:事务可以读取其他事务未提交的数据(“脏读”)
存在的问题:
脏读(Dirty Read)
不可重复读(Non-Repeatable Read)
幻读(Phantom Read) - 读已提交(Read Committed)
定义:事务只能读取其他事务已提交的数据
解决的问题:脏读
存在的问题:
不可重复读
幻读 - 可重复读(Repeatable Read)
定义:同一事务内多次读取同一数据的结果一致
解决的问题:脏读、不可重复读
存在的问题:幻读(但MySQL通过MVCC部分避免) - 串行化(Serializable)
定义:事务串行执行,完全避免并发问题
解决的问题:脏读、不可重复读、幻读
存在的问题:性能极低(通过严格加锁实现)
4)事务的语法
- 开启事务
BEGIN; -- 或 START TRANSACTION;
- 提交事务
COMMIT; -- 提交事务,持久化数据变更
- 事务回滚(MySQL中rollback许多时候可以隐式使用)
ROLLBACK; -- 回滚事务,撤销所有未提交的操作
以下情况需要显式调用

- 保存点
SAVEPOINT savepoint_name; -- 设置保存点
ROLLBACK TO savepoint_name; -- 回滚到指定保存点
RELEASE SAVEPOINT savepoint_name; -- 释放保存点
- 设置隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL isolation_level;
5)例子
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 隔离级别设于开始事务前
BEGIN;
-- 开始事务然后写要作为事务的SQL语句
UPDATE account SET balance = balance - 100 WHERE id = 1;
SAVEPOINT after_deduct; -- 可以设置保存点
UPDATE account SET balance = balance + 100 WHERE id = 2;
-- 若第二步失败,回滚到保存点,并非回滚到begin下第一个语句
ROLLBACK TO after_deduct; --显示调用rollback
COMMIT; --提交事务
6)注意事项
- 隔离级别越高事务执行效率越低,隔离级别越低事务执行效率越高
- 隔离级别越高事务的准确性越高
- BEGIN 是有效的,但更推荐使用 START TRANSACTION 开启事务
- 事务使用时,尽量始终显式提交或回滚事务,避免依赖隐式行为