DAY 33 简单的神经网络
- PyTorch和cuda的安装
- 查看显卡信息的命令行命令(cmd中使用)
- cuda的检查
- 简单神经网络的流程
- 数据预处理(归一化、转换成张量)
- 模型的定义
- 继承nn.Module类
- 定义每一个层
- 定义前向传播流程
- 定义损失函数和优化器
- 定义训练流程
- 可视化loss过程
预处理补充:
1. 分类任务中,若标签是整数(如 0/1/2 类别),需转为long类型(对应 PyTorch 的torch.long),否则交叉熵损失函数会报错。
2. 回归任务中,标签需转为float类型(如torch.float32)。
(一)PyTorch安装
PyTorch安装
安装PyTorch的CPU版本:
import torch
torch.cuda<module 'torch.cuda' from 'd:\\Anaconda\\envs\\DL\\lib\\site-packages\\torch\\cuda\\__init__.py'>(二)数据准备
- 划分数据集
# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 打印下尺寸
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)(120, 4)
(120,)
(30, 4)
(30,)- 对数据归一化
# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放
# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)(三)模型架构
定义一个简单的全连接神经网络模型,包含一个输入层、一个隐藏层和一个输出层。定义层数+定义前向传播顺序。
import torch
import torch.nn as nn
import torch.optim as optim
class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
model = MLP()(四)模型训练
# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 使用自适应学习率的化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值
losses = []for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')#此时可以同时观察每个epoch训练完后测试集的表现:测试集的loss和准确度。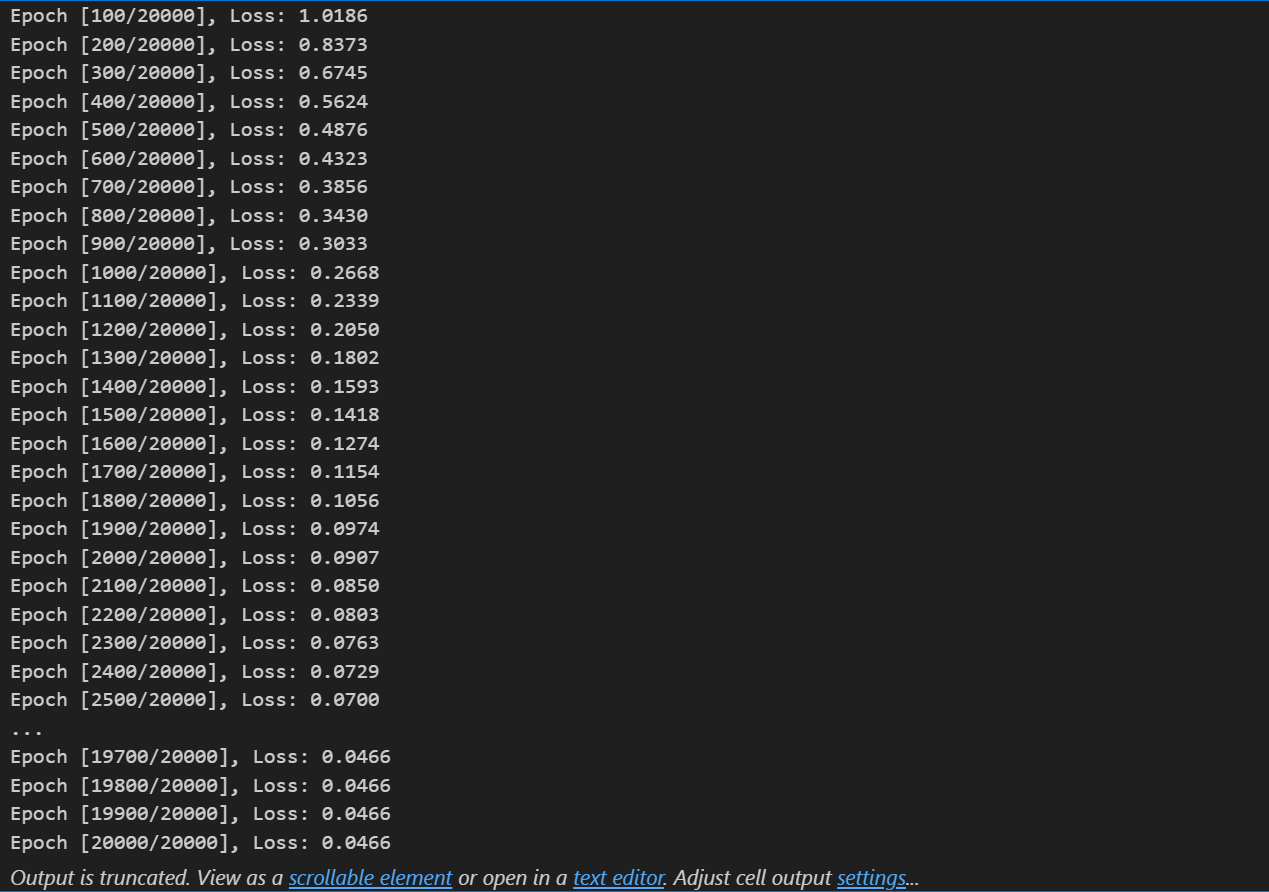
#若重新运行上面这段训练循环,模型参数、优化器状态和梯度会继续保留,导致训练结果叠加,模型参数和优化器状态(如动量、学习率等)不会被重置。这会导致训练从之前的状态继续,而不是从头开始
(五)可视化
!pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show() 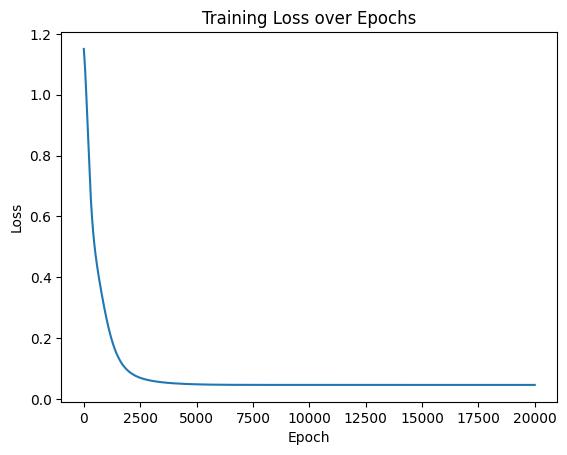
(六)总结和补充
-
Lasso回归
Lasso(Least Absolute Shrinkage and Selection Operator)是一种线性回归的改进方法,通过引入L1正则化(绝对值惩罚项)实现特征选择和防止过拟合。核心特点:
特征选择:通过将部分系数压缩到0,自动筛选重要特征
稀疏性:适用于高维数据,生成稀疏模型
超参数λ:控制正则化强度,λ越大模型越简单
-
多层感知机(MLP)模型
结构组成:输入层 → [隐藏层(激活函数)] × N → 输出层
多层感知机由输入层、一个或多个隐藏层以及输出层组成。每一层由多个神经元(也称为节点)构成,神经元之间通过带权重的连接进行信息传递。信息从输入层进入,依次经过各个隐藏层,最终在输出层产生输出结果。
- 输入层 :接收原始数据,输入层神经元的数量通常等于输入特征的维度。
- 隐藏层 :可以有一个或多个隐藏层,每个隐藏层包含若干神经元。隐藏层的作用是对输入数据进行非线性变换,从而学习到数据的复杂特征。
- 输出层 :输出模型的预测结果,输出层神经元的数量取决于具体的任务,例如分类任务中,神经元数量通常等于类别数
-
交叉熵损失函数criterion = nn.CrossEntropyLoss()
交叉熵(Cross-Entropy)信息论中的一个概念,原本用于衡量两个概率分布之间的差异。在机器学习的分类任务里,交叉熵损失函数用于衡量模型预测的概率分布与真实标签的概率分布之间的差异。模型训练的目标就是最小化这个差异,从而让模型的预测结果尽可能接近真实标签
交叉熵损失函数通过衡量预测分布与真实分布的差异,为分类模型提供了高效的优化目标。其核心优势在于:
-梯度特性良好,避免训练过程中梯度消失;
-与最大似然估计理论一致,具有清晰的概率解释;
-通过变种(如加权、焦点损失)可适应类别不平衡等复杂场景。
-
optimizer.zero_grad()梯度清零
PyTorch默认累积梯度,每次迭代需手动清零,否则梯度会叠加导致训练异常,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsize
-
神经网络基础
1. 梯度下降的思想
通过迭代更新模型参数,沿着损失函数梯度的反方向搜索最优解,使损失函数值最小化
2. 激活函数的作用
为神经网络引入非线性能力,使其能够拟合复杂的非线性映射关系。
| 函数 | 公式 | 优势 | 劣势 |
|---|---|---|---|
| ReLU | \(f(x) = \max(0, x)\) | 计算高效,缓解梯度消失 | 负区间输出恒为 0,可能导致神经元 “死亡” |
| Sigmoid | \(f(x) = \frac{1}{1+e^{-x}}\) | 输出概率值,适合二分类 | 梯度易消失,计算耗时 |
| Tanh | \(f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}\) | 输出对称,均值接近 0 | 梯度消失问题仍存在 |
3. 损失函数的作用
量化模型预测与真实标签的差异,为模型优化提供明确的优化目标,举例:
- 分类任务:交叉熵损失(衡量概率分布差异)。
- 回归任务:均方误差(MSE,衡量数值距离)。
- 生成任务:对抗损失(GAN 中判别器与生成器的博弈目标)。
4. 优化器
基于损失函数的梯度,实现参数更新策略的算法组件,是梯度下降思想的工程化实现。
| 优化器 | 核心策略 | 优势 | 适用场景 |
|---|---|---|---|
| SGD | 直接沿梯度反方向更新 | 实现简单,内存占用小 | 大规模数据,需调参 |
| Adam | 结合动量和自适应学习率 | 无需精细调参,收敛快 | 大多数场景默认选择 |
| Adagrad | 按历史梯度平方和调整学习率 | 适合稀疏特征 | 自然语言处理等稀疏数据 |
5. 神经网络的概念
由多层神经元(节点)相互连接构成的计算模型,通过模拟生物神经元的信息传递机制,实现对复杂数据的特征提取和模式识别。核心组成:
- 神经元:接收输入信号,通过加权求和与激活函数处理后输出
- 网络层:
- 输入层:接收原始数据(如图像像素值)。
- 隐藏层:通过多层非线性变换提取抽象特征(如 CNN 的卷积层、全连接层)。
- 输出层:生成预测结果(如分类任务的类别概率)。
- 连接方式:前向传播中,每层神经元的输出作为下一层的输入,反向传播时梯度沿连接权重传递。