RNN神经网络
RNN神经网络
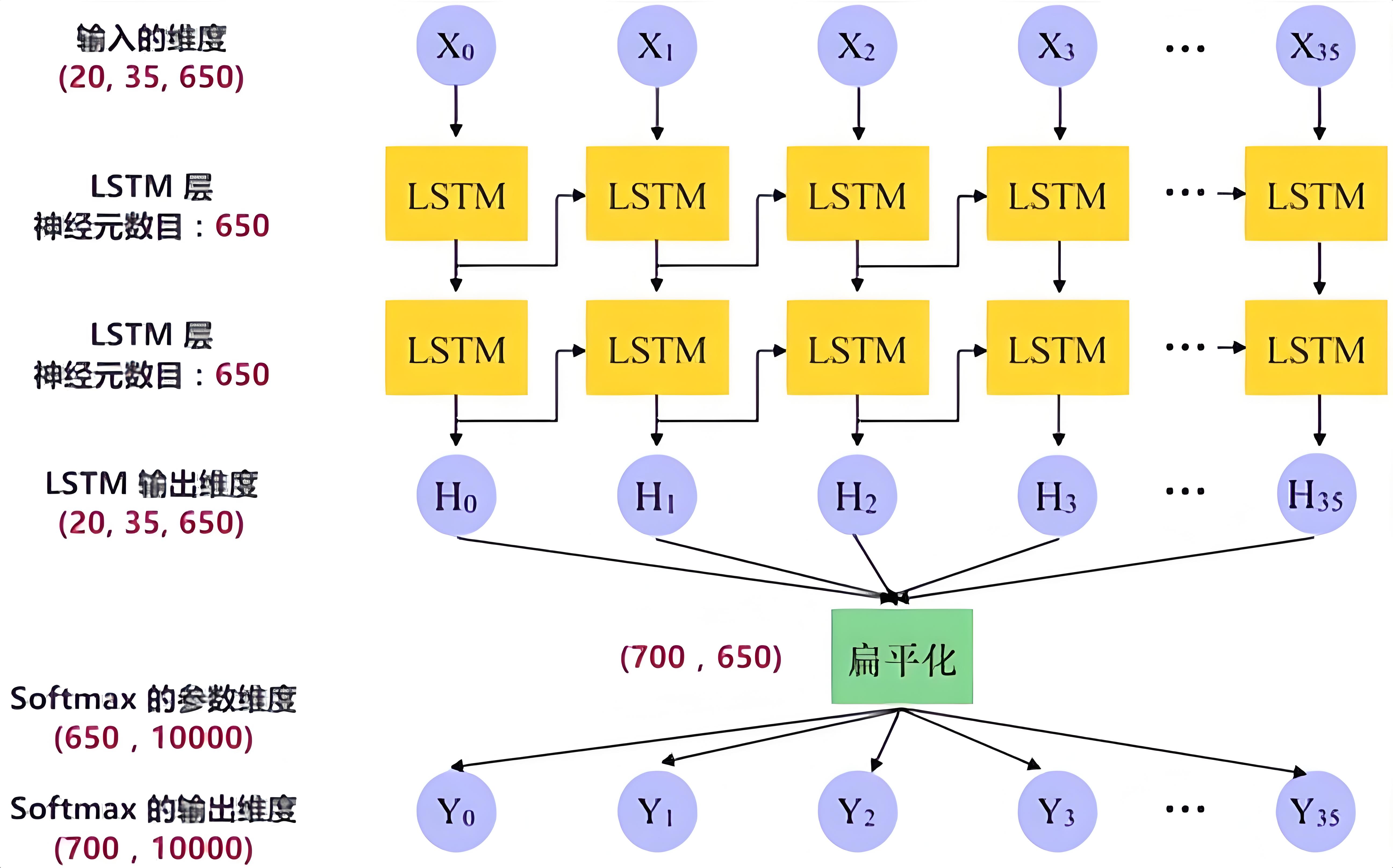
1-核心知识
- 1-解释RNN神经网络
- 2-RNN和传统的神经网络有什么区别?
- 3-RNN和LSTM有什么区别?
- 4-transformer的归一化有哪几种实现方式
2-知识问答
1-解释RNN神经网络
Why:与我何干?
在我们的生活中,很多事情是有先后顺序的,比如听一首歌,歌词是一句接一句的;看一部电影,情节是一幕接一幕的。如果能让计算机像我们一样理解这种顺序,就能更好地处理语言、音乐、视频等很多问题。RNN神经网络就是一种能让计算机处理这种顺序信息的工具,它可以用来做语音识别、翻译、写作助手等等,让机器更好地理解我们。
What:定义、概念解释,可以做什么
**RNN神经网络(Recurrent Neural Network)**是一种神经网络,它和普通的神经网络不一样,普通的神经网络是把输入直接变成输出,而RNN神经网络可以记住之前的信息,就像我们人类一样,会把之前看到的东西记在心里,然后用这些记忆来理解现在看到的东西。比如,你看到一个故事的前半部分,就会根据这些内容来理解后半部分。RNN神经网络也可以做到这一点,它能够处理像句子、时间序列数据(比如股票价格的变化)这样有先后顺序的信息。
How:步骤流程方法,以及解释所需的任何主题内容
RNN神经网络的工作方式有点像一个接力赛。想象一下,你和朋友们在接力赛中,每个人手里都拿着一个接力棒,这个接力棒就像RNN神经网络中的“记忆”。当一个新的信息(比如一个单词)进来的时候,RNN神经网络会把之前的记忆(也就是之前的接力棒)和这个新的信息结合起来,然后更新一下记忆,再把更新后的记忆传递给下一个时刻。这个过程会一直重复下去,就像接力赛一样,每一个时刻的输出都和之前的信息有关。
举个例子,假设你正在读一个故事,RNN神经网络就像是你在读这个故事的时候,每读到一个新的句子,就会把之前读到的内容(记忆)和这个新的句子结合起来,然后更新一下你对整个故事的理解。这样,当你读到后面的内容时,就能更好地理解整个故事的情节。
How good:可以给听众带来什么好处,什么改变
RNN神经网络的好处在于它能够处理有先后顺序的信息,这在很多实际应用中都非常有用。比如在语音识别中,它可以更好地理解语音中的单词顺序;在翻译中,它可以更好地理解句子的结构,从而翻译得更准确;在预测股票价格时,它可以利用之前的价格变化来预测未来的价格。通过这种方式,RNN神经网络让计算机能够更好地处理和理解我们生活中的各种顺序信息,让机器变得更加智能。
2-RNN和传统的神经网络有什么区别?
Why:与我何干?
了解RNN神经网络和传统神经网络的区别,可以帮助你更好地选择适合的工具来解决不同的问题。比如,如果你要处理像句子、视频、音乐这样有先后顺序的信息,RNN神经网络可能更适合;而如果你要处理像图片这样没有顺序关系的信息,传统神经网络可能就足够了。
What:定义、概念解释,可以做什么
- 传统神经网络(Feedforward Neural Network):这种神经网络就像一个工厂的流水线,信息从输入端进去,经过一层层的处理,最后从输出端出来。每一层的处理都是独立的,不会受到之前输入的影响。它主要用于处理没有先后顺序的信息,比如图片识别,因为图片的像素点之间没有先后顺序。
- RNN神经网络(Recurrent Neural Network):这种神经网络就像一个有记忆的人,它不仅能处理当前的信息,还能记住之前的信息,并用这些记忆来影响当前的处理结果。它主要用于处理有先后顺序的信息,比如句子、时间序列数据(股票价格变化)等。
How:步骤流程方法,以及解释所需的任何主题内容
我们用一个简单的例子来说明它们的区别:
- 传统神经网络:假设你在做一个水果分类的任务,输入是一张水果的图片,输出是这个水果的种类(比如苹果、香蕉)。传统神经网络会把这张图片的像素点输入进去,经过几层处理,最后输出这个水果的种类。它不会考虑之前输入的图片,每次都是独立处理。
- RNN神经网络:假设你在做一个语言翻译的任务,输入是一个句子,输出是这个句子的翻译。RNN神经网络会一个词一个词地处理这个句子,每处理一个词,它都会把之前处理的词的信息(记忆)用上。比如,它看到“我”这个词的时候,会记住这个信息;当它看到“喜欢”这个词的时候,它会结合之前“我”的信息来理解;当它看到“吃苹果”这个词的时候,它会结合前面“我”和“喜欢”的信息,最后输出翻译结果。这个过程中,RNN神经网络就像一个有记忆的人,能够利用之前的信息来更好地理解当前的信息。
How good:可以给听众带来什么好处,什么改变
了解这两种神经网络的区别,可以帮助你更好地选择适合的工具来解决问题。如果你的任务是处理像图片、表格这样没有先后顺序的信息,传统神经网络就足够了;而如果你的任务是处理像语言、视频、股票价格这样有先后顺序的信息,RNN神经网络会更有优势。这样,你就能更高效地解决问题,让机器更好地帮助你。
3-RNN和LSTM有什么区别?
好的,我来帮你理解RNN和LSTM的区别。
Why:与我何干?
RNN和LSTM都是用来处理有先后顺序信息的神经网络,比如语言、时间序列等。但它们在处理长距离依赖关系(比如句子中前面的单词对后面的单词的影响)时表现不同。了解它们的区别,可以帮助你选择更适合的工具来解决具体问题,比如在翻译、语音识别或者股票价格预测等任务中。
What:定义、概念解释,可以做什么
- RNN(Recurrent Neural Network):RNN是一种神经网络,它能够记住之前的信息,并用这些信息来处理当前的信息。比如,它可以把一个句子一个词一个词地处理,每处理一个词,就会结合之前词的信息来理解当前的词。
- LSTM(Long Short-Term Memory):LSTM是一种改进版的RNN。它专门用来解决RNN在处理长距离依赖关系时遇到的问题。比如,在一个很长的句子中,RNN可能会忘记句子开头的信息,而LSTM可以更好地记住这些信息,从而更好地理解整个句子。
How:步骤流程方法,以及解释所需的任何主题内容
我们用一个简单的例子来说明它们的区别:
- RNN:想象你在读一个很长的故事,RNN就像是一个记忆力有限的人。它一边读一边记,但读到后面的时候,可能会忘记前面的内容。比如,故事开头提到一个人物的名字,但读到后面的时候,RNN可能就忘了这个名字,导致理解后面的情节时出现困难。
- LSTM:LSTM就像是一个有超强记忆力的人。它也有记忆,但它有一个特殊的机制,可以决定哪些信息是重要的,需要长期记住;哪些信息是暂时的,可以忘记。比如,故事开头提到一个人物的名字,LSTM会记住这个名字,并在后面的情节中用到它。即使故事很长,LSTM也能很好地记住重要的信息,从而更好地理解整个故事。
具体来说,LSTM有一个复杂的结构,它有三个“门”(输入门、遗忘门、输出门):
- 输入门:决定哪些新信息需要加入到记忆中。
- 遗忘门:决定哪些旧信息需要忘记。
- 输出门:决定哪些信息需要输出。
通过这些“门”,LSTM可以更好地控制信息的流动,从而避免像RNN那样容易忘记重要信息的问题。
How good:可以给听众带来什么好处,什么改变
- RNN:优点是简单,计算速度快,适合处理比较短的序列信息。比如,处理一个很短的句子或者一小段时间序列数据。但它的缺点是容易忘记长距离的信息,这在处理长句子或者长序列数据时会成为一个问题。
- LSTM:优点是可以很好地处理长距离依赖关系,适合处理长句子、长序列数据。比如,在翻译、语音识别或者股票价格预测等任务中,LSTM可以更好地记住前面的信息,从而提高处理的准确性。但它的缺点是结构复杂,计算速度比RNN慢。
了解它们的区别后,你可以根据具体任务的需求来选择合适的工具。如果你的任务序列比较短,RNN可能就足够了;如果你的任务序列比较长,LSTM会是一个更好的选择。
4-transformer的归一化有哪几种实现方式
好的,我们来用费曼技巧来解释“Transformer 的归一化实现方式”,难度等级是 D=2。
Why(与我何干?)
在 Transformer 模型中,归一化是一种非常重要的操作。它可以帮助模型更好地学习和训练,避免数值不稳定的问题,就像给模型的输入数据“穿上了合适的鞋子”,让模型能够更平稳地“走路”。
What(定义、概念解释,可以做什么)
归一化(Normalization)是一种对数据进行处理的方法,它的目的是让数据的分布更加均匀,通常会把数据缩放到一个固定的范围内,比如 0 到 1 或者 -1 到 1。在 Transformer 模型中,归一化可以防止某些数值过大或过小,从而影响模型的训练效果。
How(步骤流程方法,以及解释所需的任何主题内容)
Transformer 中主要有以下几种归一化实现方式:
-
Layer Normalization(层归一化)
📐 解释:这是最常用的一种归一化方式。它对每一层的输入数据进行归一化处理。具体来说,它会计算每一层中每个样本的均值和标准差,然后用这些值对数据进行调整。
📝 步骤:- 计算每一层中每个样本的均值 (\mu) 和标准差 (\sigma)。
- 对每个样本的数据 (x) 进行归一化:(\hat{x} = \frac{x - \mu}{\sigma})。
- 通常还会引入两个可学习的参数 (\gamma) 和 (\beta),对归一化后的数据进行缩放和偏移:(y = \gamma \hat{x} + \beta)。
📚 例子:想象你有一堆不同大小的苹果,你希望它们的大小都差不多,所以你先算出这些苹果的平均大小和大小的波动范围,然后根据这些值调整每个苹果的大小,最后还可以根据需要把苹果放大或缩小一点。
-
Post-Normalization(后归一化)
📝 解释:这种归一化方式是在每一层的计算完成后再进行归一化。也就是说,先进行自注意力计算和前馈网络的计算,然后再对结果进行归一化。
📚 例子:就好像你先做完了所有的作业,然后最后再检查一遍,确保作业的质量。 -
Pre-Normalization(前归一化)
📝 解释:这种归一化方式是在每一层的计算之前先进行归一化。也就是说,先对输入数据进行归一化,然后再进行自注意力计算和前馈网络的计算。
📚 例子:就好像你先检查一下作业的格式和内容,确保没有问题后再开始写作业。 -
RMS Normalization(均方根归一化)
📐 解释:这是一种改进的归一化方法,它只使用数据的均方根值来进行归一化,而不是同时使用均值和标准差。这样可以避免某些情况下均值为零的情况,让归一化更加稳定。
📝 步骤:- 计算每一层中每个样本的均方根值 (\text{RMS}(x) = \sqrt{\frac{1}{n}\sum_{i=1}{n}x_i2})。
- 对每个样本的数据 (x) 进行归一化:(\hat{x} = \frac{x}{\text{RMS}(x)})。
📚 例子:想象你有一堆不同高度的积木,你希望它们的高度都差不多,所以你先算出这些积木高度的平方和的平均值,然后根据这个值调整每个积木的高度。
How Good(可以给听众带来什么好处,什么改变)
- 稳定训练:归一化可以防止数值不稳定,让模型训练更加平稳。
- 加速收敛:通过归一化,模型可以更快地找到最优解,就像给模型“加油”一样。
- 提高性能:合适的归一化方法可以让模型的性能更好,比如在翻译、分类等任务中表现得更准确。