【VLNs篇】05:TGS-在无地图室外环境中使用视觉语言模型进行轨迹生成和选择
| 栏目 | 内容 |
|---|---|
| 论文标题 | TGS: Trajectory Generation and Selection using Vision Language Models in Mapless Outdoor Environments (TGS:在无地图室外环境中使用视觉语言模型进行轨迹生成和选择) |
| 研究问题 | 在具有非结构化越野特征(如建筑物、草地、路缘)的挑战性真实世界无地图室外环境中进行导航。 |
| 研究目标 | 计算满足以下条件的合适轨迹:(1) 满足特定环境的可通行性约束;(2) 在人行横道、人行道等区域导航时,符合类似人类的路径。 |
| 核心方法 | 多模态轨迹生成与选择算法 (TGS): 1. 轨迹生成: 使用一个以可通行性约束增强的条件变分自编码器 (CVAE) 生成模型 (基于MTG),根据LiDAR几何感知生成多个候选轨迹。 2. 轨迹选择: 利用视觉语言模型 (VLM) 及其零样本语义理解和逻辑推理能力,结合视觉提示方法(在RGB图像上用线条和数字标记候选轨迹),根据任务的上下文信息选择最佳轨迹。 |
| 创新点 | 1. 集成多模态方法:将基于CVAE的几何感知轨迹生成(LiDAR)与基于VLM的语义感知轨迹选择(RGB图像+语言)相结合。 2. 视觉提示增强VLM空间推理:通过在图像上标记候选轨迹(线条和数字),帮助VLM理解空间信息并进行选择,弥合了VLM与精确空间输出之间的差距。 3. 高质量候选轨迹生成:CVAE生成多样化且几何上可行的候选轨迹,为VLM选择提供了坚实基础,优于随机采样。 |
| 主要贡献 | 1. 提出TGS,一个新颖的集成轨迹生成和选择方法。 2. 探索了视觉提示方法在轨迹选择中增强VLM空间推理能力的应用。 3. 在多个挑战性室外场景中评估了TGS,证明了其有效性。 |
| 关键结果 | 在挑战性室外导航场景(如人行道、人行横道等)中,与基线方法相比,生成的轨迹在可通行性方面至少提高了 3.35%,在类人导航(以弗雷歇距离衡量)方面至少提高了 20.61%。 |
具体实现流程
该论文提出的TGS(Trajectory Generation and Selection)算法流程如下:
阶段一:基于几何的候选轨迹生成 (使用MTG)
- 输入:
- 连续几帧的LiDAR点云数据 ( o l o_l ol)
- 机器人当前速度 ( o v o_v ov)
- 处理:
- 将LiDAR点云和机器人速度输入到一个基于注意力机制的条件变分自编码器 (CVAE) 模型 (即MTG [24])。
- CVAE模型会生成一组 ( K K K条) 多样化的、在几何上(基于LiDAR感知)可能 traversable 的候选轨迹 ( T = { T 1 , T 2 , . . . , T K } T = \{T_1, T_2, ..., T_K\} T={T1,T2,...,TK})。这些轨迹通常长度约为15米。
- 输出 (阶段一):
- 一组候选轨迹 ( T T T)。
阶段二:基于视觉语言模型的轨迹选择
-
预处理与视觉标记:
- 轨迹筛选 (可选/隐含): 使用Hausdorff距离过滤掉彼此过于接近的轨迹,保留具有代表性的轨迹子集 T ′ T' T′。
- 坐标转换: 将候选轨迹 ( T ′ T' T′) 从机器人坐标系转换到相机坐标系,再投影到2D图像平面上,得到图像平面上的轨迹 T c T_c Tc。
- 视觉标记 (Visual Marking Module, M M M):
- 输入: 当前机器人视角的RGB图像 ( i i i),图像平面上的候选轨迹 ( T c T_c Tc)。
- 处理: 在RGB图像 ( i i i) 上,将每条候选轨迹 T c , k T_{c,k} Tc,k 用线条绘制出来。在每条绘制轨迹的末端,用一个数字 ( n k n_k nk) 进行标记。数字通常按某种启发式(如与目标方向的接近程度)排序,较小的数字可能表示更优的初步选择。
- 输出: 带有视觉标记(线条和数字)的RGB图像 ( i ′ i' i′)。
-
VLM选择:
- 输入:
- 带标记的RGB图像 ( i ′ i' i′)。
- 语言提示 ( l l l):包含导航任务的指令,例如:“选择一条我应该遵循的安全导航路径,就像人类那样。记住我必须走在人行道上,避开崎岖不平的地形,并遵守规则。我不能越过/钻过路缘。数字越小表示到达目标的最短路径。只选一个。请按以下格式提供答案:{‘trajectory’: []}”。
- 处理:
- 将带标记的图像 ( i ′ i' i′) 和语言提示 ( l l l) 一同输入到预训练的视觉语言模型 (VLM),例如GPT-4V。
- VLM利用其对图像内容的语义理解能力(例如识别道路、人行道、障碍物)和对文本指令的逻辑推理能力,分析图像上标记的各条候选轨迹。
- VLM根据语义可行性(是否在人行道上、是否避开障碍物、是否遵守交通规则如走人行横道等)和提示中关于目标方向的指引(通过数字大小暗示),选择最合适的轨迹对应的数字。
- 输出 (阶段二):
- 选定的最佳轨迹 ( τ \tau τ)(由VLM选择的数字所对应的原始轨迹)。
- 输入:
最终输出:
- 一条经过VLM根据几何和语义信息筛选出的、被认为是当前最佳的导航轨迹 ( τ \tau τ)。这条轨迹随后可以被底层的运动规划器和控制器用于驱动机器人实际移动。
数据流转逻辑总结:
LiDAR/速度 → MTG (CVAE) \xrightarrow{\text{MTG (CVAE)}} MTG (CVAE) 多条候选轨迹 (几何) → 投影+视觉标记 \xrightarrow{\text{投影+视觉标记}} 投影+视觉标记 带标记的RGB图像 → VLM + 语言提示 \xrightarrow{\text{VLM + 语言提示}} VLM + 语言提示 单条最佳轨迹 (几何+语义)。
核心思想: 利用LiDAR的几何精确性生成多个“可能”的路径,然后利用VLM强大的场景理解和推理能力,结合视觉提示,从这些路径中选出“最应该”走的那一条,从而实现更智能、更符合人类习惯的导航。
文章目录
- 1 引言
- 2 相关工作
- 3 方法
- 3.1 问题定义
- 3.2 基于几何的轨迹生成
- 3.3 基于VLM的轨迹选择
- 4 实验结果
- 4.1 实现细节
- 4.2 定性结果
- 4.3 定量结果
- 4.4 消融研究
- 5 结论、局限性和未来工作
摘要 我们提出了一种多模态轨迹生成和选择算法,用于在具有挑战性的现实世界无地图室外导航场景中,处理如建筑物、草地和路缘等非结构化越野特征。我们的目标是计算合适的轨迹,这些轨迹 (1) 满足特定环境的可通行性约束,并且 (2) 在人行横道、人行道等区域导航时符合类似人类的路径。我们的方法使用一个条件变分自编码器 (CVAE) 生成模型,该模型通过可通行性约束进行增强,以生成多个全局导航的候选轨迹。我们利用视觉语言模型 (VLM) 及其在语义理解和逻辑推理方面的零样本能力,结合视觉提示方法,根据任务的上下文信息选择最佳轨迹。我们在各种室外场景中使用轮式机器人评估了我们的方法,并将其性能与其他全局导航算法进行了比较。实践中,我们观察到,在挑战性的室外导航场景(如人行道、人行横道等)中,生成的轨迹在可通行性方面至少提高了3.35%,在类人导航方面提高了20.61%。
关键词: 运动规划,人工智能赋能机器人,机器人算法
1 引言
无地图导航用于计算机器人在没有精确地图的情况下导航大规模环境的轨迹或方向 [15,23,37]。这个问题对于室外全局导航非常重要。与基于地图的方法 [13,14,32](需要准确且广泛的全局地图)不同,无地图技术 [24,26,37] 不需要维护准确的地图,并且能够适应频繁变化的环境 [45],包括天气变化 [31,50]、临时建筑工地 [20] 和危险区域 [10]。然而,由于可通行性分析和场景理解(就导航和社交协议而言)的挑战,无地图全局导航可能具有挑战性 [15,37]。
传统的基于地图的方法 [9,11] 和基于学习的方法 [24,25,39,43] 通常依赖于高程等属性来分析可通行性。
然而,这些属性可能不适用于所有类型的机器人,例如,楼梯对于有腿机器人是可通行的,但对于轮式机器人则不是 [11, 43]。为了应对这些挑战,可以使用多模态传感器来更好地理解场景。具体来说,LiDAR 传感器提供关于环境的几何信息,可用于处理碰撞 [25, 27],但很难使用 LiDAR 来检测颜色不同但几何属性相似的地形,例如高程 [24]。RGB 相机也可用于场景理解 [22, 33, 36, 46]。因此,使用多种模态来捕获几何和颜色信息对于可通行性分析是必要的。
考虑到机器人需要做出类似人类的决策以遵循某些社交协议并找到到达目标的更短路径,场景理解对于室外导航至关重要。场景理解具有挑战性,因为所需信息在不同环境中差异很大。例如,越野导航需要对非结构化植被进行特征理解,以判断机器人是否可以穿越 [28, 44],而社交导航任务 [16,42] 则需要信息来遵循社交线索。因此,对于特定类型的机器人、社交互动以及导致死胡同的方向,通用场景理解(就可通行性而言)至关重要。许多当前方法 [21, 44, 49] 依赖于分割或分类 [6, 22],但这些方法需要使用地面真实数据进行大量训练,并且仅限于标记数据集。这种限制阻碍了它们推广到具有复杂地形和社交约束的场景的能力。大型语言模型 (LLM) 和视觉语言模型 (VLM) 的最新进展已在各种任务中展示了卓越的能力,包括逻辑推理 [4,7,17] 和视觉理解 [2,8,33]。特别是 VLM 具有处理和理解视觉和文本信息的能力,这使其能够执行广泛的多模态任务。最近,VLM 已被用于通过图像和上下文线索理解周围环境,从而在室外场景中自主导航机器人 [12, 12, 19,38]。然而,一个挑战是 VLM 不能直接提供精确的空间几何输出 [38,42]。
主要成果: 我们提出了 TGS,一种新颖的多模态方法,用于无地图室外导航中的轨迹生成和选择。我们的方法利用 RGB 颜色和 LiDAR 几何信息进行可通行性分析。我们使用基于模型的轨迹生成方法,根据 LiDAR 几何感知生成多个候选轨迹。我们还使用 VLM 基于 RGB 颜色模态进行场景理解。虽然 VLM 无法提供精确的空间输出,我们使用视觉注释来帮助它们从一组离散的粗略选择中进行选择 [30, 40, 47]。我们还使用 VLM 做出类似人类的决策,以便在全局导航的候选项中选择合适的轨迹,即生成可在人行横道上通行、符合社交规范且更接近目标的轨迹。我们展示了我们的方法在复杂室外场景中的有效性,这些场景包括多样化的非结构化环境和导航约束,例如在过马路时行驶。
例如过马路时走人行横道、绕过建筑物等。我们工作的主要贡献包括:
- 一种新颖的集成轨迹生成和选择方法 TGS,使用基于 CVAE [41] 的方法生成多个候选轨迹,并使用 VLM 和视觉提示方法选择最合适的轨迹。我们基于 CVAE 的轨迹生成方法会生成多个候选轨迹,这些轨迹在考虑从 LiDAR 传感器检索到的几何信息的情况下是可通行的。我们基于 VLM 的轨迹选择方法会选择最佳轨迹,该轨迹在几何和语义上均可通行,并且最接近目标。
- 我们探索了使用视觉提示方法来增强 VLM 在轨迹选择方面的空间推理能力。通过在 RGB 图像中加入线条和数字指示符等视觉标记,我们为 VLM 提供了明确的指导。这有助于弥合 LiDAR 数据的具体几何信息与 VLM 提供的上下文理解之间的差距。
- 我们在四个不同的具有挑战性的室外场景中评估 TGS。我们测量了相对于人类遥操作的可通行率和弗雷歇距离。我们将结果与最先进的轨迹生成方法 ViNT [39]、NoMaD [43]、MTG [24] 和 CONVOI [34] 进行了比较。我们观察到,在可通行性方面至少提高了 3.35%,在弗雷歇距离方面提高了 20.61%。我们还定性地展示了我们的方法相对于其他方法的优势。
2 相关工作
在本节中,我们回顾了室外机器人导航的相关工作,特别关注轨迹生成。
室外无地图全局导航: 基于强化学习的运动规划方法 [18, 25] 使用端到端结构来获取观测并生成动作或轨迹。然而,这些方法是为短程导航设计的,并且基于策略的强化学习方法也存在现实差距问题。使用路径规划的地图重建方法 [35,48] 通过在导航期间构建地图为全局规划提供了一种解决方案,但这些方法需要大量的全局地图内存。为了解决这个问题,NoMaD [43] 和 ViNT [39] 使用拓扑地图来减少导航的内存使用,但这些方法需要预定义拓扑节点,使其不适用于完全未知的环境。为了克服这些限制,我们的方法使用基于 CVAE 生成模型的轨迹生成方法 [24] 来生成长轨迹,并利用 VLM 来选择到达目标的最佳轨迹。
可通行性分析: 一些方法为可通行性分析构建局部地图 [9,11],但这些方法需要大量的计算资源 [11],并且这些地图仍然需要与运动规划算法相结合以生成运动或轨迹。基于学习的方法通过直接生成轨迹 [24-26, 39, 43] 为可通行性分析提供了一种端到端的解决方案。然而,这些方法要么生成基于特定类型机器人(即机器人动力学)可通行的轨迹,要么缺乏对环境的常识性理解,这限制了它们的有效性。我们的方法利用视觉语言模型 (VLM) 来提供常识性的场景理解,例如识别交通标志、人行横道和路缘。
导航中的语言基础模型: 语言基础模型 (LFM) [5](包括 VLM 和 LLM)的最新突破展示了其在机器人导航方面的巨大潜力。LM-Nav [38] 使用 GPT-3 和 CLIP [33] 从基于文本的导航指令中提取地标描述,并在图像中进行定位,有效地引导机器人在室外环境中到达目标。VLMaps [19] 通过将视觉语言特征与 3D 地图融合,提出了一种空间地图表示方法,从而实现了自然语言引导的导航。CoW [12] 通过结合基于 CLIP 的地图和传统的探索方法,执行基于零样本语言的对象导航。现有研究主要集中于利用 VLM 提取文本-图像场景表示,这主要用于高级导航指导。其他使用 VLM 进行上下文和语义理解以指导低级导航行为的方法也已被提出。VLM-Social-Nav [42] 探索了 VLM 在与人类等社交实体互动时提取符合社交规范的导航行为的能力。CoNVOI [34] 使用视觉注释从机器人视角图像中提取一系列航点,这些航点显示了给定场景下最合适的导航行为。PIVOT [30] 在包括室内导航在内的各种低级机器人控制任务中使用了 VLM 的视觉提示和优化。它展示了视觉提示方法在机器人和空间推理领域中对 VLM 的潜力。
我们的工作建立在这些方法的基础上,利用 VLM 来指导低级导航行为,理解周围环境的上下文和语义信息。在这里,我们使用诸如线条和数字之类的视觉注释 [29, 30, 34, 40, 47] 来帮助 VLM 有效地理解空间信息。与 PIVOT [30] 中那样随机采样候选者不同,我们使用基于生成模型的轨迹生成方法来产生高质量但多样化的轨迹,确保 VLM 从中选择的轨迹具有可通行性。
3 方法
在本节中,我们阐述了无地图全局导航问题并描述了我们的方法。
3.1 问题定义
我们的方法处理无地图全局导航问题。为了有效利用多模态传感器输入,我们设计了一个两阶段流程,如图所示。
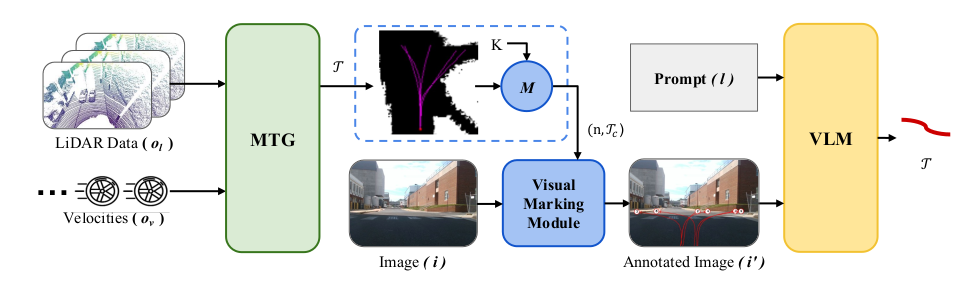
图1,以选择在可通行性和类人决策方面最佳的轨迹。给定一个长距离(约200米)目标 g ∈ O g g \in O_g g∈Og,我们利用颜色和几何模态来生成全局导航的轨迹 T T T。该轨迹旨在提供到达目标的最佳方向,避免死胡同,并满足场景的可通行性约束,即最大化 P ( o , g , l ) P(o, g, l) P(o,g,l),其中 o = { o l , o v , i } o = \{o_l, o_v, i\} o={ol,ov,i} 表示机器人的观测值。 o l ∈ O l o_l \in O_l ol∈Ol 表示 LiDAR 观测值, o v ∈ O v o_v \in O_v ov∈Ov 表示机器人速度, i ∈ I i \in I i∈I 表示来自相机的 RGB 图像。 l = { l t , l d } l = \{l_t, l_d\} l={lt,ld} 表示用于视觉语言模型 (VLM) 的语言指令,以获取可通行轨迹 ( l t l_t lt) 和到达目标的最佳方向 ( l d l_d ld),同时避免死胡同。
首先,我们利用 MTG [24] 来处理来自 LiDAR 传感器的几何信息 o l ∈ O l o_l \in O_l ol∈Ol 和来自机器人里程计的连续速度 o v ∈ O v o_v \in O_v ov∈Ov。MTG 有效地生成一组位于几何可通行区域的轨迹, T = MTG ( o l , o v ) T = \text{MTG}(o_l, o_v) T=MTG(ol,ov)。这些生成的轨迹无法处理几何相似但颜色语义不同的情况,例如路缘和草坪。因此,我们使用 VLM 从 RGB 图像中提供场景理解。
然而,在真实世界的航点和 VLM 之间存在差距,VLM 仅接受图像和文本标记。弥合这一差距的一种方法是将轨迹叠加在图像上,并使用 VLM 分析轨迹是否在可通行区域。考虑到 VLM 可以从图像中理解常识,我们使用数字来指示轨迹,将这些数字放置在图像上每个轨迹的末端,以便为 VLM 提供关于轨迹稀疏方向的更好感知。因此,我们通过以下方式将真实世界的轨迹映射到图像像素级对象:
( n , T c ) = M ( T , K ) , (n, T_c) = M(T, K), (n,Tc)=M(T,K),
其中 K K K 表示从真实世界 LiDAR 坐标系到图像平面的转换矩阵, T c T_c Tc 表示转换后的轨迹, n ∈ N n \in N n∈N 是对应于每个轨迹的数字。
给定语言指令 l t ∈ L l_t \in L lt∈L 和带有转换后轨迹 T c T_c Tc 及数字 n ∈ N n \in N n∈N 的图像 i ∈ I i \in I i∈I,VLM 基于场景的颜色语义理解提供一条可通行的轨迹, T s = VLM ( l t , i , T c , n ) T_s = \text{VLM}(l_t, i, T_c, n) Ts=VLM(lt,i,Tc,n),其中 T s ∈ A T_s \in A Ts∈A 且 A A A 表示图像 i i i 中的颜色语义可通行区域。此外,所选轨迹不一定是导航的最佳选择,因此我们使用 l d l_d ld 语言提示来提供目标方向,并要求 VLM 在给定轨迹 T s T_s Ts 中选择最佳轨迹。通过结合 l d l_d ld 和 l t l_t lt,我们最大化 max P ( T ∣ l , i , T c , n ) \max P(T|l, i, T_c, n) maxP(T∣l,i,Tc,n)。因此,问题定义为:
max P ( T ∣ l , i , T c , n ) , ( 1 ) \max P(T|l, i, T_c, n), \quad (1) maxP(T∣l,i,Tc,n),(1)
其中 ( n , T c ) = M ( MTG ( o l , o v ) , K ) . ( 2 ) \text{其中 } (n, T_c) = M(\text{MTG}(o_l, o_v), K). \quad (2) 其中 (n,Tc)=M(MTG(ol,ov),K).(2)
3.2 基于几何的轨迹生成
轨迹集 T T T 由 MTG [24] 生成,它使用条件变分自编码器 (CVAE) 来生成具有相关置信度的轨迹。对于每个观测 { o l , o v } \{o_l, o_v\} {ol,ov},我们为 CVAE 解码器计算条件值 c = f c ( o l , o v ) c = f_c(o_l, o_v) c=fc(ol,ov),其中 f c ( ⋅ ) f_c(\cdot) fc(⋅) 表示感知编码器。然后从 c c c 计算嵌入向量 z = f z ( c ) z = f_z(c) z=fz(c),其中 f z ( ⋅ ) f_z(\cdot) fz(⋅) 表示一个神经网络。
由于解码器设计为用一个嵌入向量生成一条轨迹,因此生成多个不同轨迹需要具有代表性和多样性的嵌入向量。我们通过基于条件 c c c 的线性变换将嵌入向量 z z z 投影到不同的轴上,如公式3所示:
z k = A i ( c ) z + b i ( c ) = h ψ i ( z ) , ( 3 ) z_k = A_i(c)z + b_i(c) = h_{\psi_i}(z), \quad (3) zk=Ai(c)z+bi(c)=hψi(z),(3)
其中 h ψ i h_{\psi_i} hψi 表示 z z z 的线性变换。使用每个嵌入向量 z k z_k zk,解码器生成一条轨迹 T k T_k Tk,如公式4所述,其中 T k ∈ T T_k \in T Tk∈T, z k z_k zk 和 Z ˉ k \bar{Z}_k Zˉk 分别是当前轨迹和其他轨迹嵌入集的嵌入向量。
p ( T k ∣ c ) = ∫ Z k P ( T k ∣ z k , c , Z ˉ k ) d z k . ( 4 ) p(T_k|c) = \int_{Z_k} P(T_k|z_k, c, \bar{Z}_k) dz_k. \quad (4) p(Tk∣c)=∫ZkP(Tk∣zk,c,Zˉk)dzk.(4)
3.3 基于VLM的轨迹选择
如算法1所示,生成的轨迹 T T T 是从最近的连续 t = 2 t=2 t=2 个时间步获得的。给定收集到的轨迹 T T T,我们将其转换为带有数字的图像平面:
( n , T c ) = M ( T , K , T c ) . ( 5 ) (n, T_c) = M(T, K, T_c). \quad (5) (n,Tc)=M(T,K,Tc).(5)
其中 T 0 T_0 T0 表示相机坐标系和机器人坐标系之间的外参变换。
考虑到从连续时间步生成的轨迹可能彼此非常接近,我们仅根据所有轨迹之间的 Hausdorff 距离从 T ′ ⊂ T T' \subset T T′⊂T 中选择代表性轨迹:
∀ T n , T m ∈ T ′ , d h ( T n , T m ) > d t , 其中 n ≠ m , ( 6 ) \forall T_n, T_m \in T', d_h(T_n, T_m) > d_t, \text{其中 } n \neq m, \quad (6) ∀Tn,Tm∈T′,dh(Tn,Tm)>dt,其中 n=m,(6)
其中 d h ( ⋅ , ⋅ ) d_h(\cdot, \cdot) dh(⋅,⋅) 表示 Hausdorff 距离, d t d_t dt 表示距离阈值。
然后我们将轨迹 T ′ T' T′ 从机器人坐标系投影到相机坐标系, T r = P t ( T ′ , T c ) T_r = P_t(T', T_c) Tr=Pt(T′,Tc)。随后将轨迹投影到相机图像平面 T c ′ = P c ( T r , K ) T_c' = P_c(T_r, K) Tc′=Pc(Tr,K),其中 K K K 是相机的内参矩阵。按照轨迹生成序列,我们用数字 n n n 标注轨迹。
最后,将标注的轨迹 ( n , T c ) (n, T_c) (n,Tc) 和当前观测图像 i i i 输入到视觉语言模型 (VLM) 中,并使用提示指令 l l l 来选择在可通行性和到达目标的行驶距离方面最佳的轨迹:
τ = VLMs ( l , i , T c , n ) . ( 7 ) \tau = \text{VLMs}(l, i, T_c, n). \quad (7) τ=VLMs(l,i,Tc,n).(7)
提示指令的格式如下:

4 实验结果
在本节中,我们讨论我们方法的实现细节、定性结果、定量结果和消融研究。
4.1 实现细节
我们的方法在一个配备 Velodyne VLP16 LiDAR、Realsense D435i 和一台带有 Intel i7 CPU 及 Nvidia GeForce RTX 2080 GPU 的笔记本电脑的 Clearpath Husky 上进行测试。我们使用 MTG [24],它集成了带有注意力机制的 CVAE 以生成多个轨迹,并使用 GPT-4V [1] 作为 VLM 来选择最佳的可通行轨迹。TGS 在每次迭代中生成大约 15 米的轨迹。
我们用于 CVAE 轨迹生成模型的训练数据集包含三个部分:1) LiDAR 点云和机器人速度,2) 二进制可通行性地图,以及 3) 随机生成的不同目标和最短地面真实轨迹以到达目标。可通行性地图是基于 LiDAR 点构建的,然后我们手动编辑难以用 LiDAR 检测的区域。该地图仅用于训练和评估。

为了验证 TGS,我们展示了与 MTG [24](使用启发式方法,选择到目标最短行驶距离的轨迹)、ViNT [39]、NoMaD [43] 和 CoNVOI [34] 相比的定性和定量结果。为了评估,我们随机选择了 MTG 和 TGS 在前方 50 米内的目标。ViNT、NoMaD 和 CoNVOI 不考虑到达目标的最优性。MTG 仅将 LiDAR 作为输入,而 ViNT 和 NoMaD 仅将 RGB 图像作为输入。CoNVOI 采用与我们类似的方法,将 LiDAR 作为输入以在 RGB 图像中标记数字,并使用这些带注释的图像作为 VLM 的输入来生成轨迹。我们设置了以下四个具有挑战性的基准场景:
- 花坛 (Flower bed): 机器人在花坛旁边的铺砌区域导航。机器人必须停留在铺砌路径上并避开花坛。由矮草组成的开放式花坛很难用 LiDAR 检测。
- 路缘 (Curb): 机器人在人行道上导航,人行道通过路缘与车行道明显分开。机器人必须停留在人行道上。由于人行道和车行道对于轮式机器人来说都可被认为是可通行的,因此在没有周围环境上下文的情况下选择可通行的轨迹具有挑战性。
- 人行横道 (Crosswalk): 机器人在斑马线上过马路。机器人在过马路时必须停留在人行横道上。考虑到上下文,选择铺设在人行横道上的可通行轨迹很困难。
- 拐角处 (Around the corner): 机器人朝向拐角处的目标导航。机器人必须绕过拐角,而不是走向死胡同。在不理解环境空间上下文的情况下,很难避免这样的死胡同。
4.2 定性结果
图2显示了四种不同方法在四种不同场景下的最终机器人轨迹。上面一行显示了包括我们在内的所有比较方法生成的轨迹,下面一行显示了使用TGS的候选轨迹和最终选择的轨迹。我们证明了我们的方法可以生成并选择一条在几何和语义上都可行的远程轨迹。
像ViNT [39]和NoMaD [43]这样的基于视觉的导航方法,依赖于将当前图像与预先录制的子目标图像进行比较。这些方法在沿着具有显著视觉特征的直线路径(尤其是在人行横道场景中)方面是成功的。然而,这些方法在有转弯的场景中通常难以生成可行的轨迹。在场景发生重大变化的情况下,准确性会显著下降。带有启发式算法的MTG会选择最接近目标点的轨迹,这通常会导致路径可能不遵循人行道和人行横道。在目标点位于弯道后或结构物后面的角落情况下,MTG往往会尝试直接穿过,而不是有效地绕过结构物,从而导致失败。CONVOI生成的轨迹在几何和语义上都是可行的。然而,这些轨迹是连接两个航点的直线,相对较短,可能导致机器人动作不平滑。如图2中每个场景的底部行所示,我们的方法产生多样化的轨迹,并选择那些考虑周围环境上下文的轨迹。
4.3 定量结果
为了进一步验证TGS,我们使用两种不同的指标评估这些方法:
-
可通行性 (Traversability): 生成的轨迹位于可通行区域的比率。该指标计算公式为:
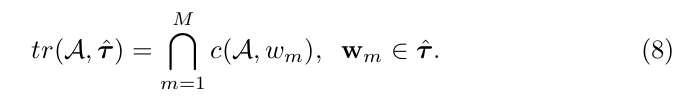
其中 c ( ⋅ ) c(\cdot) c(⋅) 判断航点 w m w_m wm 是否在可通行区域 A A A 内。
-
相对于人类遥操作的弗雷歇距离 (Fréchet Distance w.r.t. Human Teleoperation): 弗雷歇距离 [3] 是衡量两条曲线相似性的指标之一。我们测量由这些方法生成和选择的轨迹与人类遥操作轨迹之间的相似性。较低的距离表示较高的相似度。
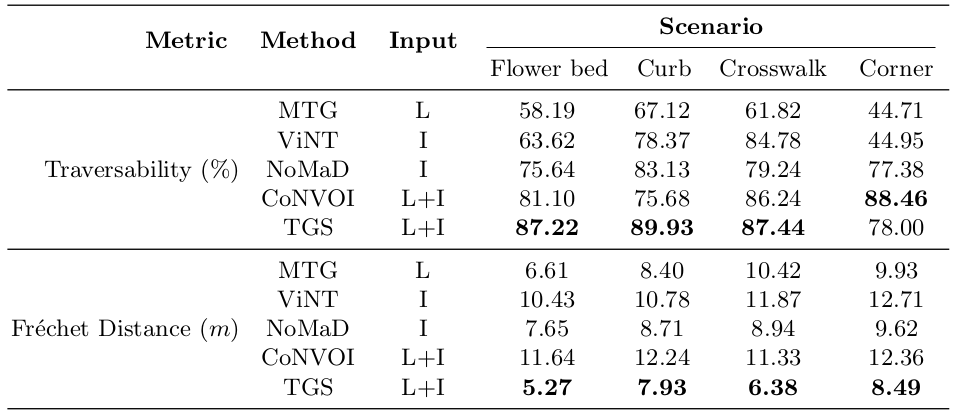
表1报告了每种方法和场景在100帧上的平均结果。结果表明,TGS在大多数情况下优于其他SOTA方法。具体而言,我们在平均可通行性方面实现了至少3.35%和至多47.74%的改进率,在平均弗雷歇距离方面实现了至少20.61%和至多40.98%的改进率。总体而言,平均改进
在可通行性方面的比率约为22.07%,在弗雷歇距离方面约为30.53%。CONVOI在可通行性方面取得了可比较的结果。然而,这是因为CONVOI计算的轨迹相对较短,这意味着航点落在不可通行区域的可能性要小得多。我们观察到,因为CONVOI只考虑两个航点的可通行性,而不考虑线性连接这两个选定点的点,所以中间点通常位于不可通行区域。我们还观察到MTG在可通行性方面的结果非常低。这不仅是因为我们的基准场景是基于难以用LiDAR检测的场景选择的,而且还因为MTG在关注目标最优性的同时,常常未能考虑可通行性。在弗雷歇距离方面,MTG和TGS产生了良好的结果,因为它们输出的轨迹长度与我们比较的15米长的人工操作轨迹相似。相比之下,CONVOI生成的线性轨迹与典型的人工操作轨迹有显著不同,导致相似性较低。
表1. 定量结果: 与MTG [24]、ViNT [39]、NoMaD [43]和CONVOI [34]在可通行性和类人导航相似性方面的比较。TGS在可通行性方面至少提高了3.35%,在弗雷歇距离方面至少提高了20.61%。在输入列中,L表示LiDAR点云,I表示RGB图像。
4.4 消融研究
为了评估我们创新中不同组件的能力,我们将TGS与两种不同的设置进行比较。首先,我们与仅使用MTG,并采用启发式方法选择到目标最短行驶距离的设置进行比较。这种比较显示了我们的视觉标记和VLM如何处理需要周围环境上下文信息的更多样化和更具挑战性的场景。其次,我们与仅使用带有视觉注释的VLM [30],并采用随机采样方法生成轨迹进行比较。这种比较显示了给VLM一组好的候选轨迹如何使我们的方法受益。
如图3和图2所示,当比较MTG和TGS时,MTG未能考虑那些难以从LiDAR检测的可通行性。例如,矮草花坛、路缘和人行横道就是这样的场景。TGS同时使用从LiDAR获得的几何信息生成多个候选轨迹,以及从图像获得的语义信息来选择可行的轨迹。特别是因为MTG使用启发式方法(到目标的距离)选择轨迹,它通常会导致轨迹越过草地或路缘。这显示了视觉提示方法如何帮助做出人类水平的轨迹选择决策。与使用基于CVAE的轨迹生成方法生成候选轨迹不同,图3©展示了随机采样的候选轨迹,这是PIVOT [30]探索的一种视觉提示方法。我们随机采样了前方5米到15米范围内的航点,然后线性连接这些点以生成轨迹。与PIVOT方法不同,我们没有应用迭代提问方法,这不适用于我们的实时导航流程,而是生成了10个随机点。虽然这种方法可以从提供的候选轨迹中选择最佳轨迹,但与TGS相比,它在与人类操作轨迹的相似性方面并未产生最优轨迹。这突显了轨迹生成的重要性,即为VLM提供高质量的候选轨迹。
图4展示了不同的视觉标记方法。红线和数字是提供给VLM的输入标记。绿线表示VLM选择的轨迹。CONVOI使用数字标记无障碍区域并选择数字进行导航。尽管标记的区域可能是无障碍的,但它不考虑中间的航点。这可能导致穿过障碍物。PIVOT随机生成子目标,并线性连接它们。由于目标是随机生成的,它通常无法生成好的候选轨迹。TGS结合了这两种方法的优点。虽然基于CVAE的轨迹生成产生多样化的轨迹,但它利用带有线条和数字的视觉提示来辅助VLM的空间推理,最终选择最可行的轨迹。
5 结论、局限性和未来工作
我们提出了TGS,一种新颖的多模态轨迹生成和选择方法,用于无地图室外导航。TGS将基于CVAE的轨迹生成方法与基于VLM的轨迹选择过程相结合,以在具有挑战性的室外环境中计算几何和语义上可行的轨迹。我们的方法在可通行性方面至少提高了3.35%,在与人类操作轨迹的相似性方面提高了20.61%。
我们的方法有一些局限性。由于TGS依赖于VLM,其性能可能取决于VLM的鲁棒性。然而,随着VLM的不断改进(目前正在发生),我们方法的鲁棒性也可以得到增强。此外,我们的轨迹生成方法可以随时被更好的方法所取代,从而可能带来进一步的性能提升。