怎么把自己做的网站放到网上网站的结构布局
本文介绍大数据技术中数据仓库Hive的安装配置,版本:Hive4.0.1,Ubuntu24.04。
Hive简介
Hive由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。
为什么需要Hive?
- 减低学习MapReduce的成本,使DBA、运维人员可以通过SQL来实现
- 开源,可以节约成本
- 可以处理大数据
Hive下载和安装
首先去官网下载安装包:
Index of /hive
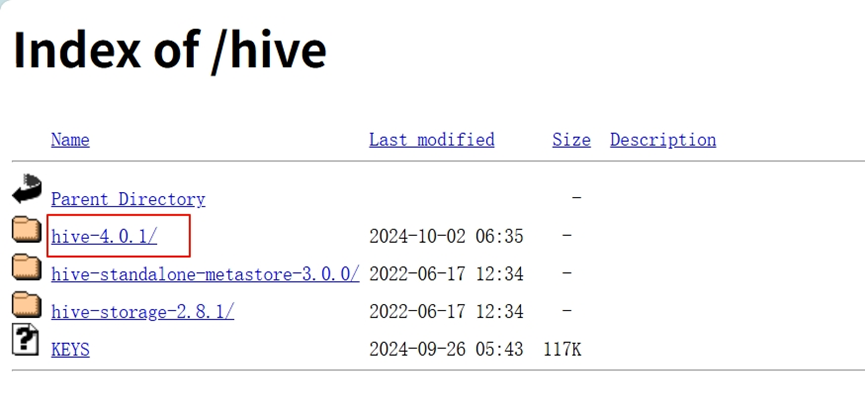
可以看到版本为4.0.1,下载apache-hive-4.0.1-bin.tar.gz,利用xftp上传
解压安装,在master中执行:
cd /home/youka
sudo tar -zvxf apache-hive-4.0.1-bin.tar.gz -C /usr/local
cd /usr/local
sudo mv apache-hive-4.0.1-bin hive
sudo chown -R root:root hive
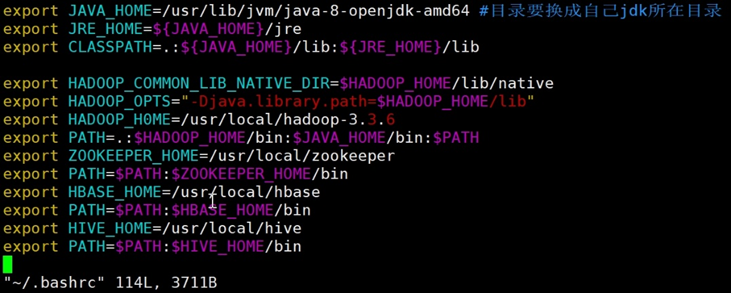
接下来配置环境变量:
vim ~/.bashrc
增加下面的配置:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
安装MySQL
Hive在使用前需要将元数据保存在关系型数据库中,将表数据保存在HDFS,需要保证对应服务开启。
接下来安装MySQL,用来保存Hive的Metastore,这里我直接使用apt的方式安装mysql
启动hadoop集群,在master上执行下列代码,可以安装MySQL的服务端和客户端:
sudo apt-get install mysql-server
sudo apt-get install mysql-client
安装完成后,MySQL已经默认启动,可以用以下命令查看状态:
service mysql status
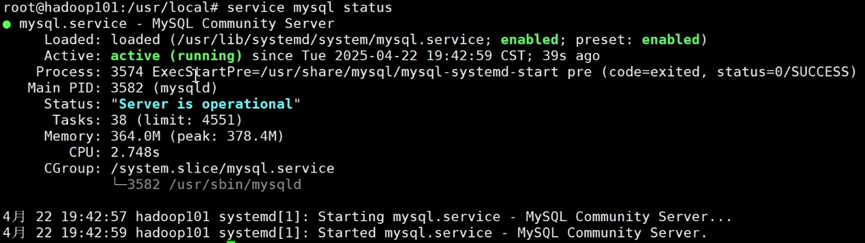
显示 active(running) 证明成功。
安装完成后,MySQL的超级用户root默认是没有密码的。使用以下命令登录
sudo mysql -u root
在mysql的cli中输入命令:
select version();
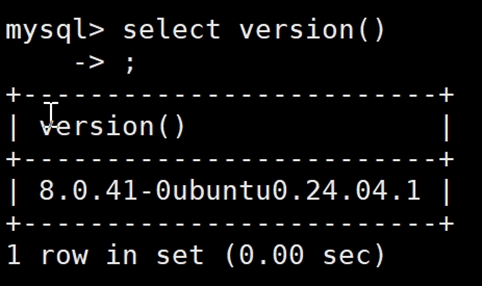
版本号为8.0.41。
use mysql;
select user,host,authentication_string from user;
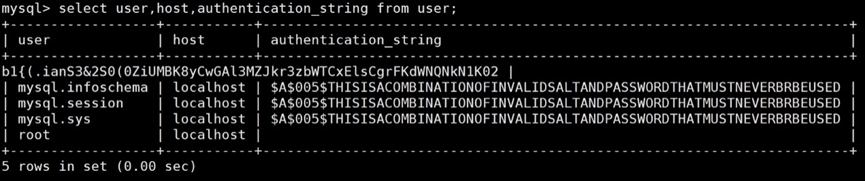
可以看到此时root用户无密码。执行下列命令,为MySQL的root用户修改密码:
alter user 'root'@'localhost' identified with mysql_native_password by '123456';
flush privileges;
重新查询root用户的密码,发现密码已经设置成功了。
select user,host,authentication_string from user;
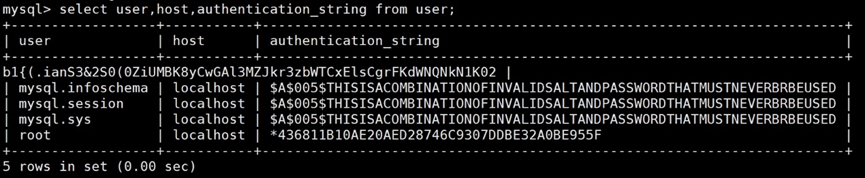
使用quit命令离开MySQL交互环境:
quit
以后要使用mysql,输入
sudo mysql -u root -p
接下来下载MySQL驱动Jar包,如果使用该数据库作为元数据存储位置,需要使得Hive能够连接到数据库,因此需要在lib目录下放入驱动jar包,可以使用wget直接下载:
cd $HIVE_HOME/lib
wget https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.32/mysql-connector-j-8.0.32.jar
配置Hive和MySQL
在Hive的配置文件中需要指定MySQL的连接信息,包括连接地址、用户名以及密码等。在master服务器中执行:
cd $HIVE_HOME/conf
# 创建一个新的hive-site.xml
vim hive-site.xml
这样就创建了一个新的hive-site.xml文件,在其中输入:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value><description>Metadata store connection URL</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value><description>Metadata store JDBC driver</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>Metadata store username</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>Metadata store password</description></property>
</configuration>
保存这个配置文件,然后执行初始化脚本:
schematool -initSchema -dbType mysql
结尾会出现Initialization script completed和schemaTool completed证明成功。

在Hive安装完成后,可以使用hive命令直接开启一个连接,默认会出现一个default数据库。
hive
出现Beeline>的提示框,这与我们想象的并不同,这是因为hive4.0.1版本以后不再使用hive CLI。我们需要利用beeline继续连接hive。
进入hadoop配置路径,修改core-site.xml
cd /usr/local/hadoop-3.3.6/etc/hadoop/
vim core-site.xml
添加:
<!-- hive默认在hdfs的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop101</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><property><name>hive.metastore.uris</name><value>thrift://localhost:9083</value></property>
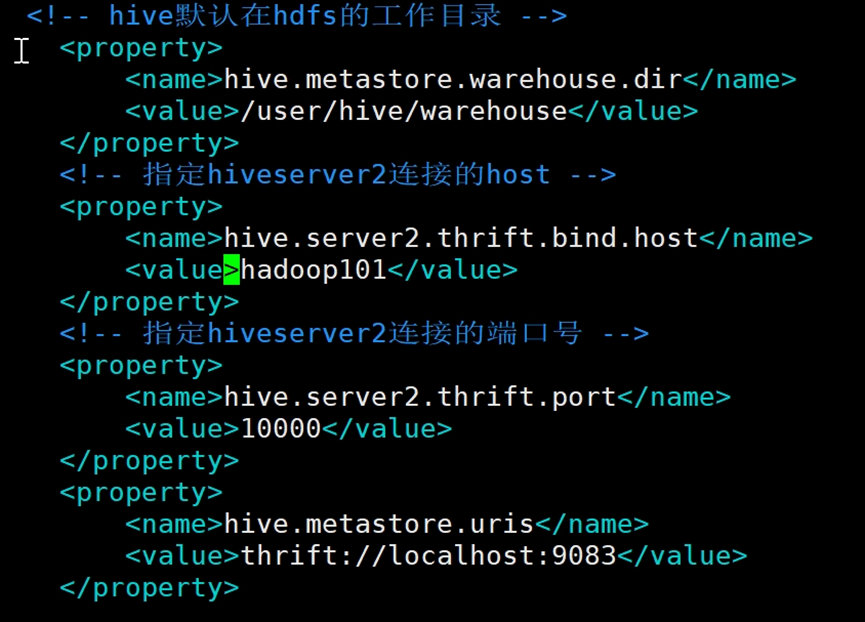
需要注意,指定hiveserver2连接的host为自己定义,这里需要和启动hive的beeline指令里的域名一致。
随后重启hadoop服务
start-all.sh
然后,先需要启动hiveserver2,下面是后台启动
nohup hiveserver2 > /tmp/hiveserver2.log 2>&1 &
上面的路径是存放hiveserver2日志的路径,可以自己写一个
注意,后台启动是看不到什么时候启动的,这一步时间可能很长,因为beeline要连接metastore和HDFS,可能持续时间5min左右,所以可能你接下来执行的步骤会被拒绝,但是后续就会成功。你可以通过执行下面的命令,来判断是否绑定到了10000端口上:
sudo ss -tulnp | grep 10000
![]()
上图发现我们端口绑定的地址是127.0.0.1,即localhost。
在hive4.0.1之后,启动hive的方式也发生了变化,需要通过beeline指令来实现
beeline -u jdbc:hive2://localhost:10000 -n root
注意:上面指令中hive2:后面的域名一定一定要和sudo ss -tulnp | grep 10000绑定的主机名对应!!如果你发现不是127.0.0.1而是192.168.179.150,那就不能用localhost连接,而是用hadoop101或者192.168.179.150连接。

还有一种连接方法是
hive
!connect jdbc:hive2://localhost:10000 -n root