准备好,开始构建:由 Elasticsearch 向量数据库驱动的 Red Hat OpenShift AI 应用程序
作者:来自 Elastic Tom Potoma
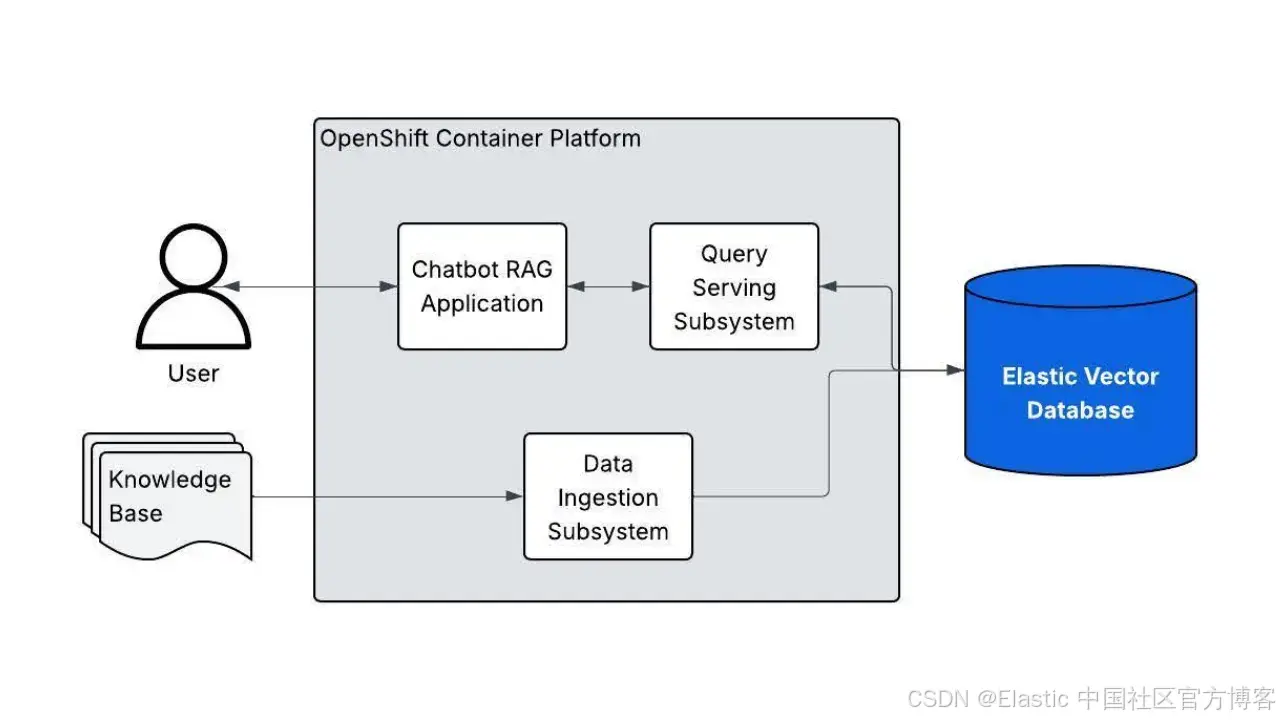
Elasticsearch 向量数据库现在被 “基于 LLM 和 RAG 的 AI 生成” 验证模式支持。本文将指导你如何开始使用。
Elasticsearch 已原生集成业内领先的生成式 AI 工具和服务提供商。欢迎观看我们的网络研讨会,了解如何突破 RAG 基础,或在 Elastic 向量数据库上构建可投入生产的应用程序。
为了为你的使用场景构建最佳搜索解决方案,现在就开始免费的云试用,或在本地机器上试用 Elastic 吧。
Red Hat 验证模式框架使用 GitOps,实现 Red Hat OpenShift 上所有操作器和应用的无缝部署。Elasticsearch 向量数据库现已被 “基于 LLM 和 RAG 的 AI 生成” 验证模式正式支持。这使开发者能够利用 Elastic 的向量数据库,在 OpenShift 上快速启动检索增强生成(RAG)应用的开发,结合 Red Hat 容器平台的优势和 Elastic 的向量搜索能力。
在验证模式中开始使用 Elastic
我们来一步步讲解如何使用 Elasticsearch 作为向量数据库来设置该模式:
先决条件
-
本地系统已安装 Podman
-
在 AWS 上运行的 OpenShift 集群
-
你的 OpenShift 拉取密钥
-
已安装 OpenShift CLI(oc)
-
安装配置文件
步骤 1:Fork 仓库
创建 rag-llm-gitops 仓库的一个 Fork。
步骤 2:克隆 Fork 后的仓库
克隆你 Fork 的仓库,并进入仓库的根目录。
git clone git@github.com:your-username/rag-llm-gitops.git
cd rag-llm-gitops步骤 3:配置并部署
创建 secret 值文件的本地副本:
cp values-secret.yaml.template ~/values-secret-rag-llm-gitops.yaml通过编辑 values-global.yaml 文件,配置该模式使用 Elasticsearch:
# Open the file in your favorite editor
vi values-global.yaml# Look for the 'db' section under 'global':
# global:
# db:
# type: DEFAULT_VALUE# Change the db.type from "EDB" (default) or "REDIS" to "ELASTIC"如果需要:配置 AWS 设置(如果你的集群位于不支持的区域):
mkdir -p ~/.aws
echo -e "[default]\nregion = <your-region>" > ~/.aws/config向你的集群添加 GPU 节点:
./pattern.sh make create-gpu-machineset安装该模式:
./pattern.sh make install安装过程会自动部署:
-
模式操作器组件
-
用于密钥管理的 HashiCorp Vault
-
Elasticsearch 操作器和集群
-
RAG 应用的 UI 和后端
步骤 4:验证部署
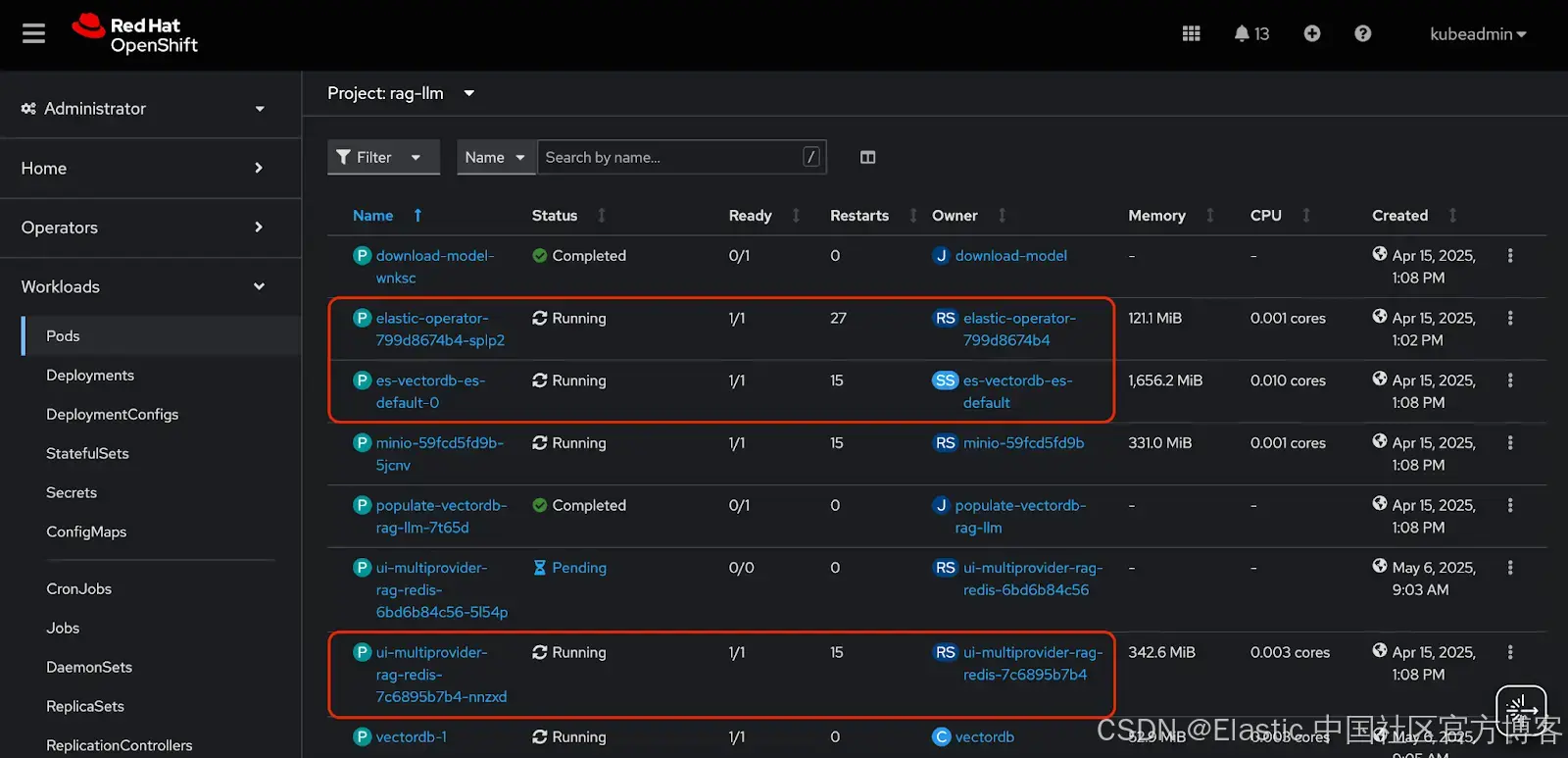
安装完成后,检查所有组件是否正常运行。
在 OpenShift Web 控制台中,进入 Workloads > Pods 菜单。从下拉框中选择 rag-llm 项目。
以下 pod 应该处于运行状态:
或者,你可以通过 CLI 检查:
oc get pods -n rag-llm你应该能看到以下 pod:
-
elastic-operator — Elasticsearch 操作器
-
es-vectordb-es-default-0 — Elasticsearch 集群
-
ui-multiprovider-rag-redis — RAG 应用的 UI(尽管名字带有 redis,但它使用的是配置的数据库类型,这里是 Elastic)
步骤 5:试用应用程序
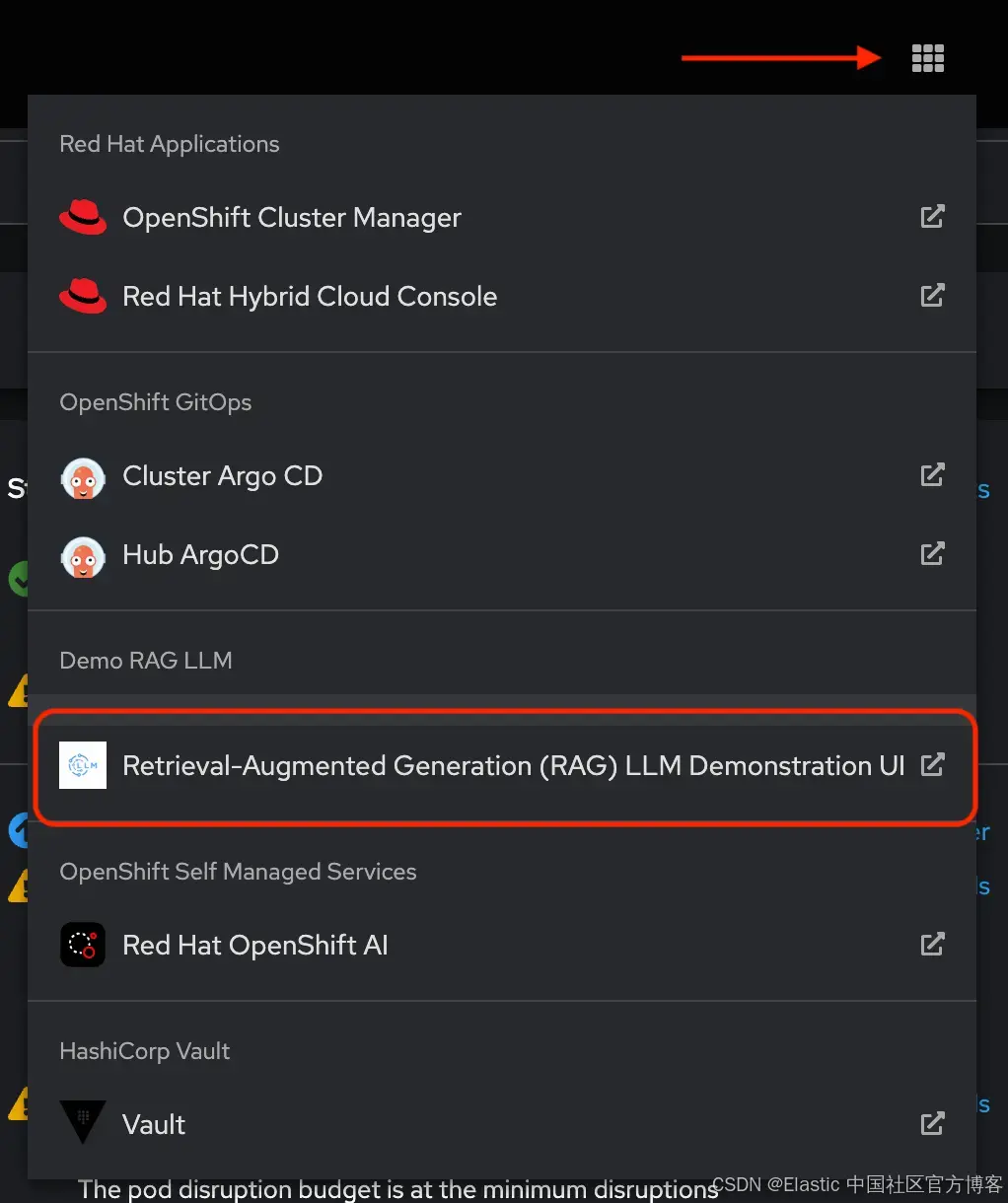
在浏览器中打开 UI,开始使用由 Elasticsearch 支持的 RAG 应用生成内容。
在 OpenShift 控制台的任意页面,点击Application/应用菜单,选择该应用:
然后:
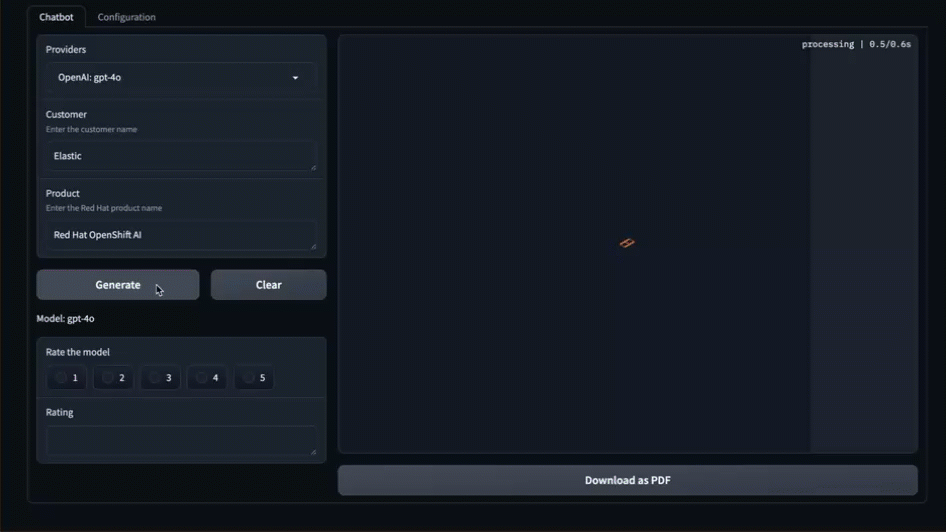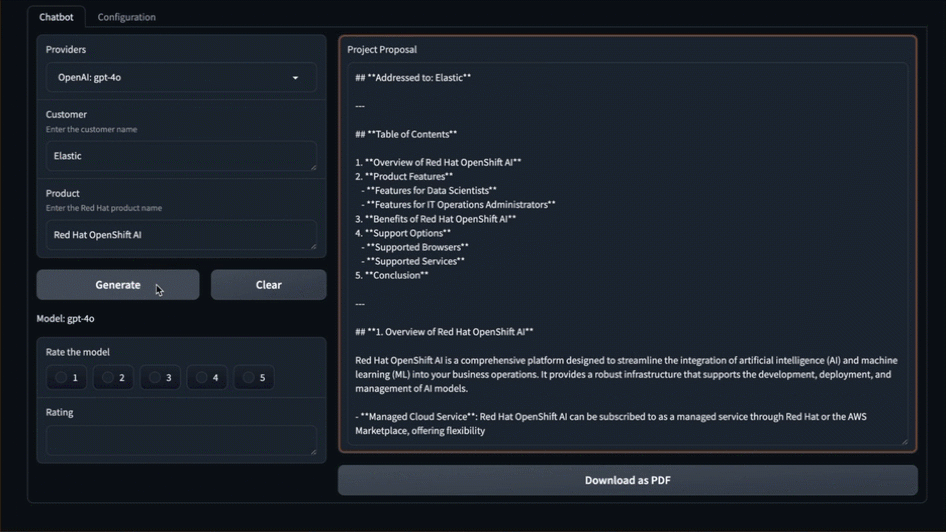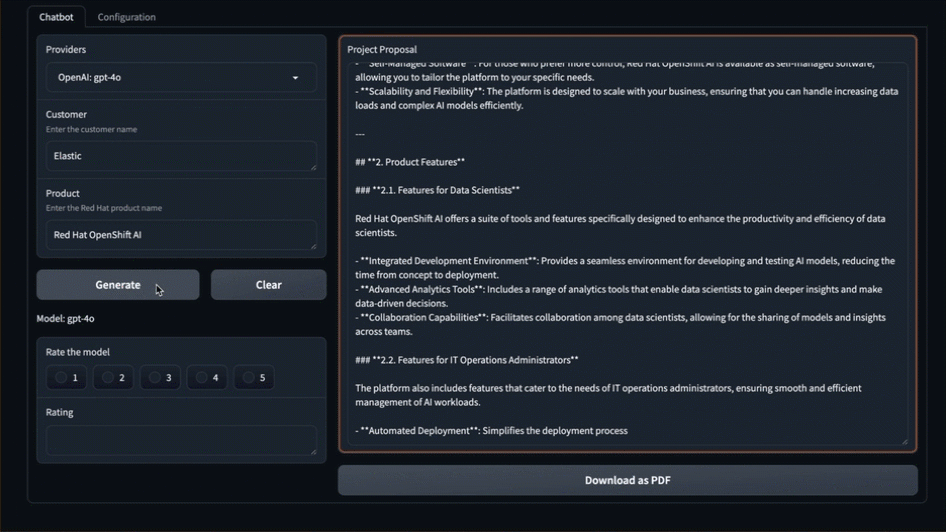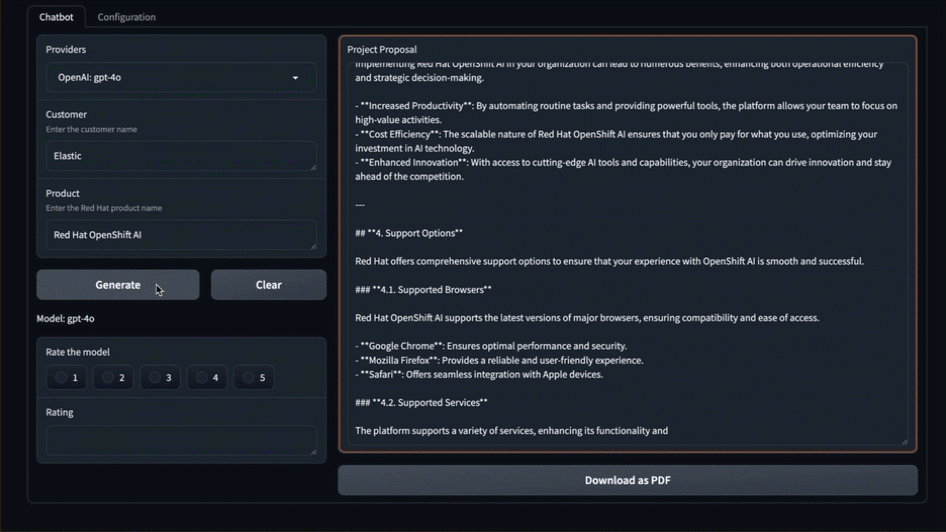
- 选择你配置好的 LLM 提供商,或者自行配置
- 使用 OpenAI 时,应用会自动添加合适的接口地址。因此,在 “URL” 字段填写 https://api.openai.com/v1’,而不是 ‘https://api.openai.com/v1/chat/completions'
- 输入 “Product” 为 “RedHat OpenShift AI”
- 点击“Generate”
- 实时观看系统为你创建提案
那么刚才发生了什么?
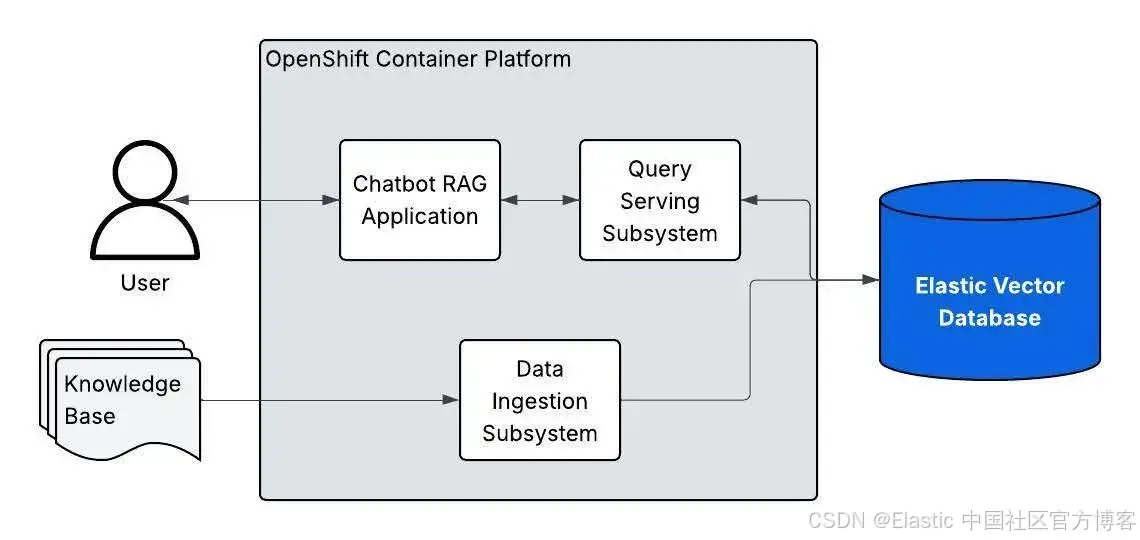
当你部署带有 Elasticsearch 的模式时,后台发生了以下事情:
-
部署了 Elasticsearch 操作器来管理 Elasticsearch 资源
-
配置了具有向量搜索能力的 Elasticsearch 集群
-
处理示例数据,并将其作为向量嵌入存储在 Elasticsearch 中
-
配置 RAG 应用以连接 Elasticsearch 进行检索
-
生成内容时,应用会查询 Elasticsearch,找到适合 LLM 的相关上下文
接下来呢?
这次初步集成只是展示了将 Elasticsearch 向量搜索与 OpenShift AI 结合的可能性开端。Elastic 提供丰富的信息检索能力,非常适合生产环境的 RAG 应用。我们正在考虑未来的改进方向:
-
高级语义理解 — 利用 Elastic 的 ELSER 模型实现更精准的检索,无需微调
-
使用 Elastic 原生的文本分块和预处理功能进行智能数据处理
-
混合搜索优势 — 将向量嵌入与传统关键词搜索和 BM25 排名结合,获取最相关结果
-
生产就绪的监控 — 利用 Elastic 全面的可观测性堆栈,监控 RAG 应用性能,洞察 LLM 使用模式
我们欢迎反馈和贡献,持续为 OpenShift AI 应用带来强大的向量搜索功能!如果你参加 Red Hat Summit 2025,欢迎来 Booth #1552 了解更多 Elastic 信息!
资源链接:
- AI Generation with LLM and RAG | Validated Patterns
- Deploying a different database | Validated Patterns
原文:Get set, build: Red Hat OpenShift AI applications powered by Elasticsearch vector database - Elasticsearch Labs