支持向量存储:PostgresSQL及pgvector扩展详细安装步骤!老工程接入RAG功能必备!
之前文章和大家分享过,将会出一篇专栏(从电脑装ubuntu系统,到安装ubuntu的常用基础软件:jdk、python、node、nginx、maven、supervisor、minio、docker、git、mysql、redis、postgresql、mq、ollama等),目前CSDN专栏(https://blog.csdn.net/a13879442471/category_12899690.html)已经分享了jdk、node、redis、ollama、python的搭建,今天继续和大家分享ubuntu如何快速安装PostgreSQL以及数据库向量扩展pgvector
postgressql安装详细步骤
1、更新系统包
sudo apt upgrade

2、使用命令安装postgresql
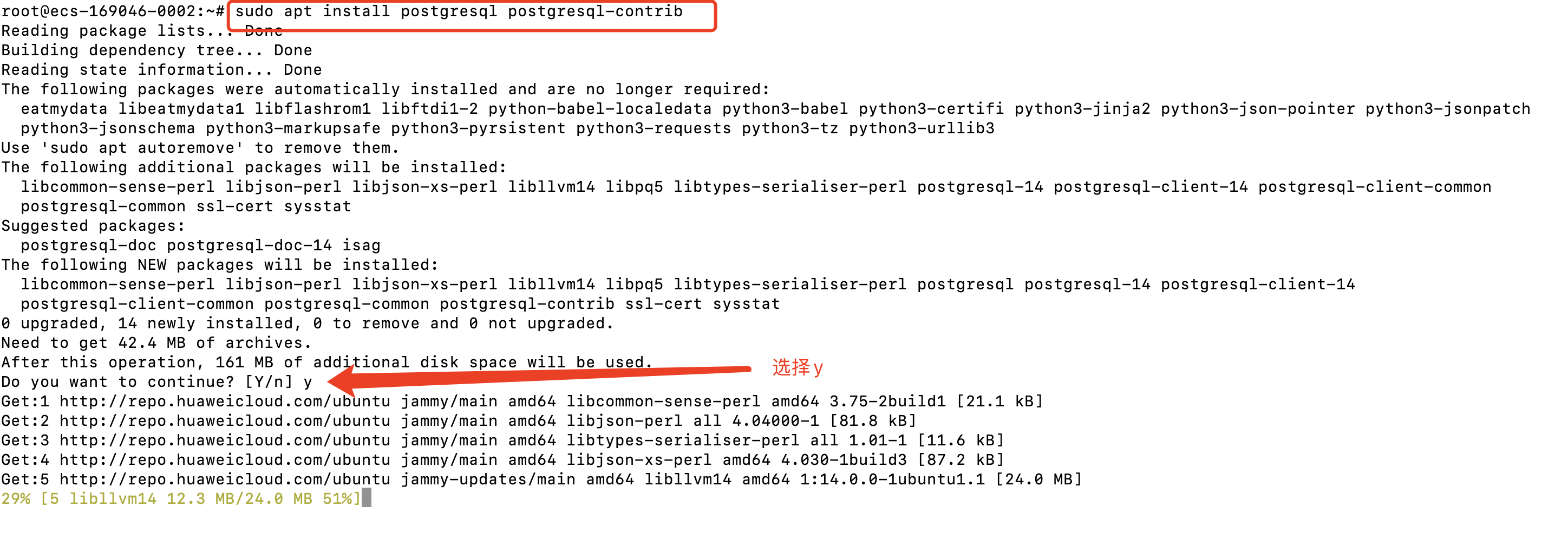
使用以下命令安装,一路y下去就可以
sudo apt install postgresql postgresql-contrib
3、启动postgresql服务
sudo systemctl start postgresql
4、设置开机启动postgresql
sudo systemctl enable postgresql

5、创建新用户
PostgreSQL安装后,默认会创建一个名为 <font style="color:rgb(36, 41, 47);">postgres</font> 的用户。你可以使用这个用户登录到PostgreSQL。
5.1、切换到postgres用户并进入PostgreSQL
sudo -i -u postgres
psql

5.2、创建新用户和数据库 这里我创建了一个my_robot用户,密码为:myROBOT123,然后创建了一个vector数据库,并把该数据库全部操作权限赋权给my_robot
CREATE USER my_robot WITH PASSWORD 'myROBOT123';
CREATE DATABASE vector OWNER my_robot;
GRANT ALL PRIVILEGES ON DATABASE vector TO my_robot;

5.3 退出PostgreSQL命令行,并退出postgres用户
这里需要操作2步,才能退出到云服务器下,先\q退出postgresql命令行,再exit退出postgres用户
\q
exit

6、配置可公网访问
因为我需要在别的服务器访问该数据库,所以需要打开配置允许公网访问
6.1、编辑pg_hba.conf配置文件
编辑pg_hba.conf配置文件
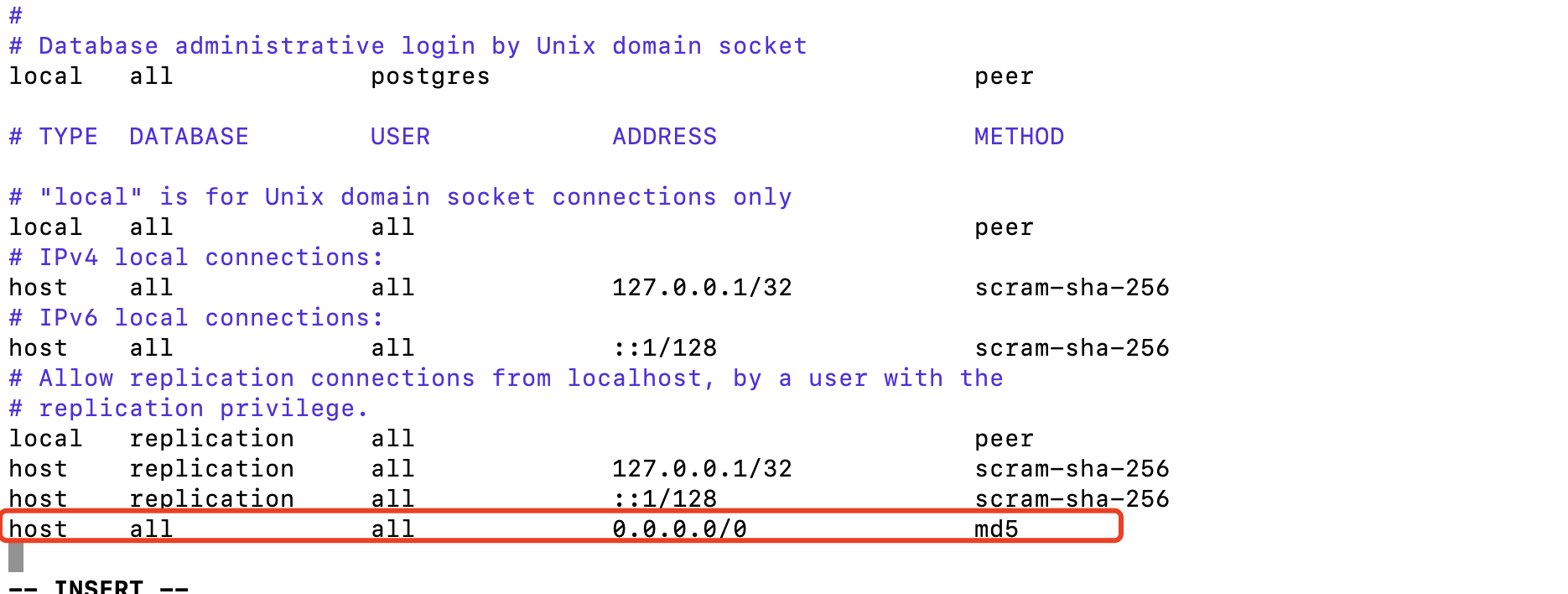
sudo vim /etc/postgresql/14/main/pg_hba.conf
在文件底部添加以下参数
host all all 0.0.0.0/0 md5
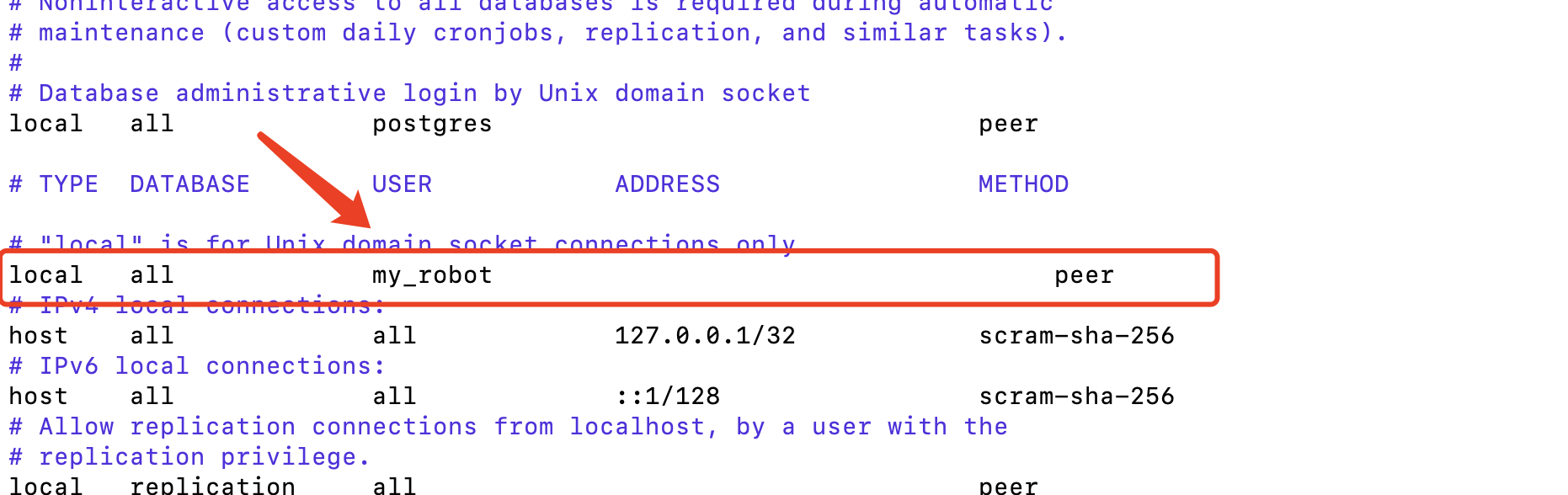
注意踩坑项
这里需要把all改为你前面的用户名,否则会提示权限问题
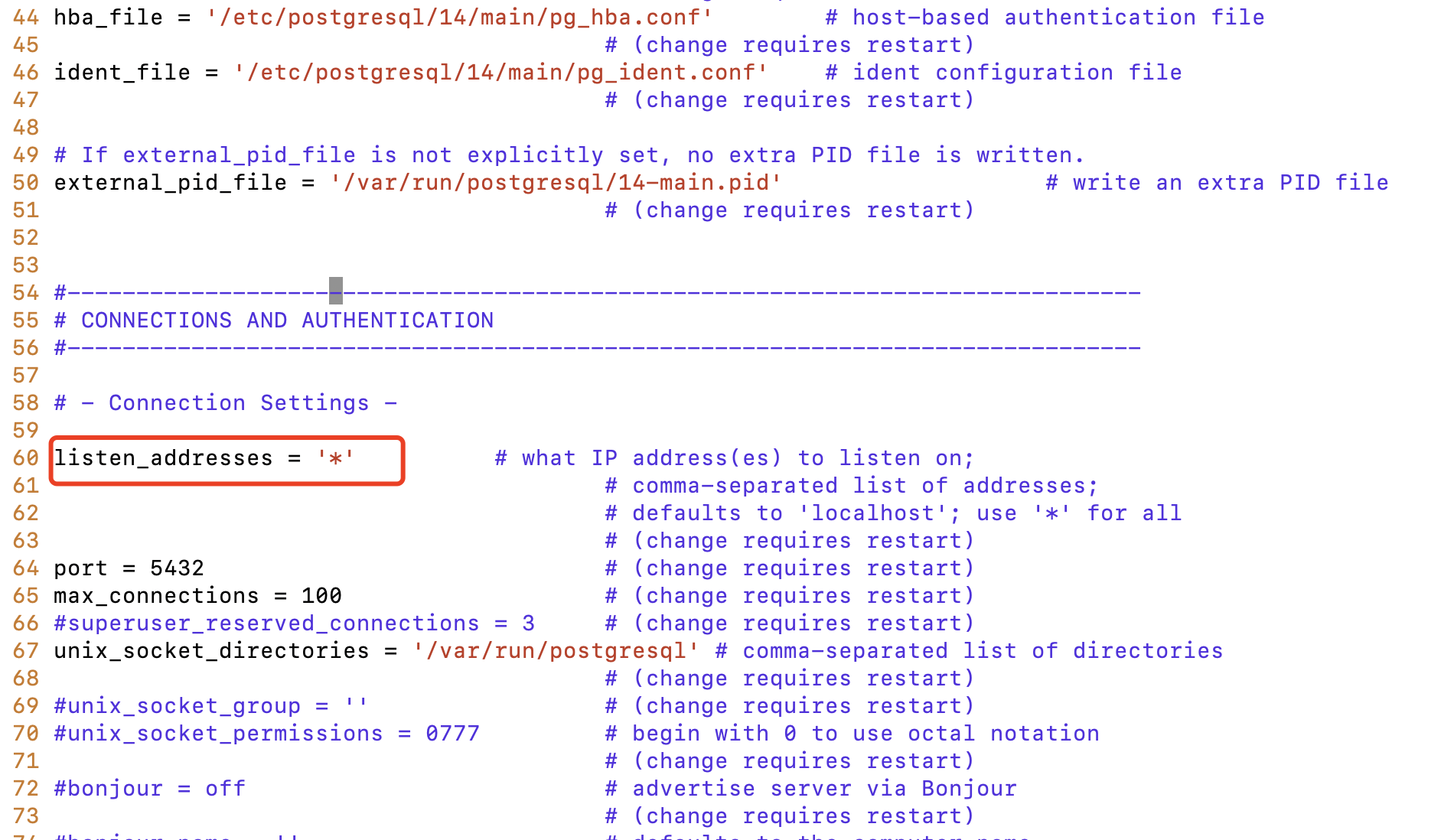
6.2、编辑postgresql.conf配置文件
sudo vim /etc/postgresql/14/main/postgresql.conf
打开地址监听
listen_addresses = '*'
如果想要访问安全些,这里可以把*改成指定ip地址
6.3、重启PostgreSQL服务
sudo systemctl restart postgresql
7、打开云服务器的PostgreSQL端口
我部署在的云服务器上,所以需要再去服务器把安全组打开postgresql端口公网访问,postgresql的默认安全端口是5432
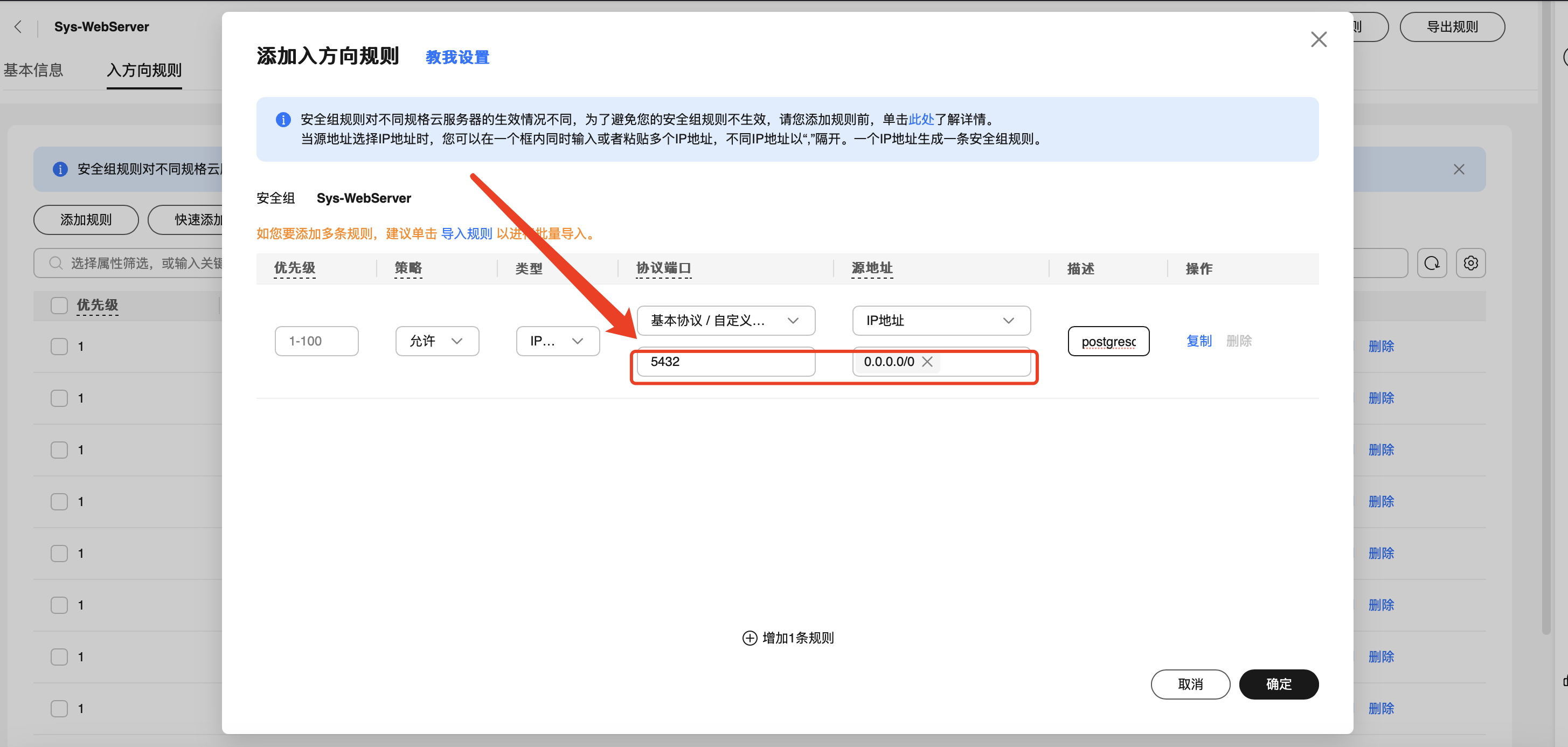
如果端口有更改的,也可以在服务器使用命令(netstat -nltp)查看具体端口

8、测试访问
使用可视化工具Navicat Premium,点击新建连接,选择PostgreSQL
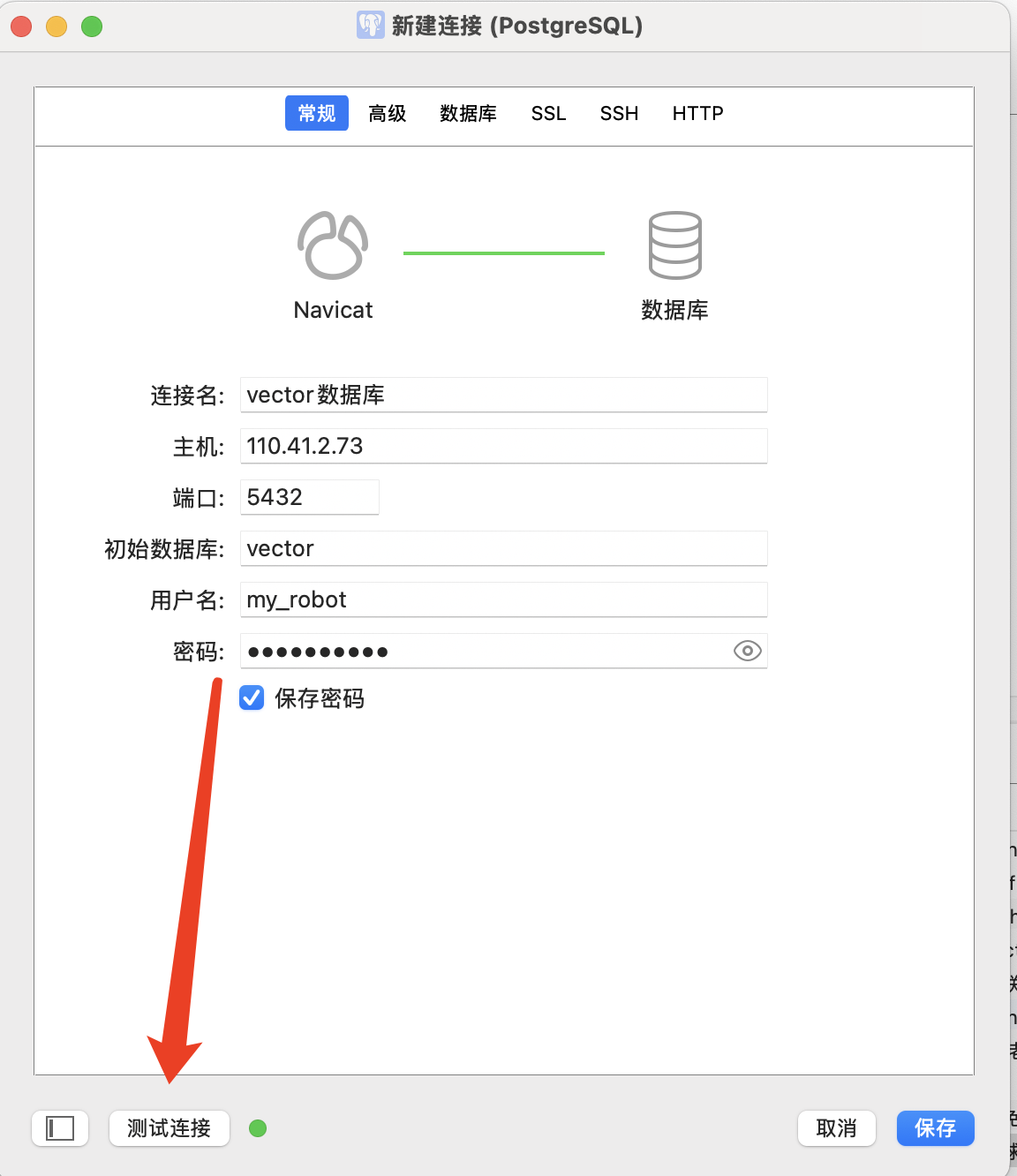
把第5步创建的用户名、密码及数据库名拷贝过来
引申阅读
postgresql是什么?
PostgreSQL是一种开源的关系型数据库管理系统(RDBMS),它具有高度的可靠性、稳定性和扩展性。PostgreSQL支持大部分SQL标准,并提供许多高级功能,如复杂查询、外键、触发器、视图等。它也支持许多扩展,可以用于处理各种不同类型的数据。PostgreSQL被广泛用于企业和开发者的应用程序中,是一个功能强大且可靠的数据库解决方案。
postgresql和mysql存储数据有什么区别?
PostgreSQL和MySQL是两种流行的开源关系型数据库管理系统,它们在存储数据方面有一些区别:
数据类型和功能
- PostgreSQL:
- 支持更丰富的数据类型,如数组、JSON、HSTORE、范围类型等。
- 提供更高级的功能,如窗口函数、CTE(Common Table Expressions)、全文搜索等。
- 支持更复杂的查询和数据操作,如递归查询、复杂的多表连接等。
- MySQL:
- 数据类型相对简单,主要支持基本的数据类型,如整数、字符串、日期等。
- 提供一些特定的功能,如全文索引(在某些存储引擎中)、地理空间数据类型和函数。
- 以简单易用和性能优化著称,适合快速开发和部署。
存储引擎
- PostgreSQL:
- 使用单一的存储引擎,称为“Heap Storage”,它处理所有类型的数据存储。
- 支持表空间(Tablespaces),可以将表和索引存储在不同的物理位置。
- MySQL:
- 支持多种存储引擎,如InnoDB、MyISAM、Memory等,每种引擎有不同的特性和优化。
- 默认的存储引擎是InnoDB,它支持事务、行级锁和外键约束。
事务和并发
- PostgreSQL:
- 提供强大的事务支持,包括ACID(原子性、一致性、隔离性、持久性)特性。
- 支持多种隔离级别,包括Serializable。
- MySQL:
- 也提供事务支持,但不同存储引擎的事务特性有所不同。
- InnoDB存储引擎支持完整的ACID事务,而MyISAM等其他存储引擎不支持事务。
性能和优化
- PostgreSQL:
- 在复杂查询和数据分析方面表现出色,适合数据仓库和分析应用。
- 优化器功能强大,能够处理复杂的查询计划。
- MySQL:
- 在简单查询和高并发读取方面表现良好,适合Web应用和在线事务处理(OLTP)。
- 优化器相对简单,但在某些场景下性能较高。
社区和支持
- PostgreSQL:
- 社区活跃,文档丰富,有大量的扩展和插件。
- 强调数据完整性和功能丰富性。
- MySQL:
- 社区同样活跃,有大量的用户和开发者。
- 强调性能和易用性,适合快速开发和部署。
什么场景下需要使用PostgreSQL?
选择PostgreSQL还是MySQL取决于具体的应用需求。如果需要更丰富的数据类型和高级功能,PostgreSQL可能是更好的选择。如果需要简单易用和高并发性能,MySQL可能更适合。PostgreSQL因其强大的功能、丰富的数据类型和高级特性,在多种场景下都非常适用。以下是一些常见的使用场景:
1. 复杂查询和数据分析
- 数据仓库和BI系统:PostgreSQL支持复杂的查询和数据聚合操作,适合用于数据仓库和商业智能系统。
- 地理空间数据:PostgreSQL通过PostGIS扩展支持地理空间数据类型和函数,适合用于GIS(地理信息系统)应用。
2. 数据完整性和高级功能
- 事务处理:PostgreSQL提供完整的事务支持,包括ACID特性,适合需要高度数据完整性的应用。
- 复杂数据类型:支持数组、JSON、HSTORE等复杂数据类型,适合需要存储非结构化或半结构化数据的应用。
3. 数据一致性和并发控制
- 多用户并发:PostgreSQL提供强大的并发控制机制,适合多用户同时访问和修改数据的应用。
- 隔离级别:支持多种隔离级别,包括Serializable,适合需要严格数据一致性的应用。
4. 扩展性和灵活性
- 扩展插件:PostgreSQL有丰富的扩展和插件,可以增加新的功能和数据类型,适合需要高度定制化的应用。
- 表继承和分区:支持表继承和分区,适合需要管理大量数据和复杂数据结构的应用。
5. 安全和合规性
- 数据加密:PostgreSQL支持数据加密和安全特性,适合需要遵守数据安全和隐私法规的应用。
- 审计和日志:提供详细的审计和日志功能,适合需要监控和记录数据操作的应用。
6. 科研和教育
- 科研项目:PostgreSQL的丰富功能和灵活性使其成为科研项目的理想选择,可以支持复杂的数据分析和实验。
- 教育机构:作为开源数据库,PostgreSQL在教育机构中广泛使用,用于教学和实验。
7. 企业级应用
- 企业资源规划(ERP):PostgreSQL适合用于企业资源规划系统,支持复杂的数据模型和业务逻辑。
- 客户关系管理(CRM):适合用于客户关系管理系统,支持大量的客户数据和复杂的业务流程。
总结
PostgreSQL在需要复杂查询、高级数据类型、事务完整性、并发控制和扩展性的场景下表现出色。无论是数据仓库、地理信息系统、科研项目还是企业级应用,PostgreSQL都是一个强大的选择。
安装pgvector扩展步骤
在Ubuntu上手工安装pgvector,并将其集成到PostgreSQL 14中,可以按照以下步骤进行:
- 安装必要的依赖:
sudo apt-get update
sudo apt-get install -y build-essential postgresql-server-dev-14
- 克隆pgvector仓库:
git clone --branch v0.6.2 git@github.com:pgvector/pgvector.git
cd pgvector
- 编译并安装pgvector:
make
sudo make install
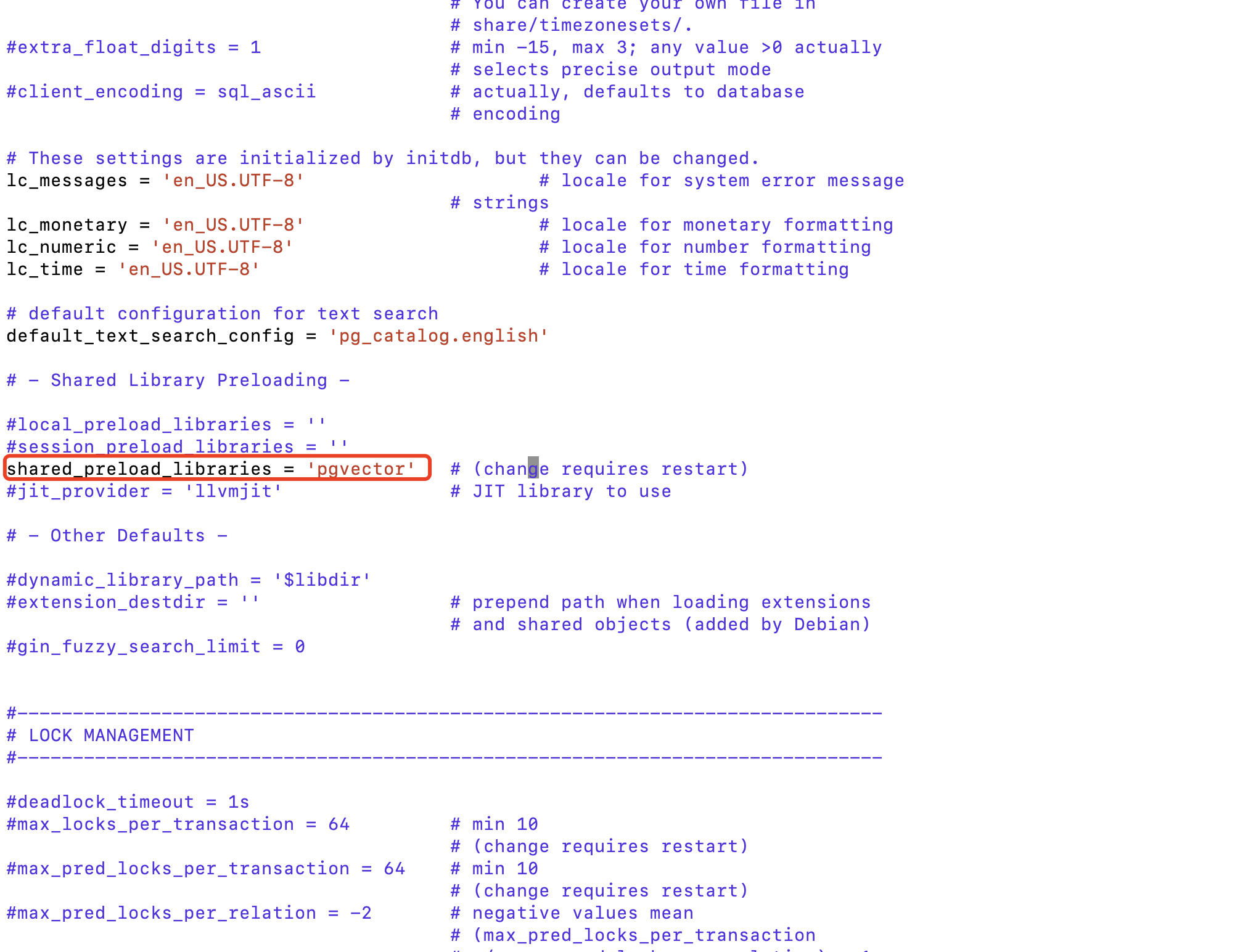
- 配置PostgreSQL以加载pgvector扩展:
编辑PostgreSQL的配置文件postgresql.conf,通常位于/etc/postgresql/14/main/postgresql.conf。
sudo vim /etc/postgresql/14/main/postgresql.conf
找到shared_preload_libraries行,并添加pgvector:
shared_preload_libraries = 'vector'
- 重启PostgreSQL服务:
sudo systemctl restart postgresql
- 在PostgreSQL数据库中创建pgvector扩展:
登录postgres用户,使用psql
su - postgres
psql
使用psql或其他PostgreSQL客户端连接到你的数据库,并运行以下命令:
CREATE EXTENSION vector;
- 验证安装:
你可以通过以下查询来验证pgvector是否安装成功:
SELECT * FROM pg_available_extensions WHERE name = 'pgvector';
如果返回结果中包含pgvector,则表示安装成功。
通过以上步骤,你已经成功在Ubuntu上手工安装了pgvector,并将其集成到PostgreSQL 14中。现在你可以在数据库中使用pgvector提供的向量相似性搜索功能了。