[论文精读]Ward: Provable RAG Dataset Inference via LLM Watermarks
Ward: Provable RAG Dataset Inference via LLM Watermarks
[2410.03537] Ward: Provable RAG Dataset Inference via LLM Watermarks
ICLR 2025
Rebuttal:Ward: 可证明的 RAG 数据集推理通过 LLM 水印 | OpenReview --- Ward: Provable RAG Dataset Inference via LLM Watermarks | OpenReview
论文研究了 RAG 数据集推理(RAG-DI)的问题,即数据所有者希望通过黑盒查询来检测他们的数据集是否包含在 RAG 语料库中。与 RAG MIA 设置的主要区别在于,数据所有者做出的是数据集级别的决策,而不是像 MIA 中那样做出文档级别的决策。
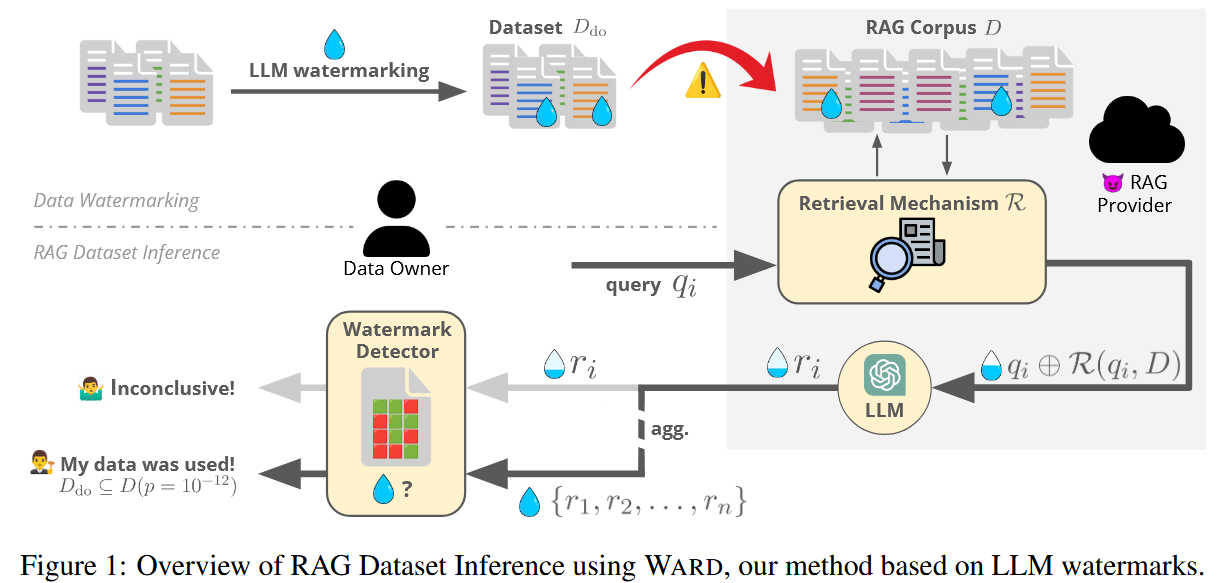
RAG引发了对未经授权使用文档的担忧,文章把这个问题正式称为RAG 数据集推理 (RAG-DI),其中数据所有者旨在通过黑盒查询检测其数据集未经授权包含在 RAG 语料库中(图 1)。在对这个问题的第一次全面研究中,观察到用于 RAG 隐私的相邻工作中使用的现有数据集不适合 RAG-DI。首先,这些数据集中的样本可能已被用于当代 LLM 训练,这使得 RAG 语料库由新数据组成的现实评估变得复杂。其次,这些数据集没有对事实冗余进行建模,这是现实世界 RAG 的一个关键属性,其中多个文档具有相似的内容,要么是由于从各种来源(例如新闻)抓取数据,要么是由于分块。研究 RAG-DI 的另一个挑战源于缺乏适用于现实黑盒设置的基线。
RAG-DI 的基础
在这项工作中,我们采取了多个步骤来弥合这些差距: 首先引入了 FARAD,这是一个专为在现实条件下评估 RAG-DI 而设计的新数据集。FARAD 包含虚构的文章,这些文章在设计上不属于任何 LLM 训练数据,并且可以在事实冗余下进行评估,从而能够准确评估 RAG-DI 方法。其次调整了之前关于 RAG 成员推理攻击 (MIA)对 RAG-DI 问题的工作[Generating is believing: Membership inference attacks against retrieval-augmented generation. ][Is My Data in Your Retrieval Database? Membership Inference Attacks Against Retrieval Augmented Generation],并提出了一个简单的基线 FACTS.
后续做了实验评估FARAD,发现它在们没有事实冗余的环境中优于其他baseline,这体现出先前数据集的缺点;当存在数据冗余的时候,所有基线都表现不佳,因此需要能够可靠识别RAG语料库中未经授权使用文档的新检测方法
文章基于LLM水印提出了WARD,它通过印记 LLM 水印来保护数据所有者的数据集【A watermark for large language models. In ICML, 2023.;Robust distortion-free watermarks for language models. TMLR 05/2024, 2024.】。如图 1 所示,给定对检索增强 LLM 的有限数量的黑盒查询 q i,数据所有者可以在响应 r i 中检测到即使是很小的水印痕迹,并首次获得有关其数据集在 RAG 语料库中使用情况的严格统计保证,使他们能够有效地审计 RAG 提供商。由于其跨设置的稳健性,以及它只与检索增强的 LLM 进行自然交互的事实,即使 RAG 提供商试图防止系统意外使用,WARD 也能保持其性能。
主要贡献
• 正式提出了RAG 数据集推理(RAG-DI),其中数据所有者旨在检测在 RAG 系统中未经授权使用其数据集
• 通过以下方式促进对这个问题的研究:(i) 提出一个新的数据集 FARAD,专门用于在现实条件下对 RAG-DI 方法进行基准测试,以及 (ii) 引入一组初始基线方法
• 提出了 LLM 水印作为一种可证明、稳健和可靠地检测 RAG 语料库中未经授权的数据使用的方法,将 WARD 作为一种新的 RAG-DI 方法
• 在各种设置中的实验评估肯定了现有数据集和所有 RAG-DI 基线的基本局限性,并证明了 WARD 的有效性,它始终显示出高准确性, 查询效率和健壮性
LLM水印技术:
参考另一篇文章对开山作《A Watermark for Large Language Models》的分析:大模型水印技术:判断文本是不是LLM生成的 - 知乎
更新的LLM水印方法:THU-BPM/MarkLLM: MarkLLM: An Open-Source Toolkit for LLM Watermarking.(EMNLP 2024 Demo)
RAG数据集推理 RAG-DI
目标实际上和MIA很像。但是MIA是文档级别的检测,这个任务是数据集级别的检测。
RAD-DI问题张的关键实体是数据所有者,目的是从未经授权的RAG语料库应用中保护它们自己的n个文档的数据集D_do。然后RAG语料库使用者的目标是找到是否这些未经授权的内容存在于语料库中,如果存在,就需要对它们进行修改(因为语料库的收集往往是非人工审核的,为了避免纠纷需要对侵权内容进行修改)。最终还是一个二分类问题。
构造适用于RAG-DI任务的数据集
要求:不应该是LLM训练语料的一部分;需要存在事实冗余信息(有重叠主题和信息的文档)。
先前针对RAG隐私的相关工作使用的是EnronEmails(2004年)和Health-careMagic(2021年)两个数据集,因为其中包含PII个人隐私信息,但是发布时间过早,可能被添加到训练语料中了,其次是缺少事实冗余信息。
因此构建了FARAD数据集。
FARAD 由多个组组成。每个组都包含共享一个主题和大量信息的文章,但这些文章是由不同的 (LLM) 作者独立撰写的。使用 RepLiQA作为数据源,其中包含有关虚构实体和事件的文章,通过设计确保这些知识不存在于任何 LLM 训练数据中。RepLiQA数据集不是一下子全部发布完毕的,在创建FARAD的时候使用 split 0 (0号分片)作为撰写本文时唯一可用的 split,但计划将其扩展到未来的 split。
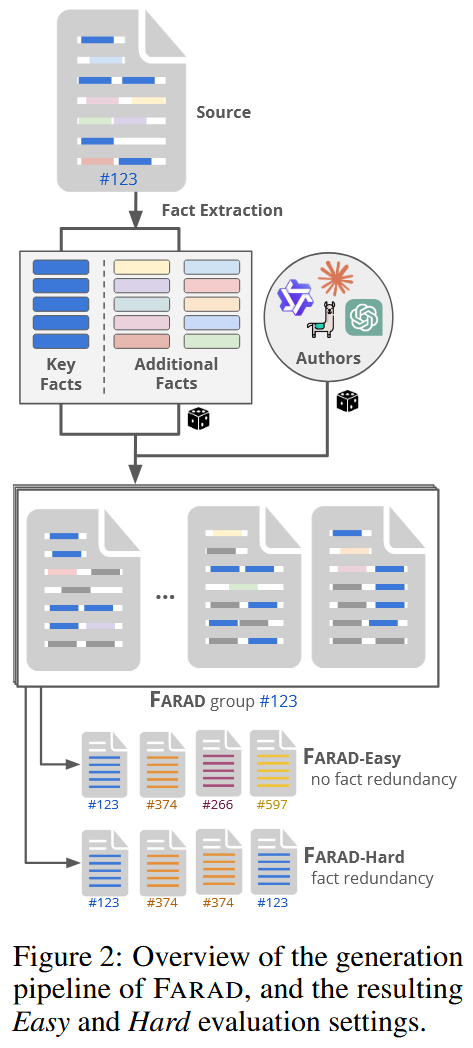
每篇 RepLiQA 文章都是其中一个小组的来源,使用图 2 所示的管道:首先提示 GPT4O 将文章的信息内容提炼成 5 个独立的关键事实,这些事实对理解文章至关重要,以及 10 个独立的附加事实,这些事实存在于文章中,但对其关键信息不是必需的。部分prompt如下:

为了创建一个组,从最先进的 LLM 的集合 A = {GPT4O, CLAUDE3.5-SONNET,LLAMA3.1-405B,QWEN1.5-110B} 中抽取一个作者模型。作者的多样性、抽样事实和(理想的)幻觉内容导致了基于相同核心知识的多样化虚构文章集,这满足了我们之前的要求。虽然此管道可以扩展到更大/更多的组、更多的作者和不同的事实组合,但我们将 FARAD 限制为 3591 个组(3391 个用于测试,200 个用于训练),每个组 4 篇文章,A 中的每位作者一篇。prompt在上面。
在后文的实验中使用 FARAD 创建两个评估设置:简单和困难,如图 2 所示(底部)。简单设置遵循上述传统设置,其中事实是唯一表示的,每个 FARAD 组始终最多使用 1 篇文章。Hard 设置通过始终包含组中的所有 4 篇文章来引入事实冗余。
RAG-DI基线
先把MIA的方案迁移过来,对数据集中的所有文档都使用MIA,得到一组二进制结果,求平均就是数据集级别的评估分数。使用DI的训练数据集实例化几个IN和OUT实例,计算对应的两类评估分数,如果总体数据集的评估分数大于两个评估分数的均值,则认为是成员数据集。
提出了FACTS基线,FACTS 是一种文档级方法。给定一个文档 d,FACTS 提示辅助 LLM 生成一个只能通过阅读 d 来回答的问题,然后,M ⋆ (RAG系统)被提示该问题,如果它认为它无法回答,我们设置 mi(d, M ⋆ ) = 0,否则将其设置为 1。如上所述,我们通过在训练集上拟合阈值,将此类文档级决策聚合为语料库级决策。
LLM水印方案
理想的RAG-DI方案应该满足三个关键要求:
- 单调性:随着对RAG查询的增加,该方法预测的准确性应该不断提高,最好以高速率提高
- 保证该方法应该能够为其决策提供统计保证,既有及其罕见且控制良好的1类错误(把正确的结果误判)因为诬告 RAG 提供者在实践中是非常不可取的,并且会破坏对该方法的信任。
- 稳健性:该方法应在不同的评估设置下保持高准确性,包括 RAG 提供商主动隐藏未经授权的数据使用的尝试。
前文的baseline都在一定程度上违反了这些要求,因此提出了 WARD(RAG-DI 水印),这是一种基于 LLM 水印的主动 RAG-DI 方法,并讨论了为什么它可能满足所有规定的要求。
基本思想
假定数据所有者已通过嵌入 LLM 水印对每个文档 di∈Ddo 进行了保护,方法可以是通过Human-in-the-loop人机回环程序,也可以是(如本工作中的)用带水印的 LM 重新表述每个文档。原则上,任何 LLM 水印都可以应用,但本文将重点放在流行的红绿水印上(相关内容部分的开山文章)。
为了审核 RAG 提供者的语料库,对于每个 di ∈ Ddo,WARD 会生成一个与内容相关的开放式问题 qi,并查询 M⋆。如果 di ∈ D(IN 情况),我们希望检索方法 R 将 di 中的水印内容引入 LLM 上下文。水印对文本转换的鲁棒性足以将信号的痕迹传播到LLM 的最终响应 ri = M⋆(qi)。
增强弱信号
这要求将每个 r i 标记为带水印,即水印检测器 p 值 p < α,将是一个强假设,因为水印信号可能会在整个 RAG 管道中降级。但是,这不是 WARD 有效的必要条件。相反,按照 Sander 等人(Watermarking makes language models radioactive. NeurIPS, 2024.)的说法,在 n 次查询之后,我们计算出一个联合 p 值 R = {r 1 , . . ., r n },直接对应于零假设“数据所有者的数据集 Ddo 不在 RAG 语料库 D 中”。
这个联合 p 值可以满足 p < α,即拒绝原假设,即使单个 r i 仅携带微弱的水印信号,也不会单独拒绝它。为了说明这一点,给定一个期望的 p 值的阈值 α,方程 ( 1) 意味着 R 中所需的绿色标记比率至少是![]() 其中 Φ 是标准正态分布 CDF,并且 |R|⊕ 是R 中响应的总长度。此下限会随着 |R|⊕的增加急剧降低:在图 3 中,我们将下限绘制为 n 的函数,假设 ∀i : |r i |= 400 个令牌,α ≈ 3 • 10 -5(z 分数至少为 4),γ = 0.25,和后文的实验设置一致。
其中 Φ 是标准正态分布 CDF,并且 |R|⊕ 是R 中响应的总长度。此下限会随着 |R|⊕的增加急剧降低:在图 3 中,我们将下限绘制为 n 的函数,假设 ∀i : |r i |= 400 个令牌,α ≈ 3 • 10 -5(z 分数至少为 4),γ = 0.25,和后文的实验设置一致。
对于 n ≥ 100,如果通过 RAG 管道传播水印仅将绿色标记的比率增加 1%,则已经可以高置信度检测到它。这使得 WARD 可行,满足 Guarantees 要求,这与任何基线都不同。它还有助于单调性:假设每个 d i 都有一个 γ ′' 的绿色标记比率,通过 M ⋆ 传播的比率减少到 γ ′ ∈ (γ, γ ′′ ),IN 情况的 p 值会随着查询的增加而严格降低。
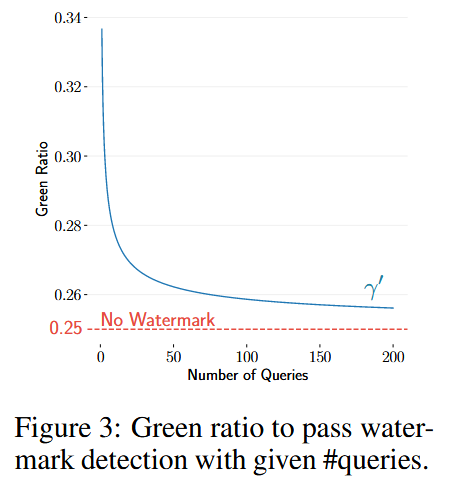
【图三对于理解这篇文章有很重要的意义,写在下面】
纵轴Green Ratio标识回答中的“绿色词”的比例。这个比例是检测水印信号的关键指标。No Watermark表示没有水印的情况下随机文本的绿色词比例为0.25,对应的就是公式2里面的γ
- 初始阶段(0-50 次查询) :
- 需要较高的 Green Ratio 才能通过检测。
- 这是因为样本量较小,统计显著性较低。
- 中期阶段(50-150 次查询) :
- Green Ratio 快速下降,表明 WARD 方法的效率很高。
- 即使水印信号较弱,也可以通过多次查询积累足够的证据。
- 后期阶段(150-200 次查询) :
- Green Ratio 接近稳定,接近 No Watermark 的基准线。
- 这表明即使在大量查询后,WARD 仍然能够提供可靠的检测结果
单调性的另一个要求是 OUT 情况的 p 值经过良好校准,确保极少见的假阳性。为了确保水印检测器评分的标记之间的独立性,有必要忽略 R 中的重复 h 元语法。虽然这减少了每个查询的有用令牌数量,但后文的实验结果表明,它不会影响 WARD 性能。
红绿方案的关键参数是上下文宽度h。在 LLM 水印的常见应用中,不建议使用低 h,因为它使水印很容易通过重复查询窃取。在 RAG-DI 的上下文中,这并不是一个问题,因为数据所有者永远不会像给 LLM 添加水印时那样公开对水印内容的不受约束的查询访问。因此,由于低 h 有利于水印通过 RAG 的传播,我们使用 h = 2.这有助于 WARD 的高鲁棒性
实用性:使 WARD 健壮的另一个方面是它不显眼,因为它通过合法使用 RAG 系统对看起来自然的文档、查询和响应——这使得 RAG 提供商阻止恶意交互的潜在尝试效果降低。这与 AAG 等基线不同,后者直接揭示了泄露 D 信息的意图。此外,WARD 不需要对 RAG-DI 进行任何训练或适应,因为 LLM 水印自然适用于此任务。
人话描述上面的所有内容
研究背景:大模型私用数据来训练模型有MIA在牵制着,但是一旦引入了RAG,就不好界定训练数据和目标数据之间是否存在一个比较明确的包含关系。先抛开训练数据不谈,未经授权的数据使用(比如爬取并使用他人数据来用作自己的知识库)变得越来越普遍,当前并不存在一种方法来提供统计上的保证来证明数据的不正当使用。
动机是隐私保护,防止偷偷滥用数据,以及考虑到数字水印技术让LLM生成结果可追溯,如果能够迁移过来,对数据加上数字水印是否可以来证明自己数据被偷偷使用了呢?
问题定义:RAG-DI,在一个黑盒环境下(即无法访问模型参数),数据拥有者(Data Owner)想要通过查询接口,判断自己的数据是否被某个 RAG 系统所使用 。
传统MIA的局限性:主要针对的是训练数据的成员推断(判断某条数据是否参与了模型训练)。但在 RAG 场景下,它并不是基于训练数据进行推理,而是基于检索数据,并且文档内容可能重复(fact redundancy),使得传统方法难以区分来源
这一新问题存在的挑战:黑盒环境限制,检测只能对RAG进行查询并获得输出;不同文档可能描述相同或者相似的事实(比如多家媒体报道同一个事件),这就使得如果只依赖于语义相似度或者关键词匹配来判断很容易误判;还缺乏一个数据集,先前的数据集不确定是不是被拿去参与训练了,而且这些数据集中往往不存在数据冗余,导致评估不够真实。
作者也同步定义了三个评估RAG-DI方法好坏的标准:单调性(查询次数越多,检测准确率越高,并且这个提升速度越快越好),统计保证(一类误报错误要极低才能适应真实应用),鲁棒性(即使面对防御手段比如RAG数据集构建者自知理亏,用人家的数据集但是对人家的数据集进行了改写操作,或者是限制了n-gram重叠,此时仍要保证方法的高准确率)
方法的核心思想是基于水印的信号传播:利用LLM水印技术对数据拥有者的文档进行水印化处理,观察这些水印是否会在RAG系统的输出中保留【这个文章急于验证数字水印的潜力以及开辟研究方向,就先只考虑了让私有数据过一遍水印模型来加水印,再投放,因此加水印这里就很简略了】;基于统计实现验证:如果水印再输出中出现的概率显著高于随机水平就说明RAG很有可能使用了这些文档。
具体步骤
(1) 数据准备阶段
- 构建水印文档 :数据拥有者使用带有水印的模型对其文档进行改写(paraphrase),从而在文档中嵌入不可见的水印。
- 构造测试集 :为了评估效果,作者构建了一个名为FARAD的数据集,其中每个文档都有多个由不同LLM生成的版本,并且包含相同的核心事实(key facts)和一些额外的事实(additional facts)。为每个水印文档生成若干个问题,这些问题的答案需要依赖该文档中的信息才能正确回答,目的是确保当 RAG 系统检索到该文档时,会将其内容用于生成答案。
【文章很精明的一点是,他在数据集构造的时候说了,构造的全都是虚假信息,都不是基于真实世界发生的事情,因此谁要是用他这个数据集来参与训练还会吃瘪,影响自己模型的准确性,哪个RAG偷用他的数据集也可能导致他们RAG产生更多幻觉,无懈可击。】
(2) 查询与检测阶段
- 模拟用户查询 :向RAG系统发送一系列问题,这些问题需要从特定文档中提取信息才能回答。(在构造数据集的时候同步构造的问题)
- 收集响应 :记录RAG系统的输出,并检查其中是否包含水印特征。
- 统计分析 :计算水印特征在输出中的出现频率,如果水印特征出现的概率显著高于随机水平,则说明 RAG 系统很可能使用了 Ddo 中的文档。通过 p-value(显著性检验)来量化这种概率,设定阈值 α(如 0.05)作为判断依据
(3) 水印检测机制
- Red-Green水印 :这是目前主流的一种水印技术。在生成过程中,词汇表被划分为“绿色”(鼓励使用的token)和“红色”( discouraged token)。通过调整生成策略,模型倾向于选择绿色token,从而形成可检测的模式。
- 水印传播 :当RAG系统使用水印文档作为输入时,生成的答案会继承这些水印特征,从而可以在输出中检测到。
文章这种检测方式的核心还是因为水印传播,当 RAG 系统使用水印文档作为输入时,它会在生成回答时继承这些水印特征,因为 RAG 系统的生成过程通常是对检索到的内容进行“压缩”或“总结”,而不是完全重新生成。
文章还提到了水印强度控制参数δ和上下文长度h,前者控制水印强度,值越大水印越明显,可能会影响文本的质量(因为绿色列表中的可选词更少了),后者控制水印检测器使用的上下文长度,值越大检测能力越强,但是可能需要更多的样本才能可靠检测。上下文长度 h 是指在使用 Red-Green 水印技术 时,水印检测器在判断一个 token 是否是“绿色词”时所参考的历史 token 数量,如果 h = 2,那么判断当前 token 是否为绿色词时,只看它前面最近的 2 个 token,决定了水印信号的局部上下文依赖性
实验验证
实验设置:
每个 FARAD 组(group)包含 4 篇文章 ,分别由不同的语言模型生成(LLM authors)。这些文章描述相同的“核心事实”,但使用不同的措辞(paraphrase),模拟现实中的事实冗余现象
使用FARAD数据集。在FARAD-EASY情况下,数据集总条目数800,其中测试用的数据条目200(800个里面有200个是故意塞进去的带有水印的文本,需要检测出来)每组只使用一篇文章,确保事实唯一表示(no redundancy)
在FARAD-HARD情况下总条目数3000,每组使用全部 4 篇文章,形成严重的事实冗余,模拟更真实、更具挑战性的场景。
使用的大模型:GPT3.5, Claude3 Haiku, Llama3.1-70B
系统提示词:一个Naive-P,基础rag提示词,没有额外限制

一个Def-p,防御性提示,提示模型不要逐字复制来源内容,并拒绝泄露上下文信息。用于模拟 RAG 提供商试图隐藏未经授权的数据使用的场景。

假定使用一个完美的检索系统,它总能够检索到最相关的文档
完美检索器用来排除检索误差对实验结果的影响,观察WARD在理想条件下的最佳表现。
策略是手动设置返回结果优先级:
如果用户的问题是基于某个特定文档 d∈Ddo 构建的,并且该文档存在于 D 中,则首先将其放入检索结果中;接下来,加入与目标文档属于同一 FARAD 组(即描述相同核心事实的不同版本)的所有文档,这些文档可能来自不同的 LLM 作者(如 A1, A2, A3, A4),它们表达了相同的事实但措辞不同(HARD模式下);最后,从知识库中随机选择其余的文档,直到达到指定的检索数量 k
实验中最多进行 200 次查询,用来测试方法随查询次数增加的表现变化
δ :水印强度(strength),影响绿色词出现的概率范围:2.5 ~ 4.5
h :上下文长度(context size),决定水印检测器使用的上下文窗口大小默认值:h=2
k ∈ {3, 4, 5, 10},以测试检索规模对性能的影响表示,k每次检索返回的文档数量
结果

绿色块表示正确的检测结果(IN状态下正确识别目标模型被使用,OUT状态下正确识别未被使用);红色快表示错误检测结果(IN状态下的漏报,OUT状态下的误报)
在 Hard 设置中,所有基线都无法一致地执行,从而导致误报和假阴性。这可以归因于它们在处理事实冗余方面的缺点:FACTS 直接依赖于事实,而 SIB 和 AAG 依赖于受事实内容影响的语义相似性。值得注意的是,只有 WARD 在所有设置、模型和系统提示中实现了 100% 的准确性,这表明尽管检索到具有部分重叠事实的文档,但水印为数据集推理提供了可靠的信号。这支持了我们关于事实冗余对于实际 RAG-DI 评估的重要性的说法,并强调了水印作为 RAG-DI 方法的潜力
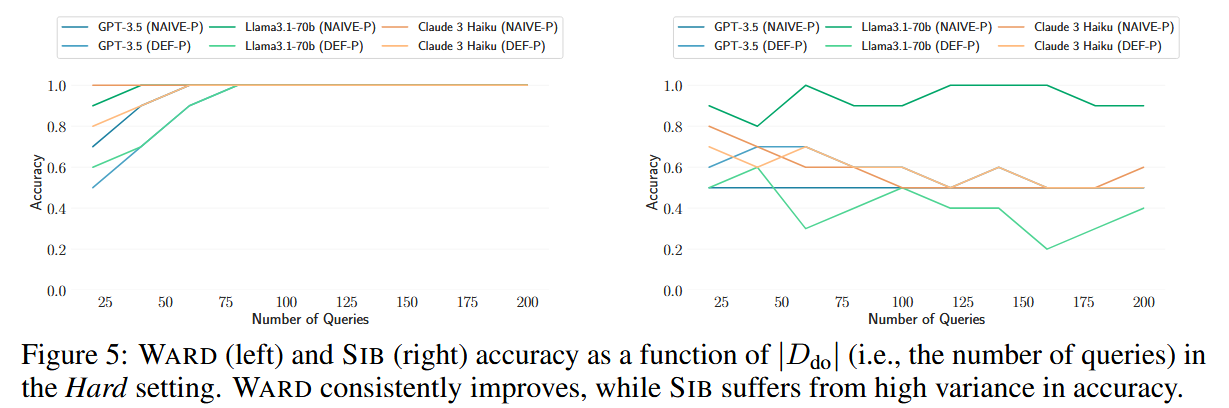
可以看出,baseline不满足定义的单调性

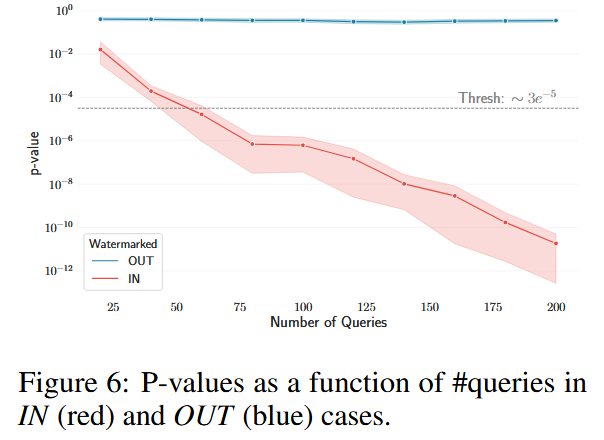
统计保证:
分别测试 IN(文档被使用)和 OUT(文档未被使用)两种情况下的 p-value 变化。
设定显著性阈值 α = 3 × 10⁻⁵。
图6 显示,IN 情况下的 p-value 随查询次数迅速下降至接近 0。
OUT 情况下的 p-value 保持在较高水平(接近随机分布),没有明显下降趋势。
说明WARD 成功提供了严格的统计保证,几乎没有误报(Type I 错误)。这对于法律诉讼、商业合规等场景至关重要。
鲁棒性:实际上图4就是鲁棒性的证明,所有baseline在hard模式下表现不佳。
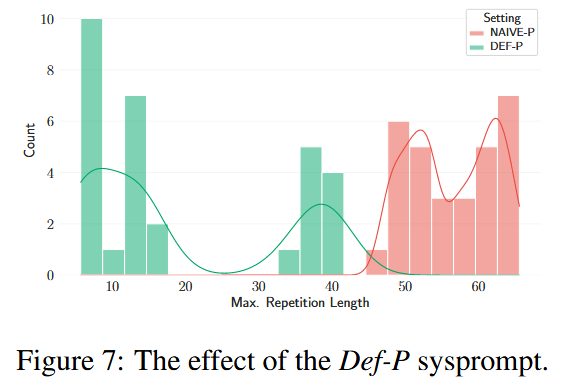
这个是比较两种PROMPT的优劣,是对比输出结果和LLM实际接收到的prompt内容的重复文本数目统计,可以看出Def-p的防护还是可以的,很少出现多词汇泄露。
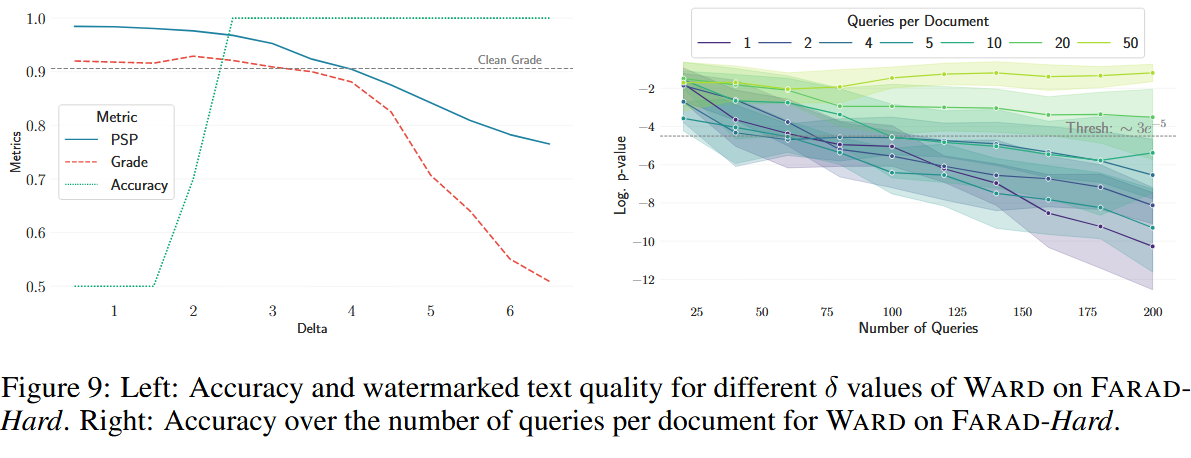
左图是水印强度的探究
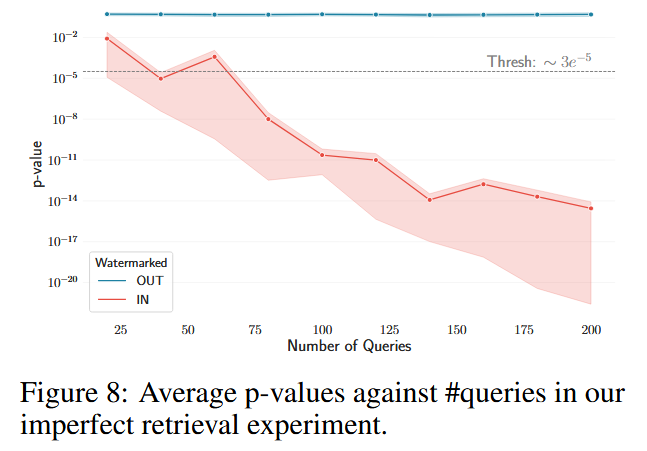
p-value值,再IN情况下,随着查询数迅速下降,说明方法有效
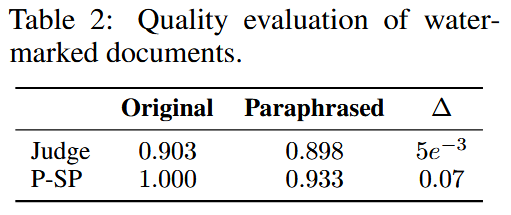
释义前后文本质量变化程度