目标检测 LW-DETR(2024)详细解读
文章目录
- 整体架构
LW-DETR全称Light-Weight DETR,是百度团队提出的第二代面向实时检测算法,比yolo v8的速度和精度更好
整体架构
LW-DETR 由一个ViT编码器(Vision Transformer Encoder)、一个投影器(Projector)和一个DETR解码器(DETR Decoder)组成。
(知乎观点)LW-DETR之所以这么用ViT,灵感是来源于kaiming团队的ViTDet,但是,ViT的结构显然是同质的,每一层之间的特征的关联性是很大的,即浅层的特征在深层特征中能够得到很好的保留,那么多层特征拼接的做法除了符合某种“思维惯性”,看不出来什么必要性。
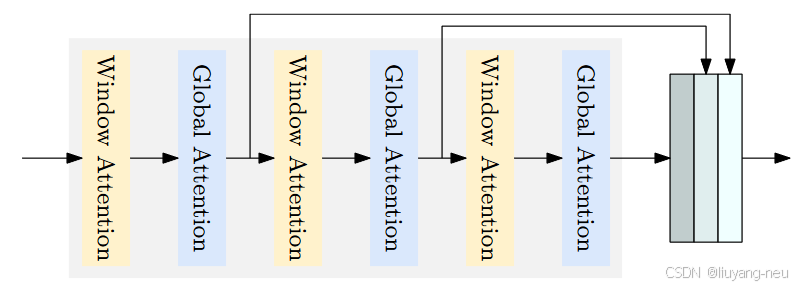
另外,考虑到检测任务的图像尺寸一般是大于分类的,此时ViT中的全局自注意力操作便会是显著的计算瓶颈,为了解决这一问题,作者团队便采用了窗口注意力机制,同时,为了保证窗口之间的交互,窗口注意力之后又添加了其他可进去全局关联的模块,这一设计也是借鉴了ViTDet。
编码器
Encoder 采用ViT 作为检测编码器。原始的ViT包含一个分块层和Transformer编码层。Transformer编码层在最初的ViT中包含一个对所有token(patch)的全局自注意力层和一个FFN层。全局自注意力计算成本较高,其时间复杂度与token(patch)数量的平方成正比。通过在Transformer编码层使用窗口自注意力来降低计算复杂度。作者提出将多级特征图、编码器中间层和最终特征图进行聚合,形成更强的编码特征图。
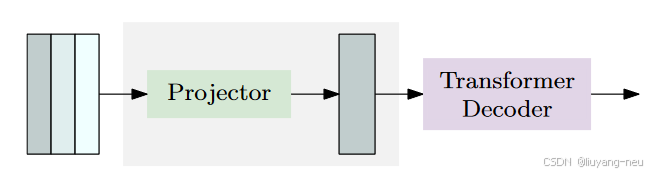
投影器(连接编解码器)
在ViT之后,又接了一个YOLOv8的C2f模块将ViT输出的特征图做一次映射。需要说明的是,LW-DETR的ViT会输出多层特征,如下图所示,将多层特征沿着通道拼接,再由C2f模块来做一次映射之后,进入decoder。
解码器
解码器和rt-detr一样,由Transform的decoder层组成,只不过由原来的6层减少到了3层,缩短了一半的时间。
采用混合查询选择策略 (和rt-detr类似)来形成对象查询,它是内容查询和空间查询的组合。内容查询是可学习的嵌入,类似于DETR。空间查询基于两阶段方法:首先从Projector的最后一层中选择前K个特征,然后预测边界框,并将相应的框转换为嵌入作为空间查询。