【TTS回顾】StyleTTS 深度剖析:TTS+风格迁移
写在前面
这篇博客我们回顾一下StyleTTS,当时的背景是,文本转语音(TTS)技术,早已不再满足于仅仅将文字转化为可听的语音。行业需要的是“真人TTS”,AI 不仅能“说得清楚”,更能“说得生动”、“说得有感情”,甚至能模仿特定人物的说话风格。富有表现力的语音合成,即能够捕捉和再现人类说话时的韵律、语调、情感和独特风格,已成为 TTS 领域的核心挑战和前沿方向。
传统的并行 TTS 模型(如 FastSpeech 系列)在合成速度和鲁棒性上取得了显著进展,但它们在风格多样性、情感表现力和自然韵律方面往往表现不足。这些模型通常依赖于独立的时长、音高、能量预测器,难以捕捉这些声学特征之间复杂的相互作用,也难以从参考音频中有效迁移细致的风格信息。
为了突破这些局限,StyleTTS 应运而生。它创新性地将**风格迁移(Style Transfer)的思想引入到并行的 TTS 框架中,通过自适应实例归一化(Adaptive Instance Normalization, AdaIN)**模块,将参考音频的“风格”注入到合成过程中,从而生成具有高度自然度、丰富表现力和多样化风格的语音。
本文带你深入剖析其模型架构、核心创新点(如可迁移单调对齐器 TMA、时长不变数据增强)、损失函数设计、两阶段训练策略、推理机制,以及探讨其在实现高质量、风格可控的语音合成方面的独特之处。
一、 StyleTTS 模型架构:八个模块的协作
StyleTTS 的整体架构设计精巧,由八个核心模块组成,这些模块可以大致归为三类:语音生成模块、TTS 预测模块和训练辅助模块。其目标是根据输入的音素序列 t 和任意的参考梅尔频谱图 x(作为风格参考),生成与 t 内容一致、且带有 x 风格的梅尔频谱图 x̃。
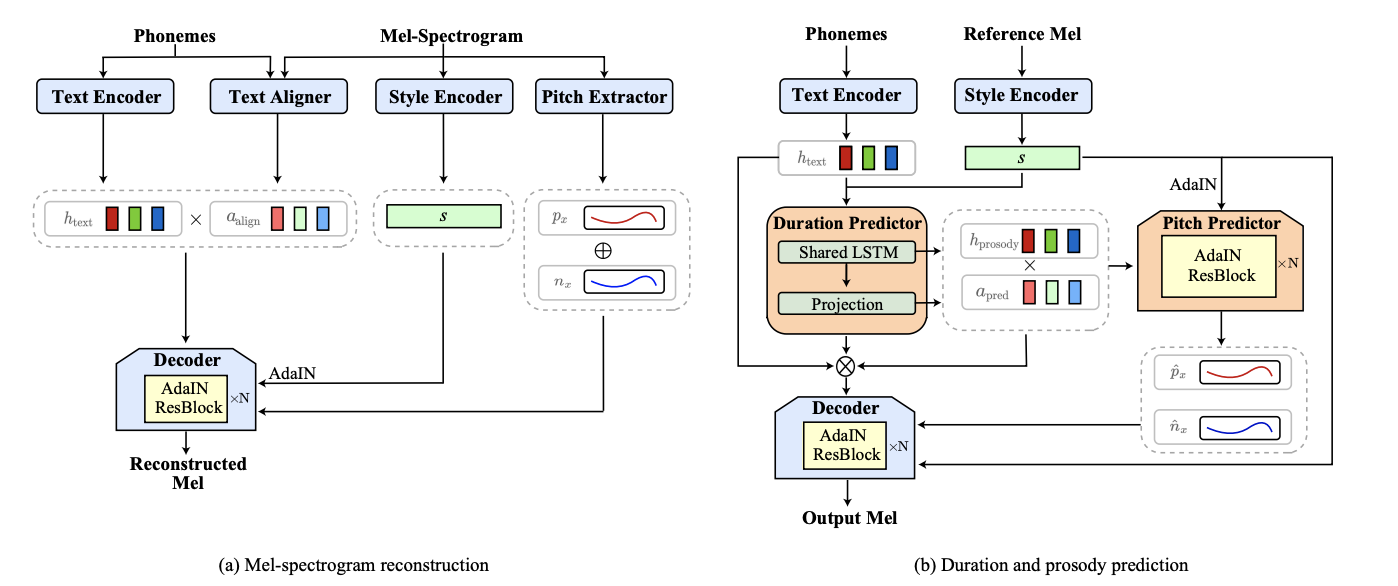
图注:StyleTTS 包含文本编码器、风格编码器、解码器、时长预测器、韵律预测器、音高提取器、文本对齐器和判别器。核心在于风格编码器和解码器中的 AdaIN 模块。
1. 语音生成模块
- 文本编码器 (Text Encoder):
- 功能:将输入的音素序列
t转换为隐层表示h_text。 - 结构:3 层 CNN + 双向 LSTM (BiLSTM)。
- 功能:将输入的音素序列
- 风格编码器 (Style Encoder):
- 功能:从输入的参考梅尔频谱图
x中提取风格向量s = E(x)。这个风格向量捕捉了参考音频的韵律、音色、情感等非语言学特征。 - 结构:4 个残差块 (Residual Blocks) + 时间维度的平均池化层。
- 核心作用:为后续的解码过程提供风格控制的条件信息。
- 功能:从输入的参考梅尔频谱图
- 解码器 (Decoder):
- 功能:根据对齐后的文本隐层表示
h_text · d_align、风格向量s、预测的音高轮廓p_x和能量n_x,重建目标梅尔频谱图x̂ = G(h_text · d_align, s, p_x, n_x)。 - 结构:7 个残差块,其中自适应实例归一化 (AdaIN) 是关键。
- AdaIN 的作用:
其中AdaIN(c, s) = L_σ(s) * ((c - μ(c)) / σ(c)) + L_μ(s)c是解码器中某个卷积层的通道特征图,s是风格向量,μ(c)和σ(c)是通道的均值和标准差,L_σ(s)和
- 功能:根据对齐后的文本隐层表示