YOLOv4深度解析:从架构创新到工业落地的目标检测里程碑
YOLOv4深度解析:从架构创新到工业落地的目标检测里程碑
一、引言
在目标检测领域,YOLO系列以“单阶段、全卷积”的设计打破了传统两阶段算法的速度瓶颈。2020年发布的YOLOv4,在YOLOv3的基础上融合了多项前沿技术,实现了精度与速度的双重跃升。本文将结合技术细节与应用场景,全面解读YOLOv4的核心改进及其在工业界的实践价值。
二、YOLOv4的技术革新:博采众长的集大成者

(一)数据增强:模拟真实场景的“数据魔法”
YOLOv4通过多样化的数据增强策略,迫使模型学习鲁棒性特征:
-
马赛克增强(Mosaic Augmentation)
- 将4张图像随机缩放、裁剪并拼接成1张,模拟复杂背景下的目标分布。例如,拼接图中可能同时包含城市街道、自然景观与不同类型的目标,提升模型对跨场景特征的适应性。
- 效果:小目标检测精度提升显著(COCO数据集中小目标mAP+1.1%),且减少对大batch size的依赖。

-
自对抗训练(SAT)
- 分两步操作:先通过模型生成对抗噪声扰动图像,再用扰动后的图像反向优化模型。例如,给“熊猫”图像添加噪声后,模型可能误判为“熊”,通过对抗训练可增强特征判别力。
- 价值:提升模型对输入噪声的鲁棒性,避免过拟合表面特征。

-
其他增强技术
- 随机擦除(Random Erase):随机遮挡图像区域(如用灰色填充),模拟目标部分遮挡场景。
- 颜色抖动(Color Jittering):调整亮度、对比度、色调,增强模型对光照变化的适应性。
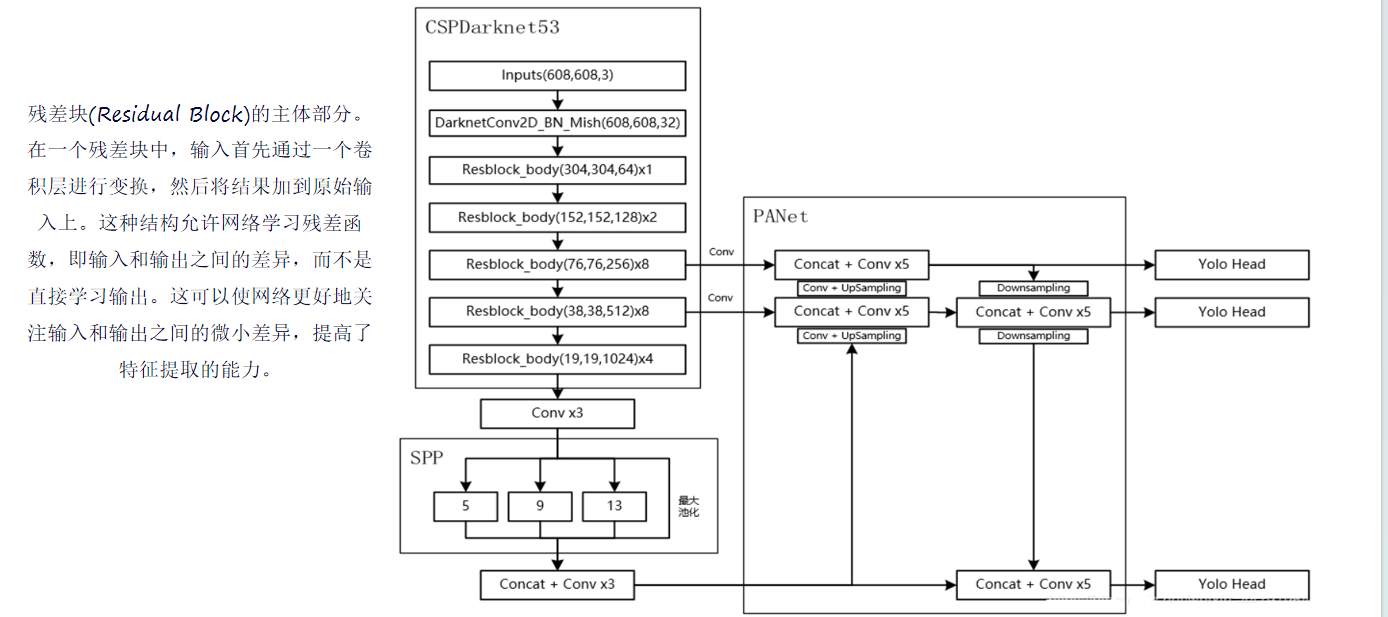
(二)主干网络:CSPDarkNet53的轻量化革命
YOLOv4采用CSPDarkNet53作为主干网络,基于**CSPNet(跨阶段局部网络)**架构实现三大突破:
-
残差块的特征拆分
- 将每个残差块的输入特征按通道拆分为两部分:
- 分支1:经过卷积-批量归一化(Conv-BN)提取残差特征。
- 分支2:直接跳过卷积,保留原始特征。
- 输出:通过拼接(Concatenation)融合两支特征,而非传统残差块的加法,保留更多原始信息的同时减少计算量(相比DarkNet53,参数量减少30%)。
- 将每个残差块的输入特征按通道拆分为两部分:
-
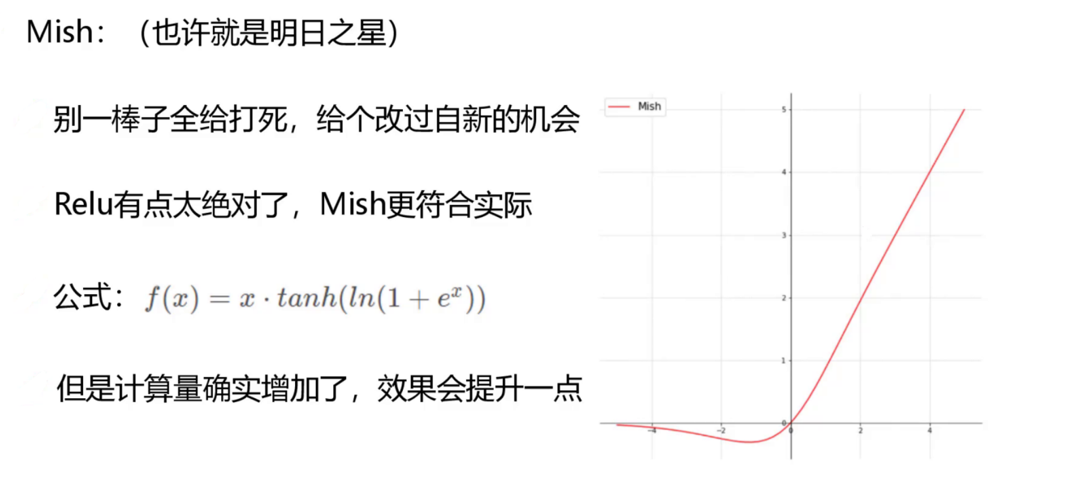
激活函数升级:Mish替代Leaky ReLU
- Mish公式:f(x) = x \cdot \tanh(\ln(1+e^x))
- 优势:光滑非单调特性允许负值区域有梯度流动(避免ReLU的“神经元死亡”问题),提升特征表达能力,实验显示mAP+1.5%。
-
多尺度特征提取
- 通过5次下采样,输出3种尺度的特征图(13×13、26×26、52×52),分别对应大、中、小目标的感受野需求。
(三)颈部网络:SPP+PAN的双向特征流动
-
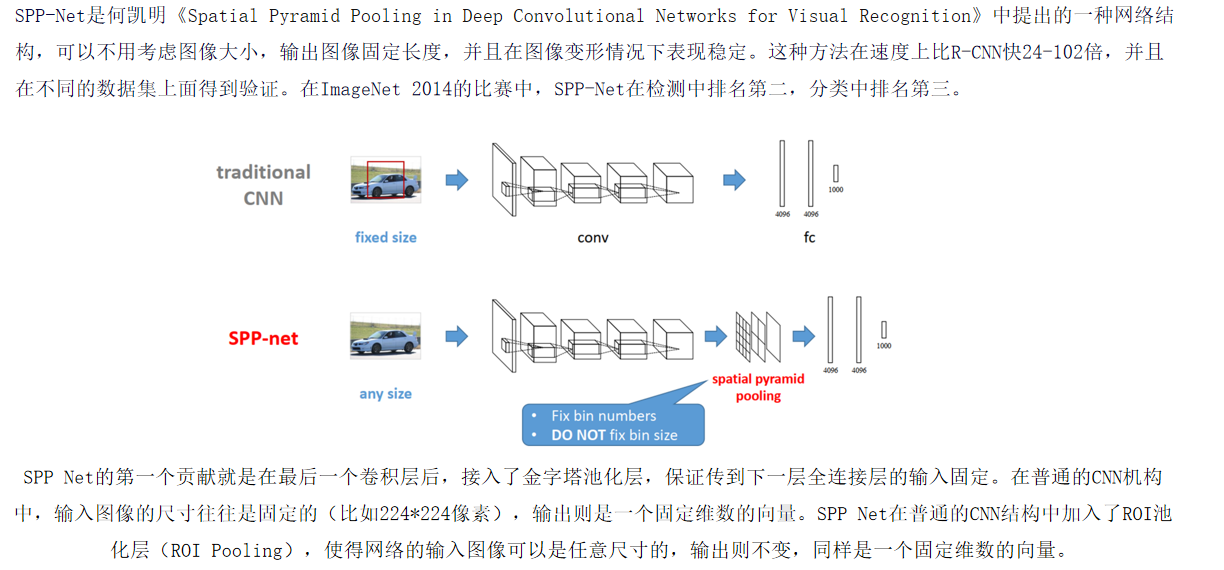
空间金字塔池化(SPP)
- 在主干网络末端,对特征图分别进行1×1、5×5、9×9、13×13的池化(步长1),提取不同尺度的上下文信息。
- 作用:捕获全局语义(如“车辆的整体形状”)与局部细节(如“车轮纹理”),增强模型对多尺度目标的适应性。
-
路径聚合网络(PAN)
- 双向特征流动:
- 自顶向下(Top-Down):高层语义特征(如“行人”类别)通过上采样传递至低层,增强细节特征的语义信息。
- 自底向上(Bottom-Up):低层细节特征(如边缘、纹理)通过下采样传递至高层,弥补语义特征的细节缺失。
- 融合方式:采用拼接(Concatenation)而非加法,保留更多维度信息,实验显示小目标mAP+3.3%。

- 双向特征流动:
(四)检测头与损失函数:精准定位的关键
-
多尺度检测与先验框优化
- 在3个尺度特征图上分别预测目标,每个尺度配备3种基于K-means聚类的先验框(共9种):
- 13×13(大目标):(116×90)、(156×198)、(373×326)
- 26×26(中目标):(30×61)、(62×45)、(59×119)
- 52×52(小目标):(10×13)、(16×30)、(33×23)
- 优势:覆盖COCO数据集中90%以上的目标尺寸分布,提升检测召回率。
- 在3个尺度特征图上分别预测目标,每个尺度配备3种基于K-means聚类的先验框(共9种):
-
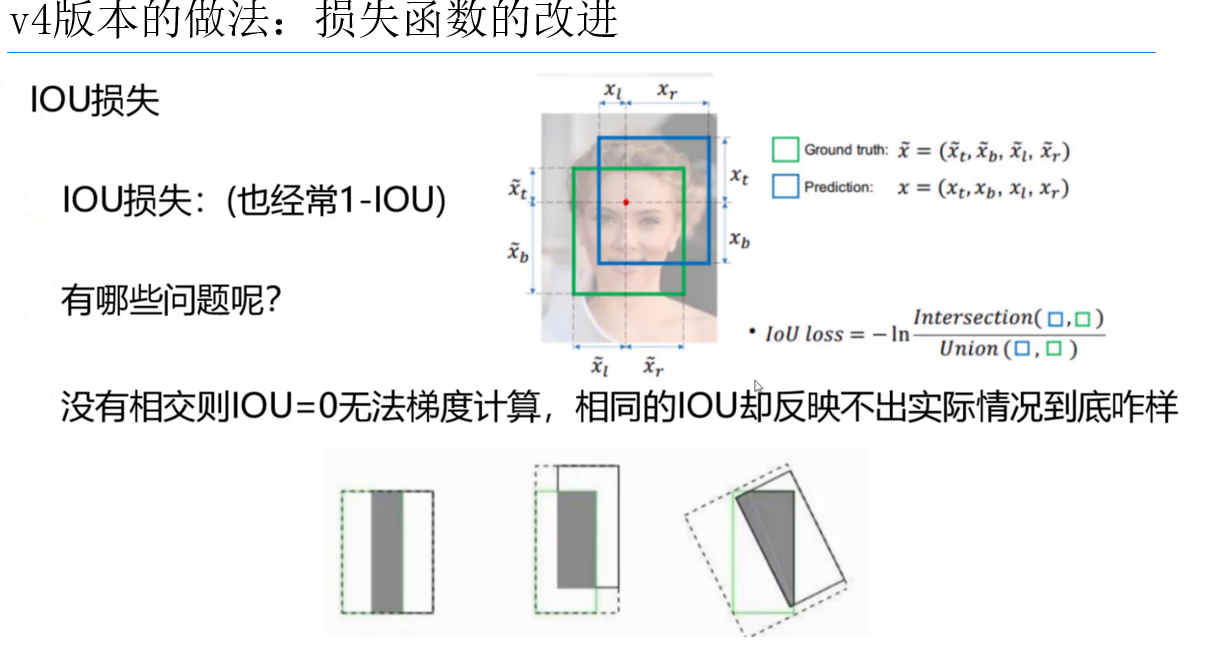
CIoU损失函数:几何度量的全面升级
- 公式:( L_{CIoU} = 1 - IoU + \frac{\rho2(b,b{gt})}{c^2} + \alpha v )
- ( IoU ):交并比,衡量重叠面积。
- ( \rho2(b,b{gt}) ):中心点距离平方,引导预测框向真实框中心靠拢。
- ( v ):长宽比差异项,强制预测框匹配真实框比例。
- 对比GIoU/DIoU:CIoU首次同时考虑重叠面积、中心点距离、长宽比,尤其在预测框与真实框未重叠时(如训练初期),优化方向更明确。

- 公式:( L_{CIoU} = 1 - IoU + \frac{\rho2(b,b{gt})}{c^2} + \alpha v )
三、推理优化:从算法到工程的落地适配
(一)非极大值抑制(NMS)改进
-
DIoU-NMS
- 在传统NMS的IoU筛选基础上,引入中心点距离惩罚项。若两框重叠但中心点距离较远(如属于不同目标),则保留低得分框,避免漏检密集目标。
- 公式:( s_i = s_i \cdot e{-\frac{\rho2(b_m,b_i)}{c^2}} )(( s_i )为框得分,( c )为最小包围框对角线)。

-
Soft-NMS
- 不直接删除重叠框,而是通过高斯函数衰减其得分(如( s_i = s_i \cdot e{-\text{IoU}2/\sigma^2} )),保留更多候选框,提升复杂场景下的召回率。

(二)轻量化设计与部署优化
- 无全连接层:全卷积架构支持任意尺寸输入,适配工业场景中多分辨率图像检测需求。
- 跨平台兼容性:基于Darknet框架,支持CPU(如Intel Xeon)、GPU(如NVIDIA Tesla)及边缘设备(如Jetson系列)的高效推理。
- 模型剪枝与量化:通过去除冗余层、权重量化(如FP16/INT8),进一步压缩模型体积,提升边缘设备部署效率。
四、性能对比:COCO数据集上的标杆表现
| 模型 | mAP@0.5-0.95 | FPS(RTX 2080Ti) | 参数量(GFLOPs) |
|---|---|---|---|
| YOLOv3 | 28.8 | 60 | 65.7 |
| YOLOv4 | 43.5 | 65 | 68.9 |
| Faster R-CNN | 38.3 | 20 | - |
| EfficientDet-D4 | 43.2 | 32 | 211.1 |
- 核心结论:
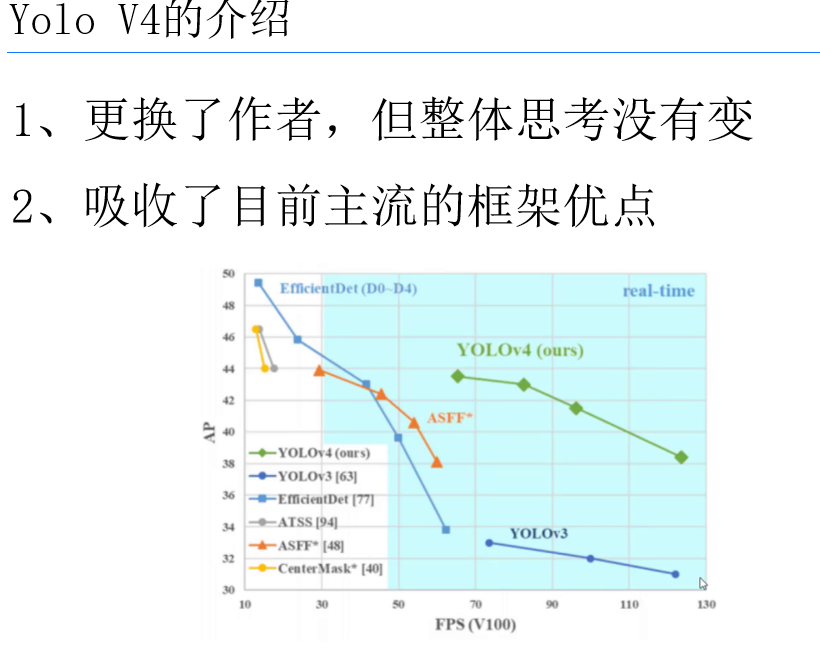
YOLOv4以65 FPS的实时速度实现了43.5%的mAP,远超YOLOv3,且在精度上接近两阶段算法(如Faster R-CNN),同时速度是其3倍以上。对比EfficientDet,YOLOv4在同等精度下速度快1倍,更适合工业实时检测场景。
五、工业应用场景与实践案例
(一)智能安防
- 需求:实时检测监控画面中的异常目标(如入侵人员、可疑包裹),要求低延迟与高召回率。
(二)自动驾驶
- 需求:车载摄像头实时检测行人、车辆、交通标志,支持多尺度目标(如远处车辆、近处行
(三)工业质检
- 需求:检测生产线上的小尺寸缺陷(如芯片划痕、零件缺失),要求高分辨率图像下的细节识别。
六、总结:YOLOv4的技术遗产与未来展望
YOLOv4的成功印证了“组合创新”的力量——通过整合CSPNet、SPP、PAN、CIoU等单项技术,在不显著增加计算成本的前提下实现了性能突破。其核心价值不仅在于学术指标的提升,更在于为工业界提供了“高精度+实时性+易部署”的完整解决方案。