Python----循环神经网络(Word2Vec)
一、Word2Vec
Word2Vec是word to vector的简称,字面上理解就是把文字向量化,也就是词嵌入 的一种方式。 它的核心就是建立一个简单的神经网络实现词嵌入。 其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括 CBOW和Skip-gram模型。

二、CBOW
CBOW(Continuous Bag of Words)的核心思想是通过上下文窗口中的周围词来预 测中心词。 在CBOW中,上下文窗口指的是以目标词为中心的一定范围内的其他词汇。
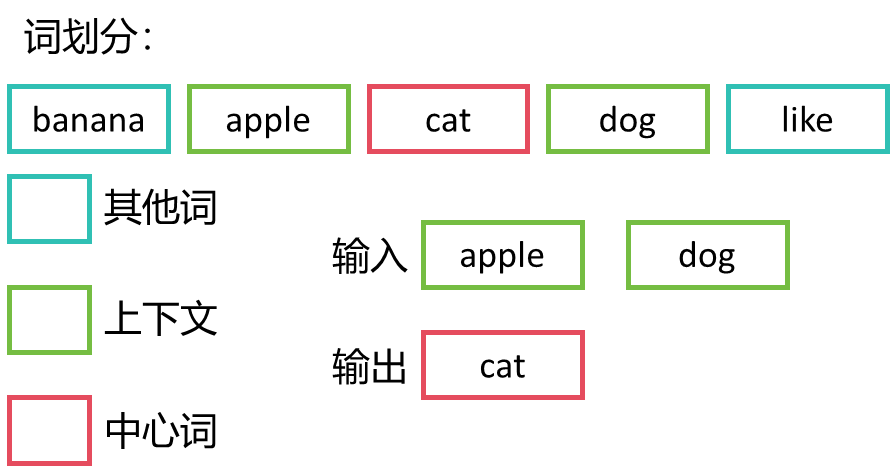
例如,如果设定上下文窗口为1,那么对于句子"banana apple cat dog like", 以"cat"为中心词,则上下文窗口为1,上下文词汇为"apple"和"dog", 而"banana"和"like"则被视为其他词。
在训练CBOW模型时,输入的样本由上下文窗口中的词汇组成,而标签则是中心词本 身。以"cat"为例,对应的输入样本为["apple", "dog"],而标签则为["cat"],将他们 转换为编码后的形式为输入样本[5,2],标签[4]。
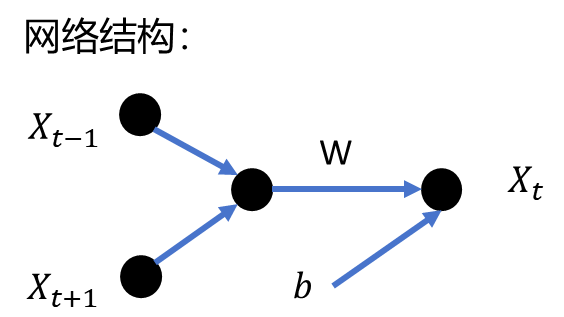
CBOW的网络结构非常简单,仅仅包括输入层、隐藏层和输出层。
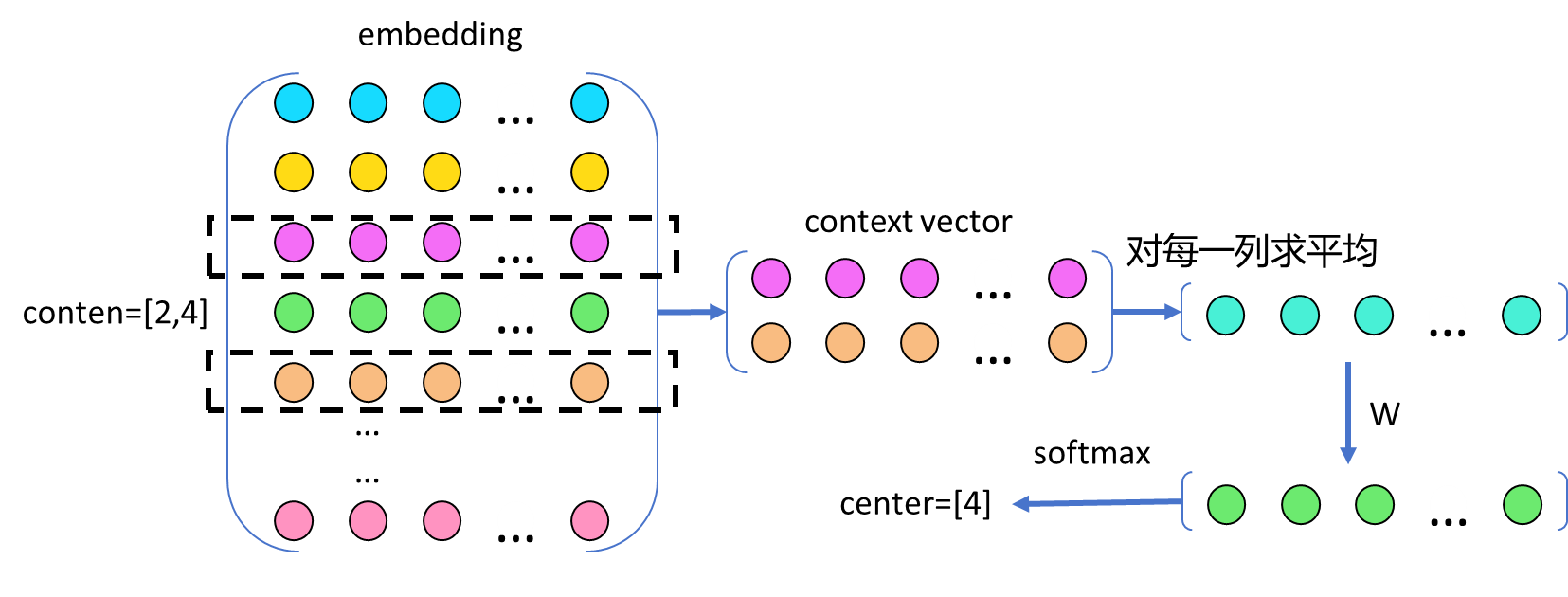
首先,通过初始化一个包含可训练参数的嵌入矩阵,即Embedding矩阵。
接着,根据之前所定义的字典,将输入样本和标签中的词汇映射为对应的数值。以输 入样本["apple", "dog"] 和标签["cat"]为例,它们通过映射转换为编码形式,分别为 输入样本(context)[5, 2] 和标签(center)[4]。
接下来,使用上下文的编码作为索引,从embedding矩阵中提取上下文的向量,在 这个例子中,样本输入[5, 2],对应于embedding矩阵中索引为5和2的向量,即上下 文向量,得到context vector。
现在,由于样本输入有两个,而标签只有一个,需要对上下文向量的每一列进行平均 操作(网络结构中的mean),从而融合上下文的特征表示。这相当于将上下文信息 整合为一个综合的上下文向量。最后,通过一个线性层和softmax函数,进行标签 (center)的预测。
三、Skip-gram
与CBOW相反,其核心思想是通过给定中心词来预测上下文词。
对于给定的中心词,Skip-gram模型试图预测在给定上下文窗口中可能出现的周围 词。假设我们有句子:"banana apple cat dog like",我们选择"cat"作为中心词,上 下文窗口为1。
在Skip-gram中,将中心词作为输入,而上下文词作为标签。对于"cat"作为中心词的 例子,输入样本是["cat"],而标签是上下文窗口中的词汇,即["apple", "dog"],将它 们转换为编码后的形式为样本输入[4],标签[5,2]。
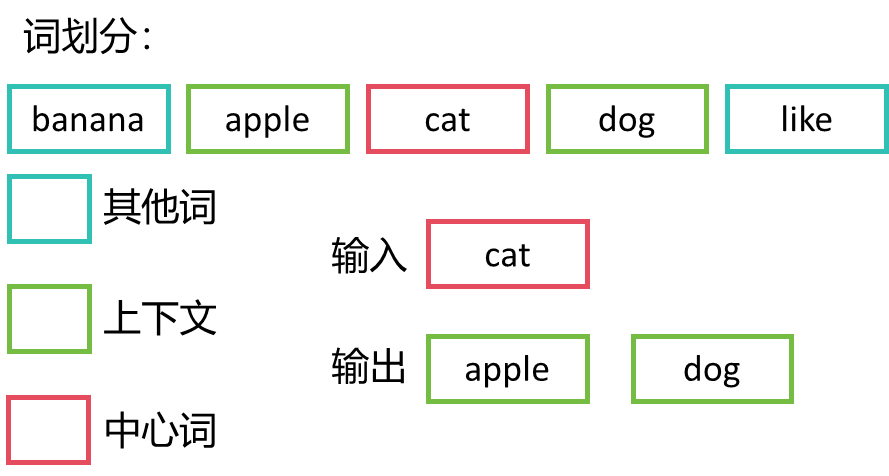
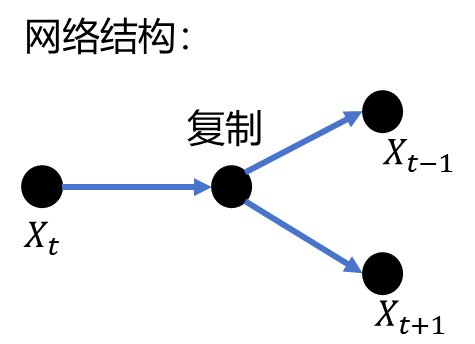
Skip-gram的网络结构非常简单,仅仅包括输入层、隐藏层和输出层。与CBOW不同 的是中间的处理不是mean而是复制。
对于Skip-gram模型,其计算过程与CBOW有所不同。 在Skip-gram中,目标是根据中心词来预测上下文词汇。
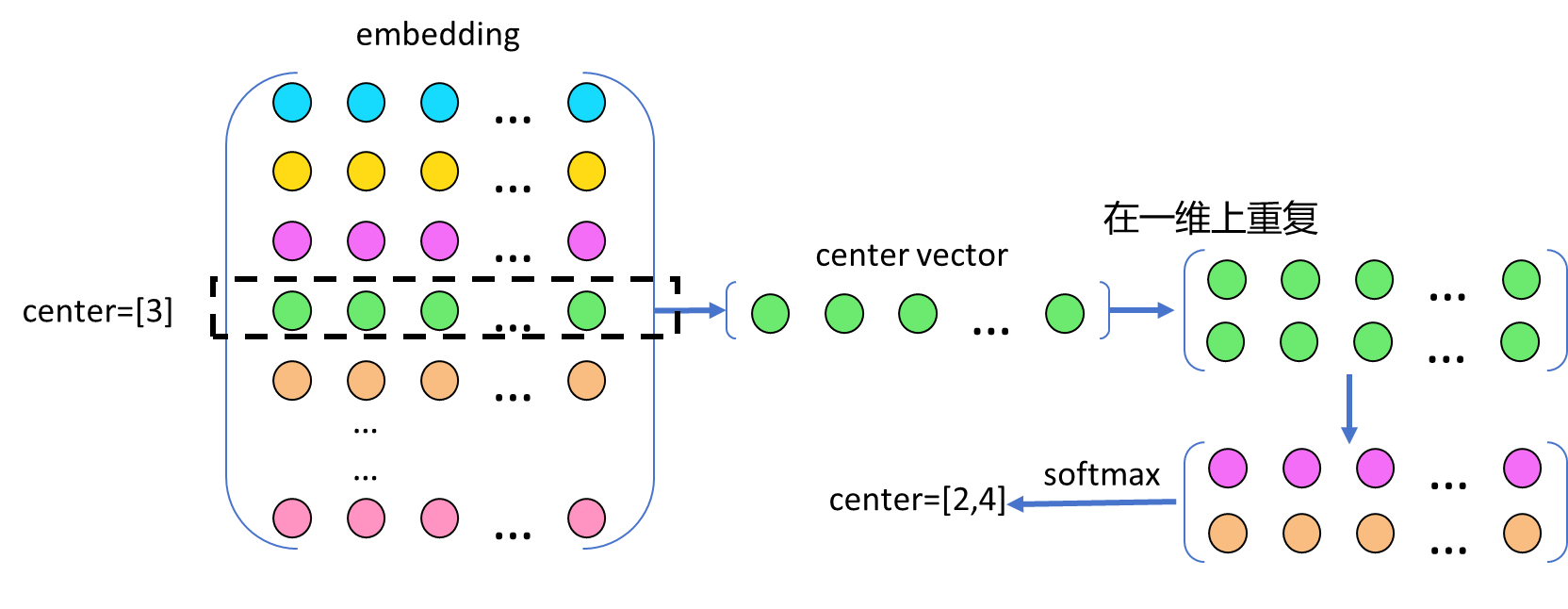
首先,同样通过初始化一个包含可训练参数的embedding矩阵。然后,根据之前定 义的字典,将输入样本和标签中的词汇映射为相应的数值。以中心词"cat"为例,将 其映射为编码形式,得到样本输入(center)[4],对于上下文词汇["apple", "dog"],其编码为标签(context)[5, 2]。
接下来,使用中心词的编码作为索引,从embedding矩阵中提取中心词的向量。在 这个例子中,样本输入[4],对应于embedding矩阵中索引为4的向量,即中心词向 量。现在,由于样本输入只有1个,而标签有两个,对中心词向量的进行复制操作。
最后,通过一个线性层和softmax函数,进行标签(context)的预测。
四、设计思路

4.1、CBOW
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
from collections import Counter
from scipy.spatial.distance import cosine
import re# 数据预处理
corpus = ["jack like dog", "jack like cat", "jack like animal","dog cat animal", "banana apple cat dog like", "dog fish milk like","dog cat animal like", "jack like apple", "apple like", "jack like banana","apple banana jack movie book music like", "cat dog hate", "cat dog like"
]# 将句子分词,并转换为小写
def tokenize(sentence):# \b 单词的边界# \w+ 匹配一个或者多个单词字符(字母,数字,下划线)# [,.!?] 匹配逗号、句号、感叹号和问号word_list = []for word in re.findall(r"\b\w+\b|[,.!?]", sentence):word_list.append(word.lower())return word_list
words = []
for sentence in corpus:for word in tokenize(sentence):words.append(word)
print(words)
word_counts = Counter(words)
print(word_counts)
vocab = sorted(word_counts, key=word_counts.get, reverse=True)
print(vocab)# {"like": 1, "dog": 2}
# 创建词汇表到索引的映射
vocab2int = {word: ii for ii, word in enumerate(vocab, 1)}
print(vocab2int)# 将所有的单词转换为索引表示
int2vocab = {ii: word for ii, word in enumerate(vocab, 1)}
print(int2vocab)# 将所有单词变成索引
word2index = [vocab2int[word] for word in words]
print(word2index)
window = 1
center = []
context = []
a=[]
for i, target in enumerate(word2index[window: -window], window):# print(i, target)# 数据:3 1 2 3 1 4# 索引:0 1 2 3 4 5center.append(target)context.append(word2index[i - window: i] + word2index[i + 1: i + 1 + window])
print(center)
print(context)
torch.manual_seed(10)# 特殊标记:0,用于填充或者标记未知单词
# <SOS>: 句子起始标识符
# <EOS>:句子结束标识符
# <PAD>:补全字符
# <MASK>:掩盖字符
# <SEP>:两个句子之间的分隔符
# <UNK>:低频或未出现在词表中的词
vocab_size = len(vocab2int) + 1 # 词汇表大小
embedding_dim = 2 # 嵌入维度
class CBOWModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOWModel, self).__init__()self.embeddings = nn.Parameter(torch.randn(vocab_size, embedding_dim)) # 初始化embedding矩阵,大小为 (词汇表大小, 嵌入维度)self.linear = nn.Linear(embedding_dim, vocab_size) # 定义线性层,输出维度为词汇表大小,用于预测中心词def forward(self, context):# context.shape -> [bs, 2] # 输入上下文是索引列表,形状为 (batch_size, 2*window_size)context_emb = self.embeddings[context] # 获取上下文中每个词的嵌入向量,形状为 (batch_size, 2*window_size, embedding_dim)# print(context_emb.shape) # torch.Size([4, 2, 2])avg_emb = torch.mean(context_emb, dim=1, keepdim=True).squeeze(1) # 对上下文的嵌入向量在维度1上(即上下文词的维度)取平均,得到平均嵌入向量,形状为 (batch_size, embedding_dim)y = self.linear(avg_emb) # 通过线性层将平均嵌入向量映射到词汇表大小的维度,用于预测每个词的概率分布,形状为 (batch_size, vocab_size)return y
model = CBOWModel(vocab_size, embedding_dim)
cri = nn.CrossEntropyLoss() # 定义交叉熵损失函数,用于衡量预测概率分布与真实中心词之间的差距
optimizer = optim.Adam(model.parameters(), lr=0.01) # 定义Adam优化器,用于更新模型参数
bs = 4 # 定义批次大小
epochs = 2000 # 定义训练轮数
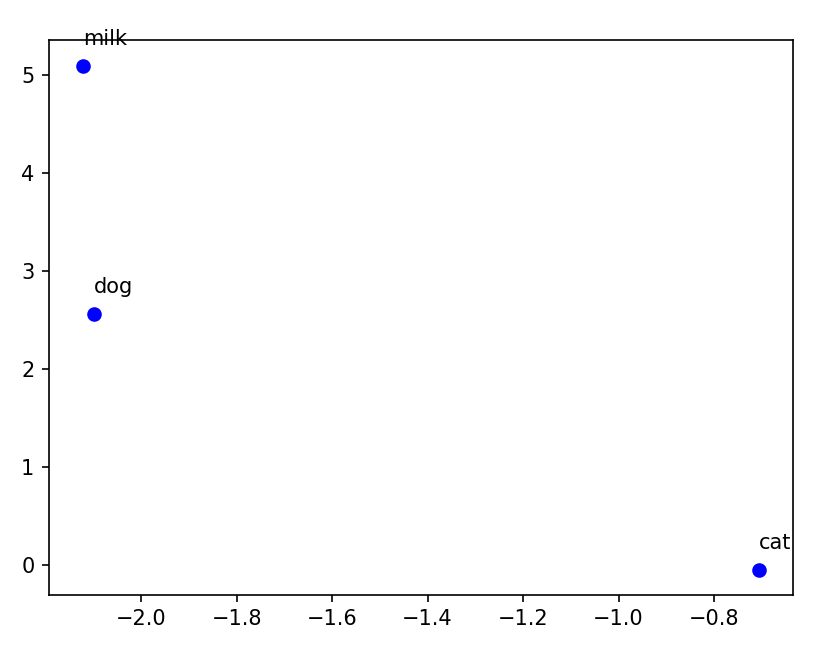
for epoch in range(1, epochs + 1):total_loss = 0for batch_index in range(0, len(context), bs):# 上下文的Tensorcontext_tensor = torch.tensor(context[batch_index: batch_index + bs]) # 获取当前批次的上下文词索引,并转换为Tensor,形状为 (batch_size, 2*window_size)# print(context_tensor.shape)# 中心词的tensorcenter_tensor = torch.tensor(center[batch_index: batch_index + bs]) # 获取当前批次的中心词索引,并转换为Tensor,形状为 (batch_size,)output = model(context_tensor) # 将上下文Tensor输入模型,得到预测的中心词概率分布,形状为 (batch_size, vocab_size)loss = cri(output, center_tensor) # 计算损失total_loss += lossoptimizer.zero_grad() # 清空梯度loss.backward() # 反向传播计算梯度optimizer.step() # 更新模型参数avg_loss = total_loss / len(context) # 计算平均损失if epoch == 1 or epoch % 50 == 0:print(f"Epoch [{epoch}/{epochs}] Loss {avg_loss:.4f}")word_vec=model.embeddings.data.numpy() # 获取训练后的词嵌入矩阵,形状为 (vocab_size, embedding_dim)x=word_vec[:,0] # 获取所有词嵌入的第一个维度y=word_vec[:,1] # 获取所有词嵌入的第二个维度select_word=['dog','cat','milk'] # 选择要可视化的词语select_word_index=[vocab2int[word] for word in select_word] # 获取所选词语的索引select_word_x=x[select_word_index] # 获取所选词语的x坐标select_word_y=y[select_word_index] # 获取所选词语的y坐标plt.cla() # 清除当前轴plt.scatter(select_word_x,select_word_y) # 绘制所选词语的散点图for word,x,y in zip(select_word,select_word_x,select_word_y):plt.annotate(word,(x,y),textcoords='offset points',xytext=(0,10)) # 为每个散点添加词语标签plt.pause(0.5) # 暂停0.5秒
plt.show() # 显示最终的词嵌入可视化结果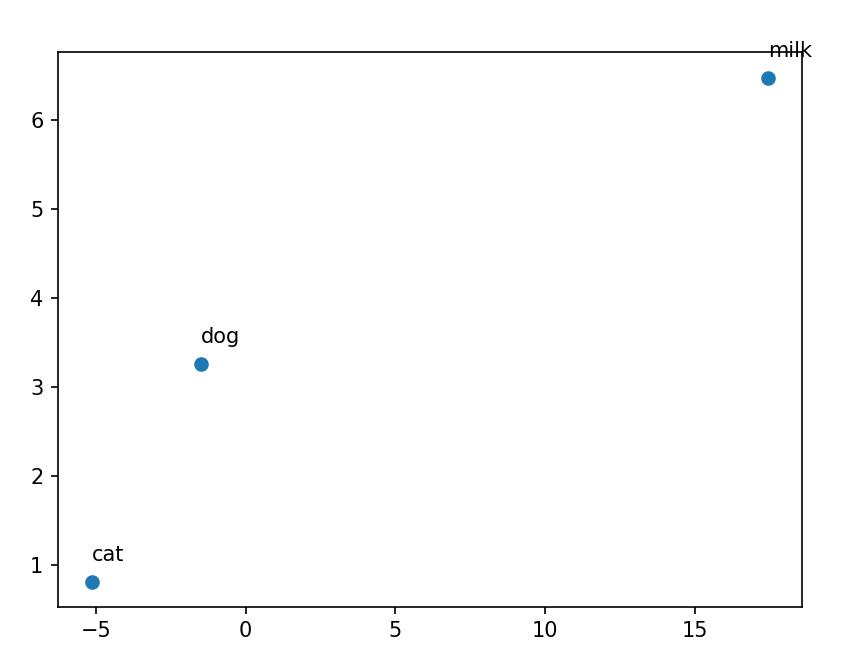
4.2、 Skip-gram
import torch
import torch.nn as nn
import torch.optim as optimimport matplotlib.pyplot as plt
import numpy as np
from collections import Counter
from scipy.spatial.distance import cosine
import re# 数据预处理
corpus = ["jack like dog", "jack like cat", "jack like animal","dog cat animal", "banana apple cat dog like", "dog fish milk like","dog cat animal like", "jack like apple", "apple like", "jack like banana","apple banana jack movie book music like", "cat dog hate", "cat dog like"
]# 将句子分词,并转换为小写
def tokenize(sentence):# \b 单词的边界# \w+ 匹配一个或者多个单词字符(字母,数字,下划线)# \[,.!?] 匹配逗号、句号、感叹号和问号word_list = []for word in re.findall(r"\b\w+\b|[,.!?]", sentence):word_list.append(word.lower())return word_listwords = []
for sentence in corpus:for word in tokenize(sentence):words.append(word)# print(words)
word_counts = Counter(words)vocab = sorted(word_counts, key=word_counts.get, reverse=True)
# print(vocab)# {"like": 1, "dog": 2}
# 创建词汇表到索引的隐射
vocab2int = {word: ii for ii, word in enumerate(vocab, 1)}
# print(vocab2int)
# 将所有的单词转换为索引表示
int2vocab = {ii: word for ii, word in enumerate(vocab, 1)}
# print(int2vocab)# 将所有单词变成索引
word2index = [vocab2int[word] for word in words]
# print(word2index)
window = 1
center = []
context = []for i, target in enumerate(word2index[window: -window], window):# print(i, target)# 数据:3 1 2 3 1 4# 索引:0 1 2 3 4 5center.append(target)context.append(word2index[i - window: i] + word2index[i + 1: i + 1 + window])torch.manual_seed(10)# 特殊标记:0,用于填充或者标记未知单词
# <SOS>: 句子起始标识符
# <EOS>:句子结束标识符
# <PAD>:补全字符
# <MASK>:掩盖字符
# <SEP>:两个句子之间的分隔符
# <UNK>:低频或未出现在词表中的词
vocab_size = len(vocab2int) + 1 # 词汇表大小
embedding_dim = 2 # 嵌入维度class SkipGramModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(SkipGramModel, self).__init__()self.embeddings = nn.Parameter(torch.randn(vocab_size, embedding_dim)) # 初始化embedding矩阵,大小为 (词汇表大小, 嵌入维度)self.linear = nn.Linear(embedding_dim, vocab_size) # 定义线性层,输入维度为嵌入维度,输出维度为词汇表大小,用于预测上下文词def forward(self, center):center_emb = self.embeddings[center] # 获取中心词的嵌入向量,形状为 (batch_size, 1, embedding_dim)y = self.linear(center_emb) # 通过线性层将中心词嵌入向量映射到词汇表大小的维度,用于预测每个词作为上下文词的概率分布,形状为 (batch_size, 1, vocab_size)return ymodel = SkipGramModel(vocab_size, embedding_dim)
cri = nn.CrossEntropyLoss() # 定义交叉熵损失函数,用于衡量预测概率分布与真实的上下文词之间的差距
optimizer = optim.Adam(model.parameters(), lr=0.01) # 定义Adam优化器,用于更新模型参数bs = 4 # 定义批次大小
epochs = 2000 # 定义训练轮数
for epoch in range(1, epochs + 1):total_loss = 0for batch_index in range(0, len(context), bs):# 上下文的Tensorcontext_tensor = torch.tensor(context[batch_index: batch_index + bs]) # 获取当前批次的上下文词索引,并转换为Tensor,形状为 (batch_size, 2*window_size)# 中心词的tensorcenter_tensor = torch.tensor(center[batch_index: batch_index + bs]).view(bs,1) # 获取当前批次的中心词索引,并转换为Tensor,形状为 (batch_size, 1)output = model(center_tensor) # 将中心词Tensor输入模型,得到预测的上下文词概率分布,形状为 (batch_size, 1, vocab_size)# print(output) # [4, 1, 14]# repeat 用在张量上重复output = output.repeat(1, context_tensor.shape[1], 1) # 将输出在第二个维度(上下文词的个数)上重复,形状为 (batch_size, 2*window_size, vocab_size)output = output.view(-1, 14) # 将输出形状reshape为 (batch_size * 2*window_size, vocab_size),用于计算损失loss = cri(output, context_tensor.view(-1)) # 计算损失,将上下文Tensor也reshape为一维total_loss += lossoptimizer.zero_grad() # 清空梯度loss.backward() # 反向传播计算梯度optimizer.step() # 更新模型参数avg_loss = total_loss / len(context) # 计算平均损失if epoch == 1 or epoch % 50 == 0:print(f"Epoch [{epoch}/{epochs}] Loss {avg_loss:.4f}")# 每个单词的embedding向量word_vec = model.embeddings.data.numpy() # 获取训练后的词嵌入矩阵,形状为 (vocab_size, embedding_dim)# print(word_vec)x = word_vec[:, 0] # 获取所有词嵌入的第一个维度y = word_vec[:, 1] # 获取所有词嵌入的第二个维度selected_word = ["dog", "cat", "milk"] # 选择要可视化的词语selected_word_index = [vocab2int[word] for word in selected_word] # 获取所选词语的索引selected_word_x = x[selected_word_index] # 获取所选词语的x坐标selected_word_y = y[selected_word_index] # 获取所选词语的y坐标plt.cla() # 清除当前轴plt.scatter(selected_word_x, selected_word_y, color="blue") # 绘制所选词语的散点图# 将每个点的标注加上for word, x, y in zip(selected_word, selected_word_x, selected_word_y):plt.annotate(word, (x, y), textcoords="offset points", xytext=(0, 10)) # 为每个散点添加词语标签plt.pause(0.5) # 暂停0.5秒plt.show() # 显示最终的词嵌入可视化结果