Pydantic数据验证实战指南:让Python应用更健壮与智能
导读:在日益复杂的数据驱动开发环境中,如何高效、安全地处理和验证数据成为每位Python开发者面临的关键挑战。本文全面解析了Pydantic这一革命性数据验证库,展示了它如何通过声明式API和类型提示系统,彻底改变Python数据处理模式。
从基础的字段验证到复杂的嵌套模型,从传统的错误处理到与大语言模型的深度集成,文章层层深入,为读者揭示了Pydantic的核心优势:自动类型转换、详细的错误报告、基于类型提示的验证以及卓越的性能表现。通过与传统验证方法的对比,您将看到Pydantic如何显著减少样板代码,提高代码可读性。
文章还探讨了一个引人注目的前沿应用:Pydantic与LLM的结合如何构建更可靠的AI应用?PydanticOutputParser如何确保非结构化LLM输出转为可靠的结构化数据?
无论您是构建Web API、处理复杂配置还是开发AI应用,这篇指南都将帮助您掌握现代Python数据验证的最佳实践。
引言:数据验证的重要性
在当今数据驱动的软件开发环境中,处理外部数据已成为每个应用程序的核心挑战。无论是来自API的响应、用户输入还是配置文件,数据验证都是确保系统稳定性和安全性的关键环节。正如开发界的经典格言所言:“永远不要相信用户的输入”。
Pydantic作为Python生态系统中的明星库,彻底改变了我们处理数据验证和解析的方式。本文将深入探讨Pydantic的核心功能、实践应用以及与大语言模型(LLM)结合的高级用例,帮助开发者构建更加健壮、可靠的Python应用。
一、Pydantic基础:重新定义Python数据验证
1.1 Pydantic的本质与价值
Pydantic是Python生态系统中的数据验证与解析库,通过声明式的方式定义数据模型,并结合Python的类型提示系统提供强大的验证功能。它的核心价值在于:
- 自动类型转换:智能地将输入数据转换为预期类型
- 详细的错误报告:提供清晰的错误信息,便于调试
- 基于类型提示:利用Python的类型注解系统,代码即文档
- 高性能:核心验证逻辑用Rust实现,性能卓越
与传统的数据验证方法相比,Pydantic显著减少了样板代码,提高了代码可读性和可维护性。
1.2 传统验证方法的痛点
在Pydantic出现之前,开发者通常需要编写大量的验证代码。以下对比展示了传统方法与Pydantic的差异:
Java传统方式:
public class User {private String name;private int age;// 需要手写校验方法public void validate() throws IllegalArgumentException {if (name == null || name.isEmpty()) {throw new IllegalArgumentException("姓名不能为空");}if (age > 150) {throw new IllegalArgumentException("年龄不合法");}}
}
传统Python方式:
class User:def __init__(self, name: str, age: int):if not isinstance(name, str):raise TypeError("name必须是字符串")if not isinstance(age, int):raise TypeError("age必须是整数")if age > 150:raise ValueError("年龄必须在0-150之间")self.name = nameself.age = age
Pydantic方式:
from pydantic import BaseModel, Fieldclass User(BaseModel):name: str = Field(min_length=1, max_length=50) # 内置字符串长度验证age: int = Field(ge=0, le=150) # 数值范围验证
Pydantic方式不仅代码量减少,更重要的是将验证规则与数据定义紧密结合,提高了代码的表达力和可维护性。
1.3 安装与基本使用
Pydantic V2是当前的生产版本,需要Python 3.10+:
pip install pydantic==2.7.4
基本使用示例:
from pydantic import BaseModelclass UserProfile(BaseModel):username: str # 必须字段age: int = 18 # 带默认值的字段email: str | None = None # 可选字段# 创建实例
user1 = UserProfile(username="Alice")
print(user1) # username='Alice' age=18 email=None# 自动类型转换
user2 = UserProfile(username="Bob", age="20")
print(user2.age) # 20 (int类型)# 验证失败示例
try:UserProfile(username=123) # 触发验证错误
except ValueError as e:print(e.errors())
二、深入Pydantic字段验证
2.1 Field函数:字段验证的核心
Field函数是Pydantic中为字段添加元数据和验证规则的主要工具。它提供了丰富的参数来定义字段的特性和约束:
from pydantic import BaseModel, Fieldclass Product(BaseModel):name: str = Field(..., # 表示必填字段title="产品名称",description="产品的显示名称",min_length=2,max_length=50)price: float = Field(...,gt=0, # 大于0description="产品价格(元)")tags: list[str] = Field(default_factory=list, # 默认空列表max_length=10 # 最多10个标签)
Field函数的常用参数包括:
| 参数 | 描述 | 适用类型 |
|---|---|---|
| default | 默认值 | 所有类型 |
| title | 字段标题 | 所有类型 |
| description | 详细描述 | 所有类型 |
| min_length/max_length | 长度限制 | 字符串、列表 |
| gt/ge/lt/le | 数值范围 | 数值类型 |
| regex | 正则表达式 | 字符串 |
| example | 示例值 | 所有类型 |
2.2 必填与可选字段
在Pydantic中,字段的必填性由是否提供默认值决定:
from pydantic import BaseModel, Fieldclass User(BaseModel):# 必填字段 (使用...)name: str = Field(..., title="用户名", min_length=2)# 可选字段 (有默认值)age: int = Field(18, ge=0, le=150)# 可为None的字段email: str | None = Field(None, title="电子邮箱")
...是Python中的特殊对象,在Pydantic中表示"无默认值",即该字段必须由用户提供。
2.3 复杂验证场景
嵌套模型验证
Pydantic支持模型嵌套,实现复杂数据结构的验证:
from pydantic import BaseModel, Fieldclass Address(BaseModel):city: str = Field(..., min_length=1)street: strpostal_code: str = Field(..., pattern=r'^\d{5,6}$')class User(BaseModel):name: str = Field(...)address: Address # 嵌套模型# 使用嵌套字典初始化
user = User(name="Alice", address={"city": "Shanghai", "street": "Main St", "postal_code": "200001"}
)
混合类型字段
Pydantic支持联合类型,允许字段接受多种类型的值:
from pydantic import BaseModel
from typing import Unionclass Item(BaseModel):# 可以是整数或字符串id: Union[int, str] # Python 3.10前的写法# 或使用新语法 (Python 3.10+)quantity: int | float # 可以是整数或浮点数
三、自定义验证器:超越基本约束
3.1 field_validator装饰器
当Field参数无法满足复杂验证需求时,可以使用field_validator装饰器实现自定义验证逻辑:
from pydantic import BaseModel, Field, field_validatorclass User(BaseModel):username: strpassword: str@field_validator("username")def validate_username(cls, value: str) -> str:if len(value) < 3:raise ValueError("用户名至少需要3个字符")if not value.isalnum():raise ValueError("用户名只能包含字母和数字")return value@field_validator("password")def validate_password(cls, value: str) -> str:errors = []if len(value) < 8:errors.append("密码至少需要8个字符")if not any(c.isupper() for c in value):errors.append("密码需要至少一个大写字母")if not any(c.isdigit() for c in value):errors.append("密码需要至少一个数字")if errors:raise ValueError("; ".join(errors))return value
3.2 多字段验证器
验证器可以同时应用于多个字段:
from pydantic import BaseModel, field_validatorclass Product(BaseModel):price: floatcost: float@field_validator("price", "cost")def check_positive(cls, v):if v <= 0:raise ValueError("金额必须大于0")return v
3.3 高级验证技巧
依赖其他字段的验证
在某些情况下,一个字段的验证可能依赖于其他字段的值:
from pydantic import BaseModel, field_validatorclass Discount(BaseModel):original_price: floatdiscounted_price: float@field_validator("discounted_price")def validate_discount(cls, v, info):# 获取原始价格original = info.data.get("original_price")if original is not None and v > original:raise ValueError("折扣价不能高于原价")return v
格式化与清理数据
验证器不仅可以验证数据,还可以格式化或清理数据:
from pydantic import BaseModel, field_validatorclass User(BaseModel):email: str@field_validator("email")def normalize_email(cls, v):# 转换为小写并去除空白return v.lower().strip()
四、Pydantic与大语言模型的结合:高级解析器
4.1 为什么需要Pydantic解析器
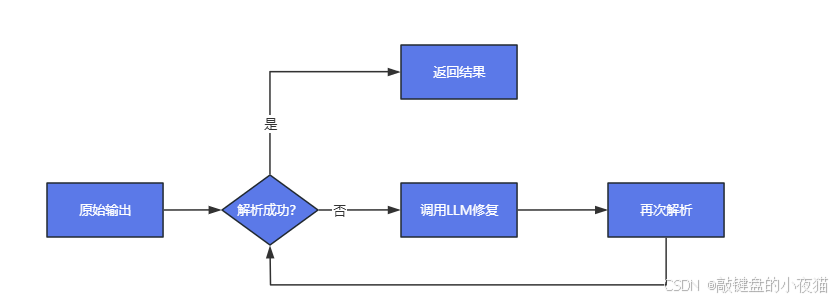
在与大语言模型(LLM)交互时,我们经常需要将其自然语言输出转换为结构化数据。Pydantic解析器提供了以下优势:
- 结构化输出:将非结构化文本转换为可编程对象
- 数据验证:自动验证字段类型和约束条件
- 开发效率:减少手动解析代码
- 错误处理:内置异常捕获与修复机制
4.2 PydanticOutputParser实战
PydanticOutputParser是LangChain库中的一个组件,用于将LLM输出解析为Pydantic模型实例:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate# 定义Pydantic模型
class UserInfo(BaseModel):name: str = Field(description="用户姓名")age: int = Field(description="用户年龄", gt=0)hobbies: list[str] = Field(description="兴趣爱好列表")# 创建解析器
parser = PydanticOutputParser(pydantic_object=UserInfo)# 定义大模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="YOUR_API_KEY",temperature=0.7
)# 构建提示模板
prompt = ChatPromptTemplate.from_template("""
提取用户信息,严格按格式输出:
{format_instructions}用户信息:{input}
""")# 注入格式指令
prompt = prompt.partial(format_instructions=parser.get_format_instructions()
)# 组合处理链
chain = prompt | model | parser# 执行解析
result = chain.invoke({"input": "我的名称是张三,年龄是18岁。兴趣爱好有打篮球、看电影。"
})print(type(result)) # <class '__main__.UserInfo'>
print(result) # name='张三' age=18 hobbies=['打篮球', '看电影']
4.3 JsonOutputParser与Pydantic结合
JsonOutputParser是另一个常用的解析器,它与Pydantic结合使用可以实现更灵活的解析:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser# 定义JSON结构
class SentimentResult(BaseModel):sentiment: strconfidence: floatkeywords: list[str]# 定义大模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="YOUR_API_KEY",temperature=0.7
)# 构建处理链
parser = JsonOutputParser(pydantic_object=SentimentResult)prompt = ChatPromptTemplate.from_template("""
分析评论情感:
{input}
按照JSON格式返回:
{format_instructions}
""")chain = prompt | model | parser# 执行分析
result = chain.invoke({"input": "物流很慢,包装破损严重"})
print(result)
# 输出: sentiment='negative' confidence=0.85 keywords=['物流慢', '包装破损']
JsonOutputParser的一个重要优势是支持流式处理,适用于大型响应:
# 流式调用
for chunk in chain.stream({"input": "物流很慢, 包装破损严重"}):print(chunk) # 逐步输出结果
五、OutputFixingParser:提升解析鲁棒性
5.1 LLM输出修复机制
大语言模型的输出有时会存在格式问题,如JSON语法错误、字段缺失等。OutputFixingParser提供了自动修复这些问题的机制:
from langchain.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import List# 定义模型
class Actor(BaseModel):name: str = Field(description="演员姓名")film_names: List[str] = Field(description="参演电影列表")# 创建基础解析器
parser = PydanticOutputParser(pydantic_object=Actor)# 定义LLM
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="YOUR_API_KEY",temperature=0.7
)# 包装为修复解析器
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
5.2 修复常见格式错误
以下示例展示了如何修复常见的JSON格式错误:
# 模拟格式错误的输出 (使用单引号而非双引号)
misformatted_output = "{'name': '成龙', 'film_names': ['宝贝计划','十二生肖','警察故事']}"# 直接解析会失败
try:parsed_data = parser.parse(misformatted_output)
except Exception as e:print(f"解析失败: {e}") # 输出: 解析失败: JSONDecodeError...# 使用修复解析器
fixed_data = fixing_parser.parse(misformatted_output)
print(type(fixed_data)) # <class '__main__.Actor'>
print(fixed_data.model_dump()) # {'name': '成龙', 'film_names': ['宝贝计划', '十二生肖', '警察故事']}
OutputFixingParser的工作原理是:
- 检测到错误后,将错误信息与原始输入传递给LLM
- LLM根据提示生成符合Pydantic模型的修正结果
- 返回修正后的结构化数据
5.3 提高解析成功率的最佳实践
为了最大限度地提高解析成功率,可以采取以下措施:
- 明确的格式说明:在提示中提供详细的输出格式指南
- 示例驱动:提供正确格式的示例,帮助模型理解期望输出
- 降低模型温度:对于结构化输出,使用较低的temperature值(0.0-0.3)
- 多次重试:设置适当的重试次数
- 错误处理:实现优雅的错误处理机制
# 增强修复解析器配置
enhanced_fixing_parser = OutputFixingParser.from_llm(parser=parser,llm=model,max_retries=2 # 最多重试2次
)# 错误处理示例
try:result = enhanced_fixing_parser.parse(problematic_output)# 成功解析process_valid_data(result)
except Exception as e:# 即使修复也失败handle_parsing_failure(e, problematic_output)
六、实际应用场景与最佳实践
6.1 API请求/响应验证
Pydantic在FastAPI等现代Web框架中广泛用于API请求和响应验证:
from fastapi import FastAPI
from pydantic import BaseModel, Fieldapp = FastAPI()class CreateUserRequest(BaseModel):username: str = Field(..., min_length=3)email: strpassword: str = Field(..., min_length=8)class UserResponse(BaseModel):id: intusername: stremail: str@app.post("/users/", response_model=UserResponse)
async def create_user(user: CreateUserRequest):# FastAPI自动验证请求体# 并将响应序列化为UserResponse格式db_user = await database.create_user(user.username, user.email, user.password)return db_user
6.2 配置管理
Pydantic非常适合处理应用程序配置:
from pydantic import BaseModel, Field
from pydantic_settings import BaseSettings
import osclass DatabaseSettings(BaseModel):host: str = "localhost"port: int = 5432username: strpassword: strdatabase: strclass AppSettings(BaseSettings):app_name: str = "MyApp"debug: bool = Field(default=False, description="启用调试模式")database: DatabaseSettings# 从环境变量加载配置class Config:env_prefix = "MYAPP_"env_nested_delimiter = "__"# 使用
settings = AppSettings(database=DatabaseSettings(username=os.getenv("DB_USER"),password=os.getenv("DB_PASS"),database="myapp")
)
6.3 LLM应用中的结构化输出
在构建LLM应用时,Pydantic可以确保输出符合预期格式:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field, field_validator
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate# 定义产品推荐模型
class ProductRecommendation(BaseModel):product_name: str = Field(description="推荐产品名称")price_range: str = Field(description="价格范围,例如'100-200元'")reasons: list[str] = Field(description="推荐理由列表,至少3条")@field_validator("reasons")def validate_reasons(cls, v):if len(v) < 3:raise ValueError("推荐理由至少需要3条")return v# 创建解析器和链
parser = PydanticOutputParser(pydantic_object=ProductRecommendation)
model = ChatOpenAI(temperature=0.2)prompt = ChatPromptTemplate.from_template("""
根据用户需求推荐一款产品:
{user_needs}{format_instructions}
""")chain = (prompt.partial(format_instructions=parser.get_format_instructions())| model| parser
)# 使用
recommendation = chain.invoke({"user_needs": "我需要一款性价比高的笔记本电脑,主要用于办公和轻度设计"
})print(f"推荐产品: {recommendation.product_name}")
print(f"价格范围: {recommendation.price_range}")
print("推荐理由:")
for i, reason in enumerate(recommendation.reasons, 1):print(f"{i}. {reason}")
6.4 性能优化建议
在处理大量数据时,可以考虑以下性能优化建议:
- 使用model_construct:对于已知有效的数据,使用
model_construct跳过验证 - 延迟验证:使用
validate=False创建模型,在需要时手动调用model_validate - 自定义验证器优化:避免在验证器中执行耗时操作
- 批量处理:处理大量数据时使用批量验证
# 性能优化示例
from pydantic import BaseModel
import timeclass Item(BaseModel):name: strprice: float# 标准方法
start = time.time()
items1 = [Item(name=f"item{i}", price=i*1.5) for i in range(10000)]
print(f"标准方法: {time.time() - start:.4f}秒")# 优化方法 - 使用model_construct
start = time.time()
items2 = [Item.model_construct(name=f"item{i}", price=i*1.5) for i in range(10000)]
print(f"使用model_construct: {time.time() - start:.4f}秒")
七、Pydantic V2的新特性与迁移指南
7.1 V1与V2的主要区别
Pydantic V2是对库的重大重写,带来了许多改进和API变化:
| 功能 | Pydantic V1 | Pydantic V2 |
|---|---|---|
| 性能 | 纯Python实现 | 核心验证逻辑用Rust实现,性能提升5-50倍 |
| 类型系统 | 有限支持 | 更全面的类型支持,包括TypedDict |
| API | 原始API | 更一致的命名约定 |
| 验证器 | @validator | @field_validator 和 @model_validator |
| 序列化 | dict() | model_dump() |
| JSON解析 | parse_raw() | model_validate_json() |
7.2 API变更对照表
以下是V1到V2的主要API变更:
| Pydantic V1 | Pydantic V2 |
|---|---|
| fields | model_fields |
| private_attributes | pydantic_private |
| validators | pydantic_validator |
| construct() | model_construct() |
| copy() | model_copy() |
| dict() | model_dump() |
| json_schema() | model_json_schema() |
| json() | model_dump_json() |
| parse_obj() | model_validate() |
| update_forward_refs() | model_rebuild() |
7.3 迁移策略
从V1迁移到V2的建议步骤:
- 更新依赖:确保Python版本≥3.10,更新pydantic到最新版本
- API调整:使用新的方法名称(如
model_dump替代dict) - 验证器更新:将
@validator替换为@field_validator - 类型注解检查:确保类型注解与V2兼容
- 测试覆盖:确保充分的测试覆盖,验证迁移后的功能正确性
# Pydantic V1
from pydantic import BaseModel, validatorclass UserV1(BaseModel):name: strage: int@validator('age')def check_age(cls, v):if v < 0:raise ValueError('年龄不能为负数')return vdef to_dict(self):return self.dict()# Pydantic V2
from pydantic import BaseModel, field_validatorclass UserV2(BaseModel):name: strage: int@field_validator('age')def check_age(cls, v):if v < 0:raise ValueError('年龄不能为负数')return vdef to_dict(self):return self.model_dump()
八、结论与展望
Pydantic已经成为Python生态系统中数据验证和解析的标准工具,其声明式API和强大的验证功能使其在Web开发、数据处理和AI应用中不可或缺。
随着AI和大语言模型的兴起,Pydantic与LangChain等框架的结合为构建可靠的AI应用提供了坚实基础。通过PydanticOutputParser和OutputFixingParser等工具,开发者可以轻松地将非结构化的LLM输出转换为结构化数据,实现更复杂的应用场景。
未来,随着Pydantic继续发展,我们可以期待:
- 更深入的AI集成:与更多AI框架的无缝集成
- 更高的性能:进一步优化Rust核心,提供更快的验证速度
- 更丰富的生态系统:更多基于Pydantic的工具和扩展
对于Python开发者来说,掌握Pydantic不仅能提高日常开发效率,还能为构建下一代AI应用打下坚实基础。无论是构建API、处理配置还是与大语言模型交互,Pydantic都是不可或缺的工具。
参考资源
- Pydantic官方文档
- LangChain文档
- FastAPI与Pydantic
- Pydantic V2迁移指南