基于CNN的猫狗识别(自定义Resnet-18模型)
目录
一,数据集介绍
1.1 数据集下载
1.2 数据集简介
二,Resnet介绍
2.1 Resnet简介
2.2 Resnet核心思想
2.3 Resnet优势
2.4 Resnet的两种残差块
2.5 为什么Resnet可以堆叠100层以上
三,模型训练
3.1 功能包导入及基础配置
3.2 数据集的加载与分割
3.3 训练集和验证集的预处理
3.4 定义Resnet-18模型
3.5 初始化设备及优化器
3.6 训练和验证
四,测试结果
4.1 训练集结果
4.2 测试集结果
4.3 总结
五,完整代码
5.1 模型训练部分代码
5.2 模型测试部分代码
一,数据集介绍
1.1 数据集下载
本数据集下载自:
Cat and Dog | Kaggle
1.2 数据集简介
该数据集分为训练集和测试集,其中训练集包含4000张"cat"照片和4000张"dog"照片。测试集包括1000+"cat"照片和1000+"dog"照片
二,Resnet介绍
2.1 Resnet简介
ResNet(Residual Neural Network,残差网络)是深度学习领域中具有里程碑意义的卷积神经网络(CNN)架构,由何恺明等人于 2015 年提出,首次在 ImageNet 图像识别大赛中夺冠,解决了深度神经网络训练中的梯度消失 / 爆炸和退化问题,极大推动了计算机视觉及深度学习的发展。
2.2 Resnet核心思想
传统 CNN 随着网络层数增加,训练误差可能先下降后上升(退化问题),本质是深层网络难以优化。ResNet 通过引入残差块(Residual Block),让网络学习输入与输出之间的残差关系,公式为:

2.3 Resnet优势
缓解梯度消失:恒等映射路径允许梯度直接反向传播,避免深层网络因参数更新困难导致的梯度消失。
支持更深的网络:通过堆叠残差块,ResNet 可轻松构建数十层甚至上百层的网络,且性能持续提升。
2.4 Resnet的两种残差块
基本残差块结构:

瓶颈残差块结构:

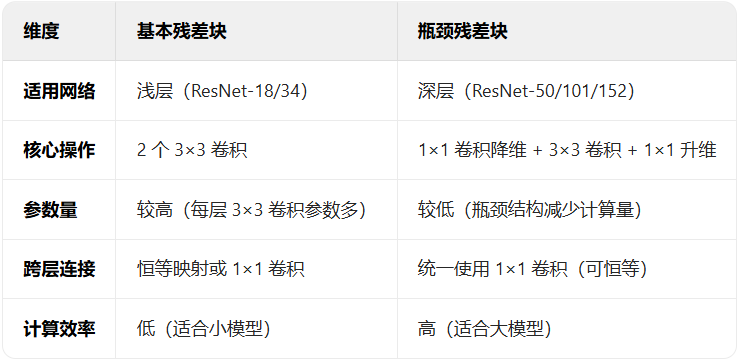
本质差异:基本块注重结构简洁,瓶颈块注重效率与深度的平衡。两者共同体现了 ResNet “通过跨层连接让网络更易优化” 的核心思想,并成为后续深度学习架构(如 ResNeXt、EfficientNet)的设计基础。
2.5 为什么Resnet可以堆叠100层以上
ResNet 之所以能够堆叠一百层以上,核心在于其独特的残差学习机制与跨层连接设计:通过残差块的恒等映射路径(快捷连接),梯度可直接反向传播至浅层,有效缓解了深层网络中常见的梯度消失 / 爆炸问题;同时,残差块允许网络在性能无法提升时通过学习恒等映射(即输出等于输入)来 “退化” 为浅层结构,解决了传统网络的退化问题。此外,瓶颈残差块通过 “1×1 卷积降维 + 3×3 卷积提取特征 + 1×1 卷积升维” 的结构显著减少参数量,结合分层 Stage 设计与批量归一化(BN)技术,在保证计算效率的同时稳定了训练过程。
三,模型训练
3.1 功能包导入及基础配置
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms, models # 导入预训练模型库
import matplotlib.pyplot as plt
import numpy as np# --------------------------- 基础配置 ---------------------------
# 设置中文字体支持,确保图表中的中文正常显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 避免Jupyter环境下的库冲突问题# 设置随机种子,保证实验可复现
torch.manual_seed(42)
np.random.seed(42)3.2 数据集的加载与分割
# --------------------------- 加载数据集 ---------------------------
# 创建训练集和验证集,使用不同的预处理方法
train_dataset = datasets.ImageFolder(data_dir, transform=train_transform)
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform)# 按8:2比例划分训练集和验证集
train_size = int(0.8 * len(train_dataset))
val_size = len(train_dataset) - train_size
generator = torch.Generator().manual_seed(42) # 固定随机数生成器种子
train_indices, val_indices = random_split(range(len(train_dataset)), [train_size, val_size], generator=generator
)# 根据划分的索引创建子集
train_dataset = torch.utils.data.Subset(train_dataset, train_indices)
val_dataset = torch.utils.data.Subset(val_dataset, val_indices)# --------------------------- 数据加载器 ---------------------------
# 创建训练数据加载器,设置批大小和打乱顺序
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 创建验证数据加载器,不打乱顺序
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)验证集的作用是在模型训练过程中,用于评估模型在未见过数据上的泛化能力、调整超参数(如学习率、正则化系数等)、监控模型是否过拟合或欠拟合。通过在验证集上观察损失值和指标变化,可及时优化模型结构或训练策略,避免直接在测试集上调参导致的信息泄露,确保最终在测试集上的评估结果能真实反映模型的实际性能。
3.3 训练集和验证集的预处理
# --------------------------- 数据预处理 ---------------------------
# 训练集数据增强和标准化处理
train_transform = transforms.Compose([transforms.Resize((256, 256)), # 调整图像大小为256x256transforms.RandomRotation(15), # 随机旋转±15度,增加图像多样性transforms.RandomCrop(224), # 随机裁剪出224x224的区域transforms.RandomHorizontalFlip(), # 随机水平翻转图像transforms.ToTensor(), # 转换为Tensor格式# 使用预计算的均值和标准差进行归一化,加速收敛transforms.Normalize([0.4883, 0.4551, 0.4174], [0.2596, 0.2526, 0.2552])
])# 验证集仅需进行尺寸调整和标准化,不进行数据增强
val_transform = transforms.Compose([transforms.Resize((224, 224)), # 直接缩放到224x224transforms.ToTensor(), # 转换为张量# 使用与训练集相同的均值和标准差进行标准化transforms.Normalize([0.4883, 0.4551, 0.4174], [0.2596, 0.2526, 0.2552])
])在训练集的与处理中,加入了对于原始图像的裁剪,翻转,旋转等简单的预处理方法以提高模型的泛化能力。在验证集中,不需要对图片进行类似的操作。
3.4 定义Resnet-18模型
# --------------------------- 定义ResNet-18模型(迁移学习)---------------------------
def create_resnet_model(pretrained=True):"""创建基于ResNet-18的猫狗分类模型"""# 使用预训练权重初始化ResNet-18模型weights = models.ResNet18_Weights.IMAGENET1K_V1 if pretrained else Nonemodel = models.resnet18(weights=weights)# 修改最后一层全连接层# 获取原始全连接层的输入特征数in_features = model.fc.in_features# 替换为适应猫狗分类任务的输出层(2类)model.fc = nn.Linear(in_features, 2)return model迁移学习通过复用预训练模型在大规模数据中学习到的通用特征,显著降低对目标任务数据量和计算资源的需求,缩短模型训练周期;其跨领域适配能力可将源领域知识迁移至数据稀缺或标注成本高的目标领域,有效避免从头训练的过拟合风险,尤其适用于医疗影像分析、自然语言处理等数据受限场景,大幅提升模型泛化能力和开发效率。
3.5 初始化设备及优化器
# --------------------------- 初始化设备和模型 ---------------------------
# 自动选择计算设备(GPU优先)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 创建模型并移至指定设备
model = create_resnet_model(pretrained=True).to(device)# --------------------------- 损失函数和优化器 ---------------------------
# 定义交叉熵损失函数,适用于多分类任务
criterion = nn.CrossEntropyLoss()
# 使用Adam优化器,设置学习率
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学习率调度器:当验证损失停滞时降低学习率
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5
)学习率调度器的作用是在模型训练过程中动态调整学习率,以平衡训练速度和优化效果:初始阶段采用较大学习率加速收敛,后期逐步降低学习率避免错过最优解或导致训练震荡,从而提升模型收敛效率、优化最终性能并防止过拟合。
在本代码中,学习率调度器(ReduceLROnPlateau)的工作机制如下:在每个训练周期(epoch)结束后,计算模型在验证集上的损失值,并通过scheduler.step(val_loss)将该值传递给调度器。调度器会维护一个验证损失的历史记录,并与当前损失进行比较。若连续 3 个周期(由patience=3控制)验证损失未达到更低值(即模型性能停滞),则触发学习率调整。此时,调度器会将优化器(Adam)的学习率乘以 0.5(由factor=0.5控制),例如从初始的 0.001 降至 0.0005。这一过程会在每个周期自动执行,使学习率能够根据模型在验证集上的实际表现动态调整,从而平衡训练速度与收敛稳定性,避免因学习率过大导致震荡或过小导致收敛缓慢的问题。
3.6 训练和验证
# --------------------------- 训练和验证函数 ---------------------------
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs):"""训练模型并返回训练历史"""best_val_acc = 0.0history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}for epoch in range(epochs):# --------------------------- 训练阶段 ---------------------------model.train() # 设置为训练模式train_loss = 0.0train_correct = 0train_total = 0# 遍历训练数据批次for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)# 梯度清零,防止累积optimizer.zero_grad()# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化loss.backward()optimizer.step()# 统计训练损失和准确率train_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)train_total += labels.size(0)train_correct += predicted.eq(labels).sum().item()# 计算平均训练损失和准确率train_loss /= len(train_dataset)train_acc = 100.0 * train_correct / train_total# --------------------------- 验证阶段 ---------------------------model.eval() # 设置为评估模式val_loss = 0.0val_correct = 0val_total = 0# 禁用梯度计算,提高验证效率with torch.no_grad():for inputs, labels in val_loader:inputs, labels = inputs.to(device), labels.to(device)# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 统计验证损失和准确率val_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)val_total += labels.size(0)val_correct += predicted.eq(labels).sum().item()# 计算平均验证损失和准确率val_loss /= len(val_dataset)val_acc = 100.0 * val_correct / val_total# --------------------------- 学习率调整和模型保存 ---------------------------# 根据验证损失调整学习率scheduler.step(val_loss)# 保存最佳模型if val_acc > best_val_acc:best_val_acc = val_acctorch.save(model.state_dict(), 'cat_dog_resnet.pth')print(f'保存最佳模型: 验证准确率 = {val_acc:.2f}%')# --------------------------- 结果记录 ---------------------------history['train_loss'].append(train_loss)history['train_acc'].append(train_acc)history['val_loss'].append(val_loss)history['val_acc'].append(val_acc)# 打印当前轮次训练结果print(f'Epoch {epoch + 1}/{epochs}')print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')print('-' * 50)return model, history四,测试结果
4.1 训练集结果
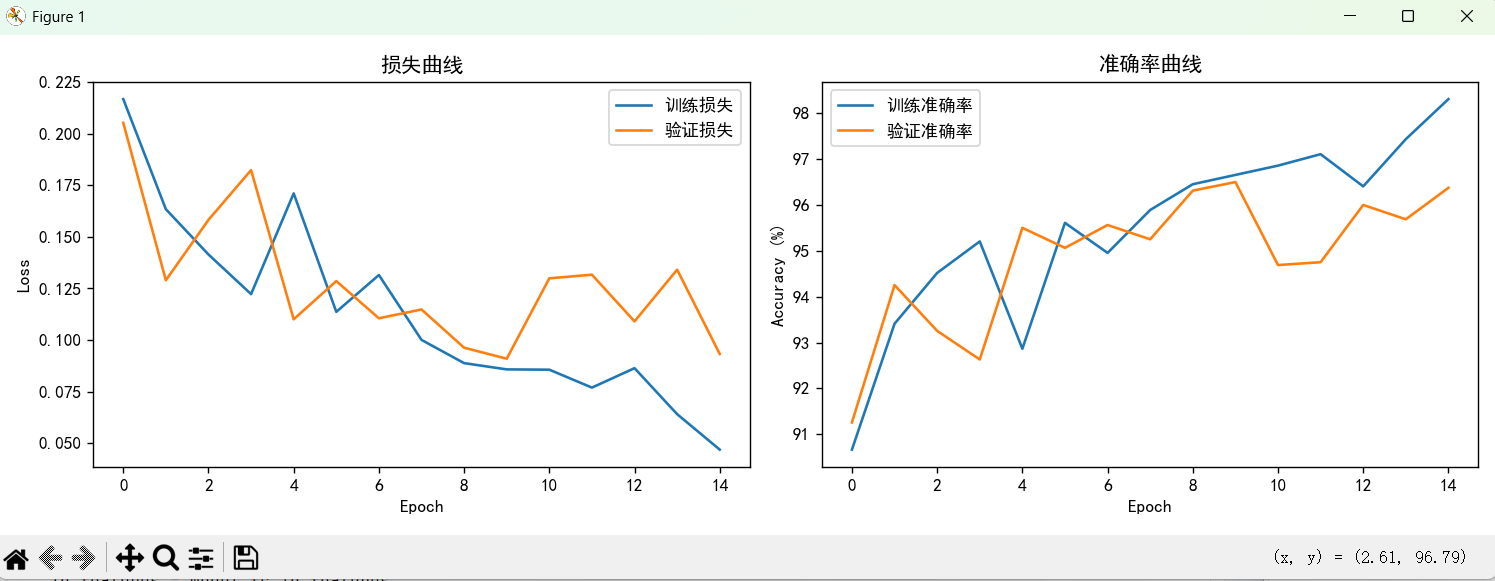
训练集和验证集上的损失与准确率曲线

最后该模型能达到96%以上的正确率
4.2 测试集结果
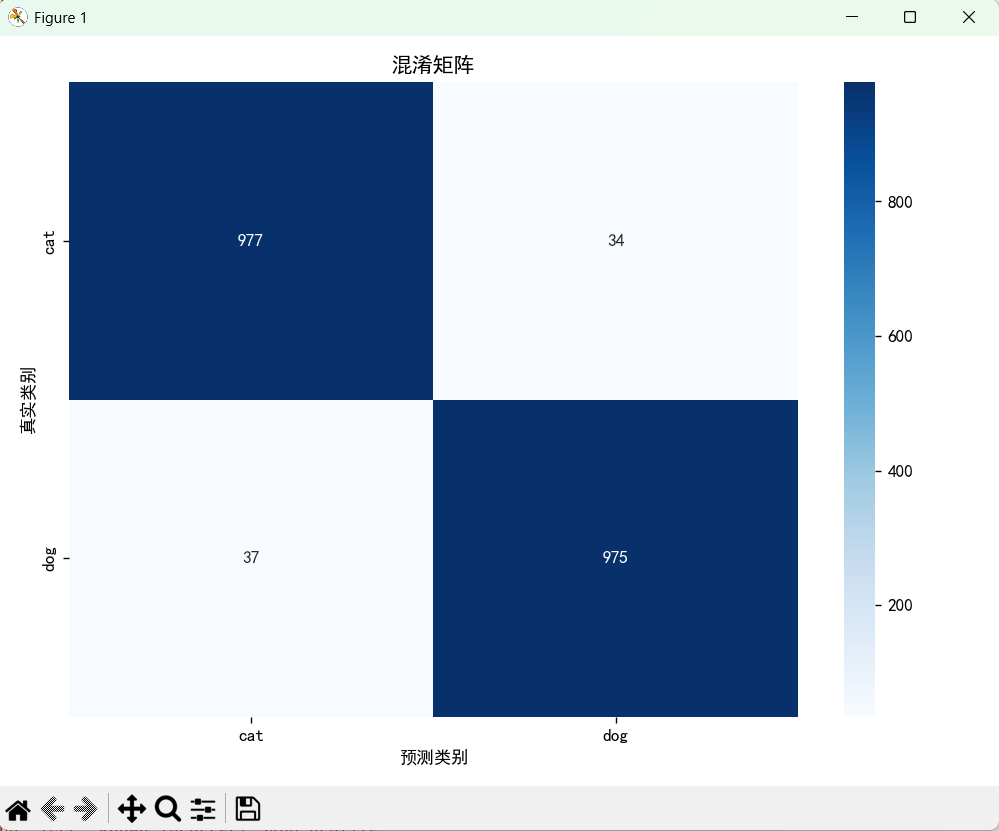

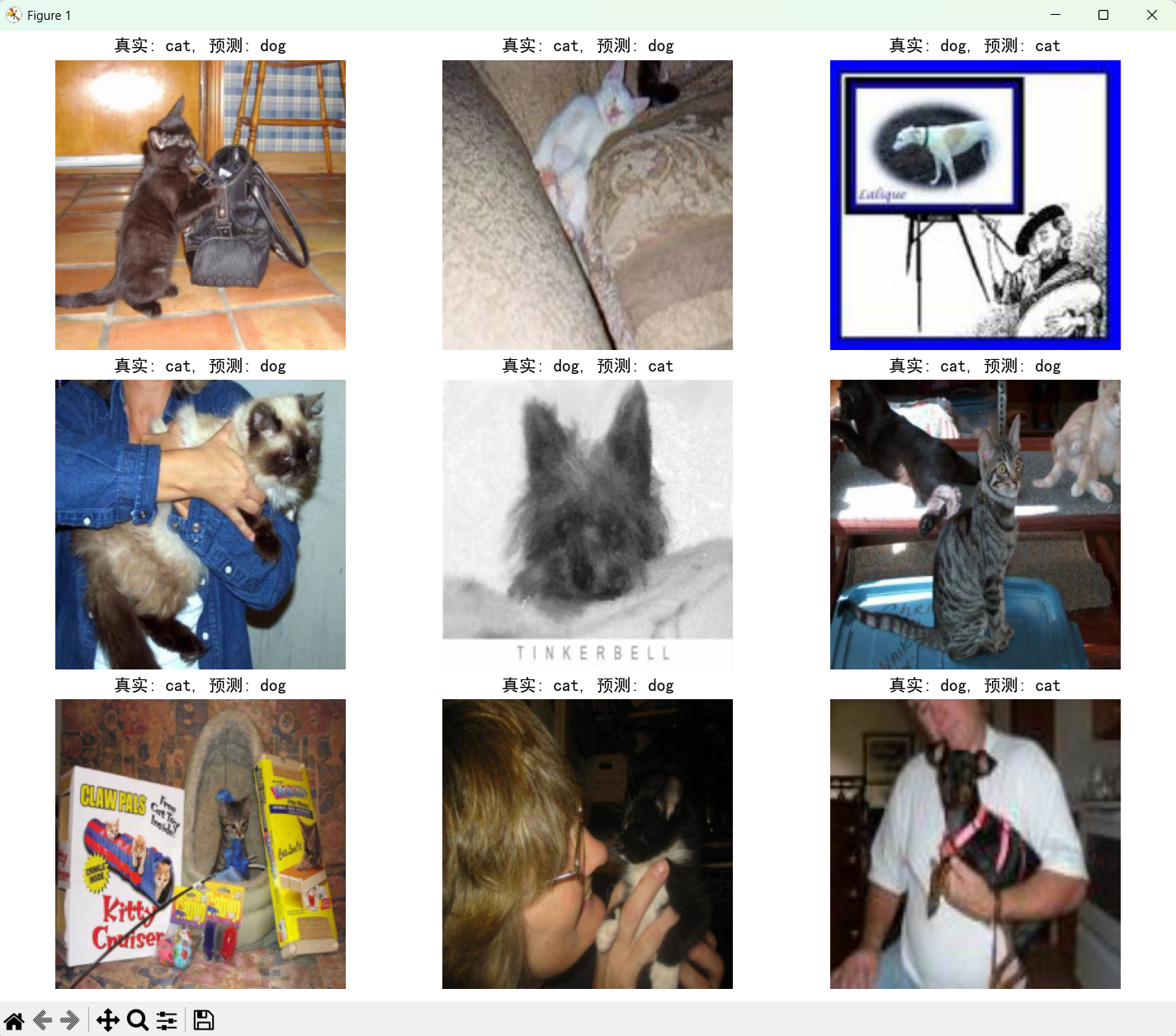
4.3 总结
相比之前的仅用简单的CNN模型进行猫狗图像的预测,使用Resnet18进行迁移学习的效果提升了不少,当然当前代码也有很多值得改进的 地方,比如在上面显示出来的识别错误的图像中,有一部分是因为图像的预处理而产生的错误。Resnet是图像处理中一个划时代的产物,具有里程碑式的意义。
五,完整代码
5.1 模型训练部分代码
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms, models # 导入预训练模型库
import matplotlib.pyplot as plt
import numpy as np# --------------------------- 基础配置 ---------------------------
# 设置中文字体支持,确保图表中的中文正常显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 避免Jupyter环境下的库冲突问题# 设置随机种子,保证实验可复现
torch.manual_seed(42)
np.random.seed(42)# --------------------------- 数据预处理 ---------------------------
# 训练集数据增强和标准化处理
train_transform = transforms.Compose([transforms.Resize((256, 256)), # 调整图像大小为256x256transforms.RandomRotation(15), # 随机旋转±15度,增加图像多样性transforms.RandomCrop(224), # 随机裁剪出224x224的区域transforms.RandomHorizontalFlip(), # 随机水平翻转图像transforms.ToTensor(), # 转换为Tensor格式# 使用预计算的均值和标准差进行归一化,加速收敛transforms.Normalize([0.4883, 0.4551, 0.4174], [0.2596, 0.2526, 0.2552])
])# 验证集仅需进行尺寸调整和标准化,不进行数据增强
val_transform = transforms.Compose([transforms.Resize((224, 224)), # 直接缩放到224x224transforms.ToTensor(), # 转换为张量# 使用与训练集相同的均值和标准差进行标准化transforms.Normalize([0.4883, 0.4551, 0.4174], [0.2596, 0.2526, 0.2552])
])# 数据集路径配置
data_dir = r'C:\Users\10532\Desktop\Study\Test\Data\catordog\training_set\training_set'# --------------------------- 加载数据集 ---------------------------
# 创建训练集和验证集,使用不同的预处理方法
train_dataset = datasets.ImageFolder(data_dir, transform=train_transform)
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform)# 按8:2比例划分训练集和验证集
train_size = int(0.8 * len(train_dataset))
val_size = len(train_dataset) - train_size
generator = torch.Generator().manual_seed(42) # 固定随机数生成器种子
train_indices, val_indices = random_split(range(len(train_dataset)), [train_size, val_size], generator=generator
)# 根据划分的索引创建子集
train_dataset = torch.utils.data.Subset(train_dataset, train_indices)
val_dataset = torch.utils.data.Subset(val_dataset, val_indices)# --------------------------- 数据加载器 ---------------------------
# 创建训练数据加载器,设置批大小和打乱顺序
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 创建验证数据加载器,不打乱顺序
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)# --------------------------- 定义ResNet-18模型(迁移学习)---------------------------
def create_resnet_model(pretrained=True):"""创建基于ResNet-18的猫狗分类模型"""# 使用预训练权重初始化ResNet-18模型weights = models.ResNet18_Weights.IMAGENET1K_V1 if pretrained else Nonemodel = models.resnet18(weights=weights)# 修改最后一层全连接层# 获取原始全连接层的输入特征数in_features = model.fc.in_features# 替换为适应猫狗分类任务的输出层(2类)model.fc = nn.Linear(in_features, 2)return model# --------------------------- 初始化设备和模型 ---------------------------
# 自动选择计算设备(GPU优先)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 创建模型并移至指定设备
model = create_resnet_model(pretrained=True).to(device)# --------------------------- 损失函数和优化器 ---------------------------
# 定义交叉熵损失函数,适用于多分类任务
criterion = nn.CrossEntropyLoss()
# 使用Adam优化器,设置学习率
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学习率调度器:当验证损失停滞时降低学习率
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5
)# --------------------------- 训练和验证函数 ---------------------------
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs):"""训练模型并返回训练历史"""best_val_acc = 0.0history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}for epoch in range(epochs):# --------------------------- 训练阶段 ---------------------------model.train() # 设置为训练模式train_loss = 0.0train_correct = 0train_total = 0# 遍历训练数据批次for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)# 梯度清零,防止累积optimizer.zero_grad()# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化loss.backward()optimizer.step()# 统计训练损失和准确率train_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)train_total += labels.size(0)train_correct += predicted.eq(labels).sum().item()# 计算平均训练损失和准确率train_loss /= len(train_dataset)train_acc = 100.0 * train_correct / train_total# --------------------------- 验证阶段 ---------------------------model.eval() # 设置为评估模式val_loss = 0.0val_correct = 0val_total = 0# 禁用梯度计算,提高验证效率with torch.no_grad():for inputs, labels in val_loader:inputs, labels = inputs.to(device), labels.to(device)# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 统计验证损失和准确率val_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)val_total += labels.size(0)val_correct += predicted.eq(labels).sum().item()# 计算平均验证损失和准确率val_loss /= len(val_dataset)val_acc = 100.0 * val_correct / val_total# --------------------------- 学习率调整和模型保存 ---------------------------# 根据验证损失调整学习率scheduler.step(val_loss)# 保存最佳模型if val_acc > best_val_acc:best_val_acc = val_acctorch.save(model.state_dict(), 'cat_dog_resnet.pth')print(f'保存最佳模型: 验证准确率 = {val_acc:.2f}%')# --------------------------- 结果记录 ---------------------------history['train_loss'].append(train_loss)history['train_acc'].append(train_acc)history['val_loss'].append(val_loss)history['val_acc'].append(val_acc)# 打印当前轮次训练结果print(f'Epoch {epoch + 1}/{epochs}')print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')print('-' * 50)return model, history# --------------------------- 开始训练 ---------------------------
print("开始训练ResNet-18模型...")
model, history = train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs=15)# --------------------------- 结果可视化 ---------------------------
plt.figure(figsize=(12, 4))# 绘制损失曲线
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='训练损失')
plt.plot(history['val_loss'], label='验证损失')
plt.legend()
plt.title('损失曲线')
plt.xlabel('Epoch')
plt.ylabel('Loss')# 绘制准确率曲线
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='训练准确率')
plt.plot(history['val_acc'], label='验证准确率')
plt.legend()
plt.title('准确率曲线')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.tight_layout()
plt.show()# 输出最佳验证准确率
print(f"最佳验证集准确率: {max(history['val_acc']):.2f}%")5.2 模型测试部分代码
import os
import torch
import torch.nn as nn
from torchvision import datasets, transforms, models
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
# --------------------------- 添加字体配置 ---------------------------
# 设置中文字体(需根据系统选择合适字体)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)# --------------------------- 模型定义 ---------------------------
def create_resnet_model(pretrained=False):# 修改:使用新的weights参数替代pretrainedif pretrained:model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)else:model = models.resnet18(weights=None)in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, 2) # 猫狗二分类return model# --------------------------- 数据预处理 ---------------------------
test_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.4883, 0.4551, 0.4174], [0.2596, 0.2526, 0.2552])
])# --------------------------- 测试函数 ---------------------------
def test_model(model_path, test_dir=None, single_image_path=None, batch_size=32):"""测试训练好的模型Args:model_path: 模型权重文件路径test_dir: 测试数据集目录(格式同训练集)single_image_path: 单张图像测试路径batch_size: 批量大小"""device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 加载模型model = create_resnet_model()model.load_state_dict(torch.load(model_path, map_location=device))model.to(device)model.eval()# 单张图像测试if single_image_path:predict_single_image(model, single_image_path, device)# 测试集批量测试if test_dir:test_loader = prepare_test_loader(test_dir, batch_size)evaluate_model(model, test_loader, device)# --------------------------- 准备测试数据加载器 ---------------------------
def prepare_test_loader(test_dir, batch_size):test_dataset = datasets.ImageFolder(test_dir, transform=test_transform)test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)print(f"测试集大小: {len(test_dataset)}")print(f"类别映射: {test_dataset.class_to_idx}")return test_loader# --------------------------- 单张图像预测 ---------------------------
def predict_single_image(model, image_path, device):"""预测单张图像"""# 加载图像image = Image.open(image_path).convert('RGB')image_tensor = test_transform(image).unsqueeze(0).to(device)# 预测with torch.no_grad():outputs = model(image_tensor)probs = torch.nn.functional.softmax(outputs, dim=1)confidence, pred_class = torch.max(probs, 1)# 类别名称映射class_names = ['cat', 'dog']pred_label = class_names[pred_class.item()]# 显示图像和预测结果plt.figure(figsize=(6, 4))plt.imshow(np.array(image))plt.title(f"预测结果: {pred_label}\n置信度: {confidence.item():.4f}")plt.axis('off')plt.tight_layout()plt.savefig('single_prediction_result.png')plt.show()print(f"预测类别: {pred_label}")print(f"置信度: {confidence.item():.4f}")print(f"各类别概率: {probs.cpu().numpy()[0]}")# --------------------------- 评估模型 ---------------------------
def evaluate_model(model, test_loader, device):"""在测试集上评估模型"""all_labels = []all_preds = []all_probs = []with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)probs = torch.nn.functional.softmax(outputs, dim=1)_, preds = torch.max(probs, 1)all_labels.extend(labels.cpu().numpy())all_preds.extend(preds.cpu().numpy())all_probs.extend(probs.cpu().numpy())# 计算准确率accuracy = np.mean(np.array(all_labels) == np.array(all_preds)) * 100print(f"测试集准确率: {accuracy:.2f}%")# 打印分类报告class_names = ['cat', 'dog']print("\n分类报告:")print(classification_report(all_labels, all_preds, target_names=class_names))# 绘制混淆矩阵cm = confusion_matrix(all_labels, all_preds)plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=class_names, yticklabels=class_names)plt.xlabel('预测类别')plt.ylabel('真实类别')plt.title('混淆矩阵')plt.tight_layout()plt.savefig('confusion_matrix_test.png')plt.show()# 可视化错误预测的样本visualize_misclassified(all_labels, all_preds, test_loader, class_names)# --------------------------- 可视化错误分类的样本 ---------------------------
def visualize_misclassified(true_labels, pred_labels, test_loader, class_names):"""可视化错误分类的样本"""misclassified_indices = []for i, (true, pred) in enumerate(zip(true_labels, pred_labels)):if true != pred:misclassified_indices.append(i)if not misclassified_indices:print("所有样本均预测正确!")returnprint(f"错误分类样本数: {len(misclassified_indices)}")# 随机选择最多9个错误样本进行可视化np.random.shuffle(misclassified_indices)misclassified_indices = misclassified_indices[:9]fig, axes = plt.subplots(3, 3, figsize=(12, 12))axes = axes.flatten()for i, idx in enumerate(misclassified_indices):# 获取样本在数据加载器中的位置batch_idx = idx // test_loader.batch_sizesample_idx = idx % test_loader.batch_size# 获取图像和标签inputs, labels = list(test_loader)[batch_idx]image = inputs[sample_idx].permute(1, 2, 0).numpy()image = (image * np.array([0.2596, 0.2526, 0.2552]) +np.array([0.4883, 0.4551, 0.4174])) # 反归一化image = np.clip(image, 0, 1)true_label = class_names[labels[sample_idx].item()]pred_label = class_names[pred_labels[idx]]axes[i].imshow(image)axes[i].set_title(f"真实: {true_label}, 预测: {pred_label}")axes[i].axis('off')plt.tight_layout()plt.savefig('misclassified_samples.png')plt.show()# --------------------------- 主函数 ---------------------------
if __name__ == "__main__":# 设置参数model_path = 'cat_dog_resnet.pth' # 训练好的模型路径test_dir = r'C:\Users\10532\Desktop\Study\Test\Data\catordog\test_set\test_set' # 测试集路径single_image_path = None # 单张图像测试路径(如需要)# 测试模型test_model(model_path=model_path,test_dir=test_dir,single_image_path=single_image_path)