【DeepSeek论文解读】DeepSeek LLM和DeepSeek Moe解读
本文主要是整理了deepseek系列论文,做一个简要的阅读和概览。希望可以对大家有所帮助。
DeepSeek发展概览
deepseek:DeepSeek · GitHub
| 版本 | 发布时间 | 链接 | 概况 | 性能 |
| DeepSeek LLM | 2024.1 | https://arxiv.org/pdf/2401.02954 | 训练采用LLaMA架构,GQA+多阶段训练 | 训练速度提升20% |
| DeepSeek MOE | 2024.1 | https://arxiv.org/pdf/2401.06066 | 采用switch transformer结构,负载均衡优化loss | 推理成本降低60% |
| DeepSeek V2 | 2024.6 | https://arxiv.org/pdf/2405.04434 | 采用MLA结构 | 训练成本降低42.5% |
| DeepSeek V3 | 2024.12 | https://arxiv.org/pdf/2412.19437 | Multi-Token Prediction(MTP,多令牌预测) 训练加速:FP8混合精度训练/DualPipe跨节点通信/MOE负载均衡 | 首个在 Arena-Hard 测试中突破 85% 的开源模型 训练成本降低 |
| DeepSeek R1 | 2025.1 | https://arxiv.org/pdf/2501.12948 | DeepSeekR1-Zero | 推理基准测试中达到 OpenAI-o1-0912 |
| DeepSeek R1 | 推理基准测试集 达到OpenAI-o1-1217 | |||
| DeepSeek-R1-Distil |
备注:DeepSeek-MATH:https://arxiv.org/pdf/2402.03300
前言
LLama
transforme rarchitecture, as well as our training method.
- GPT3 Pre-normalization
使用GPT3的预标准化。为了提高训练稳定性,对每个Transformer子层的输入进行归一化,而不是对输出进行归一化。使用由RMSNorm 归一化函数
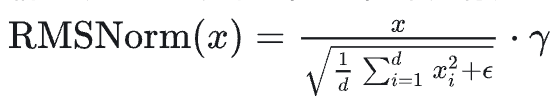
- swiglu:结合swish激活函数和门控机制,增强模型的表达能力和性能
- ROPE(Rotary Position Embedding):用绝对位置编码的方式实现相对位置编码,具有远程衰减的特性(Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces)
|
|
|

LLM训练范式
New LLM Pre-training and Post-training Paradigms
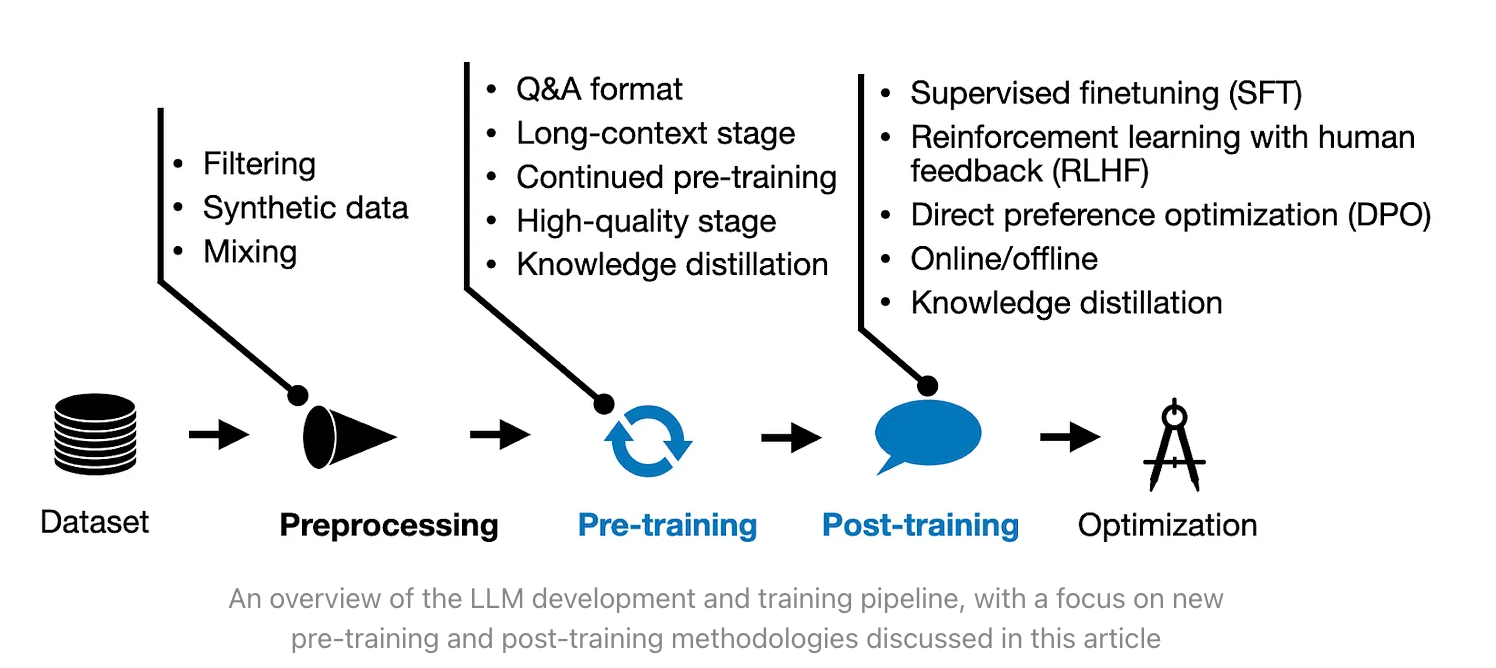
- pre-training:在特定任务上进行微调之前,对大型语言模型进行的初始训练阶段。这个阶段的目标是通过处理大规模的语料库数据,让模型学习到语言的统计规律、语义信息和上下文关系,从而为后续的微调任务提供强大的语言理解和生成能力。
- 常用的一些任务:Language Modelling比较常见的例如Next sentence prediction,Denoising Autoencoding例如Masked language model
- post-training:(https://arxiv.org/pdf/2502.21321)在垂直领域消除大模型的偏差,让大模型更精准,对齐人类认知。
- Fine-Tuning:让LLM适配特定垂直领域的任务。但是如果fine-tune过火,可能出现over-fitting、Catastrophic Forgetting等让LLM退步的问题
- 全参数微调(Full Fine-Tuning)
- 低秩适配(LoRA,Low-Rank Adaptation)
- 适配器(Adapters)
- Supervised fine-tuning (SFT)
- Reinforcement Learning: 通过reward优化模型决策,使其回答更符合人类偏好、更加逻辑清晰
- RLHF
- DPO
- GRPO
- Fine-Tuning:让LLM适配特定垂直领域的任务。但是如果fine-tune过火,可能出现over-fitting、Catastrophic Forgetting等让LLM退步的问题
DeepSeek LLM
模型沿用LLaMA架构(GitHub - meta-llama/llama-models: Utilities intended for use with Llama models.),对transformer层采用RMS Norm归一化函数,SwiGlu激活函数,维度采用8/4d,采用RoPE对position进行编码。
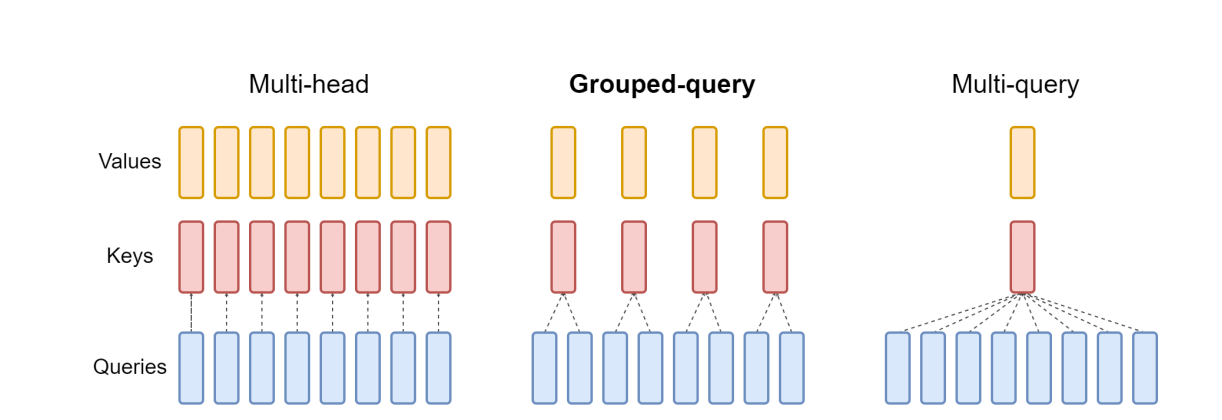
67Bmodel采用GQA(Grouped Query Attention).训练框架采用HAI-LLM (HAI-LLM:高效且轻量的大模型训练工具)训练框架并行训练。

数据
150w英文和中文一般语言任务的分布为31.2%,数学问题的分布为46.6%,编程练习的分布为22.2%。安全数据包含30万个实例,涵盖各种敏感主题。
训练流程:训练采用SFT和DPO进行训练
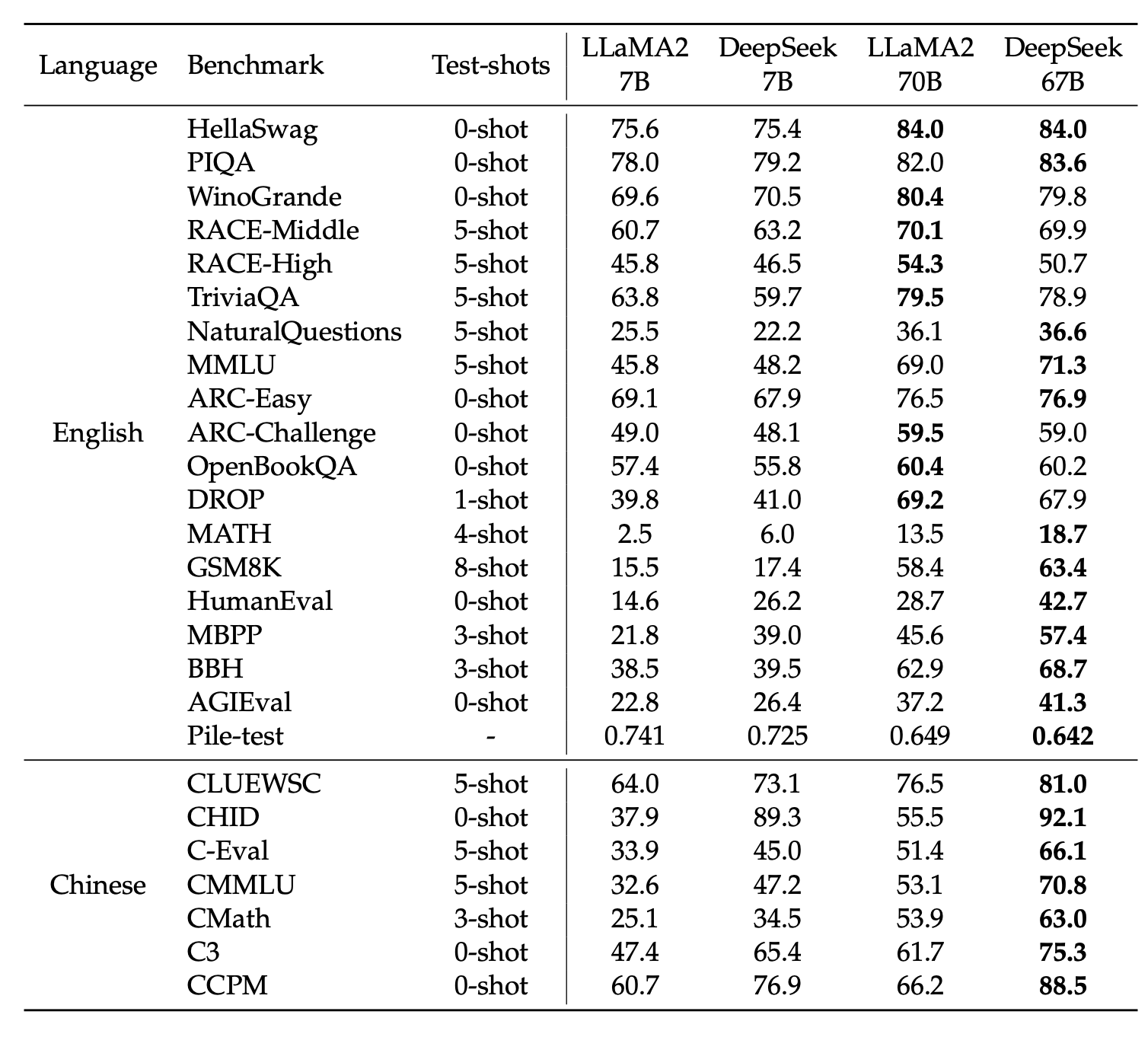
效果:
DeepSeek Moe
模型结构
- switch transformer(https://arxiv.org/pdf/2101.03961)
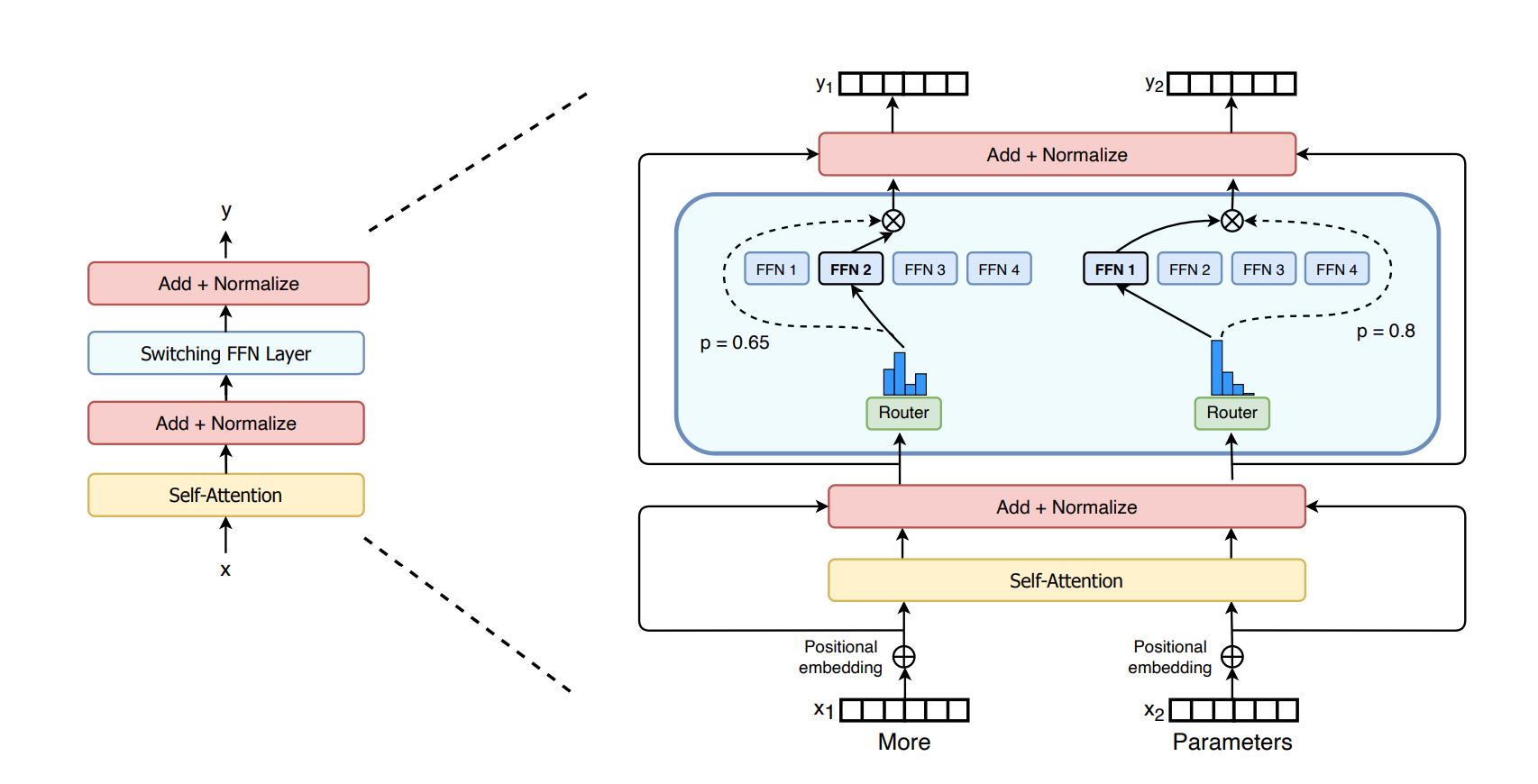
MOE的基本原理是使用混合专家来替代原transformer架构中的前向反馈层(FFN)。
结构如下一个token输入经过Attention计算并且归一化操作后除了残差分支外,原本通向FFN层的分支进入了MOE层,简单来说,MOE层是由多个FFN组成,每个FFN理论上更关注不同领域知识,也就是所谓的专家,每个token会选择其中的top-K个FFN向前传递,即选择这个token所在领域相关的专家,这个top-K也可能是个权重系数。
- moe structure
细粒度专家网络划分 Fine-Grained expert segmentation(图b)
在保持参数数量不变的情况下,我们通过拆分前馈网络(FFN)的中间隐藏维度,将专家划分得更细。相应地,在保持计算成本不变的前提下,我们还激活更多细粒度专家,以便更灵活、自适应地组合激活的专家。细粒度专家划分能让多样的知识更精细地分解,并更精确地由不同专家学习,每个专家都能保持更高程度的专业化。此外,激活专家组合方式灵活性的提升,也有助于更准确、有针对性地获取知识。
共享专家分离 Shared Expert Isolation(图c)
分离出特定的专家作为共享专家,这些共享专家始终处于激活状态,目的是捕捉并整合不同上下文环境中的通用知识。通过将通用知识压缩到这些共享专家中,其他路由专家之间的冗余将得到缓解。这可以提高参数效率,并确保每个路由专家通过专注于独特方面保持专业性。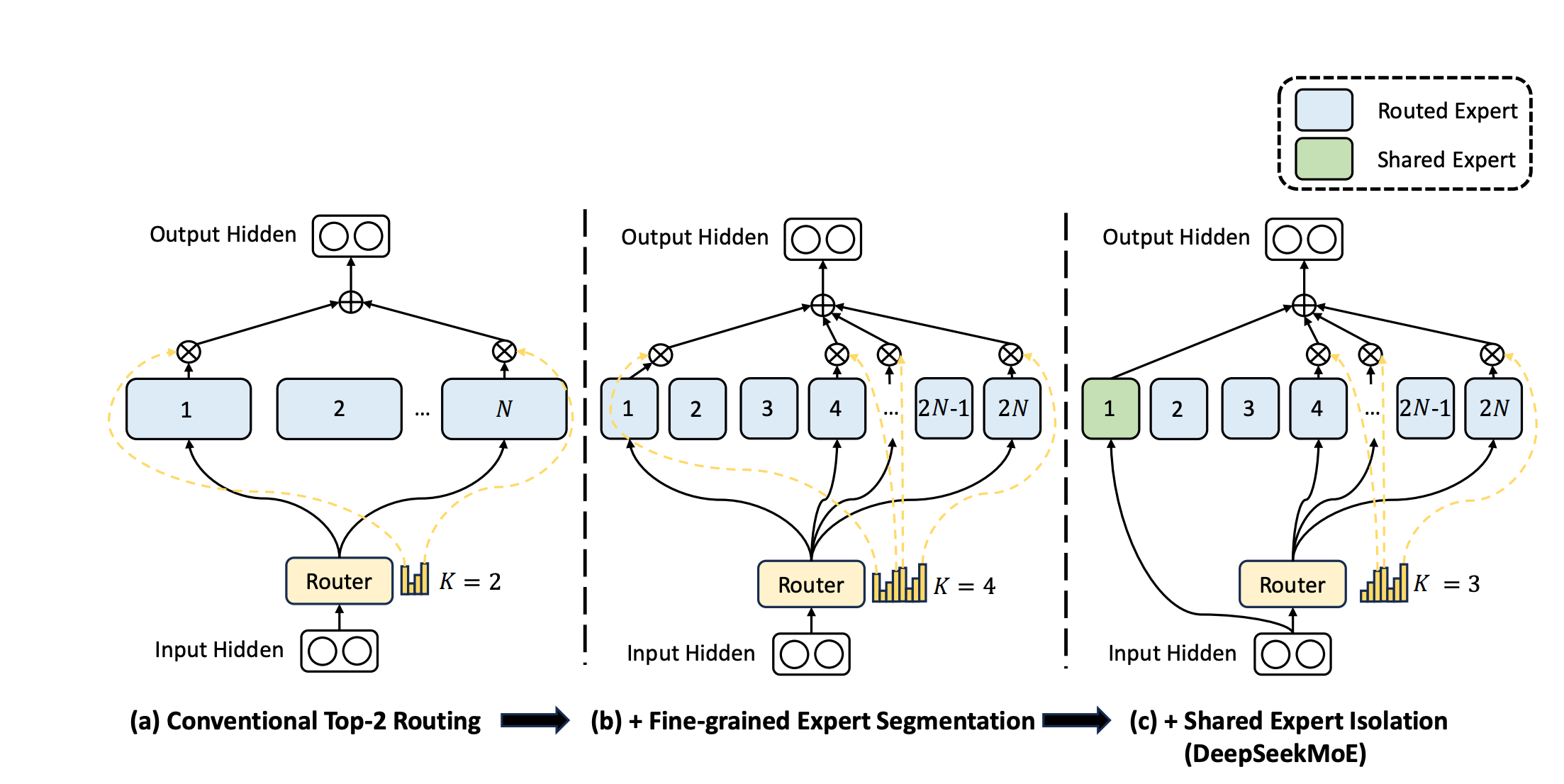
负载均衡优化
- 专家级loss负载 Expert-level Balance Loss

- 设备级loss负载 Device-level Balance Loss
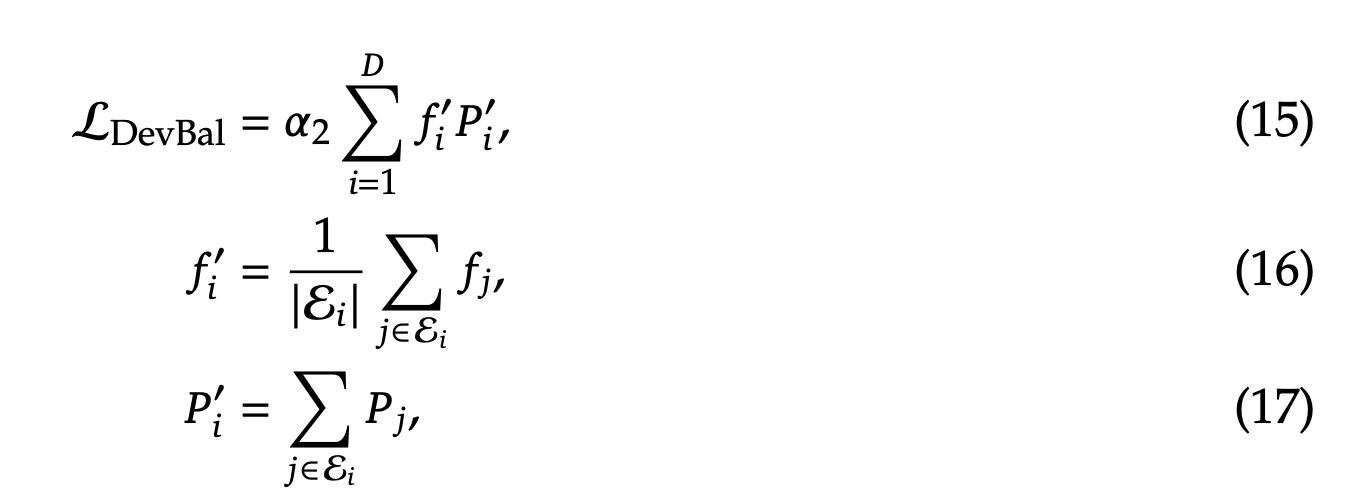
训练数据和训练框架:
训练数据是由Deepseek AI生成的多语言语料,主要包括中文和英文。
训练框架依然采用HAI-LLM
效果:
