优化model我们可能会怎么做(具体)
在选择模型方面
-
资源推荐:
- 建议访问 torchvision.models 查看可用的模型结构列表
- 或者访问 timm (PyTorch Image Models) 获取最新的模型结构
-
重要限制:
- 明确规定不允许使用预训练权重,必须设置 pretrained=False
- 这可能是为了确保学习过程的公平性或教学目的
-
分类模型选项: 图片列出了可用于图像分类的几种经典模型架构:
- AlexNet:2012年提出的开创性CNN架构
- VGG:以简单而深的结构著称
- ResNet:引入残差连接解决深度网络训练问题
- SqueezeNet:轻量级模型,设计用于资源受限环境

数据增强方面
-
目的:
- 通过修改图像数据,确保每个训练周期(epoch)模型接收到的都是非完全相同的输入
- 这种方法有效防止模型过拟合,提高泛化能力
-
资源推荐:
- 建议访问torchvision.transforms库,查看各种可用的图像变换方法及其效果
- 强调多样性的重要性,鼓励组合多种变换方法以获得更好的结果
-
实现提示:
- 提供了代码提示:需要填写train_tfm部分来实现数据增强效果
-
示例效果:
- 图片底部展示了同一张宇航员图像经过不同数据增强处理后的效果:
- 原始图像
- 颜色变换(蓝色调整)
- 原始图像(可能是对照)
- 亮度/对比度调整(灰度效果)
- 颜色变换(绿色调整)
- 图片底部展示了同一张宇航员图像经过不同数据增强处理后的效果:

其中有一个mix up,是将两个图片叠加起来,
MixUp是一种先进的数据增强技术,它通过线性组合两个不同的训练样本及其标签来创建新的训练数据。图片中解释了实现这一技术需要的关键步骤:
-
图像混合:
- 在torch.utils.Dataset类的__getitem__()方法中,需要返回两个图像的线性组合
- 通常形式为:λ·图像A + (1-λ)·图像B,其中λ是一个在0到1之间的随机值
-
标签混合:
- getitem()方法还需要返回一个向量形式的标签,而不是单一类别
- 这个向量为每个类别分配概率值,反映混合后的图像属于各个类别的可能性
- 例如,如果图像A的标签是[1,0,0],图像B的标签是[0,1,0],混合后的标签可能是[0.7,0.3,0]
-
损失函数调整:
- 标准的CrossEntropyLoss不支持多标签(软标签)情况
- 需要手动实现交叉熵损失函数的数学公式来处理这种情况
- 通常需要计算:-∑(真实概率分布·log(预测概率分布))
MixUp技术的优势在于它能够:
- 增强模型的泛化能力
- 减少对抗样本的影响
- 提高模型对噪声的鲁棒性
- 帮助模型学习更平滑的决策边界

接下来是test time augmentation,测试时数据增强
测试时数据增强是一种高级技术,它在模型推理阶段(而不仅仅是训练阶段)应用数据变换,以提高预测准确性。图片解释了这一技术的关键点:
-
标准测试方法的局限性:
- 传统方法仅使用确定性的"测试变换"(通常只是简单的归一化和调整大小)
- 这限制了模型对测试图像的理解
-
TTA的核心思想:
- 对同一测试图像应用多种变换,创建多个变体
- 对每个变体进行预测
- 将所有预测结果集成(通常通过平均或投票)得到最终预测
-
实现步骤:
- 需要修改train_tfm(训练变换)
- 更改test_dataset的增强方法
- 修改预测代码以处理多个变体并集成结果
-
图示说明:
- 左侧展示了训练时使用的各种变换后的图像
- 中间显示了标准测试图像
- 右侧表示TTA后的最终预测结果
- 底部箭头表示将多个预测结果集成为最终预测
TTA的优势:
- 减少单一视角带来的偏差
- 提高模型对细微变化的鲁棒性
- 通常能显著提升模型性能,特别是在测试数据与训练数据分布略有差异时

testing的权重多一点会好一点

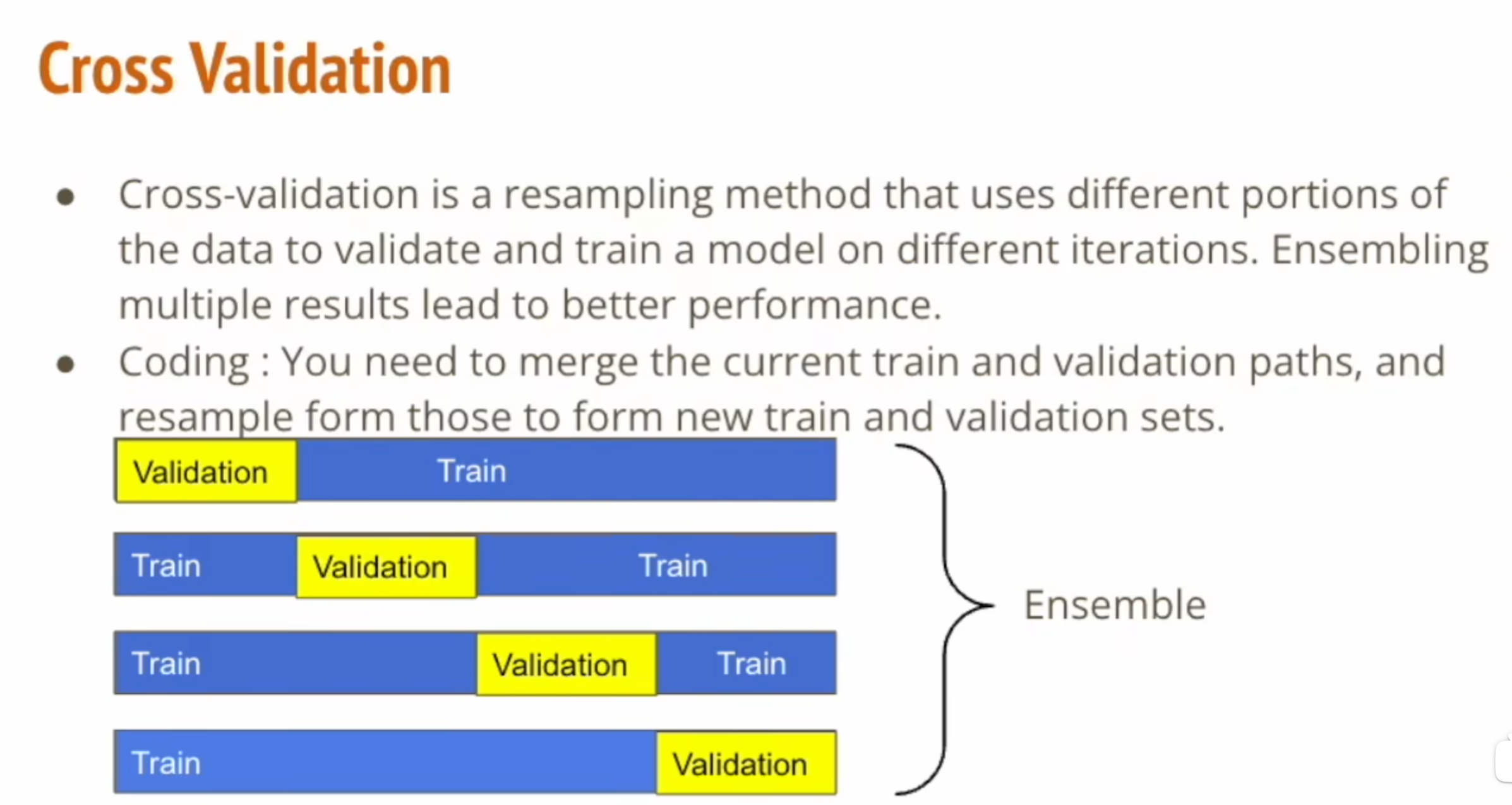
cross validation
用多的vali其实没啥用
模型集成是机器学习中的一种强大技术,它通过组合多个模型的预测结果来获得比单个模型更好的性能。图片解释了两种主要的集成方法:
-
逻辑值或概率平均法:
- 这种方法对多个模型输出的原始逻辑值(logits)或概率值进行平均
- 优点:需要保存详细的输出信息,结果更精确,减少歧义
- 例如:如果三个模型对某类别的预测概率分别是0.7、0.6和0.8,平均后为0.7
-
投票法:
- 每个模型对样本进行分类,最终分类结果由"多数表决"决定
- 优点:实现简单,计算量小
- 缺点:需要处理平票情况(当不同类别获得相同票数时)
- 例如:如果三个模型分别预测类别A、A和B,最终结果为A
-
实现提示:
- 可以使用NumPy或PyTorch等库中的基本数学运算来实现集成
- 对于平均法,可以使用np.mean()或torch.mean()
- 对于投票法,可以使用np.bincount()或类似函数统计票数
模型集成的优势:
- 减少单个模型的过拟合风险
- 提高预测的稳定性和可靠性
- 捕捉不同模型捕获的不同数据特征和模式
- 通常能显著提升最终性能