AI 商业化部署中,ollama 和 vllm 的选型对比
介绍
ollama
Ollama是指一个开源的大模型服务工具,旨在简化大型语言模型(LLM)的本地部署、运行和管理。它让用户能够在本地设备上轻松运行和管理各种大语言模型,无需依赖云端服务。
vllm
在深度学习推理领域,vLLM框架凭借其卓越的性能表现脱颖而出。作为基于PyTorch构建的专用解决方案,该框架深度融合CUDA加速技术,通过创新性的连续批处理机制、智能内存分配策略以及分布式张量计算能力,为大规模语言模型部署提供了工业级的高效运行环境。

vLLM被专门设计用于高性能推理和生产环境,其主要特点包括:
-
优化的GPU效能:通过CUDA和PyTorch的配合使用,我们充分发挥了GPU的潜力,从而实现更迅速的推理过程。
-
批处理功能:我们实现了连续的批处理和高效的内存管理,以此来提升多个并行请求的吞吐量。
-
安全性:内建API密钥支持和正确的请求验证机制,而不是直接忽视身份验证。
-
灵活的部署方式:全面支持Docker,可以对GPU内存使用和模型参数进行精细控制。
部署模型:
# 需要GPU支持
docker run -it \--runtime nvidia \--gpus all \--network="host" \--ipc=host \-v ./models:/vllm-workspace/models \-v ./config:/vllm-workspace/config \vllm/vllm-openai:latest \--model models/Qwen2.5-14B-Instruct/Qwen2.5-14B-Instruct-Q4_K_M.gguf \--tokenizer Qwen/Qwen2.5-14B-Instruct \--host "0.0.0.0" \--port 5000 \--gpu-memory-utilization 1.0 \--served-model-name "VLLMQwen2.5-14B" \--max-num-batched-tokens 8192 \--max-num-seqs 256 \--max-model-len 8192 \--generation-config config其中
--runtime nvidia --gpus all: 启用对容器的 NVIDIA GPU 支持。
--network="host": 使用主机网络模式以获得更好的性能。
--ipc=host: 允许主机和容器之间共享内存。
- v ./model:/vllm-workspace/model: 将本地模型目录装入容器,目录包含了示例的Qwen2.5–14B模型
--model: 指定 GGUF 模型文件的路径。
--tokenizer: 定义要使用的 HuggingFace tokenizer。
--gpu-memory-utilization 1: 将 GPU 内存使用率设置为 100% 。
--served-model-name: 通过 API 提供服务时模型的自定义名称,可以指定所需的名称。
--max-num-batched-tokens: 批处理中的最大token数量。
--max-num-seqs: 同时处理的序列的最大数目。
--max-model-len: 模型的最大上下文长度。
Ollama官方网址:https://ollama.com
vLLM官方网址:https://vllm.ai
Ollama 和 vLLM,都是在本地 电脑部署和运行DeepSeek等AI大模型的工具,性能强大,开源免费。但是,二者在技术路线上有显著的差异,这决定了它们在不同场景下的表现和适用范围。
Ollama 的技术核心在于其便捷的本地部署能力,而 vLLM 则专注于推理加速,采用了一系列先进的技术来提升推理性能。
对比
作为新手,如果在本地电脑部署DeepSeek,Ollama和vLLM哪一个更快、更合适?二者在性能、硬件要求、部署难度、模型支持、资源占用、用途、交互方式等各方面有哪些区别?
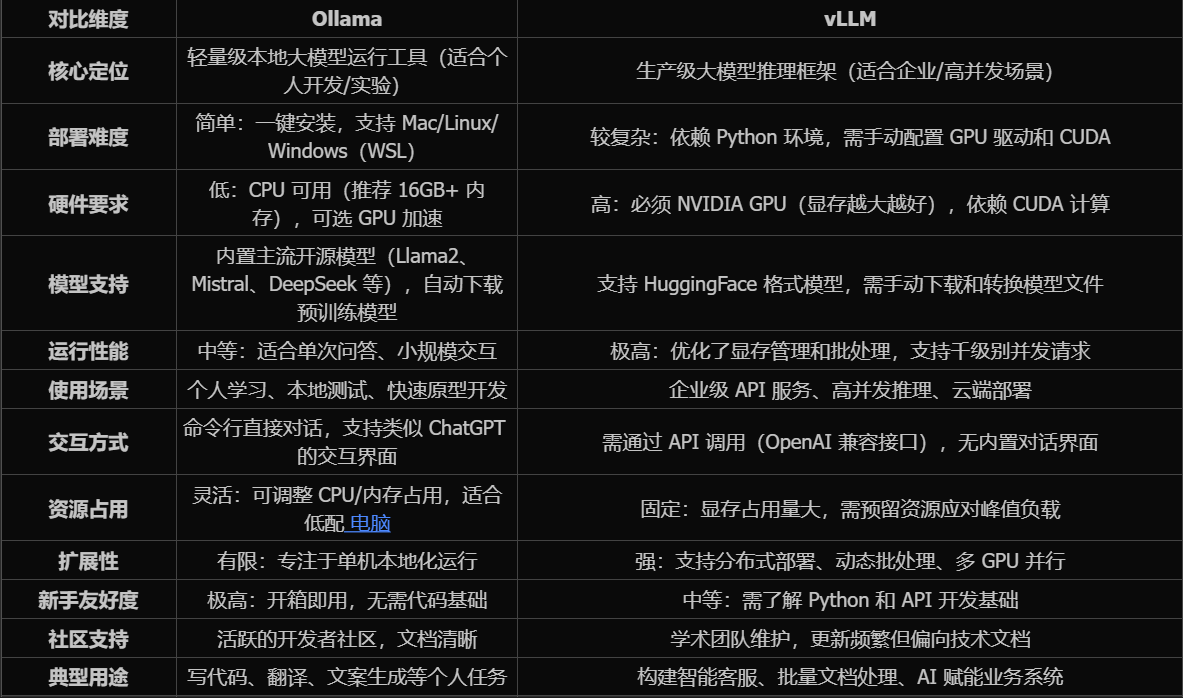
在一次 7B 模型中的性能跑分:

这里援引一篇测试文:
http://www.hubwiz.com/blog/vllm-ollama-comprehensive-comparison/
大量实验测试和生产应用表明,vllm性能比ollama有显著提升。
选择 Ollama 的场景:
新手友好:安装只需一行命令(如 curl -fsSL https://ollama.com/install.sh | sh),无需配置环境。
低配电脑可用:即使只有 CPU 和 16GB 内存,也能运行 7B 参数的 DeepSeek 模型。
快速验证需求:直接输入 ollama run deepseek 即可开始对话,适合测试模型基础能力。
选择 vLLM 的场景:
需要 API 服务:计划将 DeepSeek 集成到其他应用(如开发智能助手)。
高性能需求:本地有高端 GPU(如 RTX 4090),需处理大量并发请求(如批量生成内容)。
定制化需求:需修改模型参数或添加业务逻辑(通过 Python 代码调用)。
综合评价
VLLM:性能标杆,高吞吐推理的利器。
Ollama:快速上手,本地开发、测AI效果的友好伙伴。
如果你想在本地或远程服务器上快速试验大模型,Ollama是理想之选,其易用性让初次使用大型语言模型的开发者能平滑入门。而对于注重性能、可扩展性和资源优化的生产环境,vLLM表现出色,高效处理并行请求和优化GPU利用,且文档完备,使其成为生产环境大规模部署的强力候选者,尤其在充分挖掘硬件性能方面。在实际正式生产里面,大部分都是选用 vllm 。
- 性能表现:基准测试显示vLLM具有明显的速度优势,单请求处理时token生成速率较Ollama提升超过15%。
- 并发处理能力:vLLM采用先进的资源调度算法,可高效处理高并发请求;而Ollama在并行请求处理方面存在架构限制,即使少量并发请求(如4个)也会导致系统资源争用问题。
- 开发便捷性:Ollama凭借极简的交互设计脱颖而出,开发者通过单行命令即可实现模型交互;相较之下,vLLM需要掌握容器化部署技术,并需理解各类性能调优参数。
- 生产就绪度:vLLM的工业级特性使其成为企业级部署的首选,包括多家知名AI服务商在内的技术团队都采用其作为核心推理引擎。该框架支持细粒度的资源分配和弹性扩展,完美适配云原生环境。
- 安全机制:vLLM内置完善的认证体系,支持基于token的访问控制;而Ollama默认采用开放式访问模式,需要额外配置网络层防护措施来保证服务安全。
- 技术支持体系:Ollama的文档注重快速上手体验,但技术实现细节相对匮乏,社区论坛中的关键技术问题经常得不到有效解答。
常见问题和技巧
Ollama
• 模型下载中断:改用国内镜像源(如http://ollama.org.cn)
• 显存不足:启用量化参数(如ollama run deepseek-r1:7b-q4)
启动预训练模型仅需简单指令
# 添加--detail参数可实时监控token生成速率,便于性能调优。
ollama start qwen2.5-14b --detail
vLLM
• 性能调优:添加–block-size 16减少内存碎片,吞吐量提升30%
• 成本控制:采用Spot实例+自动扩缩容,云上成本降低50%
其他博主写的不错的文章:
https://blog.csdn.net/qq_36631379/article/details/148048876
https://yanghaixiong.com/aigc/ollama