【强化学习】#6 n步自举法
主要参考学习资料:《强化学习(第2版)》[加]Richard S.Suttion [美]Andrew G.Barto 著
文章源文件:https://github.com/INKEM/Knowledge_Base
概述
- n步时序差分方法是蒙特卡洛方法和时序差分方法更一般的推广。
- 将单步Sarsa推广到n步Sarsa我们得到n步方法的同轨策略控制。
- n步方法最基本的离轨策略控制是基于重要度采样的。
- n步树回溯法是一种不需要重要度采样的离轨策略控制。
目录
- n步时序差分预测
- n步Sarsa
- n步离轨策略学习
- n步树回溯法
- 总结
回顾动态规划和时序差分学习,它们都根据对后继状态价值的估计来更新对当前状态价值的估计,这种基于其他估计来更新自己的估计的思想被称为自举法。通过将单步时序差分推广到 n n n步,我们可以得到一系列 n n n步自举法,甚至在极限状态下得到蒙特卡洛方法。
n步时序差分预测
对于固定策略 π \pi π下的给定的多幕采样序列,从某一状态开始,蒙特卡洛方法利用直至终止状态的收益序列对该状态的价值进行更新,而时序差分方法只根据下一步的即时收益,在后继状态的价值估计值的基础上进行自举更新。
我们很容易想到一种介于二者之间的方法是利用该状态之后的多个中间时刻的收益来进行更新,但又不到达终止状态。对于 n n n步更新,我们利用当前状态之后的 n n n步收益和 n n n步之后的价值估计来更新当前状态价值估计。 n n n步更新仍然属于时序差分方法,因为前面状态的估计值仍根据它与后继状态估计值的差异进行更新,只不过后继状态可以是 n n n步之后的状态。时序差分量被扩展成 n n n的方法被称为n步时序差分方法。
利用回溯图可以直观地对算法进行图示总结。不同步数下的时序差分方法更新的回溯图如下,空心圈代表采样的状态,实心点代表采样的动作:
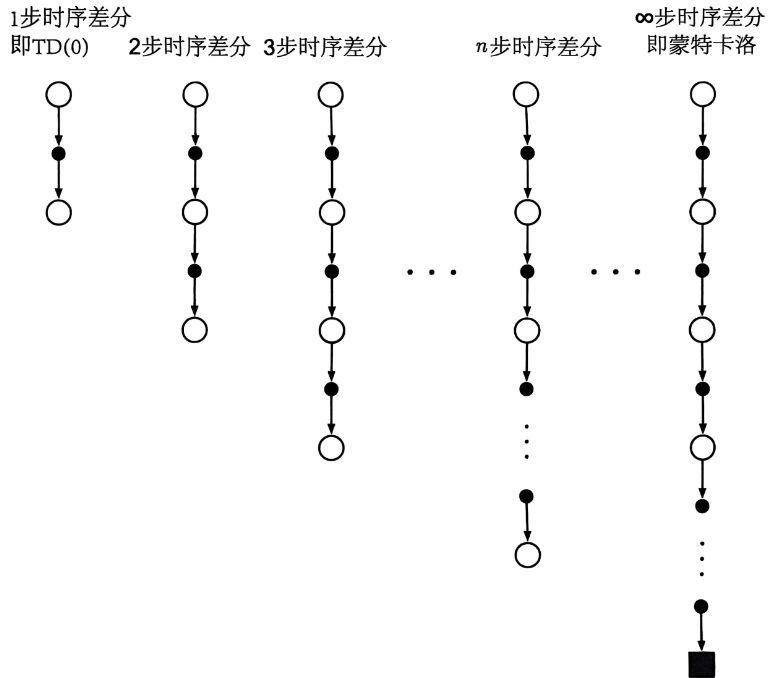
接下来我们考虑该方法的数学表示。我们知道,在蒙特卡洛方法中,更新目标 G t G_t Gt沿着完整回报的方向计算
G t = ˙ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ + γ T − t − 1 R T G_t\dot=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots+\gamma^{T-t-1}R_T Gt=˙Rt+1+γRt+2+γ2Rt+3+⋯+γT−t−1RT
其中 T T T是终止状态的时刻。
而在单步时序差分中,更新的目标是即时收益加上后继状态的价值函数估计值乘以折扣系数,我们称其为单步回报
G t : t + 1 = ˙ R t + 1 + γ V t ( S t + 1 ) G_{t:t+1}\dot=R_{t+1}+\gamma V_t(S_{t+1}) Gt:t+1=˙Rt+1+γVt(St+1)
其中 V t V_t Vt是在 t t t时刻 v π v_\pi vπ的估计值,后继状态的折后价值函数估计 γ V t ( S t + 1 ) \gamma V_t(S_{t+1}) γVt(St+1)可以视为对后续完整回报 γ R t + 2 + ⋯ + γ T − t − 1 R T \gamma R_{t+2}+\cdots+\gamma^{T-t-1}R_T γRt+2+⋯+γT−t−1RT的估计。类似地,将这种想法扩展到两步的情况,我们有两步更新的目标两步回报
G t : t + 2 = ˙ R t + 1 + γ R t + 2 + γ 2 V t + 1 ( S t + 2 ) G_{t:t+2}\dot=R_{t+1}+\gamma R_{t+2}+\gamma^2V_{t+1}(S_{t+2}) Gt:t+2=˙Rt+1+γRt+2+γ2Vt+1(St+2)
而任意 n n n步更新的目标是n步回报
G t : t + n = ˙ R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n V t + n − 1 ( S t + n ) G_{t:t+n}\dot=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^nV_{t+n-1}(S_{t+n}) Gt:t+n=˙Rt+1+γRt+2+⋯+γn−1Rt+n+γnVt+n−1(St+n)
其中 n ⩾ 1 n\geqslant1 n⩾1, 0 ⩽ t ⩽ T − n 0\leqslant t\leqslant T-n 0⩽t⩽T−n。 n n n步回报即在 n n n步后截断完整回报,并用 V t + n − 1 ( S t + n ) V_{t+n-1}(S_{t+n}) Vt+n−1(St+n)作为对剩余部分的估计。如果 t + n ⩾ T t+n\geqslant T t+n⩾T,则超出终止状态的部分均为零, n n n步回报等于完整回报。
计算时刻 t t t的 n n n步回报需要在时刻 t + n t+n t+n时得到 R t + n R_{t+n} Rt+n和 V t + n − 1 V_{t+n-1} Vt+n−1后才能计算。最基础的基于 n n n步回报的状态价值函数更新算法即n步时序差分( n n n步TD)算法
V t + n ( S t ) = ˙ V t + n − 1 ( S t ) + α [ G t : t + n − V t + n − 1 ( S t ) ] , 0 ⩽ t < T V_{t+n}(S_t)\dot=V_{t+n-1}(S_t)+\alpha[G_{t:t+n}-V_{t+n-1}(S_t)],0\leqslant t<T Vt+n(St)=˙Vt+n−1(St)+α[Gt:t+n−Vt+n−1(St)],0⩽t<T
在更新当前状态的过程中,其他状态 s ≠ S t s\neq S_t s=St的价值估计保持不变
V t + n ( S ) = V t + n − 1 ( S ) V_{t+n}(S)=V_{t+n-1}(S) Vt+n(S)=Vt+n−1(S)
用 n n n步回报在 V t + n − 1 V_{t+n-1} Vt+n−1的基础上更新 V t + n V_{t+n} Vt+n的一个重要依据是, n n n步回报的期望和真实状态价值函数 v π ( s ) v_\pi(s) vπ(s)之间的最大误差能保证不大于 V t + n − 1 V_{t+n-1} Vt+n−1和 v π ( s ) v_\pi(s) vπ(s)之间的最大误差的 γ n \gamma^n γn倍
max s ∣ E π [ G t : t + n ∣ S t = s ] − v π ( s ) ∣ ⩽ γ n max s ∣ V t + n − 1 ( s ) − v π ( s ) ∣ \underset s\max|\mathbb E_\pi[G_{t:t+n}|S_t=s]-v_\pi(s)|\leqslant\gamma^n\underset s\max|V_{t+n-1}(s)-v_\pi(s)| smax∣Eπ[Gt:t+n∣St=s]−vπ(s)∣⩽γnsmax∣Vt+n−1(s)−vπ(s)∣
这被称为 n n n步回报的误差减少性质,其可以证明所有的 n n n步时序差分方法在合适的条件下都能收敛到正确的预测,且 n n n越大,收敛性越好。
n n n步TD的伪代码如下:

该伪代码的逻辑较为晦涩,其进一步解释如下:在每一幕,我们从 S 0 S_0 S0根据策略 π \pi π选择动作直至终止状态 S T S_T ST,其中 T T T在一开始并不知道,直到遇到终止状态才能确定。 S 0 S_0 S0的更新需要等到时刻 t = n + 1 t=n+1 t=n+1时才能执行,相应地,往后 S τ ( τ ⩾ 0 ) S_\tau(\tau\geqslant0) Sτ(τ⩾0)的更新则在时刻 t = n + 1 + τ t=n+1+\tau t=n+1+τ执行,在代码中则表示为在时刻 t t t执行对 S t − n + 1 ( τ = t − n + 1 ⩾ 0 ) S_{t-n+1}(\tau=t-n+1\geqslant0) St−n+1(τ=t−n+1⩾0)的更新。在更新中,如果 S τ S_\tau Sτ距离终止状态 S T S_T ST不足 n n n步,则 min ( τ + n , T ) = T \min(\tau+n,T)=T min(τ+n,T)=T,回报只能在终止状态截断,即直接使用完整回报作为更新目标,此时也无需再加上后继状态的折后价值估计,因为终止状态的价值 v ( S T ) = 0 v(S_T)=0 v(ST)=0。
事实证明,对于大小为 ∣ S ∣ |\mathcal S| ∣S∣的状态集合, n n n取其中间大小的值时通常效果最好,这也证明了将单步时序差分方法和蒙特卡洛方法推广到 n n n步时序差分方法可能会得到更好的效果。
n步Sarsa
将 n n n步方法与Sarsa结合,我们可以得到同轨策略下的 n n n步时序差分学习控制方法。 n n n步版本的Sarsa被称为n步Sarsa,相应地,上一章介绍的初始版本的Sarsa被称为单步Sarsa或Sarsa(0)。不同步数下的Sarsa方法更新的回溯图如下:
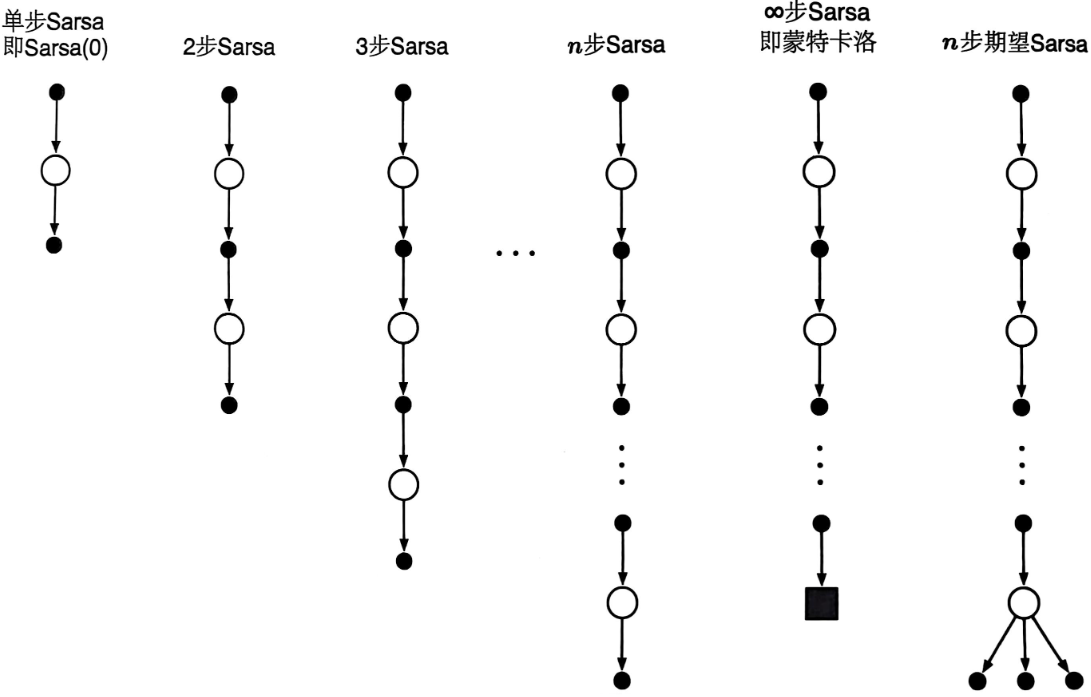
和单步TD到单步Sarsa的转换一样, n n n步TD到 n n n步Sarsa的核心思想也是将状态替换为“状态-动作”二元组,并使用 ϵ \epsilon ϵ-贪心策略。我们根据动作价值估计重新定义 n n n步Sarsa方法下的 n n n步回报
G t : t + n = ˙ R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n Q t + n − 1 ( S t + n , A t + n ) , n ⩾ 1 , 0 ⩽ t < T − n G_{t:t+n}\dot=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^nQ_{t+n-1}(S_{t+n},A_{t+n}),n\geqslant1,0\leqslant t<T-n Gt:t+n=˙Rt+1+γRt+2+⋯+γn−1Rt+n+γnQt+n−1(St+n,At+n),n⩾1,0⩽t<T−n
当 t + n ⩾ T t+n\geqslant T t+n⩾T时, G t : t + n = G t G_{t:t+n}=G_t Gt:t+n=Gt。
则 n n n步Sarsa的更新公式为
Q t + n ( S t , A t ) = ˙ Q t + n − 1 ( S t , A t ) + α [ G t : t + n − Q t + n − 1 ( S t , A t ) ] , 0 ⩽ t < T Q_{t+n}(S_t,A_t)\dot=Q_{t+n-1}(S_t,A_t)+\alpha[G_{t:t+n}-Q_{t+n-1}(S_t,A_t)],0\leqslant t<T Qt+n(St,At)=˙Qt+n−1(St,At)+α[Gt:t+n−Qt+n−1(St,At)],0⩽t<T
在处理对应“动作-状态”二元组的更新时,所有其他二元组保持不变,即对于所有 s ≠ S t s\neq S_t s=St, a ≠ A t a\neq A_t a=At,有
Q t + n ( s , a ) = Q t + n − 1 ( s , a ) Q_{t+n}(s,a)=Q_{t+n-1}(s,a) Qt+n(s,a)=Qt+n−1(s,a)
n n n步Sarsa算法的伪代码如下:

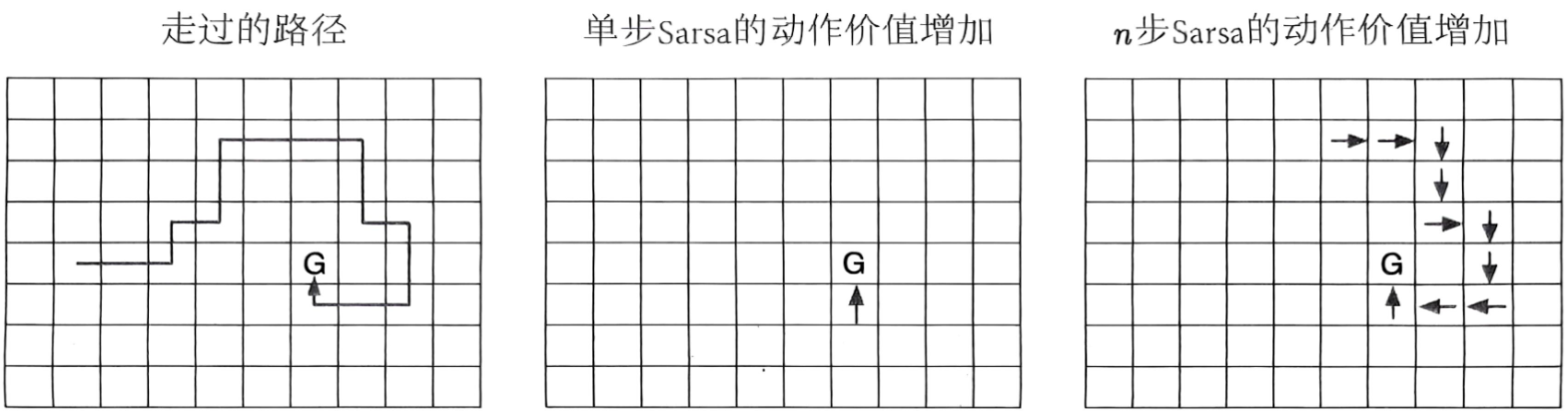
n n n步Sarsa相比单步Sarsa能够加速策略学习。假设在一个网格世界中,除了终点具有高收益,其余格子的收益均为零,则完成一幕序列的采样后,单步Sarsa的终点收益只能影响到达终点的前一个格子相应的动作价值,而 n n n步Sarsa却能更新路径上到达终点的前 n n n个格子相应的动作价值,学到了更多的知识。
n n n步期望Sarsa则在Sarsa的基础上重新定义了 n n n步回报
G t : t + n = ˙ R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n V ˉ t + n − 1 ( S t + n ) , n ⩾ 1 , 0 ⩽ t < T − n G_{t:t+n}\dot=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^n\bar V_{t+n-1}(S_{t+n}),n\geqslant1,0\leqslant t<T-n Gt:t+n=˙Rt+1+γRt+2+⋯+γn−1Rt+n+γnVˉt+n−1(St+n),n⩾1,0⩽t<T−n
其中 V ˉ ( s ) \bar V(s) Vˉ(s)表示状态 s s s的期望近似价值,它通过在目标策略下 t t t时刻的动作价值估计的期望来计算
V ˉ t ( s ) = ˙ ∑ a π ( a ∣ s ) Q t ( s , a ) \bar V_t(s)\dot=\sum_a\pi(a|s)Q_t(s,a) Vˉt(s)=˙a∑π(a∣s)Qt(s,a)
终止状态的期望近似价值为零。
n步离轨策略学习
n n n步时序差分方法的离轨策略学习与蒙特卡洛方法中介绍的离轨策略控制相似,因为我们需要行动策略和目标策略在 n n n步上采取相同行动的相对概率(重要度采样比),进而由行动策略 b b b的 n n n步回报来预测目标策略 π \pi π的 n n n步回报。
对于由策略 b b b从 t t t时刻采样的 n n n步回报 G t : t + n G_{t:t+n} Gt:t+n,在对 n n n步之后 t + n t+n t+n时刻策略 π \pi π的状态价值估计 V t + n ( S t ) V_{t+n}(S_t) Vt+n(St)进行更新时,可以简单地用重要度采样比 ρ t : t + n − 1 \rho_{t:t+n-1} ρt:t+n−1(两种策略采取 A t ∼ A t + n A_t\sim A_{t+n} At∼At+n这 n n n个动作的相对概率)进行修正
V t + n ( S t ) = ˙ V t + n − 1 ( S t ) + α ρ t : t + n − 1 [ G t : t + n − V t + n − 1 ( S t ) ] , 0 ⩽ t < T V_{t+n}(S_t)\dot=V_{t+n-1}(S_t)+\alpha\rho_{t:t+n-1}[G_{t:t+n}-V_{t+n-1}(S_t)],0\leqslant t<T Vt+n(St)=˙Vt+n−1(St)+αρt:t+n−1[Gt:t+n−Vt+n−1(St)],0⩽t<T
这里,重要度采样比的计算为
ρ t : h = ˙ ∏ k = t min ( h , T − 1 ) π ( A k ∣ S k ) b ( A k ∣ S k ) \rho_{t:h}\dot=\prod^{\min(h,T-1)}_{k=t}\frac{\pi(A_k|S_k)}{b(A_k|S_k)} ρt:h=˙k=t∏min(h,T−1)b(Ak∣Sk)π(Ak∣Sk)
其中 min ( h , T − 1 ) \min(h,T-1) min(h,T−1)在终止状态截断截断计算。
在蒙特卡洛方法的离轨策略控制中,我们使用贪心策略作为目标策略。但是尽管我们选择了具有试探性的行为策略,在重要度采样中,价值估计的更新仍然取决于目标策略是否有概率选择,因此在学习中使用绝对的贪心策略并不是一个好的选择。我们仍可以采取 ϵ \epsilon ϵ-贪心策略使得所有价值估计都有被更新的可能,在合适的条件下,基于 ϵ \epsilon ϵ-贪心策略收敛后的价值估计生成一个贪心策略也能得到最优策略。
离轨策略下的 n n n步Sarsa算法伪代码如下:

n步树回溯法
n n n步树回溯法是一种不需要重要度采样的 n n n步离轨策略学习方法。普通的 n n n步离轨策略方法只依赖行动策略采样的具体动作,因此需要对行动策略的动作采取概率进行修正。而在 n n n步树回溯法中,行动策略的作用仅仅是产生状态转移,决定采样的动作-状态路径,在计算 n n n步回报时,行动策略选择的动作和未选择的动作都会以在目标策略下的选择概率被加权。一个三步树回溯更新的回溯图如下:
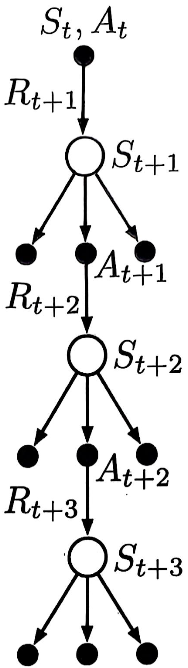
树回溯算法的单步回报与期望Sarsa相同,即对于 t < T − 1 t<T-1 t<T−1,有
G t : t + 1 = ˙ R t + 1 + γ ∑ a π ( a ∣ S t + 1 ) Q t ( S t + 1 , a ) G_{t:t+1}\dot=R_{t+1}+\gamma\sum_a\pi(a|S_{t+1})Q_t(S_{t+1},a) Gt:t+1=˙Rt+1+γa∑π(a∣St+1)Qt(St+1,a)
对于 t < T − 2 t<T-2 t<T−2,两步树回溯的回报将 Q ( S t + 1 , A t + 1 ) Q(S_{t+1},A_{t+1}) Q(St+1,At+1)展开为在 S t + 1 S_{t+1} St+1选择 A t + 1 A_{t+1} At+1转移到 S t + 2 S_{t+2} St+2的单步回报
G t : t + 2 = ˙ R t + 1 + γ ∑ a ≠ A t + 1 π ( a ∣ S t + 1 ) Q t ( S t + 1 , a ) + γ π ( A t + 1 ∣ S t + 1 ) ( R t + 2 + γ ∑ a π ( a ∣ S t + 2 ) Q t + 1 ( S t + 2 , a ) ) = R t + 1 + γ ∑ a ≠ A t + 1 π ( a ∣ S t + 1 ) Q t ( S t + 1 , a ) + γ π ( A t + 1 ∣ S t + 1 ) G t + 1 : t + 2 \begin{split} G_{t:t+2}&\dot=R_{t+1}+\gamma\sum_{a\neq A_{t+1}}\pi(a|S_{t+1})Q_t(S_{t+1},a)+\gamma\pi(A_{t+1}|S_{t+1})(R_{t+2}+\gamma\sum_a\pi(a|S_{t+2})Q_{t+1}(S_{t+2},a))\\ &=R_{t+1}+\gamma\sum_{a\neq A_{t+1}}\pi(a|S_{t+1})Q_t(S_{t+1},a)+\gamma\pi(A_{t+1}|S_{t+1})G_{t+1:t+2} \end{split} Gt:t+2=˙Rt+1+γa=At+1∑π(a∣St+1)Qt(St+1,a)+γπ(At+1∣St+1)(Rt+2+γa∑π(a∣St+2)Qt+1(St+2,a))=Rt+1+γa=At+1∑π(a∣St+1)Qt(St+1,a)+γπ(At+1∣St+1)Gt+1:t+2
从这个公式中我们可以看出树回溯的 n n n步回报的递归形式,即对于 t < T − 1 , n ⩾ 2 t<T-1,n\geqslant2 t<T−1,n⩾2,有
G t : t + n = ˙ R t + 1 + γ ∑ a ≠ A t + 1 π ( a ∣ S t + 1 ) Q t ( S t + 1 , a ) + γ π ( A t + 1 ∣ S t + 1 ) G t + 1 : t + n G_{t:t+n}\dot=R_{t+1}+\gamma\sum_{a\neq A_{t+1}}\pi(a|S_{t+1})Q_t(S_{t+1},a)+\gamma\pi(A_{t+1}|S_{t+1})G_{t+1:t+n} Gt:t+n=˙Rt+1+γa=At+1∑π(a∣St+1)Qt(St+1,a)+γπ(At+1∣St+1)Gt+1:t+n
上式是我们在代码中更新 n n n步回报的基础。对于 t + n t+n t+n超出 T − 1 T-1 T−1的部分,我们仍使用终止状态的收益 R T R_T RT截断,即 G T − 1 : t + n = R T G_{T-1:t+n}=R_T GT−1:t+n=RT。价值估计的更新公式与 n n n步Sarsa一样
Q t + n ( S t , A t ) = ˙ Q t + n − 1 ( S t , A t ) + α [ G t : t + n − Q t + n − 1 ( S t , A t ) ] , 0 ⩽ t < T Q_{t+n}(S_t,A_t)\dot=Q_{t+n-1}(S_t,A_t)+\alpha[G_{t:t+n}-Q_{t+n-1}(S_t,A_t)],0\leqslant t<T Qt+n(St,At)=˙Qt+n−1(St,At)+α[Gt:t+n−Qt+n−1(St,At)],0⩽t<T
n n n步树回溯算法的伪代码如下:

总结
n n n步方法向前看若干步的收益、状态和动作,使得价值估计的更新更加准确、稳定,但代价是延迟更新和更大的内存与计算量。在更靠后的章节,我们将学习如何借助资格迹用最少的内存和计算复杂度来实现 n n n步TD方法。