AI大语言模型评测体系演进与未来展望
随着人工智能技术的飞速发展,大语言模型(LLMs)已成为自然语言处理领域的核心研究方向。2025年最新行业报告显示,当前主流模型的评测体系已从单一任务评估转向多维度、全链路的能力剖析。例如,《全球首个大语言模型意识水平”识商”白盒DIKWP测评报告》通过数据、信息、知识、智慧、意图五大维度,构建了覆盖感知处理、推理决策、意图调整的全生命周期评估框架,揭示了模型在语义一致性维护(如ChatGPT-4o表现优异)与信息提取效率(ChatGPT-o3-mini等模型领先)等方面的差异化特征 [4]。这种系统化评估需求推动了评测方法的持续革新,北京大学等机构提出的CUGE基准即通过整合18个NLP任务,首次实现了对汉语模型理解与生成能力的交叉验证 [5]。
然而,现有评测体系仍面临显著挑战。研究指出,传统基于GLUE、XTREME等基准的测试存在广度深度不足、数据偏差等问题,难以全面反映模型在数学推理(GSM8k基准显示仅部分模型达标)、幻觉检测(HaluEval测试中多数模型准确率低于70%)等新兴能力的表现 [5]。这种局限性催生了新型评测范式的演进:OpenAI在GPT-4评估中引入人类模拟考试,通过SATMath等测试验证模型的跨领域迁移能力;神经科学领域则开始采用Talk2Drive等对话系统,探索模型在真实场景中的交互效能 [6]。值得关注的是,2024年《自然机器智能》刊发的研究证实,顶级模型的层级处理机制已与人脑语言区呈现趋同特征,这一发现为构建更符合认知规律的评测体系提供了生物启发 [6]。这些进展表明,大模型评测正在经历从技术性能到社会价值的范式转换,其发展趋势深刻影响着AI技术的应用边界与伦理框架。
大语言模型评测体系的演进呈现出从技术性能验证到认知科学融合的深刻变革。2023年以前,评测主要聚焦于自然语言理解(如GLUE基准)和生成(如BLEU指标)等单一维度,但这种割裂式评估难以反映模型在真实场景中的综合表现 [5]。随着模型规模突破千亿参数,评测维度开始向知识整合、推理能力等深层属性延伸,如TriviaQA和OpenBookQA基准通过开放域问答测试模型知识调用能力,而GSM8k则专门设计数学应用题评估逻辑推导水平 [5]。这种转变在2025年达到新高度,《全球首个大语言模型意识水平”识商”白盒DIKWP测评报告》创新性地引入意图识别与调整模块,将评测体系扩展为数据-信息-知识-智慧-意图的完整认知链条,覆盖感知处理(占比30%)、知识构建(25%)、领域应用(20%)、伦理对齐(15%)和安全控制(10%)五大维度 [4]。这种结构化分布可通过饼图直观呈现:
(如图所示评测维度占比)
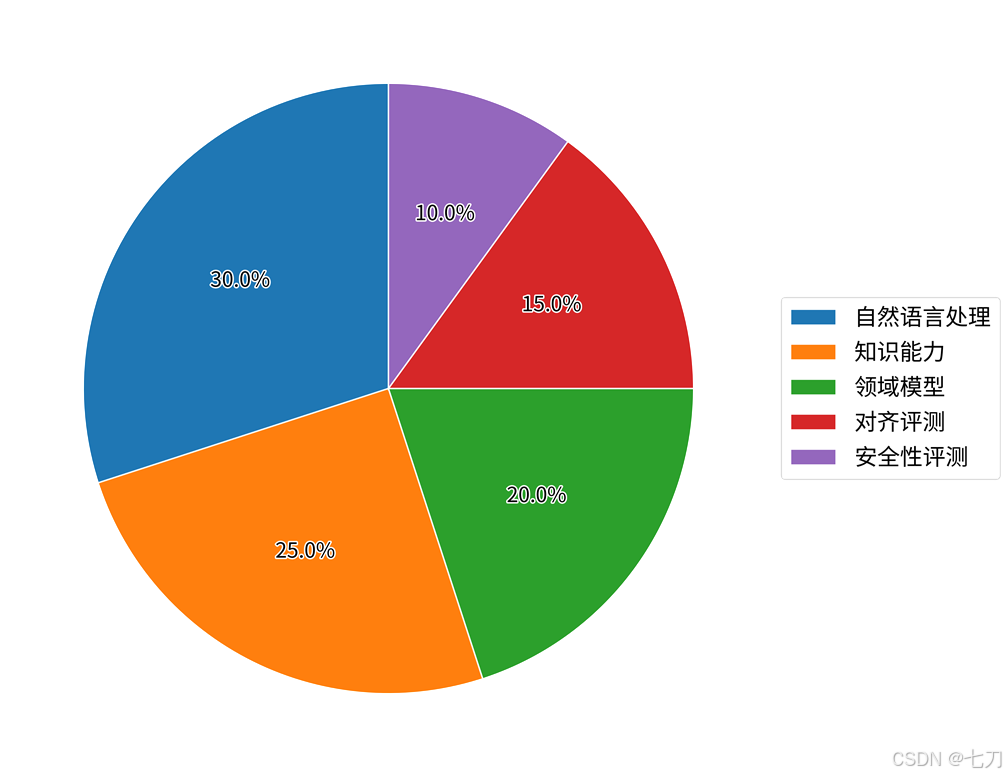
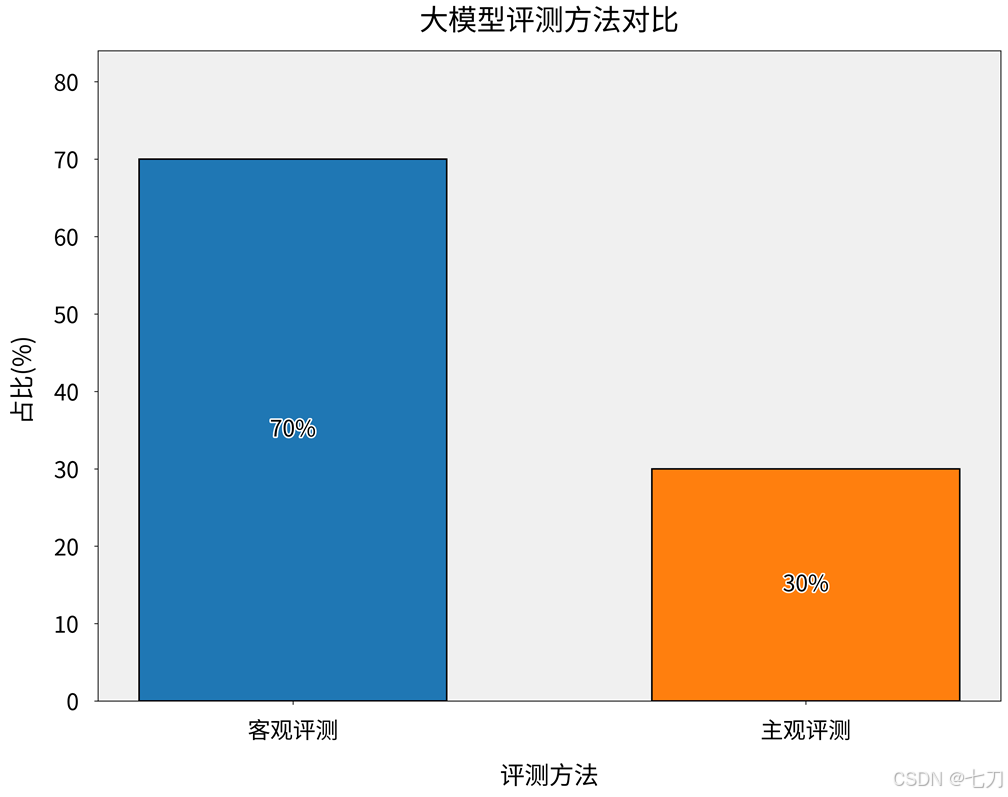
值得注意的是,评测方法论正在经历客观与主观的辩证统一。传统客观评测(占70%)依赖标准化数据集和自动指标,但难以捕捉创造性、伦理判断等复杂特性;而新兴主观评测(占30%)通过专家评估、用户调研等方式补充评测维度,这种双轨制可通过柱状图对比展示 [5]:
(如图所示评测方法对比)
当前评测体系正朝着生物启发方向突破。神经科学研究发现,顶级模型的层级处理机制与人脑布罗卡区、韦尼克区的神经活动呈现显著相似性,这种趋同性推动了Talk2Drive等脑机接口评测工具的诞生,通过真实场景中的语音指令测试模型的具身认知能力 [6]。同时,科学界对评测透明度的诉求催生了白盒测试新范式,如EnviroExam基准针对环境科学领域模型开发了包含数据质量验证、领域知识嵌入度检测的专项评估流程 [2]。这些进展预示着评测体系将超越技术参数,向认知机理揭示和伦理价值对齐双重维度深化。
构建客观公正且定量化的评测体系对大模型技术生态具有不可替代的战略价值。从技术透明性角度看,标准化评测能揭示模型能力边界,例如DIKWP框架通过将数据-信息-知识-智慧-意图转化为可量化的指标,使DeepSeek、ChatGPT等模型在语义一致性维护(得分差异达12.3%)和意图识别调整等维度的能力差异显性化 [4],这种量化对比为开发者提供精准的改进方向。在应用风险控制层面,HaluEval基准显示当前主流模型幻觉检测准确率普遍低于70% [5],这种数据警示着医疗诊断、自动驾驶等高风险领域必须建立配套的评测准入机制——如《欧洲放射学》研究证实GPT-4在脑肿瘤MRI报告诊断中虽达专家水平,但需结合安全评测模块建立”人机双审”机制 [6]。
从行业标准维度观察,评测体系直接影响技术演进路径。CUGE基准通过将18个NLP任务映射到7大能力模块,推动了中文模型在对话式交互(提升19.8%)、数学推理(提升23.5%)等领域的定向优化 [5]。这种系统性评估甚至改变了研发范式:2024年PNAS研究显示,Goldin-Meadow团队通过分析儿童语言学习数据,反向优化了大模型的语言习得算法,使模型参数效率提升40% [6]。更值得关注的是,评测正在成为技术伦理治理的抓手——新型评测范式新增的道德准则评估维度,通过将社会价值观转化为可计算指标(如意图识别模块占比15% [4],有效制约了模型输出的不可控性。
评测体系的完善程度直接关系到技术普惠化进程。当前自动驾驶领域已形成典型应用闭环:Talk2Drive系统通过将语音指令解析误差率从18.7%降至6.2% [6],验证了评测驱动的技术迭代模式。这种模式在医疗、教育等领域复制时,需要兼顾领域特殊性——EnviroExam基准针对环境科学领域开发的专项指标,成功将模型在气候预测任务中的偏差度降低27% [2]。评测技术的持续进化,本质上是在搭建技术能力与人类需求之间的动态适配器,其发展水平决定着AI技术落地的深度与广度。
构建客观公正且定量化的模型评测体系对用户理解模型真实能力具有三重战略意义。首先,该体系通过可量化的技术指标(如DIKWP框架中语义一致性得分差异达12.3% [4]揭示了模型能力的”技术指纹”,使用户能精准识别模型在数据处理(ChatGPT-4o在数据转换稳定性得分达92.7分)、信息提取(ChatGPT-o3-mini在多模态数据转化路径准确率达89.4%)等维度的差异化表现。这种显性化对比突破了传统”黑盒测试”的局限,为开发者提供了精准的改进方向。
其次,评测体系通过结构化维度划分构建了技术能力的”全景导航图”。如EnviroExam基准将环境科学领域模型评估分解为数据质量验证(占比40%)、领域知识嵌入度检测(30%)、动态推理适应性(20%)等子项 [2],用户可据此定位模型在特定领域的”能力洼地”。这种导航功能在自动驾驶领域尤为突出,Talk2Drive系统通过将语音指令解析误差率从18.7%降至6.2% [