专题讨论3:基于图的基本原理实现走迷宫问题

问题描述
迷宫通常以二维矩阵形式呈现,矩阵中的元素用 0 和 1 表示,其中 0 代表通路,1 代表墙壁 。存在特定的起点和终点坐标,目标是从起点出发,寻找一条能够到达终点的路径。
实现思路
将迷宫中的每个可通行单元格看作图中的一个节点 。如果两个可通行单元格在迷宫中相邻(上、下、左、右方向),则在对应的图节点之间建立一条边。可以使用邻接表或邻接矩阵来表示图结构。
算法概述
我将使用深度优先访问(DFS)算法来解决该问题,从起点开始,沿着一条路径不断深入探索,直至遇到死胡同或者终点。若遇到死胡同,则回溯(算法的核心就是递归遍历+回溯)到上一个未完全探索的节点,尝试其他分支路径。
算法实现
本质上是对无权无向图的 DFS 遍历:
#include <iostream>
#include <vector>
using namespace std;// 定义方向数组:上、下、左、右
const int dx[] = { -1, 1, 0, 0 };
const int dy[] = { 0, 0, -1, 1 };// DFS函数
bool dfs(int x, int y, const vector<vector<int>>& maze, vector<vector<bool>>& visited, vector<pair<int, int>>& path) {int m = maze.size();int n = maze[0].size();// 越界、碰壁或已访问过if (x < 0 || x >= m || y < 0 || y >= n || maze[x][y] == 1 || visited[x][y]) {return false;}visited[x][y] = true;path.push_back({ x, y });// 到达终点if (x == m - 1 && y == n - 1) {return true;}// 向四个方向递归搜索for (int i = 0; i < 4; ++i) {int newX = x + dx[i];int newY = y + dy[i];if (dfs(newX, newY, maze, visited, path)) {return true;}}// 回溯path.pop_back();return false;
}int main() {// 定义迷宫(0表示通路,1表示墙壁)vector<vector<int>> maze = {{0, 1, 0, 0, 0},{0, 1, 0, 1, 0},{0, 0, 0, 0, 0},{0, 1, 1, 1, 0},{0, 0, 0, 1, 0}};int m = maze.size();int n = maze[0].size();// 初始化访问标记数组vector<vector<bool>> visited(m, vector<bool>(n, false));// 存储路径vector<pair<int, int>> path;// 从起点(0,0)开始DFS搜索bool found = dfs(0, 0, maze, visited, path);// 输出结果if (found) {cout << "找到路径!路径如下:" << endl;for (const auto& p : path) {cout << "(" << p.first << ", " << p.second << ") ";}cout << endl;}else {cout << "未找到路径!" << endl;}return 0;
}算法详细讲解
数据结构
1)方向数组 dx 和 dy;
分别表示四个方向的坐标偏移:上、下、左、右;通过与 dx[i] 和 dy[i] 组合,可以计算出从当前位置 (x,y) 移动后的新坐标。
const int dx[] = { -1, 1, 0, 0 };
const int dy[] = { 0, 0, -1, 1 };2)访问标记数组 visited;
用来记录每个位置是否被访问过,防止重复访问。
vector<vector<bool>> visited(m, vector<bool>(n, false));3)路径 path;
使用动态数组vector<pair<int, int>>& path 来存储坐标点。每个 pair<int, int> 表示迷宫中的一个单元格位置。通过 push_back() 和 pop_back() 来动态修改当前路径。
vector<pair<int, int>> path;关键函数
1)DFS函数主要是用来递归+回溯。
2)主函数主要是提供迷宫,调用DFS函数。
代码运行结果展示
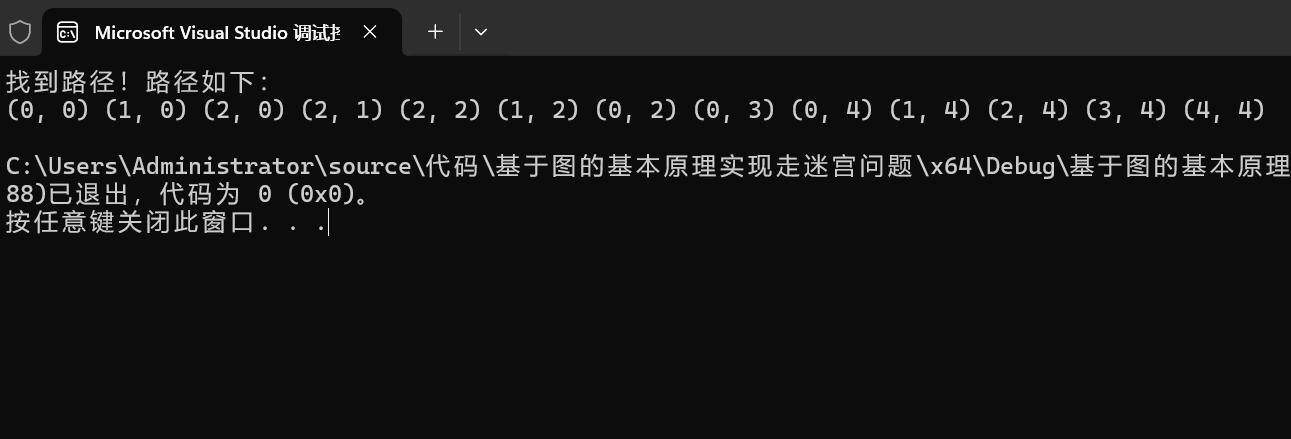
时间复杂度和空间复杂度
时间复杂度:
在最坏情况下,需要遍历迷宫中的每一个单元格,所以时间复杂度为O(m*n) ,其中m是迷宫的行数,n是迷宫的列数。
空间复杂度:
因为使用了递归,递归调用栈的深度最大为迷宫单元格数量(也就是全都访问的情况),所以说空间复杂度为O(m*n) 。
与栈走迷宫相比
因为之前刚学栈的时候,有做过栈走迷宫的专题讨论,当时还不是很会使用C++就用的C语言解决,处理的也比较粗糙;学完图以后,最直观的是代码段变短了。更加清晰明了,易于理解了。
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>// 定义栈结构
// 数据类型:用于存储位置坐标 (x, y) 以及方向 di
typedef struct datatype {int x, y, di;
} ElemType;// 节点:栈中的每个元素由节点表示,包含数据和指向下一个节点的指针
typedef struct node {ElemType data;struct node* next;
} Node;// 栈顶指示:表示栈的结构体,包含栈中元素的数量和指向栈顶节点的指针
typedef struct stack {int count; // 记录栈中元素的数量Node* point;
} Stack;// 方向存储结构:用于存储方向的偏移量,xx 和 yy 分别表示 x 和 y 方向的偏移
typedef struct {int xx, yy;
} Direction;// 创建节点
// 该函数用于创建一个新的节点,并将传入的数据存储在节点中
Node* create_node(ElemType data) {// 为新节点分配内存Node* new_node = (Node*)malloc(sizeof(Node));if (new_node) {// 若内存分配成功,将数据赋值给新节点的数据部分new_node->data = data;// 新节点的下一个节点指针初始化为 NULLnew_node->next = NULL;return new_node;}else {// 若内存分配失败,输出错误信息printf("ERROR\n");return NULL;}
}// 初始化栈
// 该函数用于初始化栈,将栈的元素数量置为 0,栈顶指针置为 NULL
void stack_init(Stack* top) {top->count = 0;top->point = NULL;
}// 判断栈是否为空
// 该函数用于判断栈是否为空,若栈中元素数量为 0,则返回 1,否则返回 0
int isEmpty(Stack* top) {if (top->count == 0) {return 1;}return 0;
}// 入栈
// 该函数用于将一个元素压入栈中
void push(Stack* top, ElemType data) {// 创建一个新节点并存储传入的数据Node* new_node = create_node(data);if (new_node) {// 若新节点创建成功,栈中元素数量加 1top->count++;if (top->count == 1) {// 如果入栈的是第一个节点,将栈顶指针指向新节点top->point = new_node;}else {// 否则,将新节点的 next 指针指向原来的栈顶节点,再将栈顶指针指向新节点new_node->next = top->point;top->point = new_node;}}elsereturn;
}// 出栈
// 该函数用于将栈顶元素弹出栈
Node* pop(Stack* top) {Node* pop_node = NULL;if (!isEmpty(top)) {// 若栈不为空,将栈顶节点指针赋值给 pop_nodepop_node = top->point;// 将栈顶指针指向原来栈顶节点的下一个节点top->point = pop_node->next;// 栈中元素数量减 1top->count--;}return pop_node;
}// 非递归输出路径
// 该函数用于非递归地输出栈中存储的路径,避免递归可能导致的栈溢出
void show_path(Node* node) {if (!node) return;// 创建一个临时栈用于反转路径顺序Stack reversed;stack_init(&reversed);// 将原栈中的元素逐个压入临时栈,实现反转Node* current = node;while (current) {push(&reversed, current->data);current = current->next;}// 输出反转后的路径current = reversed.point;while (current) {printf("(%d,%d)\n", current->data.x, current->data.y);current = current->next;}// 释放临时栈的内存while (!isEmpty(&reversed)) {free(pop(&reversed));}
}// 检查新位置是否越界
// 该函数用于检查给定的位置 (x, y) 是否在迷宫范围内且该位置为通路(值为 0)
int isValid(int maze[][5], int x, int y) { return x >= 0 && x < 5 && y >= 0 && y < 5 && maze[x][y] == 0;
}// 判断能否走出去,路径压入栈中
// 该函数用于寻找从起点 (startx, starty) 到终点 (endx, endy) 的路径
int FindPath(int maze[][5], Stack* stack, Direction dir[], int startx, int starty, int endx, int endy) {// 确保栈指针不为空assert(stack);// 检查起点是否合法if (!isValid(maze, startx, starty)) {printf("起点不合法!\n");return 0;}int x, y, di;int line, col;// 初始化:将起点标记为已访问maze[startx][starty] = -1;// 创建起点元素并压入栈ElemType start = { startx, starty, -1 };push(stack, start);while (!isEmpty(stack)) {// 弹出栈顶元素Node* po = pop(stack);ElemType temp = po->data;x = temp.x;y = temp.y;di = temp.di; // 修正:直接使用di,不再递增// 释放弹出节点的内存free(po);// 尝试从当前方向开始探索所有可能的方向while (di < 4) {// 计算新位置的坐标line = x + dir[di].xx;col = y + dir[di].yy;if (isValid(maze, line, col)) {// 若新位置合法,保存当前状态并继续探索temp = { x, y, di };push(stack, temp);// 更新当前位置x = line;y = col;// 标记新位置为已访问maze[line][col] = -1;// 检查是否到达终点if (x == endx && y == endy) {// 到达终点,将终点压入栈并返回成功temp = { x, y, -1 };push(stack, temp);return 1;}// 从新位置重新开始探索所有方向di = 0;}else {// 尝试下一个方向di++;}}}// 栈为空,说明没有找到路径return 0;
}int main() {// 定义一个 5x5 的迷宫矩阵,1 表示墙,0 表示通路int maze[5][5] = {{0, 1, 0, 0, 0},{0, 1, 0, 1, 0},{0, 0, 0, 0, 0},{0, 1, 1, 1, 0},{0, 0, 0, 1, 0}};// 定义并初始化栈Stack stack;stack_init(&stack);// 方向数组:分别表示右、下、左、上四个方向的偏移量Direction directions[4] = { {0,1}, {1,0}, {0,-1}, {-1,0} };// 调用 FindPath 函数寻找路径,并输出是否找到路径的结果// 修改起点为(0,0),终点为(4,4)以匹配迷宫布局printf("能否走出去:%d\n", FindPath(maze, &stack, directions, 0, 0, 4, 4));// 若找到路径,输出路径show_path(stack.point);// 释放栈中所有节点的内存,防止内存泄漏while (!isEmpty(&stack)) {free(pop(&stack));}return 0;
}代码运行展示
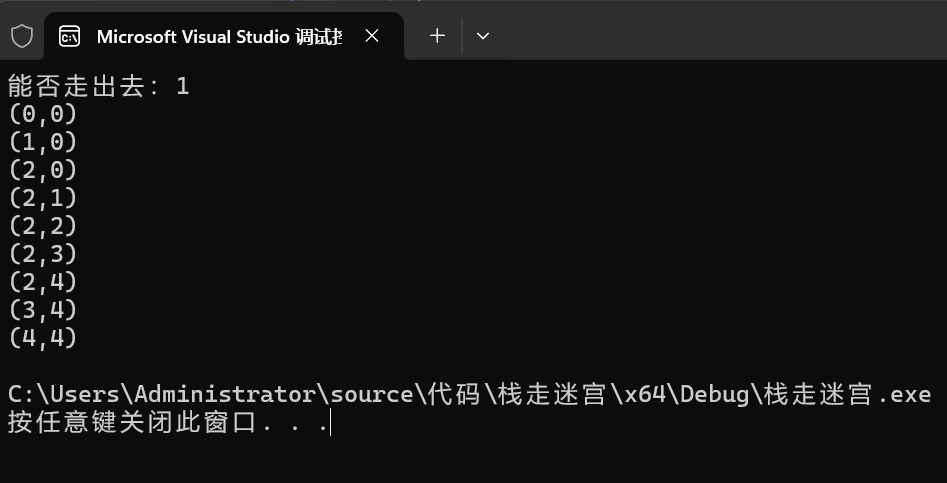
这次使用了递归调用的思想,而之前则是手动实现栈结构,通过用循环来模拟递归的过程,所以说之前的代码会很冗长。
学习心得
pair --标准库模板类的学习!!
pair 的主要作用是将两个不同类型的值组合成一个单元。// 存储一对相关的值,例如坐标点(x, y)、键值对等。
基本结构
template <class T1, class T2>
struct pair {T1 first; // 第一个值T2 second; // 第二个值
};特点
1)简洁性:直接用 pair 存储坐标,无需额外定义结构体。
2)高效性:pair 是轻量级的,访问 first 和 second 的开销极小。
3)适配容器:vector 可以方便地存储和管理 pair 对象。
用法示例
#include <iostream>
#include <vector>
using namespace std;int main() {vector<pair<int, int>> path;// 添加坐标点path.push_back({0, 0}); // 起点 (0, 0)path.push_back({0, 1}); // 向右移动path.push_back({1, 1}); // 向下移动// 遍历路径并打印每个点for (const auto& p : path) {cout << "(" << p.first << ", " << p.second << ") ";}// 输出:(0, 0) (0, 1) (1, 1)return 0;
}以上代码展示了如何使用 pair 存储坐标,并遍历路径。
在我的代码段中的运用
在我的代码段中,vector<pair<int, int>>& path 是一个用来存储坐标点的动态数组。每个 pair<int, int> 表示迷宫中的一个单元格位置:
first:对应单元格的行坐标(x)。
second:对应单元格的列坐标(y)。
path.push_back({x, y}) 则会将当前坐标 (x, y) 作为一个 pair 对象添加到路径中。
今天的分享就到这里啦~~