【第三十六周】LoRA 微调方法
LoRA
- 摘要
- Abstract
- 文章信息
- 引言
- 方法
- LoRA的原理
- LoRA在Transformer中的应用
- 补充
- 其他细节
- 实验与分析
- LoRA的使用
- 论文实验结果分析
- 总结
摘要
本篇博客介绍了LoRA(Low-Rank Adaptation),这是一种面向大规模预训练语言模型的参数高效微调方法,旨在解决全模型微调带来的高计算与存储成本问题。其核心思想是在不修改原始模型权重的前提下,引入一对可训练的低秩矩阵,以近似模拟微调过程中权重的变化,从而以极小的参数量实现模型在下游任务上的快速适配。具体来说,LoRA 针对 Transformer 中的线性层(如注意力机制中的投影矩阵)进行改造,将参数更新表示为两个小矩阵 A A A和 B B B的乘积 Δ W = B A \Delta W = BA ΔW=BA,训练时仅更新这两个矩阵,部署时可与原始权重合并,保持推理效率不变。实验表明,LoRA 能在多种自然语言处理任务中达到接近甚至超过全量微调的性能,同时显著减少所需的可训练参数量。该方法优势在于高效、通用、部署灵活,但在模块选择、模型融合与多任务共享方面仍存在一定限制。
Abstract
This blog introduces LoRA (Low-Rank Adaptation), a parameter-efficient fine-tuning method designed for large-scale pre-trained language models. It aims to address the high computational and storage costs associated with full-model fine-tuning. The core idea of LoRA is to approximate weight updates during fine-tuning by introducing a pair of trainable low-rank matrices, without modifying the original model parameters. This enables rapid adaptation to downstream tasks with a minimal number of additional parameters. Specifically, LoRA modifies the linear layers within Transformer architectures—such as the projection matrices in attention mechanisms—by expressing the weight update as the product of two smaller matrices, Δ W = B A \Delta W = BA ΔW=BA. During training, only these matrices are updated, and at deployment time, the update can be merged into the original weights to maintain inference efficiency. Experiments show that LoRA achieves performance comparable to or even better than full fine-tuning across various natural language processing tasks, while significantly reducing the number of trainable parameters. Its advantages include efficiency, generality, and deployment flexibility, though it still faces limitations in terms of module selection, model merging, and multi-task sharing.
文章信息
Title:LoRA: Low-Rank Adaptation of Large Language Models
Author:Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen
Source:https://arxiv.org/abs/2106.09685
引言
在自然语言处理(NLP)领域,“预训练 + 微调”已成为主流范式:研究者先在大规模通用语料上训练语言模型,再针对具体下游任务进行参数更新(微调)。然而,随着模型规模的不断扩大,全模型微调(full fine-tuning)带来了极高的存储和计算成本。例如,对 GPT-3 175B(约 1750 亿参数)进行独立微调,不仅需要为每个任务保存一份同规模的模型检查点,更在部署时产生巨大的显存开销,难以在实际系统中承载与切换多任务需求。
为了解决上述瓶颈,研究者提出了多种参数高效的适配方法,包括仅更新部分参数(如 Bias-only/BitFit)、插入轻量级适配层(Adapters)或对输入进行可微调的提示优化(prefix-tuning、prompt tuning)等。但这些方法存在各自局限:部分方案会引入额外的推理延迟(Adapters),或占用原有序列长度(prefix-tuning),且在模型质量上往往难以完全匹配全模型微调的效果。
本文介绍的LoRA方法在保持原始预训练权重冻结不变的前提下,仅向 Transformer 各层注入一对低秩矩阵来分解并学习微调时的权重增量。LoRA 可以极大地减少需要微调的参数量,同时在推理时可将低秩增量与原权重合并,不引入额外延迟。
方法
传统的全模型微调(full fine-tuning)会对预训练模型的所有权重 W 0 W_0 W0进行梯度更新,导致每个下游任务都需要保存一份与原模型规模相同的参数。
全模型微调主要有以下三个问题:
- 计算成本高,需要微调的参数与预训练好的参数数量一致。
- 存储开销大,每个任务都要保存一份完整模型副本,占用大量硬盘空间。
- 部署不灵活,想切换任务时,需要重新加载整套参数,速度慢且占显存。
LoRA的原理

- 在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank。
- 训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B 。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。
- 用随机高斯分布初始化 A ,用 0 矩阵初始化 B ,保证训练的开始此旁路矩阵依然是 0 矩阵。
在标准微调中,会直接更新预训练权重 W W W。但在 LoRA 中,不直接改动原始的 W W W ,公式如下:

LoRA 的关键点在于:不直接学习 Δ W \Delta W ΔW(它的大小和W一样)而是把它拆成两个更小的矩阵 A A A和 B B B的乘积: Δ W = B A \Delta W = BA ΔW=BA其中 A ∈ R r × d A \in \mathbb R^{r\times d} A∈Rr×d, B ∈ R d × r B \in \mathbb R^{d\times r} B∈Rd×r,通常 r 很小(如 4、8、16),远小于 d。
这就叫“低秩分解”,它能大大减少需要学习的参数数量。
例如,如果 W W W 是一个 1024 × 1024 1024\times 1024 1024×1024 的矩阵,有 1,048,576 个参数,而 LoRA 只需要学习两个小矩阵,总参数是 2 × 1024 × r 2\times 1024 \times r 2×1024×r,但 r = 8 r=8 r=8时,只需要 16,384 个参数,相当于只训练原始参数的约 1.6%。
训练时只更新 A A A和 B B B,而模型原始参数 W W W 保持不变,这样就大大减少了存储和计算需求。
另外,LoRA 把 B B B初始化为全零, A A A初始化为小的随机值,是为了让模型一开始行为不变,即 Δ W x = 0 \Delta Wx=0 ΔWx=0。
LoRA的这种使用旁路更新的方法有点类似残差连接的思想,都是保证已学到的不会退化,再学其他的。
LoRA在Transformer中的应用
LoRA 方法可应用于任意密集层,论文中写的主要是Transformer层的自注意力模块,在该模块中,包含查询( W q W_q Wq)、键( W k W_k Wk)、值( W v W_v Wv)和输出投影( W o W_o Wo)。LoRA 的论文主要选择对注意力模块中的查询(Query)和数值(Value)矩阵进行插入,因为这两个部分对模型的表示能力影响很大。其他部分可以保持不变。
补充
为什么矩阵B、A不能同时为0?
这主要是因为如果矩阵 A A A 也用0初始化,那么矩阵 B B B 梯度就始终为0,无法更新参数,导致 Δ W = B A = 0 \Delta W = BA=0 ΔW=BA=0,推导如下:
对于 h = W 0 x + B A x h=W_0x+BAx h=W0x+BAx,设 h ( 2 ) = B A x h^{(2)}=BAx h(2)=BAx,则

因此:

如果矩阵 A A A 也用0初始化,那么上面的梯度就变成了0。所以矩阵 A A A也用0初始化,那么上面的梯度就变成了0。
其他细节
- 缩放因子:由于 Δ W = B A \Delta W = BA ΔW=BA通常比较小,论文中加入了一个缩放因子 α / r \alpha /r α/r,防止它在训练过程中太弱。这个因子可以看作是学习率的调节器。
- 推理时合并参数:在部署模型时,LoRA 可以把 Δ W \Delta W ΔW 直接加到 W W W 里变成一个新的矩阵,然后就不需要再动态计算 B A x BAx BAx 了,这样可以节省运行时计算资源。
实验与分析
LoRA的使用
目前 LORA 已经被 HuggingFace 集成在了 PEFT(Parameter-Efficient Fine-Tuning) 代码库里。
使用也非常简单,比如使用 LORA 微调 BigScience 机器翻译模型:
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
模型微调好之后,加载也非常简单,只需要额外加载 LORA 参数:
model.load_state_dict(torch.load(peft_path), strict=False)
论文实验结果分析
理解任务上:

MNLI、SST-2 、MRPC、CoLA、QNLI、QQP、RTE、STS-B表示各项任务:
- MNLI(Multi-Genre Natural Language Inference):该任务是一个自然语言推理任务,要求模型根据给定的前提和假设来判断它们之间的关系(蕴含、中立或矛盾)。数据集中包含来自不同文体(新闻、文学等)的句子对。
- SST-2(Stanford Sentiment Treebank):该任务是一个情感分析任务,要求模型判断给定句子的情感是正面还是负面。
- MRPC(Microsoft Research Paraphrase Corpus):该任务是一个语义相似度任务,要求模型判断给定句子对是否具有语义相似性。
- CoLA(Corpus of Linguistic Acceptability):该任务是一个语言可接受性任务,要求模型判断给定句子是否符合语法规则和语言习惯。
- QNLI(Question NLI):该任务是一个自然语言推理任务,要求模型根据给定的问题和前提,判断问题是否可以从前提中推导出来。
- QQP(Quora Question Pairs):该任务是一个语义相似度任务,要求模型判断给定问题对是否具有语义相似性。
- RTE(Recognizing Textual Entailment):该任务是一个自然语言推理任务,要求模型根据给定的前提和假设来判断它们之间的关系(蕴含或不蕴含)。
- STS-B(Semantic Textual Similarity Benchmark):该任务是一个语义相似度任务,要求模型判断给定句子对是否具有语义相似性,但是与MRPC不同的是,STS-B中的句子对具有连续的语义相似性等级。
可以看到 LORA 相比其它微调方法,可训练参数最少,但是整体上效果最好。
生成任务上:


在ROBbase 、GPT-2和GPT-3上,LORA 也取得了不错的效果(见上图)。
当增加微调方法的可训练参数量时,其它微调方法都出现了性能下降的现象,只有 LORA 的性能保持了稳定,见下图:
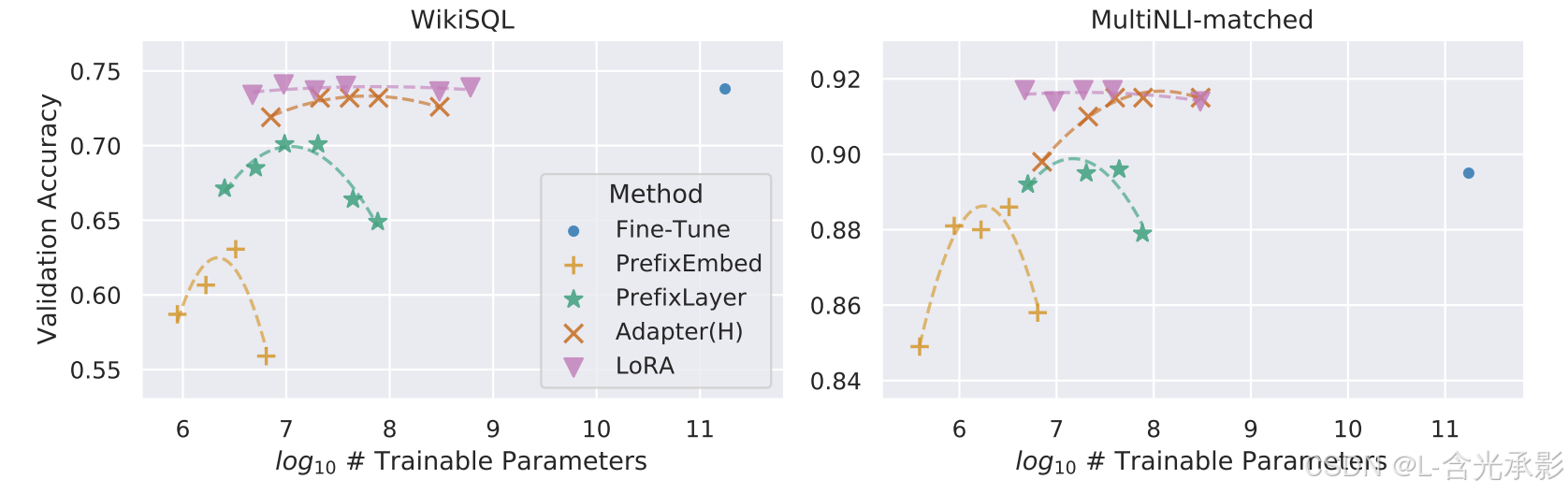
秩的选择:

实验结果显示,对于一般的任务, r r r取1,2,4,8就足够了,而一些领域差距比较大的任务可能需要更大的取值。
同时,增加 r r r 并不能提升微调的效果,这可能是因为参数量增加需要更多的语料。
总结
LoRA(Low-Rank Adaptation)是一种面向大规模预训练语言模型的参数高效微调方法,它通过引入两个低秩矩阵对权重更新进行重参数化,从而在冻结原始模型权重的基础上,仅训练极少量参数以适配下游任务。其核心结构是在特定的线性层(如注意力投影)中加入一个低秩的增量模块,训练时只更新该模块,并通过 Δ W = B A \Delta W = BA ΔW=BA的形式替代对原始权重 W W W的直接微调;推理时,该增量可以被合并进原模型中,不增加计算开销。LoRA 的工作流程包括:选择目标层、插入低秩模块、初始化并训练 A , B A,B A,B,以及部署前合并增量,实现在不影响模型性能的前提下大幅减少计算和存储成本。它的优势在于参数效率高、推理延迟低、适合多任务部署,缺点则包括对任务适配位置敏感、尚未覆盖非线性模块,以及难以在多任务共享权重场景中完全合并模型。未来研究可进一步探索其在 MLP、LayerNorm 等模块中的扩展应用、多任务场景下的动态权重调度机制,以及与提示学习等方法的融合潜力。