字节跳动开源通用图像定制模型DreamO,支持风格转换、换衣、身份定制、多条件组合等多种功能~
项目背景分析

图像定制是一个快速发展的领域,包括身份(ID)、风格、服装试穿(Try-On)等多种任务。现有研究表明,大规模生成模型在这些任务上表现出色,但大多数方法是任务特定的,难以推广到其他定制类型。例如,身份定制可能专注于面部特征,而风格转换则关注整体视觉效果。这种任务隔离限制了模型在实际应用中的灵活性,尤其是当需要同时处理多种条件(如同时改变面部和服装)时。
DreamO的开发背景正是为了填补这一空白。研究显示,DreamO旨在创建一个统一的框架,支持广泛的定制任务,包括但不限于IP(可能指图像提示)、ID(身份)、Try-On(虚拟试穿)、风格转换和多条件整合。它的目标是通过一个单一模型,实现这些任务的无缝整合,提供更高效、更通用的图像定制解决方案。例如,用户可以上传一张参考图像,并通过提示同时改变人物的服装和背景风格,而无需使用多个独立模型。
DreamO的开发受到现有研究的启发,试图解决任务特定方法在通用性上的不足。其设计理念是让模型能够处理复杂的多条件场景,例如同时保持面部身份的同时改变服装,这在之前的模型中往往需要额外的后处理或多模型组合。
模型结构详解
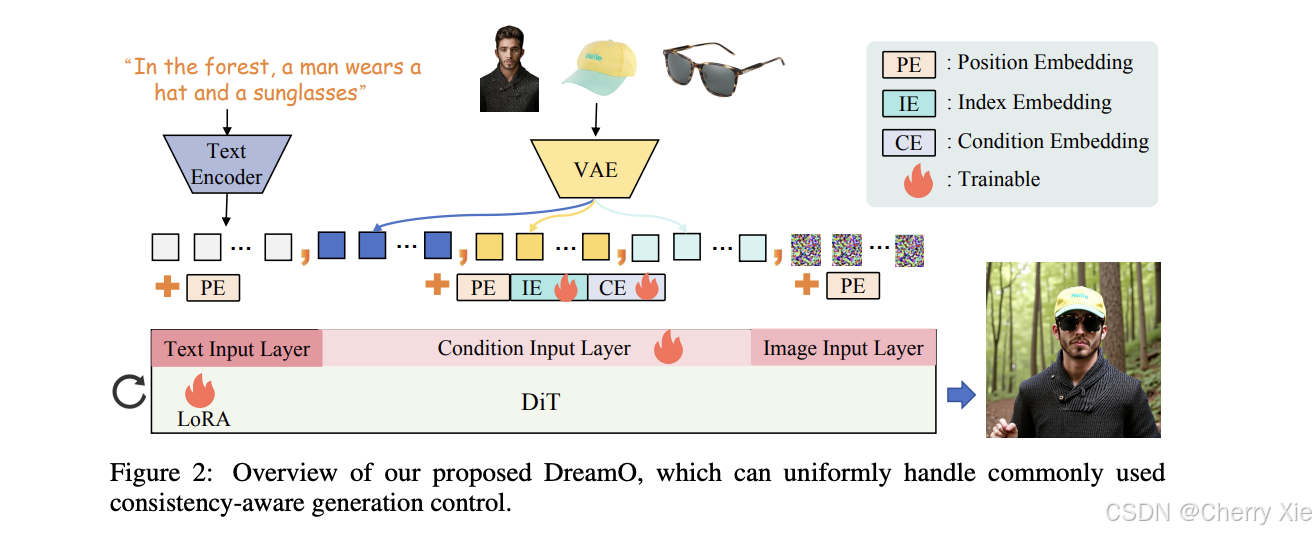
DreamO的模型结构基于扩散变换器(DiT)架构,这是一种现代扩散模型的变体,相比传统的UNet-style扩散模型更具扩展性和效率。DiT通过transformer层处理图像生成任务,类似于自然语言处理中的GPT模型,但专注于图像的“去噪”过程。研究表明,这种架构能够统一处理不同类型的输入数据,例如参考图像、文本提示和条件标签,从而支持多种定制任务。

一个关键特性是特征路由约束(feature routing constraint)。这一机制确保模型能够从参考图像中精确查询相关信息,减少不同条件之间的冲突。例如,在身份定制任务中,模型需要专注于面部特征,而在服装试穿任务中,则需要关注服装区域。这种约束通过路由机制实现,类似于网络中的数据流控制,确保信息流向正确的处理路径,从而提高定制的精确性和保真度。
另一个重要设计是占位符策略(placeholder strategy)。这一策略通过在特定位置关联条件,允许用户控制条件在生成图像中的放置。例如,用户可以指定“将参考图像中的面部身份放置在图像的中心”,从而实现更精细的控制。这种设计特别适用于需要精确定位的场景,如虚拟试穿或风格迁移。

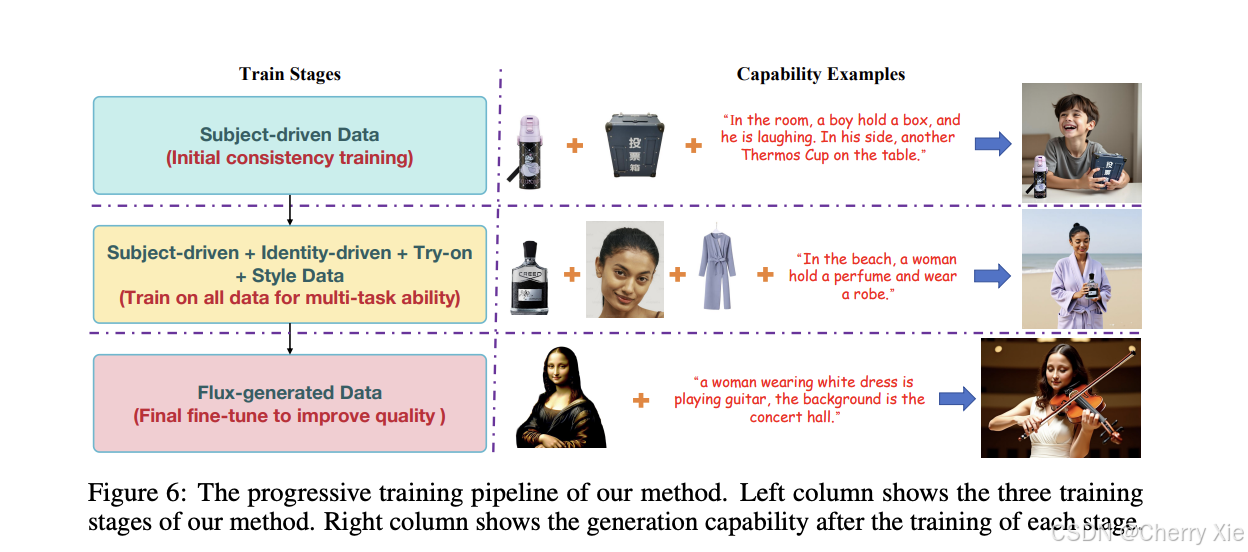
训练过程采用渐进式策略,分为三个阶段:
-
初始阶段:在简单任务和有限数据上训练,建立模型的基线能力,确保基础一致性。例如,训练模型仅处理单一条件(如仅改变风格)。
-
全面扩展阶段:在此阶段,模型接受更全面的数据集,包括多种定制任务和复杂条件组合,增强其通用性和多任务处理能力。
-
质量对齐阶段:最后阶段通过微调纠正因低质量数据引入的偏差,确保生成图像的高质量输出,例如避免面部过于光滑或细节丢失。
技术细节与应用场景

DreamO支持的任务范围广泛,包括但不限于:
-
IP任务:类似于IP-Adapter,支持字符、物体和动物的广泛输入。
-
ID任务:专注于面部身份的保真度,类似于InstantID和PuLID,但面部保真度更高,尽管可能引入更多模型污染。

- Try-On任务:支持上传上衣、下装、眼镜、帽子等,启用多件服装的虚拟试穿。
研究指出,DreamO在面部身份保真度上优于之前的适配器方法,但可能在某些情况下(如面部过于光滑)需要调整指导尺度(guidance scale)。此外,其训练集不包括多件服装或ID+服装组合数据,但模型仍能很好地泛化到这些未见场景,显示出强大的泛化能力。

相关文献
在线体验地址:https://huggingface.co/spaces/ByteDance/DreamO
github地址:https://github.com/bytedance/DreamO
技术报告:https://arxiv.org/pdf/2504.16915