TASK03【Datawhale 组队学习】搭建向量知识库
文章目录
- 向量及向量知识库
- 词向量与向量
- 向量数据库
- 数据处理
- 数据清洗
- 文档分割
- 搭建并使用向量数据库
向量及向量知识库
词向量与向量
词向量(word embedding)是一种以单词为单位将每个单词转化为实数向量的技术。词向量背后的主要想理念是相似或相关的对象在向量空间中的距离应该很近。
词向量实际上是将单词转化为固定的静态的向量,虽然可以在一定程度上捕捉并表达文本中的语义信息,但忽略了单词在不同语境中的意思会受到影响这一现实。
通用文本向量(单位:文本):RAG应用中使用的向量技术一般为通用文本向量(Universal text embedding),该技术可以对一定范围内任意长度的文本进行向量化,输出的向量会捕捉更多的语义信息。
在RAG(Retrieval Augmented Generation,检索增强生成)方面向量的优势主要有两点:
- 向量比文字更适合检索。可以通过计算问题与数据库中数据的点积、余弦距离、欧几里得距离等指标,直接获取问题与数据在语义层面上的相似度;
- 向量比其它媒介的综合信息能力更强,当传统数据库存储文字、声音、图像、视频等多种媒介时,很难去将上述多种媒介构建起关联与跨模态的查询方法;但是向量却可以通过多种向量模型将多种数据映射成统一的向量形式。
在搭建 RAG 系统时,我们往往可以通过使用向量模型来构建向量,我们可以选择:
- 使用各个公司的 Embedding API;
- 在本地使用向量模型将数据构建为向量。
向量数据库
向量数据库(每个向量代表一个数据项)是用于高效计算和管理大量向量数据的解决方案。向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。
向量数据库中的数据以向量作为基本单位,对向量进行存储、处理及检索。当处理大量甚至海量的向量数据时,向量数据库索引和查询算法的效率明显高于传统数据库。
- Chroma(功能相对简单且不支持GPU加速,适合初学者使用。
- Weaviate 支持相似度搜索和最大边际相关性搜索外还可以支持结合多种搜索算法(基于词法搜索、向量搜索)的混合搜索
- Qdrant 有极高的检索效率和RPS支持本地运行、部署在本地服务器及Qdrant云三种部署模式
_ = load_dotenv(find_dotenv())from zhipuai import ZhipuAI
def zhipu_embedding(text: str):api_key = os.environ['ZHIPUAI_API_KEY']client = ZhipuAI(api_key=api_key)response = client.embeddings.create(model="embedding-3",input=text,)return responsetext = '要生成 embedding 的输入文本,字符串形式。'
response = zhipu_embedding(text=text)
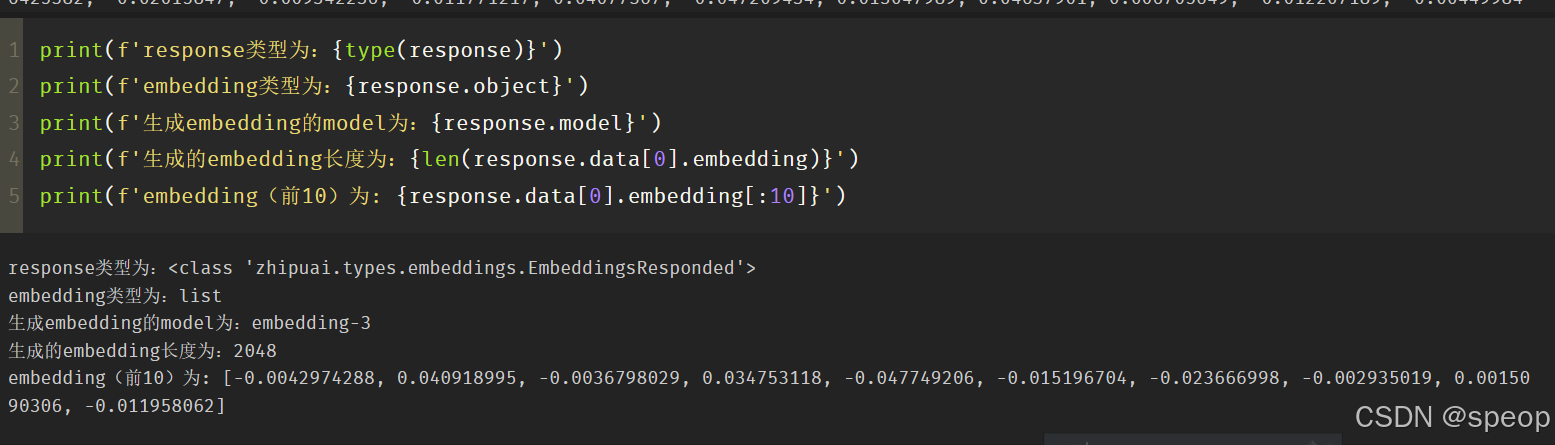
print(f'response类型为:{type(response)}')
print(f'embedding类型为:{response.object}')
print(f'生成embedding的model为:{response.model}')
print(f'生成的embedding长度为:{len(response.data[0].embedding)}')
print(f'embedding(前10)为: {response.data[0].embedding[:10]}')
数据处理
pdf读取:使用langchain的PyMuPDFLoader读取知识库的pdf,结果会包含 PDF 及其页面的详细元数据,并且每页返回一个文档。
from langchain_community.document_loaders import PyMuPDFLoader
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径
loader = PyMuPDFLoader("./pumpkin_book.pdf")
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载
pdf_pages = loader.load()
print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页")
markdown读取:
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("./1. 简介.md")
md_pages = loader.load()
page 中的每一元素为一个文档,变量类型为 langchain_core.documents.base.Document, 文档变量类型包含两个属性
- page_content 包含该文档的内容。
- meta_data 为文档相关的描述性数据。
pdf_page = pdf_pages[1]
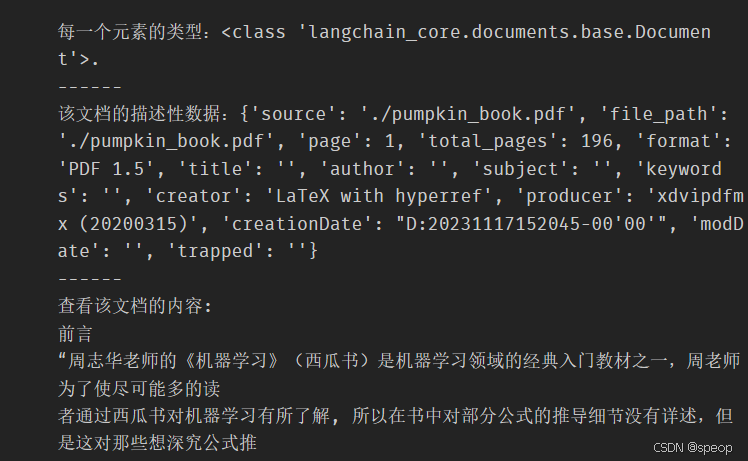
print(f"每一个元素的类型:{type(pdf_page)}.", f"该文档的描述性数据:{pdf_page.metadata}", f"查看该文档的内容:\n{pdf_page.page_content}", sep="\n------\n")
数据清洗
按照原文的分行添加了换行符\n,也在原本两个符号中间插入了\n
pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content)
print(pdf_page.page_content)
pdf_page.page_content = pdf_page.page_content.replace('•', '')
pdf_page.page_content = pdf_page.page_content.replace(' ', '')
print(pdf_page.page_content)
md_page.page_content = md_page.page_content.replace('\n\n', '\n')
print(md_page.page_content)文档分割
单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力,因此,在构建向量知识库的过程中,我们往往需要对文档进行分割,将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。
在检索时,我们会以 chunk 作为检索的元单位,也就是每一次检索到 k 个 chunk 作为模型可以参考来回答用户问题的知识,这个 k 是我们可以自由设定的。
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。
- chunk_size 指每个块包含的字符或 Token (如单词、句子等)的数量
- chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
- RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter(): 按字符来分割文本。
- MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。
- TokenTextSplitter(): 按token来分割文本。
- SentenceTransformersTokenTextSplitter(): 按token来分割文本
- Language(): 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
'''
* RecursiveCharacterTextSplitter 递归字符文本分割
RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置
RecursiveCharacterTextSplitter需要关注的是4个参数:* separators - 分隔符字符串数组
* chunk_size - 每个文档的字符数量限制
* chunk_overlap - 两份文档重叠区域的长度
* length_function - 长度计算函数
'''
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 知识库中单段文本长度
CHUNK_SIZE = 500
# 知识库中相邻文本重合长度
OVERLAP_SIZE = 50
# 使用递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE
)
text_splitter.split_text(pdf_page.page_content[0:1000])
split_docs = text_splitter.split_documents(pdf_pages)
print(f"切分后的文件数量:{len(split_docs)}")
print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}")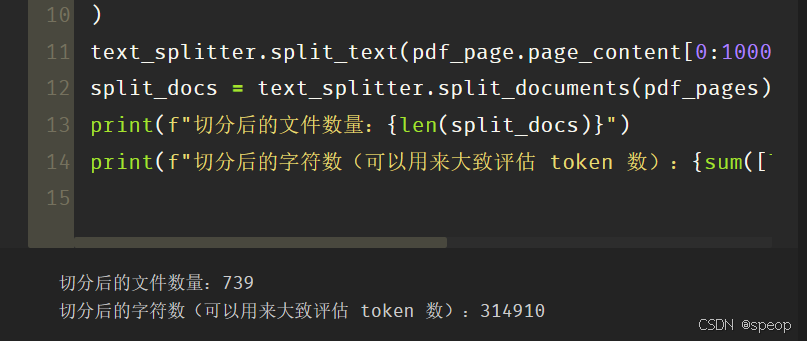
搭建并使用向量数据库
import os
from dotenv import load_dotenv, find_dotenv
# 获取folder_path下所有文件路径,储存在file_paths里
file_paths = []
folder_path = '../../data_base/knowledge_db'
for root, dirs, files in os.walk(folder_path):for file in files:file_path = os.path.join(root, file)file_paths.append(file_path)
print(file_paths[:3])
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
# 遍历文件路径并把实例化的loader存放在loaders里
loaders = []
for file_path in file_paths:file_type = file_path.split('.')[-1]if file_type == 'pdf':loaders.append(PyMuPDFLoader(file_path))elif file_type == 'md':loaders.append(UnstructuredMarkdownLoader(file_path))
# 下载文件并存储到text
texts = []
for loader in loaders: texts.extend(loader.load())
#载入后的变量类型为langchain_core.documents.base.Document, 文档变量类型同样包含两个属性
#page_content 包含该文档的内容。
#meta_data 为文档相关的描述性数据。
text = texts[1]
print(f"每一个元素的类型:{type(text)}.", f"该文档的描述性数据:{text.metadata}", f"查看该文档的内容:\n{text.page_content[0:]}", sep="\n------\n")