5.18 day24
知识点回顾:
- 元组
- 可迭代对象
- os模块
作业:对自己电脑的不同文件夹利用今天学到的知识操作下,理解下os路径。
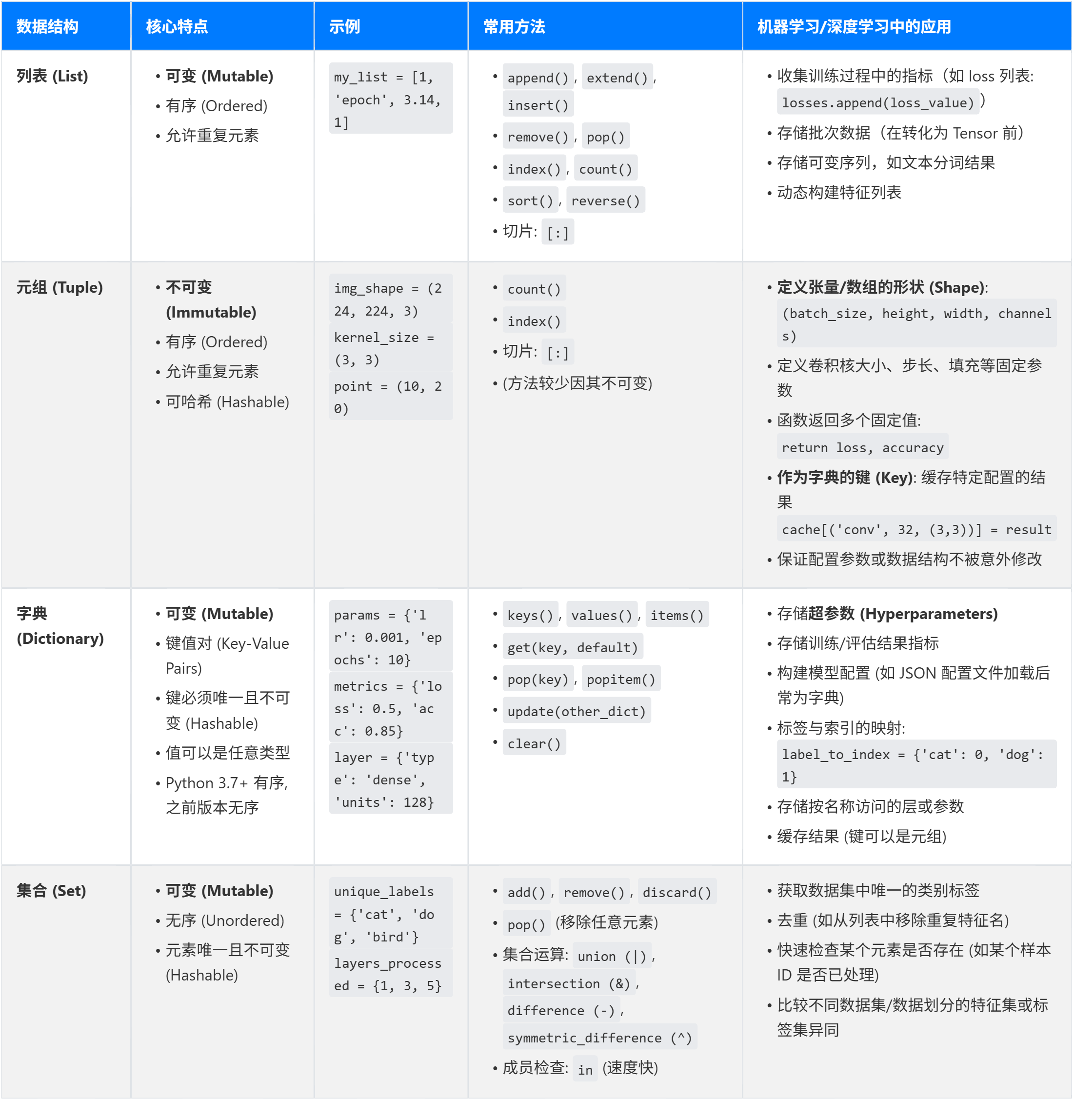
元组
元组的特点:
有序,可以重复,这一点和列表一样
元组中的元素不能修改,这一点非常重要,深度学习场景中很多参数、形状定义好了确保后续不能被修改。
很多流行的 ML/DL 库(如 TensorFlow, PyTorch, NumPy)在其 API 中都广泛使用了元组来表示形状、配置等。
可以看到,元组最重要的功能是在列表之上,增加了不可修改这个需求
元组的创建
my_tuple1 = (1, 2, 3)
my_tuple2 = ('a', 'b', 'c')
my_tuple3 = (1, 'hello', 3.14, [4, 5]) # 可以包含不同类型的元素
print(my_tuple1)
print(my_tuple2)
print(my_tuple3)# 可以省略括号
my_tuple4 = 10, 20, 'thirty' # 逗号是关键
print(my_tuple4)
print(type(my_tuple4)) # 看看它的类型# 创建空元组
empty_tuple = ()
# 或者使用 tuple() 函数
empty_tuple2 = tuple()
print(empty_tuple)
print(empty_tuple2)元组的常见用法
# 元组的索引
my_tuple = ('P', 'y', 't', 'h', 'o', 'n')
print(my_tuple[0]) # 第一个元素
print(my_tuple[2]) # 第三个元素
print(my_tuple[-1]) # 最后一个元素# 元组的长度获取
my_tuple = (1, 2, 3)
print(len(my_tuple))管道工程中pipeline类接收的是一个包含多个小元组的 列表 作为输入。
可以这样理解这个结构:
列表 []: 定义了步骤执行的先后顺序。Pipeline 会按照列表中的顺序依次处理数据。之所以用列表,是未来可以对这个列表进行修改。
元组 (): 用于将每个步骤的名称和处理对象捆绑在一起。名称用于在后续访问或设置参数时引用该步骤,而对象则是实际执行数据转换或模型训练的工具。固定了操作名+操作
不用字典因为字典是无序的。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score# 1. 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 构建管道
# 管道按顺序执行以下步骤:
# - StandardScaler(): 标准化数据(移除均值并缩放到单位方差)
# - LogisticRegression(): 逻辑回归分类器
pipeline = Pipeline([('scaler', StandardScaler()),('logreg', LogisticRegression())
])# 4. 训练模型
pipeline.fit(X_train, y_train)# 5. 预测
y_pred = pipeline.predict(X_test)# 6. 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型在测试集上的准确率: {accuracy:.2f}")可迭代对象
可迭代对象 (Iterable) 是 Python 中一个非常核心的概念。简单来说,一个可迭代对象就是指那些能够一次返回其成员(元素)的对象,让你可以在一个循环(比如 for 循环)中遍历它们。
Python 中有很多内置的可迭代对象,目前我们见过的类型包括:
序列类型 (Sequence Types):
list (列表)
tuple (元组)
str (字符串)
range (范围)
集合类型 (Set Types):
set (集合)
字典类型 (Mapping Types):
dict (字典) - 迭代时返回键 (keys)
文件对象 (File objects)
生成器 (Generators)
迭代器 (Iterators) 本身
# 列表 (list)
print("迭代列表:")
my_list = [1, 2, 3, 4, 5]
for item in my_list:print(item)# 元组 (tuple)
print("迭代元组:")
my_tuple = ('a', 'b', 'c')
for item in my_tuple:print(item)# 字符串 (str)
print("迭代字符串:")
my_string = "hello"
for char in my_string:print(char)# range (范围)
print("迭代 range:")
for number in range(5): # 生成 0, 1, 2, 3, 4print(number)# 集合类型 (Set Types)# 集合 (set) - 注意集合是无序的,所以每次迭代的顺序可能不同
print("迭代集合:")
my_set = {3, 1, 4, 1, 5, 9}
for item in my_set:print(item)# 字典 (dict) - 默认迭代时返回键 (keys)
print("迭代字典 (默认迭代键):")
my_dict = {'name': 'Alice', 'age': 30, 'city': 'Singapore'}
for key in my_dict:print(key)# 迭代字典的值 (values)
print("迭代字典的值:")
for value in my_dict.values():print(value)