布隆过滤器介绍及其在大数据场景的应用
目录
- 布隆过滤器(Bloom Filter)介绍
- 一、布隆过滤器的基本原理
- 插入元素过程:
- 查询元素过程:
- 二、布隆过滤器的特点
- 三、误判率计算
- 四、举例说明
- 五、总结
- Python版的简单布隆过滤器实现示例
- 一、简单布隆过滤器Python示例
- 二、布隆过滤器在离线数仓和分析数据库中的应用场景
- 三、具体应用说明
- 1. 离线数仓(Hive、Spark、Hadoop)
- 2. 实时分析数据库(Doris、ClickHouse)
- 四、总结
布隆过滤器(Bloom Filter)介绍
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用于判断一个元素是否在一个集合中。它的特点是:
- 快速判断元素是否存在
- 可能存在误判(假阳性),但不会漏判(假阴性)
- 占用空间小,适合大规模数据去重、过滤
一、布隆过滤器的基本原理
布隆过滤器由一个长度为 m 的位数组(bit array)和 k 个独立的哈希函数组成。
插入元素过程:
- 对要插入的元素,使用这 k 个哈希函数分别计算出 k 个哈希值,这些哈希值对应位数组中的 k 个位置。
- 将这 k 个位置的位都设置为 1。
查询元素过程:
- 对查询元素,同样用这 k 个哈希函数计算出 k 个位置。
- 检查这 k 个位置的位是否全部为 1:
- 全部为1:元素可能存在(存在假阳性)。
- 有任意一位为0:元素一定不存在。
二、布隆过滤器的特点
| 特性 | 说明 |
|---|---|
| 空间效率 | 远小于存储所有元素的集合,适合海量数据 |
| 查询速度 | 非常快,时间复杂度为 O(k) |
| 误判率 | 存在假阳性(可能误判存在),但无假阴性 |
| 不支持删除 | 传统布隆过滤器不支持删除元素(有变种支持) |
| 适用场景 | 大数据去重、缓存穿透过滤、网络黑名单检测等 |
三、误判率计算
假设:
- 位数组长度为 m
- 插入元素数量为 n
- 使用哈希函数个数为 k
误判率(假阳性概率)大致为:
[
\left(1 - e^{-\frac{k n}{m}}\right)^k
]
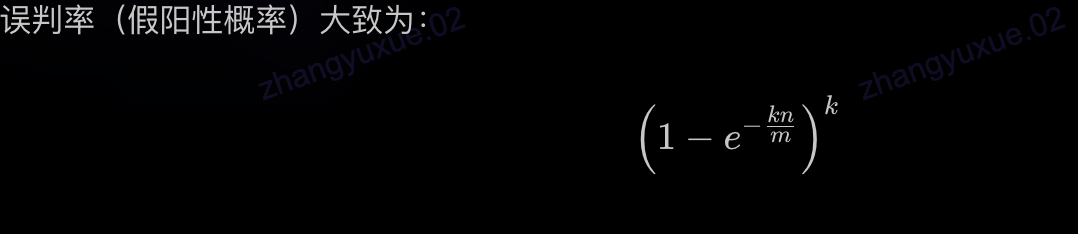
- 通过合理选择 m 和 k,可以控制误判率在可接受范围。
四、举例说明
假设布隆过滤器位数组长度为10位(初始全为0),有2个哈希函数:
- 插入元素“A”:哈希函数分别映射到位置2和5,将这两位设为1。
- 查询元素“B”:哈希函数映射到位置2和7,位置7为0,说明“B”一定不在集合中。
- 查询元素“A”:位置2和5都为1,说明“A”可能存在。
五、总结
布隆过滤器是一种用空间换时间的高效数据结构,适合快速判断元素是否存在于大规模集合中,缺点是存在一定误判率,且传统版本不支持删除。
Python版的简单布隆过滤器实现示例
一、简单布隆过滤器Python示例
import mmh3 # MurmurHash哈希库,安装:pip install mmh3
from bitarray import bitarray # 位数组库,安装:pip install bitarrayclass BloomFilter:def __init__(self, size=1000, hash_count=3):self.size = size # 位数组大小self.hash_count = hash_count # 哈希函数个数self.bit_array = bitarray(size)self.bit_array.setall(0)def add(self, item):for i in range(self.hash_count):# 计算哈希值并映射到位数组索引digest = mmh3.hash(item, i) % self.sizeself.bit_array[digest] = 1def check(self, item):for i in range(self.hash_count):digest = mmh3.hash(item, i) % self.sizeif self.bit_array[digest] == 0:return False # 一定不存在return True # 可能存在# 使用示例
bf = BloomFilter(size=5000, hash_count=5)
bf.add("user_123")
print(bf.check("user_123")) # True,可能存在
print(bf.check("user_456")) # False,一定不存在
二、布隆过滤器在离线数仓和分析数据库中的应用场景
| 系统 | 应用场景示例 |
|---|---|
| Hive | - 大规模数据去重,快速过滤已处理过的用户ID - 预过滤数据,减少Join数据量,提高查询性能 |
| Spark | - 大数据实时去重,避免重复计算 - 结合广播变量,做大表过滤小表的快速过滤器 |
| Hadoop | - MapReduce作业中,提前过滤无效数据,减少Shuffle和计算开销 |
| Doris | - 实时分析中快速判断某条记录是否已存在,避免重复写入 - 结合索引优化查询性能 |
| ClickHouse | - 近实时去重,尤其在流式数据入库前做过滤 - 结合物化视图做高效去重统计 |
三、具体应用说明
1. 离线数仓(Hive、Spark、Hadoop)
-
去重过滤
在大数据离线处理时,数据量巨大,传统的distinct操作性能差且资源消耗大。布隆过滤器可以先快速过滤掉大量重复数据,减少后续计算压力。 -
Join优化
通过布隆过滤器预先过滤掉不匹配的Key,减少Shuffle数据量,提高Join效率。 -
缓存穿透防护
在数据预处理阶段,过滤掉不在目标集合中的数据,避免无效计算。
2. 实时分析数据库(Doris、ClickHouse)
-
实时去重
流式数据入库时,用布隆过滤器判断是否已存在,避免重复写入,提高数据质量。 -
索引加速
结合布隆过滤器做索引预过滤,快速排除不匹配数据,提升查询响应速度。 -
物化视图和预聚合
在物化视图构建阶段,利用布隆过滤器快速判断是否需要更新,减少资源消耗。
四、总结
- 布隆过滤器是一种高效的概率型数据结构,适合大规模数据去重和快速判断元素存在性。
- 在离线数仓中,布隆过滤器能显著提升去重和Join性能,降低资源消耗。
- 在实时分析数据库中,布隆过滤器帮助实现高效的实时去重和查询加速。
- 需要注意的是,布隆过滤器存在一定误判率,适合容忍少量误差的场景。