Datawhale PyPOTS时间序列5月第3次笔记
下游任务的两阶段(two-stage) 处理
下载数据并预处理的程序:
# -------------------------------
# 导入必要的库
# -------------------------------
import numpy as np
import torch
from benchpots.datasets import preprocess_physionet2012
from pypots.imputation import SAITS
from pypots.optim import Adam
from pypots.nn.functional import calc_mse
from pypots.data.saving import pickle_dump# -------------------------------
# 设备配置
# -------------------------------
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"# -------------------------------
# 预处理PhysioNet2012数据
# -------------------------------
physionet2012_dataset = preprocess_physionet2012(subset="set-a", pattern="point", rate=0.1,
)
print(physionet2012_dataset.keys())# -------------------------------
# 构建缺失掩码、替换NaN
# -------------------------------
physionet2012_dataset["test_X_indicating_mask"] = (np.isnan(physionet2012_dataset["test_X"]) ^ np.isnan(physionet2012_dataset["test_X_ori"])
)
physionet2012_dataset["test_X_ori"] = np.nan_to_num(physionet2012_dataset["test_X_ori"])# -------------------------------
# 构建训练、验证、测试集
# -------------------------------
train_set = {"X": physionet2012_dataset["train_X"]}
val_set = {"X": physionet2012_dataset["val_X"],"X_ori": physionet2012_dataset["val_X_ori"],
}
test_set = {"X": physionet2012_dataset["test_X"],"X_ori": physionet2012_dataset["test_X_ori"],
}# -------------------------------
# 初始化SAITS模型
# -------------------------------
saits = SAITS(n_steps=physionet2012_dataset['n_steps'],n_features=physionet2012_dataset['n_features'],n_layers=3,d_model=64,n_heads=4,d_k=16,d_v=16,d_ffn=128,dropout=0.1,ORT_weight=1,MIT_weight=1,batch_size=32,epochs=10,patience=3,optimizer=Adam(lr=1e-3),num_workers=0,device=DEVICE,saving_path="result_saving/imputation/saits",model_saving_strategy="best",
)# -------------------------------
# 模型训练
# -------------------------------
saits.fit(train_set, val_set)# -------------------------------
# 测试集预测 & 评估
# -------------------------------
test_set_imputation_results = saits.predict(test_set)test_MSE = calc_mse(test_set_imputation_results["imputation"],physionet2012_dataset["test_X_ori"],physionet2012_dataset["test_X_indicating_mask"],
)
print(f"SAITS test_MSE: {test_MSE}")# -------------------------------
# 保存插补结果和标签
# -------------------------------
train_set_imputation = saits.impute(train_set)
val_set_imputation = saits.impute(val_set)
test_set_imputation = test_set_imputation_results["imputation"]dict_to_save = {'train_set_imputation': train_set_imputation,'train_set_labels': physionet2012_dataset['train_y'],'val_set_imputation': val_set_imputation,'val_set_labels': physionet2012_dataset['val_y'],'test_set_imputation': test_set_imputation,'test_set_labels': physionet2012_dataset['test_y'],
}pickle_dump(dict_to_save, "result_saving/imputed_physionet2012.pkl")
结果:
████████╗██╗███╗ ███╗███████╗ ███████╗███████╗██████╗ ██╗███████╗███████╗ █████╗ ██╗
╚══██╔══╝██║████╗ ████║██╔════╝ ██╔════╝██╔════╝██╔══██╗██║██╔════╝██╔════╝ ██╔══██╗██║
██║ ██║██╔████╔██║█████╗█████╗███████╗█████╗ ██████╔╝██║█████╗ ███████╗ ███████║██║
██║ ██║██║╚██╔╝██║██╔══╝╚════╝╚════██║██╔══╝ ██╔══██╗██║██╔══╝ ╚════██║ ██╔══██║██║
██║ ██║██║ ╚═╝ ██║███████╗ ███████║███████╗██║ ██║██║███████╗███████║██╗██║ ██║██║
╚═╝ ╚═╝╚═╝ ╚═╝╚══════╝ ╚══════╝╚══════╝╚═╝ ╚═╝╚═╝╚══════╝╚══════╝╚═╝╚═╝ ╚═╝╚═╝
ai4ts v0.0.3 - building AI for unified time-series analysis, https://time-series.ai2025-05-17 22:48:33 [INFO]: You're using dataset physionet_2012, please cite it properly in your work. You can find its reference information at the below link:
https://github.com/WenjieDu/TSDB/tree/main/dataset_profiles/physionet_2012
2025-05-17 22:48:33 [INFO]: Dataset physionet_2012 has already been downloaded. Processing directly...
2025-05-17 22:48:33 [INFO]: Dataset physionet_2012 has already been cached. Loading from cache directly...
2025-05-17 22:48:33 [INFO]: Loaded successfully!
2025-05-17 22:48:40 [WARNING]: Note that physionet_2012 has sparse observations in the time series, hence we don't add additional missing values to the training dataset.
2025-05-17 22:48:40 [INFO]: 23126 values masked out in the val set as ground truth, take 10.03% of the original observed values
2025-05-17 22:48:40 [INFO]: 28703 values masked out in the test set as ground truth, take 10.00% of the original observed values
2025-05-17 22:48:40 [INFO]: Total sample number: 3997
2025-05-17 22:48:40 [INFO]: Training set size: 2557 (63.97%)
2025-05-17 22:48:40 [INFO]: Validation set size: 640 (16.01%)
2025-05-17 22:48:40 [INFO]: Test set size: 800 (20.02%)
2025-05-17 22:48:40 [INFO]: Number of steps: 48
2025-05-17 22:48:40 [INFO]: Number of features: 37
2025-05-17 22:48:40 [INFO]: Train set missing rate: 79.70%
2025-05-17 22:48:40 [INFO]: Validating set missing rate: 81.74%
2025-05-17 22:48:40 [INFO]: Test set missing rate: 81.82%
dict_keys(['n_classes', 'n_steps', 'n_features', 'scaler', 'train_X', 'train_y', 'train_ICUType', 'val_X', 'val_y', 'val_ICUType', 'test_X', 'test_y', 'test_ICUType', 'val_X_ori', 'test_X_ori'])
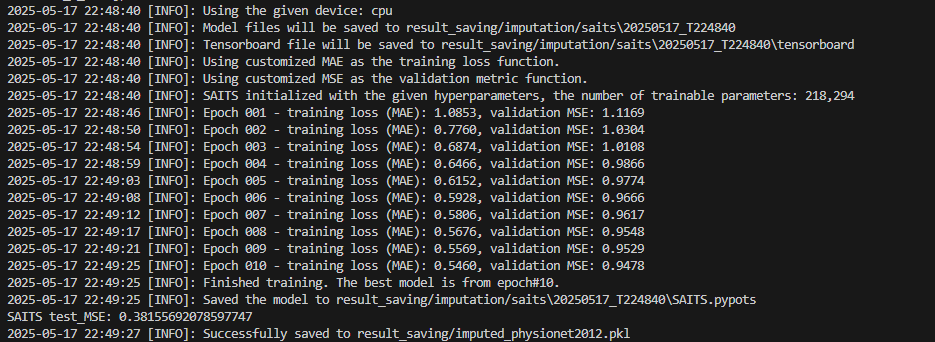
2025-05-17 22:48:40 [INFO]: Using the given device: cpu
2025-05-17 22:48:40 [INFO]: Model files will be saved to result_saving/imputation/saits\20250517_T224840
2025-05-17 22:48:40 [INFO]: Tensorboard file will be saved to result_saving/imputation/saits\20250517_T224840\tensorboard
2025-05-17 22:48:40 [INFO]: Using customized MAE as the training loss function.
2025-05-17 22:48:40 [INFO]: Using customized MSE as the validation metric function.
2025-05-17 22:48:40 [INFO]: SAITS initialized with the given hyperparameters, the number of trainable parameters: 218,294
2025-05-17 22:48:46 [INFO]: Epoch 001 - training loss (MAE): 1.0853, validation MSE: 1.1169
2025-05-17 22:48:50 [INFO]: Epoch 002 - training loss (MAE): 0.7760, validation MSE: 1.0304
2025-05-17 22:48:54 [INFO]: Epoch 003 - training loss (MAE): 0.6874, validation MSE: 1.0108
2025-05-17 22:48:59 [INFO]: Epoch 004 - training loss (MAE): 0.6466, validation MSE: 0.9866
2025-05-17 22:49:03 [INFO]: Epoch 005 - training loss (MAE): 0.6152, validation MSE: 0.9774
2025-05-17 22:49:08 [INFO]: Epoch 006 - training loss (MAE): 0.5928, validation MSE: 0.9666
2025-05-17 22:49:12 [INFO]: Epoch 007 - training loss (MAE): 0.5806, validation MSE: 0.9617
2025-05-17 22:49:17 [INFO]: Epoch 008 - training loss (MAE): 0.5676, validation MSE: 0.9548
2025-05-17 22:49:21 [INFO]: Epoch 009 - training loss (MAE): 0.5569, validation MSE: 0.9529
2025-05-17 22:49:25 [INFO]: Epoch 010 - training loss (MAE): 0.5460, validation MSE: 0.9478
2025-05-17 22:49:25 [INFO]: Finished training. The best model is from epoch#10.
2025-05-17 22:49:25 [INFO]: Saved the model to result_saving/imputation/saits\20250517_T224840\SAITS.pypots
SAITS test_MSE: 0.38155692078597747
2025-05-17 22:49:27 [INFO]: Successfully saved to result_saving/imputed_physionet2012.pkl
(pypots-env) PS D:\Projects\pypots-experiments>
两阶段处理的脚本程序:
# 导入必要库
import numpy as np
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from copy import deepcopy
from pypots.data.saving import pickle_load
from pypots.nn.functional.classification import calc_binary_classification_metrics# 设置设备
DEVICE = "cpu"# 数据集封装类
class LoadImputedDataAndLabel(Dataset):def __init__(self, imputed_data, labels):self.imputed_data = imputed_dataself.labels = labelsdef __len__(self):return len(self.labels)def __getitem__(self, idx):return (torch.from_numpy(self.imputed_data[idx]).to(torch.float32),torch.tensor(self.labels[idx]).to(torch.long),)# LSTM 分类器模型
class ClassificationLSTM(torch.nn.Module):def __init__(self, n_features, rnn_hidden_size, n_classes):super().__init__()self.rnn = torch.nn.LSTM(n_features,hidden_size=rnn_hidden_size,batch_first=True,)self.fcn = torch.nn.Linear(rnn_hidden_size, n_classes)def forward(self, data):hidden_states, _ = self.rnn(data)logits = self.fcn(hidden_states[:, -1, :])prediction_probabilities = torch.sigmoid(logits)return prediction_probabilities# 数据加载器生成函数
def get_dataloaders(train_X, train_y, val_X, val_y, test_X, test_y, batch_size=128):train_set = LoadImputedDataAndLabel(train_X, train_y)val_set = LoadImputedDataAndLabel(val_X, val_y)test_set = LoadImputedDataAndLabel(test_X, test_y)train_loader = DataLoader(train_set, batch_size, shuffle=True)val_loader = DataLoader(val_set, batch_size, shuffle=False)test_loader = DataLoader(test_set, batch_size, shuffle=False)return train_loader, val_loader, test_loader# 训练流程
def train(model, train_dataloader, val_dataloader, test_loader):n_epochs = 20patience = 5optimizer = torch.optim.Adam(model.parameters(), 1e-3)current_patience = patiencebest_loss = float("inf")for epoch in range(n_epochs):model.train()for idx, data in enumerate(train_dataloader):X, y = map(lambda x: x.to(DEVICE), data)optimizer.zero_grad()probabilities = model(X)loss = F.cross_entropy(probabilities, y.reshape(-1))loss.backward()optimizer.step()model.eval()loss_collector = []with torch.no_grad():for idx, data in enumerate(val_dataloader):X, y = map(lambda x: x.to(DEVICE), data)probabilities = model(X)loss = F.cross_entropy(probabilities, y.reshape(-1))loss_collector.append(loss.item())loss = np.asarray(loss_collector).mean()if best_loss > loss:current_patience = patiencebest_loss = lossbest_model = deepcopy(model.state_dict())else:current_patience -= 1if current_patience == 0:breakmodel.load_state_dict(best_model)model.eval()probability_collector = []for idx, data in enumerate(test_loader):X, y = map(lambda x: x.to(DEVICE), data)probabilities = model.forward(X)probability_collector += probabilities.cpu().tolist()probability_collector = np.asarray(probability_collector)return probability_collector# 加载插补后的数据
data = pickle_load('result_saving/imputed_physionet2012.pkl')
train_X, val_X, test_X = data['train_set_imputation'], data['val_set_imputation'], data['test_set_imputation']
train_y, val_y, test_y = data['train_set_labels'], data['val_set_labels'], data['test_set_labels']# 构建数据加载器
train_loader, val_loader, test_loader = get_dataloaders(train_X, train_y, val_X, val_y, test_X, test_y)# 初始化并训练分类器
rnn_classifier = ClassificationLSTM(n_features=37, rnn_hidden_size=128, n_classes=2)
proba_predictions = train(rnn_classifier, train_loader, val_loader, test_loader)# 输出测试集分类性能
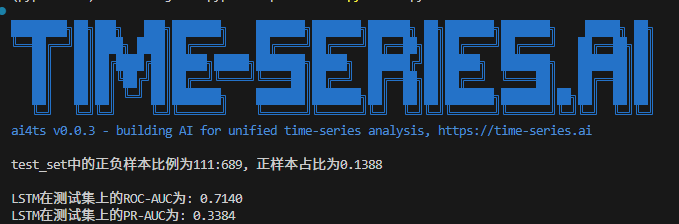
pos_num = test_y.sum()
neg_num = len(test_y) - pos_num
print(f'test_set中的正负样本比例为{pos_num}:{neg_num}, 正样本占比为{pos_num/len(test_y):.4f}\n')classification_metrics = calc_binary_classification_metrics(proba_predictions, test_y)
print(f"LSTM在测试集上的ROC-AUC为: {classification_metrics['roc_auc']:.4f}")
print(f"LSTM在测试集上的PR-AUC为: {classification_metrics['pr_auc']:.4f}")
结果如下: