论文解读:ICLR2025 | D-FINE
[2410.13842] D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
D-FINE 是一款功能强大的实时物体检测器,它将 DETRs 中的边界框回归任务重新定义为细粒度分布细化(FDR),并引入了全局最优定位自蒸馏(GO-LSD),在不引入额外推理和训练成本的情况下表现出了最佳性能。
📌文章针对目前存在的问题:
- YOLO系列和DETRs系列虽然在实时性和性能方面都取得了不错的效果,但是仍然有一些问题没有解决,一个最关键的就是边界框回归问题,没有考虑对于模糊和不确定的边界是如何进行回归建模的,关于边界框回归,大家可以去看往期的博客:目标检测中的损失函数(一) | IoU GIoU DIoU CIoU EIoU Focal-EIoU_yolo的损失函数-CSDN博客文章浏览阅读1.1k次,点赞7次,收藏20次。目标检测中的边界框回归损失函数_yolo的损失函数
https://blog.csdn.net/Jacknbv/article/details/147366898?spm=1001.2014.3001.5501目标检测中的损失函数(二) | BIoU RIoU α-IoU_bounded iou loss-CSDN博客文章浏览阅读793次,点赞30次,收藏12次。目标检测中的损失函数_bounded iou loss
- 另外一个问题就是老生常谈的问题:实时检测的效率问题,这会受到计算资源和模型参数的限制
✨论文的主要贡献:
- 提出了一种新的实时对象检测器D-FINE,解决了固定坐标回归中优化困难的问题、无法对定位不确定性进行建模的问题,以及需要以更低的训练成本实现有效提炼的问题,D-FINE最重要的就是下面这两个组件了
- Fine-grained Distribution Refinement (FDR) 将边界框回归从预测固定坐标转化为对概率分布的建模,提供了一种更精细的中间表示
- Global Optimal Localization Self-Distillation (GO-LSD),将定位知识从更深的层转移到较浅的层,额外的训练成本可以忽略不计
🔔在文章的相关工作这里,主要介绍了实时/端到端的目标检测、基于分布的目标检测知识蒸馏,其中localization distillation (LD)(定位蒸馏)是把用于分类head的knowledge distillation (KD)用于目标检测的定位head。自蒸馏是KD的一个特例,它使早期层次能够从模型自身的精炼输出中学习,由于不需要单独培训教师模型,因此需要的额外训练成本要少得多。
💡重点关注FDR和GO-LSD是怎么做的?
✨Fine-grained Distribution Refinement (FDR)
FDR迭代地优化由解码器层生成的细粒度分布。最初,第一个解码器层通过传统的边界盒回归头和D-FINE头(两个头都是MLP,只是输出维度不同)预测初步的边界盒和初步的概率分布。每个边界框与四个分布相关联,每个边对应一个分布。初始边界框用作参考框,而后续层则通过以残差方式调整分布来细化它们。然后应用改进的分布来调整相应的初始边界框的四个边,随着每次迭代逐步提高其精度。
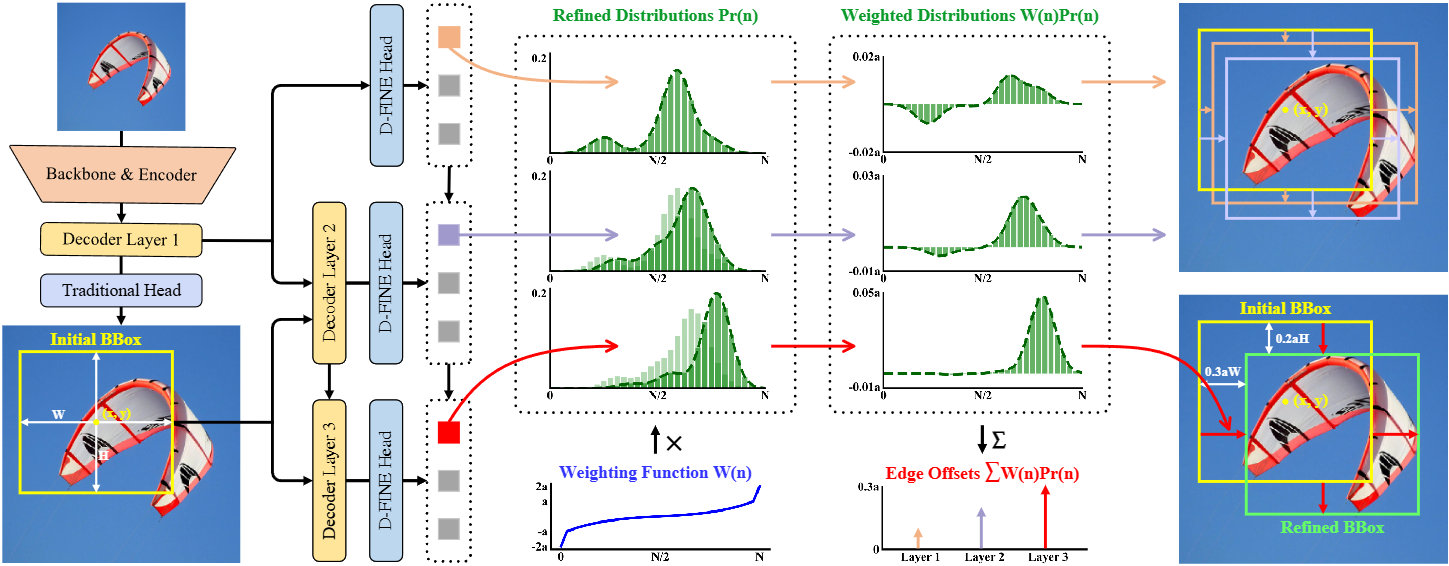

FDR 模块不是直接输出新的概率分布,而是输出一个残差,这个残差会与上一层的概率分布相加,从而得到当前层更新后的概率分布。这样做的好处是可以通过逐步调整残差的方式,对概率分布进行更精细的优化,使得模型能够逐层调整边界框,逐步收敛到更精确的位置。
权重函数W(n)的作用是让模型对接近真实位置的偏移值进行更小的调整,而对远离真实位置的边界偏移赋予更大的权重1。通过这种方式,模型可以更加关注那些需要更多调整的边界偏移,从而提高对物体边界的定位精度。分布的加权和产生边偏移,然后按初始边界框的高度H和宽度W缩放这些边偏移,以确保调整与框大小成比例。
总体而言,FDR 通过这种基于残差更新和加权的概率分布细化方式,将传统的边界框预测转变为一个迭代细化的概率分布过程,从而显著提升了模型的定位精度,增强了对物体边界细致定位的能力,并且能够更好地处理定位的不确定性。
✨Global Optimal Localization Self-Distillation (GO-LSD)
GO-LSD利用最后一层的精细分布预测将定位知识提取到较浅的层中。该过程首先将匈牙利匹配算法 (https://onlinelibrary.wiley.com/doi/abs/10.1002/nav.3800020109 End-to-End Object Detection with Transformers | SpringerLink) 应用于每个层的预测,确定模型每个阶段的局部边界框匹配。为了进行全局优化,GO-LSD将所有层的匹配索引聚合到一个统一的联合集。这个联合集结合了跨层的最精确的候选预测,确保它们都从蒸馏过程中受益。除了优化全局匹配,GO-LSD还在训练期间优化不匹配的预测,以提高整体稳定性,从而提高整体性能。虽然通过这个联合集优化了定位,但是分类任务仍然遵循一对一的匹配原则,确保没有冗余框。这种严格的匹配意味着联合集中的一些预测具有很好的局部性,但置信度较低。这些低置信度的预测通常代表具有精确定位的候选框,但仍然需要有效地提取。
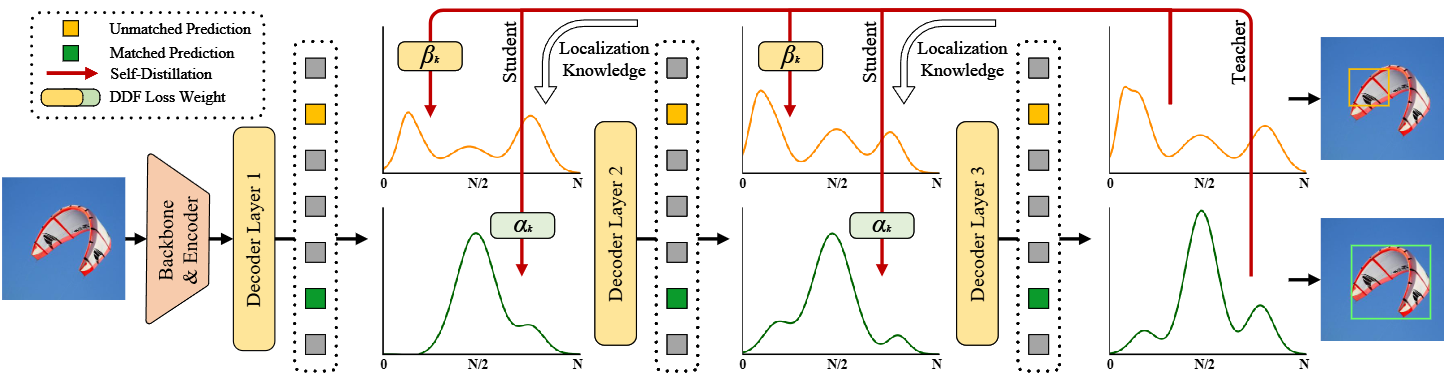
🥯针对上述这个问题,文章引入Decoupled Distillation Focal (DDF)损失去解决,这个损失是使用解耦加权策略来确保高IoU且低置信度的预测能被赋予适当的权重。DDF损失还根据匹配和不匹配预测的数量对它们进行加权,平衡它们的总体贡献和单个损失,使蒸馏更加稳定和有效。
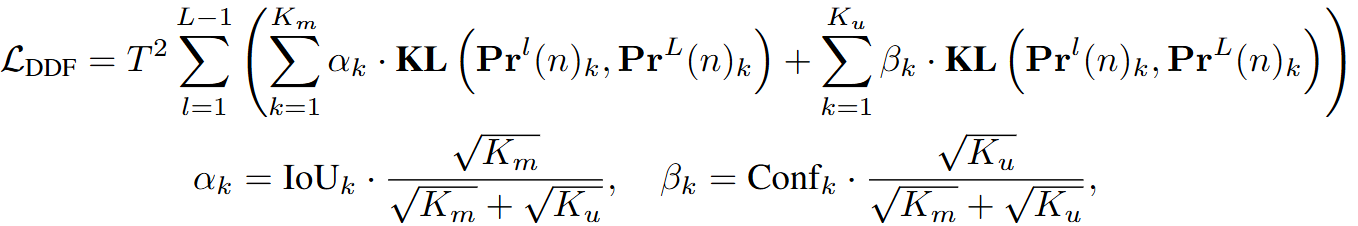
KL散度也叫相对熵,是衡量两个概率分布差异的指标,T是用于平滑logits的温度参数,第k个匹配预测的蒸馏损失通过进行加权,
和
分别是匹配和未匹配预测的数量,对于第k个不匹配的预测,权重是
,
表示的是分类的置信度。
整体上是一个累加求和的形式,主要通过计算不同层级特征(从第1层到第L−1层 )与最后一层(第L层 )特征之间的 KL散度,并结合相应权重来得到损失值。
🧶实验
D-FINE在COCO和Objects365数据集上表现出色,参考下面的表格
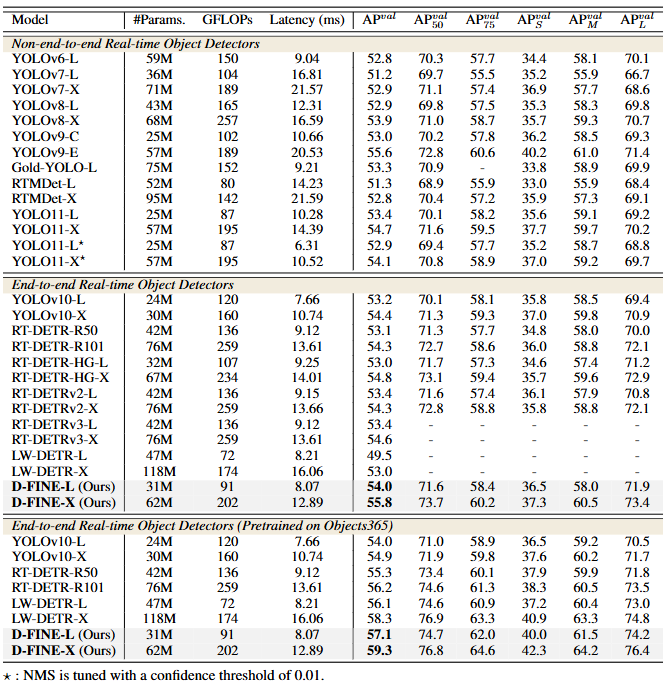
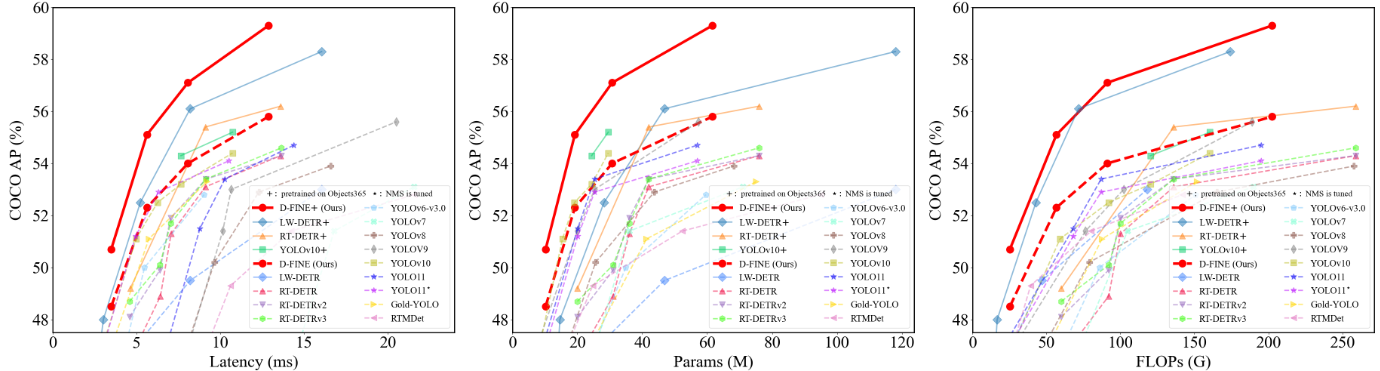
将FDR和GO-LSD无缝集成到任何DETR体系结构中,在不增加参数数量和计算负担的情况下显著提高性能在COCO数据集上进行了测试。
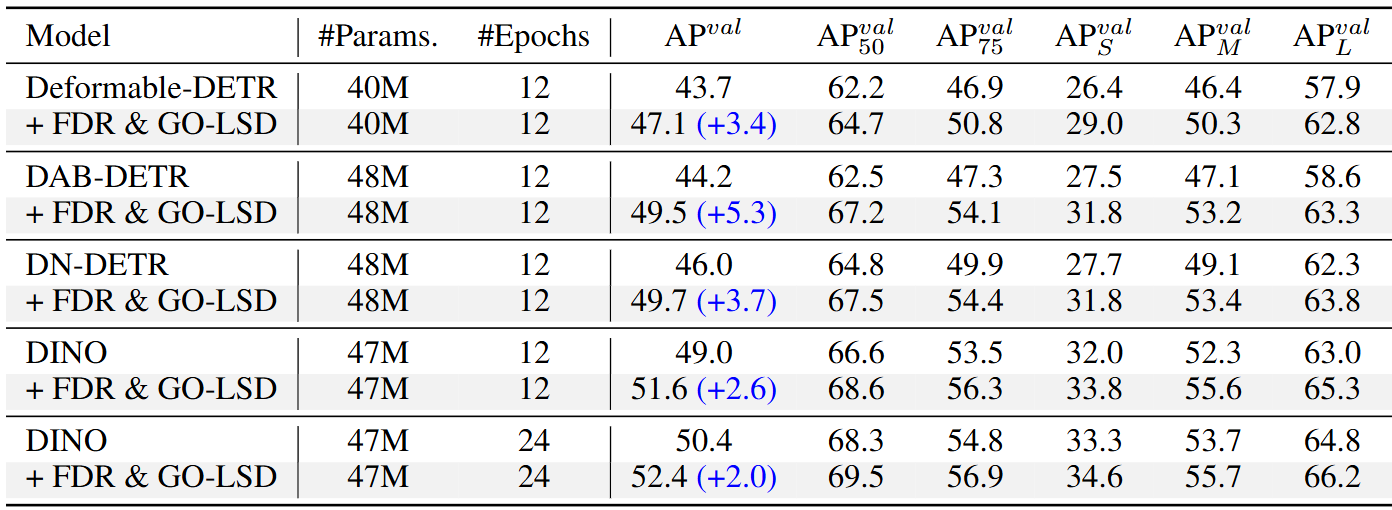
对于预训练,将Objects365 训练集的图像与验证集相结合,不包括前 5k 张图像。为了进一步提高训练效率,预先将所有分辨率超过640 × 640的图像调整为640 × 640。使用标准 COCO2017 数据拆分策略、COCO train2017 的训练和 COCO val2017 的评估。

🛒消融实验
D-FINE选择以RT-DETR-HGNetv2-L作为架构
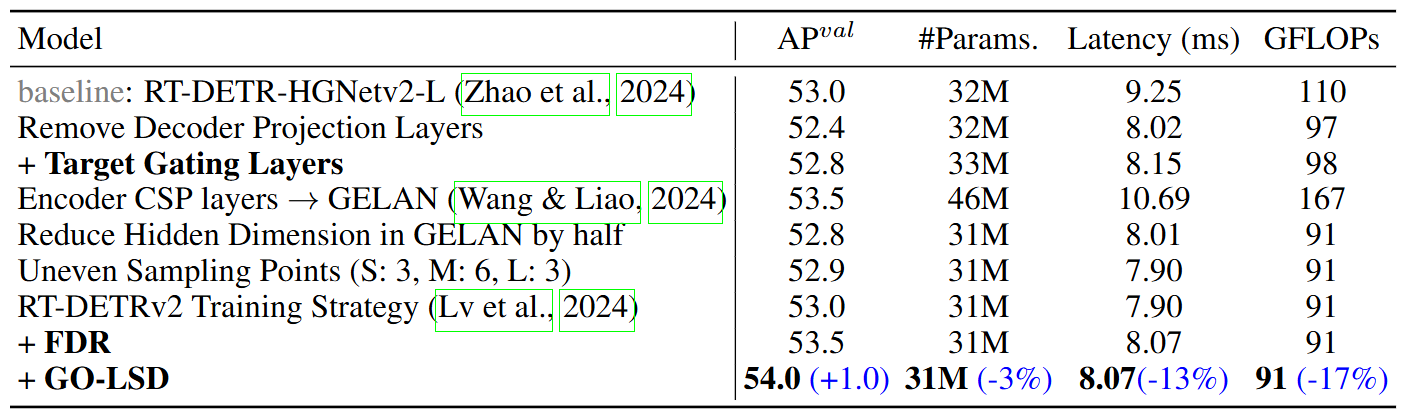 将Target Gating Layer放置在解码器的交叉注意力模块之后代替残差连接,允许查询跨层动态地将焦点切换到不同的目标上,从而有效地防止信息纠缠。
将Target Gating Layer放置在解码器的交叉注意力模块之后代替残差连接,允许查询跨层动态地将焦点切换到不同的目标上,从而有效地防止信息纠缠。
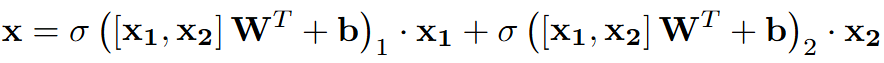
表示先前的queries,
表示交叉注意力的结果,
就是sigmoid激活函数,
是表示串行操作。
将编码器的CSP层使用GELAN层替换,为了缓解模型复杂度,降低了GELAN的隐藏层维数。RT-DETRv2的训练策略主要就是针对不同D-FINE模型的基础超参数的选择,参考下面的表格:

文章讨论了a、c、N和T超参数的取值影响,当c非常大时,加权函数以相等的间隔逼近线性函数,太大或太小的a值可能会降低精细度或限制灵活性,从而对定位精度产生不利影响。
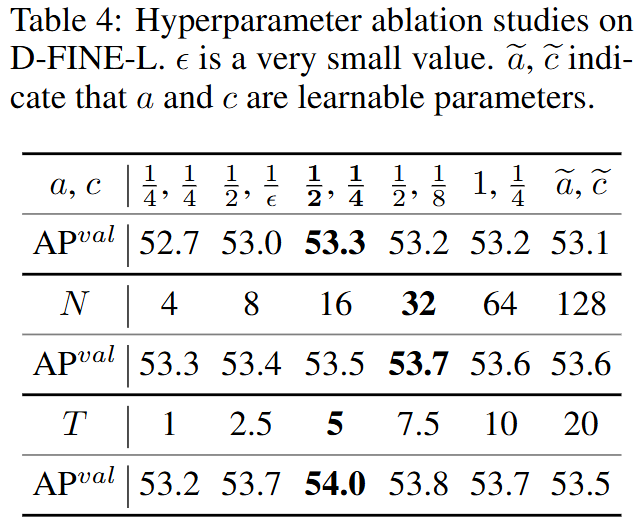
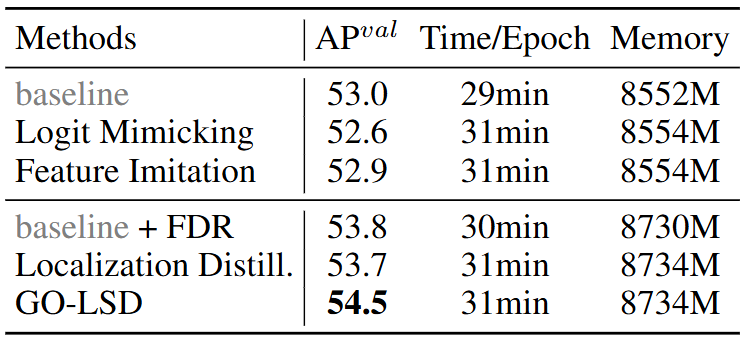
文章比较了不同的蒸馏方法的性能,GPU使用了四张NVIDIA RTX 4090。
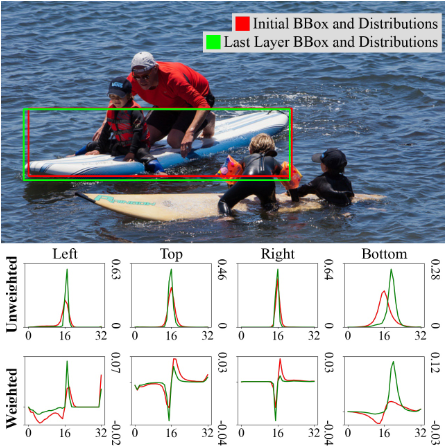
来看一下FDR的可视化效果,红色曲线表示初始分布,而绿色曲线表示最终的精细分布。加权分布强调精确预测附近的更精细调整,并允许对较大调整进行快速更改,进一步说明FDR如何细化初始边界框的偏移,从而导致越来越精确的定位。
- D-FINE是一种强大的实时对象检测器,它通过FDR和GO-LSD重新定义 DETR 模型中的边界框回归任务。COCO 数据集上的实验结果表明,D-FINE 达到了最先进的准确性和效率,超过了所有现有的实时检测器。
- D-FINE 模型和其他小模型的性能差距仍然很小,一个可能的原因是浅层解码器层可能会产生不太准确的最后一层预测,从而限制了将定位知识提取到早期层的有效性
- 未来的研究可以进一步探索更先进的架构设计或新颖的训练范例,以在保持轻量级推理的同时增强较轻模型的定位能力