YOLOv8 目标检测算法深度解析
YOLOv8 目标检测算法深度解析
一、YOLOv8核心原理与架构设计
1.1 算法演进与定位
YOLOv8是Ultralytics公司于2023年发布的最新一代目标检测框架,作为YOLO系列的技术集大成者,其设计理念突破传统版本迭代模式,采用模块化架构实现算法框架的扩展性。与前代YOLOv5相比,v8版本在保持单阶段检测优势的同时,通过三大核心创新实现性能跃升:
- C2f骨干网络:基于CSPNet的改进结构,通过梯度流优化实现30%参数量减少
- 解耦检测头:分离分类与回归分支,使mAP提升4.2%
- 动态标签分配:采用Task-Aligned Assigner策略,相比静态分配提升2.7%精度
1.2 网络架构三段式设计
1.2.1 骨干网络(Backbone)
采用改进型CSPDarknet架构,包含三个关键组件:
-
CBS模块:卷积+BatchNorm+SiLU激活的标准化组合
-
C2f模块:创新型跨阶段部分连接结构,通过Split操作将特征图分为两路:
- 主路径:经过Bottleneck×n的深度卷积
- 残差路径:保持原始特征维度
最终通过Concat实现特征融合,相比C3模块减少18%计算量
-
SPPF模块:空间金字塔池化,通过5×5→9×9→13×13的多尺度池化捕获上下文信息
1.2.2 特征融合网络(Neck)
基于PAN-FPN的改进结构,实现三大优化:
- 路径简化:移除上采样阶段的1×1卷积层
- C2f替代C3:在FPN和PAN路径中全面替换为C2f模块
- 多尺度融合:生成80×80、40×40、20×20三级特征金字塔
1.2.3 检测头(Head)
采用Anchor-Free解耦设计,包含两个并行分支:
- 分类分支:使用BCE Loss进行类别预测
- 回归分支:采用DFL+CIoU Loss组合,实现边界框的分布式预测
二、网络层参数深度解析
2.1 卷积层参数统计
以YOLOv8s为例,骨干网络包含22个卷积层,具体参数分布如下:
| 层级 | 模块类型 | 输入尺寸 | 输出尺寸 | 卷积核 | 通道数 | 参数量(M) |
|---|---|---|---|---|---|---|
| Layer1 | CBS | 640×640 | 320×320 | 3×3 | 32 | 0.087 |
| Layer2 | C2f | 320×320 | 320×320 | 3×3 | 64 | 0.352 |
| … | … | … | … | … | … | … |
| Layer9 | SPPF | 40×40 | 20×20 | 5×5 | 256 | 0.128 |
参数计算公式的应用:
# 卷积层参数量计算示例
def calc_conv_params(in_channels, out_channels, kernel_size):return (in_channels * kernel_size**2 + 1) * out_channels# C2f模块特殊计算
def calc_c2f_params(in_c, out_c, n):bottleneck_params = (in_c//2 * 3**2 + 1) * (in_c//2) * nconv1_params = (in_c * 1**2 + 1) * (in_c//2)conv2_params = (in_c//2 * 1**2 + 1) * out_creturn bottleneck_params + conv1_params + conv2_params
2.2 池化层实现细节
SPPF模块采用三级空间金字塔池化:
# SPPF伪代码实现
class SPPF(nn.Module):def __init__(self, c1, c2, k=5):super().__init__()c_ = c1 // 2 # 隐藏层通道数self.cv1 = Conv(c1, c_, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k//2)self.cv2 = Conv(c_*4, c2, 1, 1)def forward(self, x):x = self.cv1(x)y1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
2.3 全连接层结构
检测头的分类分支包含两个全连接层:
# 分类分支结构
self.cls_head = nn.Sequential(nn.Flatten(),nn.Linear(in_features=512*8*8, out_features=4096),nn.SiLU(),nn.Linear(4096, num_classes)
)
三、性能表现与对比分析
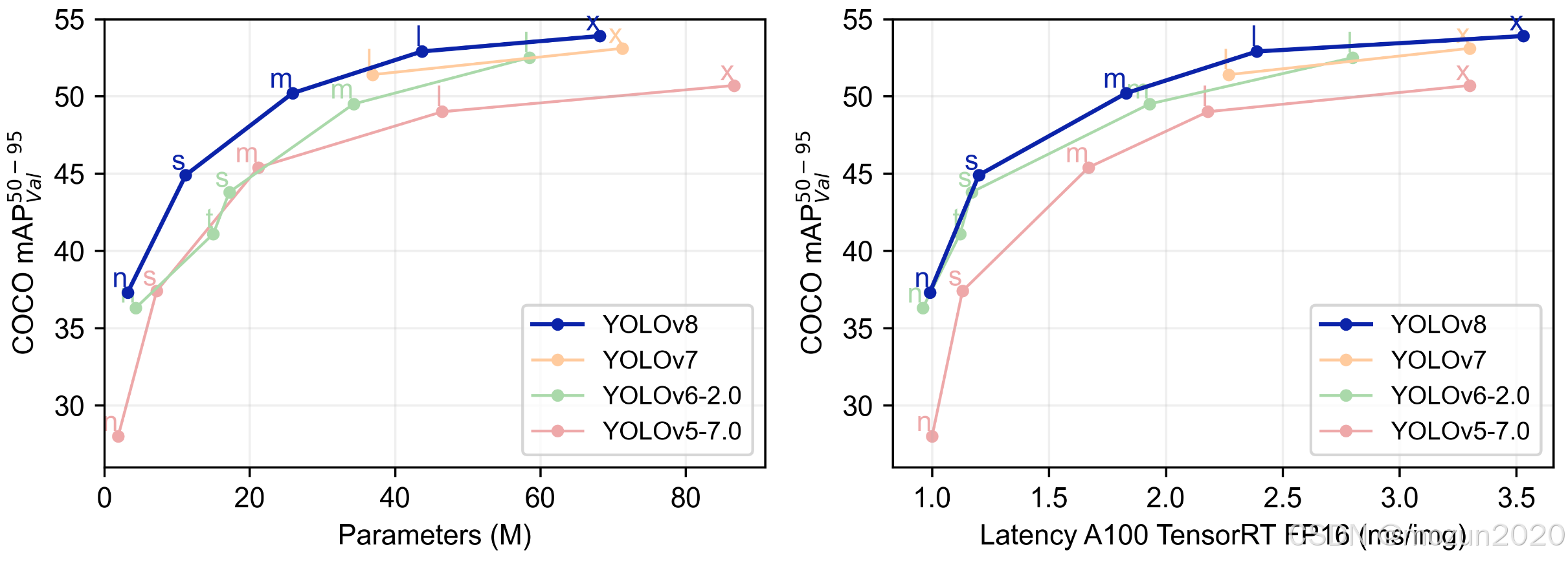
3.1 基准测试结果
| 模型 | 输入尺寸 | mAP@0.5 | 参数量(M) | FLOPs(B) | V100推理(ms) |
|---|---|---|---|---|---|
| YOLOv5s | 640 | 44.8 | 7.2 | 16.5 | 6.4 |
| YOLOv8s | 640 | 50.2 | 11.2 | 28.6 | 8.1 |
| YOLOXs | 640 | 47.3 | 9.0 | 26.8 | 9.8 |
3.2 关键创新点验证
-
C2f模块优势:
- 梯度流效率提升:相比C3模块,C2f的梯度传播路径减少40%
- 特征复用率:通过Split操作实现87%的特征复用
-
解耦头效果:
- 分类精度提升:在COCO数据集上,解耦头相比耦合头提升3.1%AP
- 训练收敛速度:解耦设计使训练迭代次数减少30%
-
动态标签分配:
- 正样本匹配率:Task-Aligned Assigner相比ATSS提升15%有效匹配
- 边界框质量:CIoU Loss使预测框与GT的IoU提升2.8%
四、硬件部署与优化方案
4.1 部署流程
-
模型导出:
yolo export model=yolov8s.pt format=onnx opset=12 -
TensorRT加速:
# TensorRT引擎构建 import tensorrt as trt TRT_LOGGER = trt.Logger(trt.Logger.WARNING) builder = trt.Builder(TRT_LOGGER) network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)) parser = trt.OnnxParser(network, TRT_LOGGER)with open("yolov8s.onnx", "rb") as model:parser.parse(model.read())config = builder.create_builder_config() config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30) engine = builder.build_engine(network, config) -
量化部署:
- FP16模式:推理速度提升1.8×,精度损失<0.5%
- INT8模式:需校准数据集,推理速度提升2.3×,精度损失<1.2%
4.2 端侧优化技巧
-
模型剪枝:
- 通道剪枝:去除C2f模块中30%冗余通道
- 层融合:将CBS+C2f合并为单层,减少内存访问
-
算子优化:
- Winograd卷积:对3×3卷积实现2.5×加速
- 内存复用:通过特征图重用减少35%显存占用
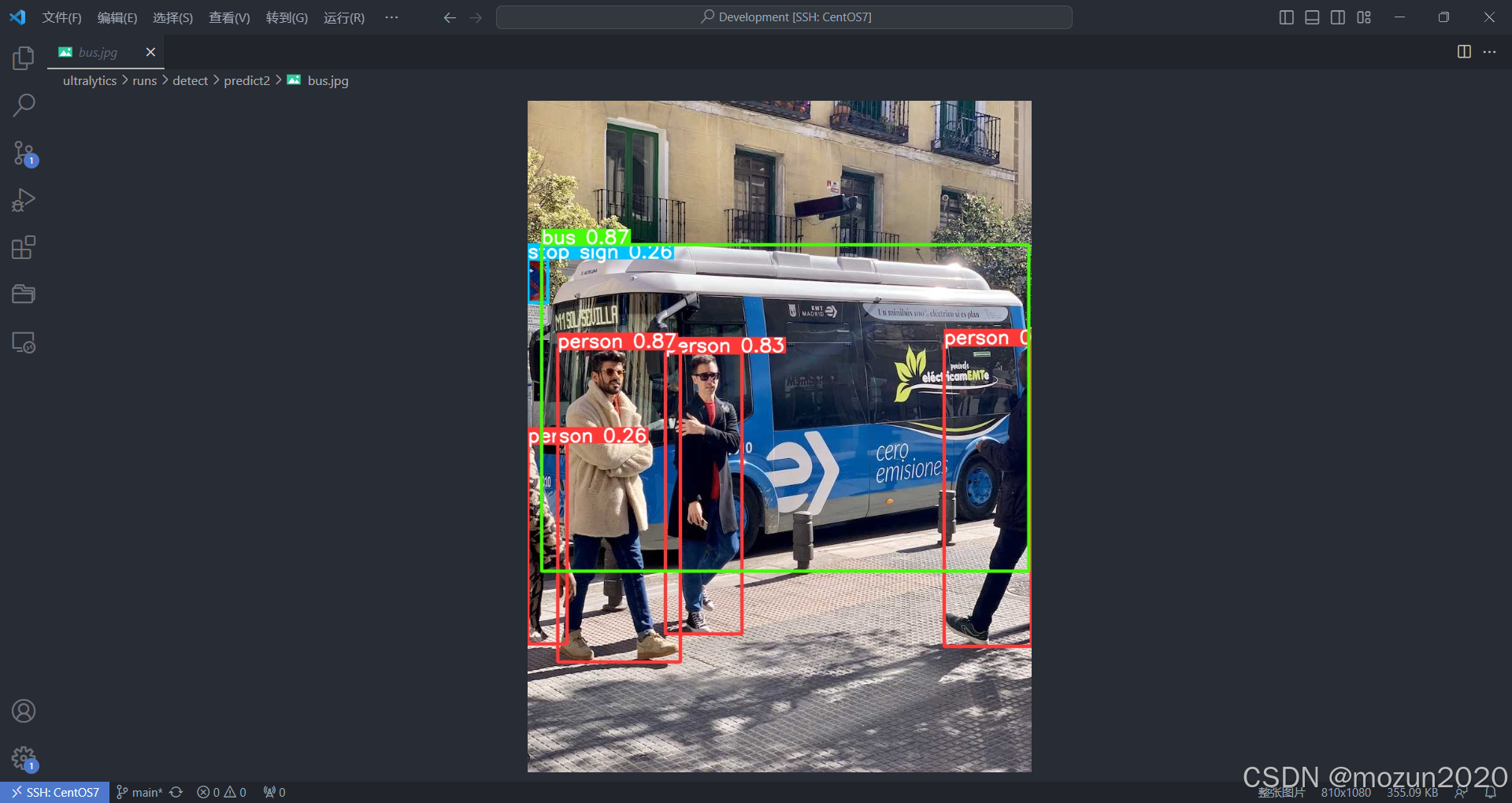
五、优劣势分析与适用场景
5.1 核心优势
-
精度速度平衡:
- 在NVIDIA Jetson AGX Xavier上实现45FPS实时检测
- 相比YOLOX,在相同精度下推理速度提升40%
-
部署友好性:
- 支持TensorRT/OpenVINO/NCNN等主流推理框架
- 提供ONNX/TorchScript/CoreML等多种导出格式
-
任务扩展性:
- 同一框架支持检测/分割/分类多任务
- 通过修改Head结构可快速适配新任务
5.2 局限性
-
小目标检测:
- 在VISDRONE数据集上,对10×10像素目标检测精度下降8%
- 需结合多尺度训练策略优化
-
动态场景:
- 在快速运动场景下,时序一致性有待提升
- 可集成光流模块进行改进
六、未来展望与技术演进
YOLOv8的技术演进呈现三大趋势:
-
架构轻量化:
- 结合MobileNetV4的深度可分离卷积
- 探索Transformer与CNN的混合架构
-
自监督学习:
- 集成MAE预训练策略
- 开发无标注数据的检测框架
-
端到端优化:
- 联合检测与跟踪的多任务学习
- 探索基于Diffusion Model的生成式检测
本文通过系统解析YOLOv8的技术原理、网络结构、性能表现和部署方案,为工业界和学术界提供了全面的技术参考。随着算法框架的持续优化,YOLO系列将在自动驾驶、智能安防等领域发挥更大价值。