Mysql 索引概述
索引(index)是帮助Mysql高效获取数据的数据结构
索引优点:1. 提高排序效率 2. 提高查询效率
索引缺点:1.索引占用空间(可忽略)2.索引降低了更新表的速度,如进行insert,update,delette 时效率降低(也可忽略,因为实际很少用,大部分还是select)
我们平常所说的索引,如果没有特别指明,都是B+树结构组织的索引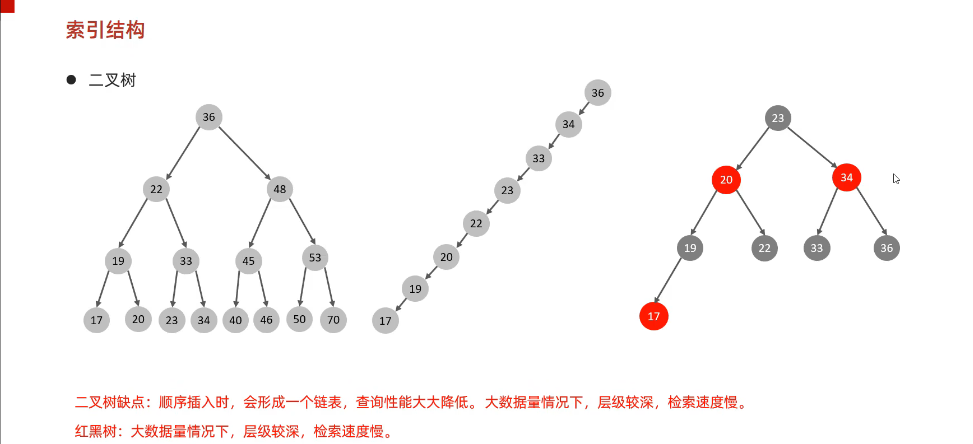
B+树
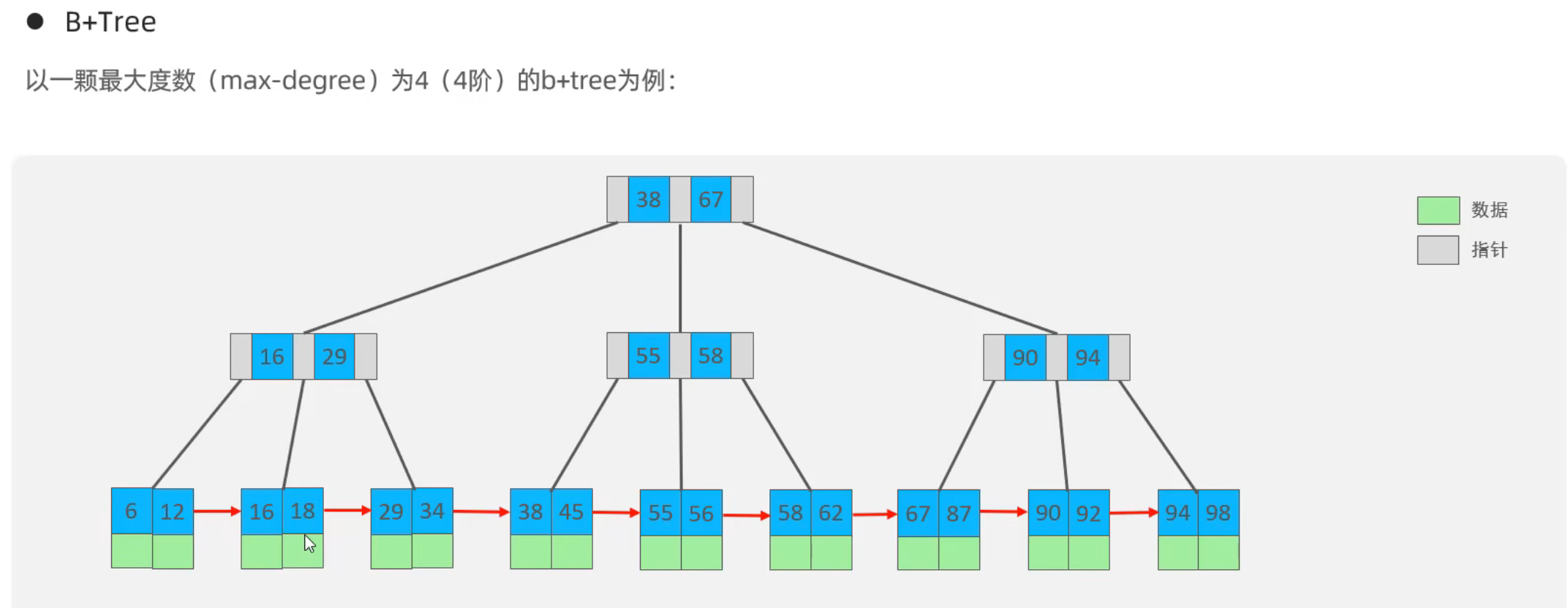
1.所有的数据都会出现在叶子结点
2.叶子结点形成一个单向链表
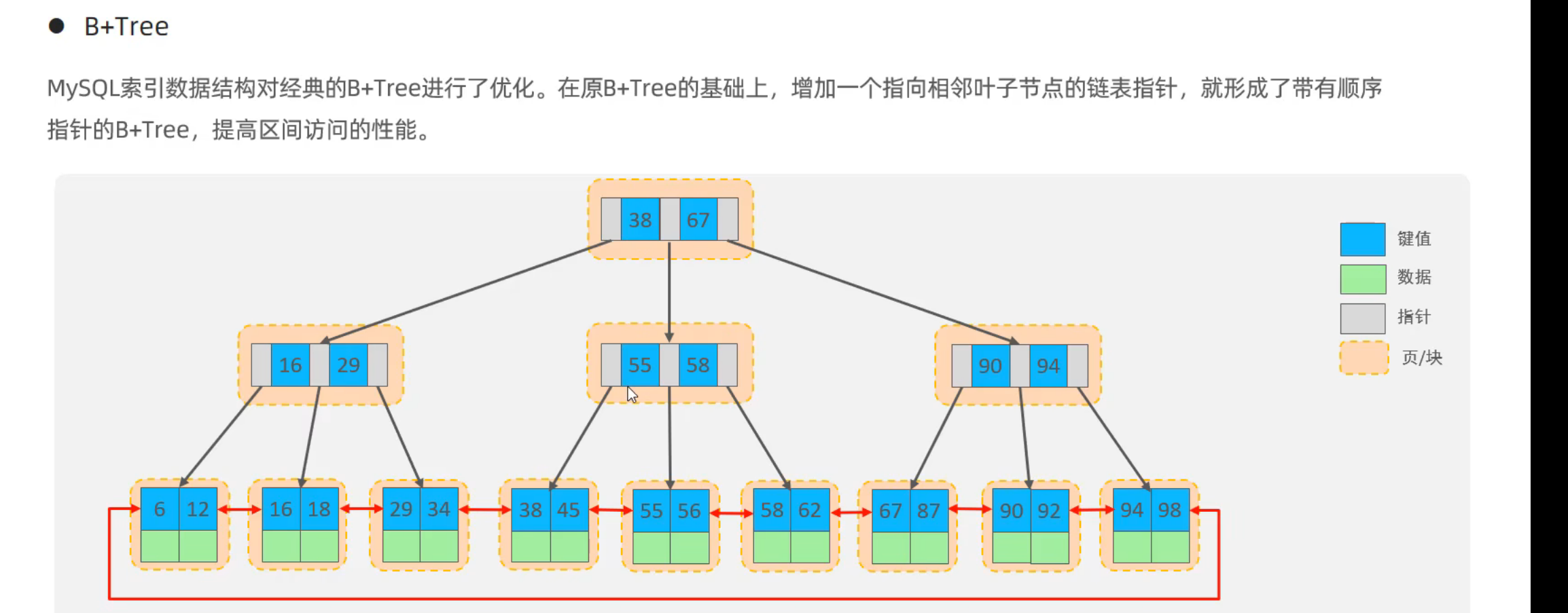
键值是不存储数据的,数据存储在叶子结点上
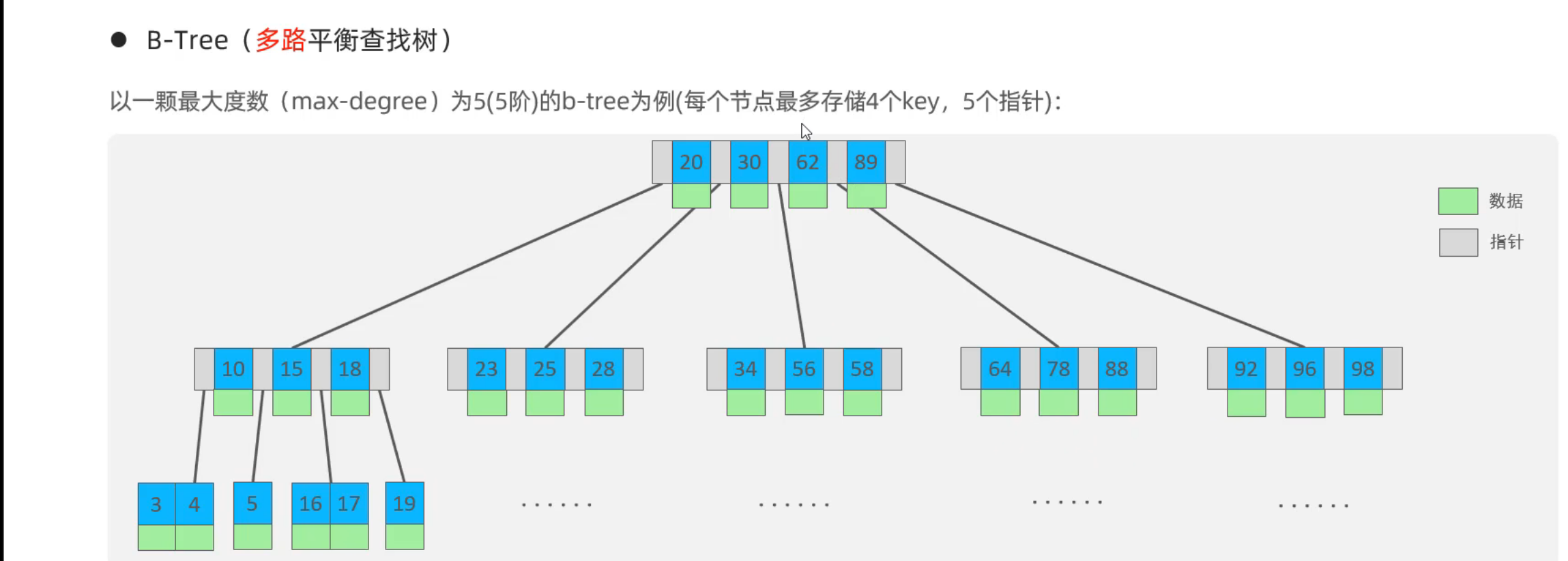
非叶子节点:仅存储索引值(键) ,不存储实际数据。
叶子节点:存储索引值和实际数据 。
查找过程
- 定位叶子节点:从根节点开始,根据待查找的键值与非叶子节点中键值的比较结果,选择对应的子节点指针向下层查找 ,不断重复这个过程,直到找到叶子节点 。
- 在叶子节点查找:在叶子节点中,由于叶子节点存储了数据或指向数据的指针,所以可以在叶子节点中找到目标数据 。如果是范围查询,比如查找某个区间内的用户记录,找到区间起始值对应的叶子节点后,通过叶子节点间的双向链表顺序遍历,就能获取该区间内的所有数据 。
哈希索引
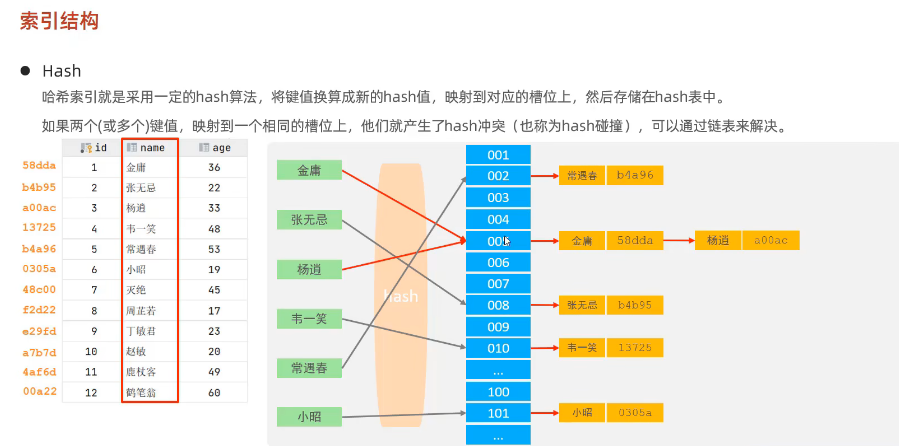
优点
- 等值查询速度极快:在理想状况下(不发生哈希冲突),哈希索引的查找时间复杂度为 O (1) ,能在常数时间内直接定位目标记录。比如在用户表中,查找用户 ID 为特定值的记录时,使用哈希索引可迅速找到对应数据,比一些树形索引结构(如 B - 树、B + 树 )更高效 。这是因为哈希索引通过哈希函数直接计算出存储位置,无需像树结构那样逐层查找 。
- 适合精确匹配场景:特别适用于精确匹配查询,像查找特定订单号、某个具体的商品编号等场景 。只要给出准确的键值,就能快速定位到对应的数据行 。
- 实现相对简单:相比一些复杂的树形索引结构(如 B + 树 ),哈希索引的原理和实现方式较为简单 。其主要依赖哈希函数和哈希表来组织和查找数据 。
- 缓存场景应用佳:由于查找速度快,在高频率的缓存场景中表现出色 。例如在缓存系统中,使用哈希索引能快速判断缓存中是否存在目标数据,提升缓存的读写率 。
缺点
- 不支持范围查询:哈希算法无法维护数据的排序关系,所以哈希索引仅适用于等值查询,不支持范围查询(如 <、>、BETWEEN 等操作 ) 。
- 存在哈希冲突问题:哈希函数可能将多个不同的键值映射到相同的位置,即产生哈希冲突 。解决哈希冲突通常采用链表法(将冲突的键值存储在链表中 )、开放地址法等 。但即便如此,哈希冲突仍可能导致性能下降,比如使用链表法解决冲突时,若链表过长,查询效率会受到影响 。
- 无法支持排序操作:因为哈希索引没有维护元素的顺序,所以无法直接支持 ORDER BY 或 GROUP BY 操作 。如果需要对数据进行排序或分组,必须在查询后对结果集进行额外处理 。
- 内存开销较大:通常需要较大的内存来存储哈希表,尤其是数据量较大时,内存占用会更加显著 。这限制了它在一些内存资源有限环境中的应用 。
- 存储引擎支持有限:在 MySQL 中,只有 MEMORY 存储引擎直接支持哈希索引 ,InnoDB 和 MyISAM 等常用存储引擎不直接支持 。虽然 InnoDB 提供了自适应哈希索引(在某些条件下自动创建 ),但并非完全等同于手动创建的哈希索引 。
为什么InnoDB引擎选择使用B+tree索引结构?
1.相对于二叉树来说层级更少,搜索效率高
2.B-tree 不管是叶子结点还是非叶子结点,都会存储数据,这样导致一页中存储的键值减少,指针跟着减少,在相同数据量的情况下占用了更多的空间。
3.相对于Hash索引,B+tree支持范围匹配及排序操作
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | 无 |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在 InnoDB 存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 (Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引 (Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则 InnoDB 会自动生成一个 rowid 作为隐藏的聚集索引。
看这条语句的查询过程 select * from user where name='Arm';
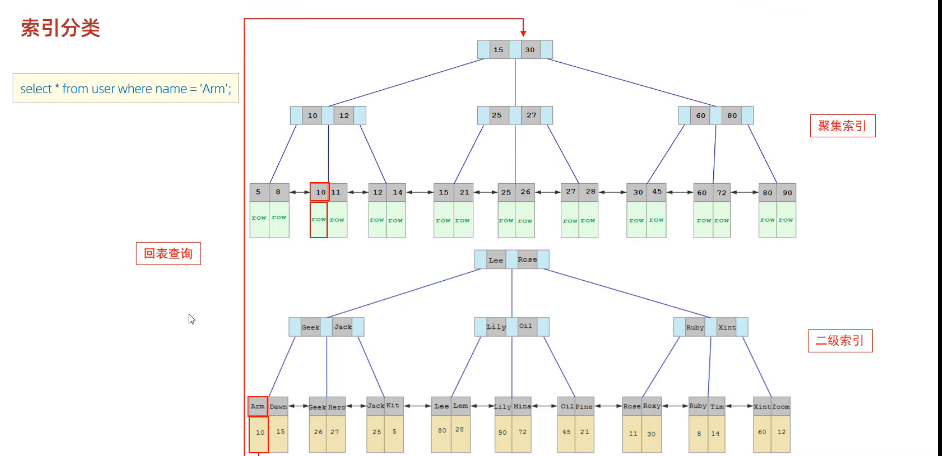 先在二级索引里 Arm与Lee与比 ,A在L之前,去前面找,找到Arm之后获得存储的数据10,然后10再去聚集索引中来比较,找到10这个索引所储存的数据
先在二级索引里 Arm与Lee与比 ,A在L之前,去前面找,找到Arm之后获得存储的数据10,然后10再去聚集索引中来比较,找到10这个索引所储存的数据
每一个节点最终落在磁盘上就会存放在一个页当中,一个页的大小是固定的16k,那么一个页存储的数据就是有限的
非叶子结点能存放多少key和指针,非叶子结点不存放数据,只存放key和指针,并且指针永远比key多一个
一行数据大小为 1k,一页中可以存储 16 行这样的数据。InnoDB 的指针占用 6 个字节的空间,主键即使为 bigint,占用字节数为 8,n代表当前结点存储的key的数量。
n*8+(n+1)*6=16*1024 解得:n=1170
所以一个结点能存储1170个key,有1171个指针,每一个指针指向下面的一个子结点,一个子结点能存储16行数据,如果树的高度为2,那么能存储的数据量就是1171*16=18736
如果树的高度为3 ,则能存储的数据量就是1171*1171*16=21,939,856