哈希表(2):
我们上节说到我们该讲下一个处理哈希冲突的方法:
链地址法:
链地址法的话,就不存在说是咱们的这个数据被别人占了,然后咱们再占别的数据的位置这个说法,因为我们的链地址法的话,他是不把数据存在哈希表里面的。
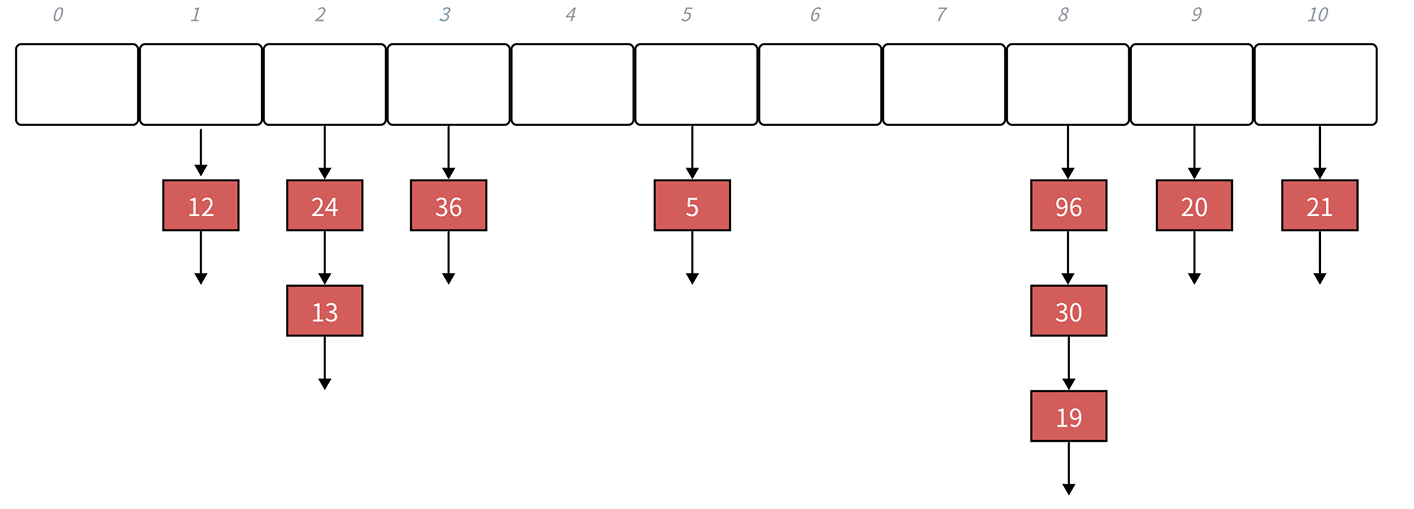
链地址法的话,他是把数据映射到这个位置以后使用链式结构把他给挂起来。
这个的话我们也叫做哈希桶。
然后我们的链地址法的话,他的负载因子是可以大于1的,之前我们的开放定址法的话,这个负载因子不能大于1,大于1的话,数据就溢出了,但是我们的链地址法的负载因子是可以大于1的,这个桶下面是可以挂很多个的。

但是虽然说链地址法的话,对他的负载因子限制比较小,可以大于1,但是负载因子越大的话,他的数据就会变多,哈希冲突的概率就会变大。
特殊:
如果有说是哈希表的某一个桶很长的话,

我们就不挂桶了,我们就改为挂红黑树。(我们把链表转换为红黑树)。
这个了解一下就行;
链地址法代码的实现:
之前我们使用开放定址法实现的,我们现在使用链地址法来实现,这两种方法都可以,我们就使用namespace把之前的方法封装起来。
//这两种都是库里面有的,我们是自己实现一下。
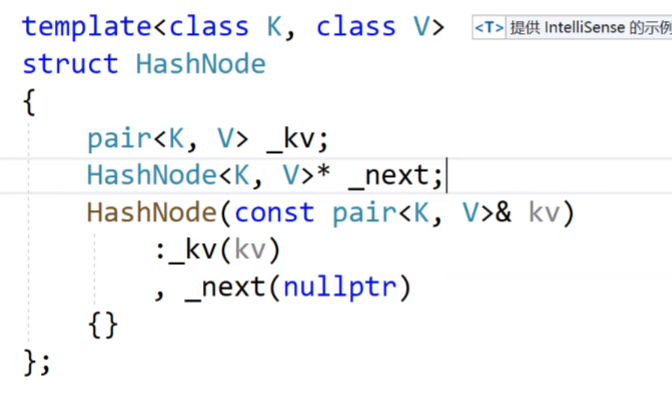
这个是我们封装的哈希表的结点的类,里面包含一个pair键值对数据和一个next指针。
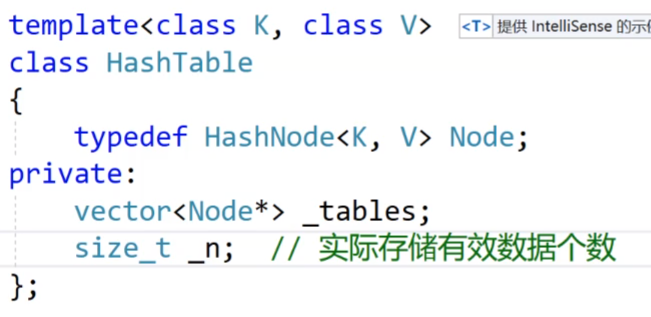
这个是哈希表的简单的框架。
insert():
首先我们看这个插入函数,
我们先找到取模后的位置在哪,我们进行插入,
这里是实现的话,我们没有使用泛型的编程,我们使用了unordered_map的方式,我们里面存储的数据类型是pair键值对类型。
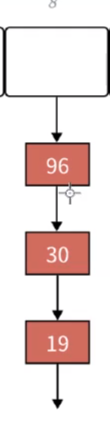 那我们插入数据到一个哈希桶里面的时候,我们是头插还是尾插呢?
那我们插入数据到一个哈希桶里面的时候,我们是头插还是尾插呢?
我们在这里实现头插:
插入结点的话,那就要分情况了,哈希表可能为空,也可能不为空;
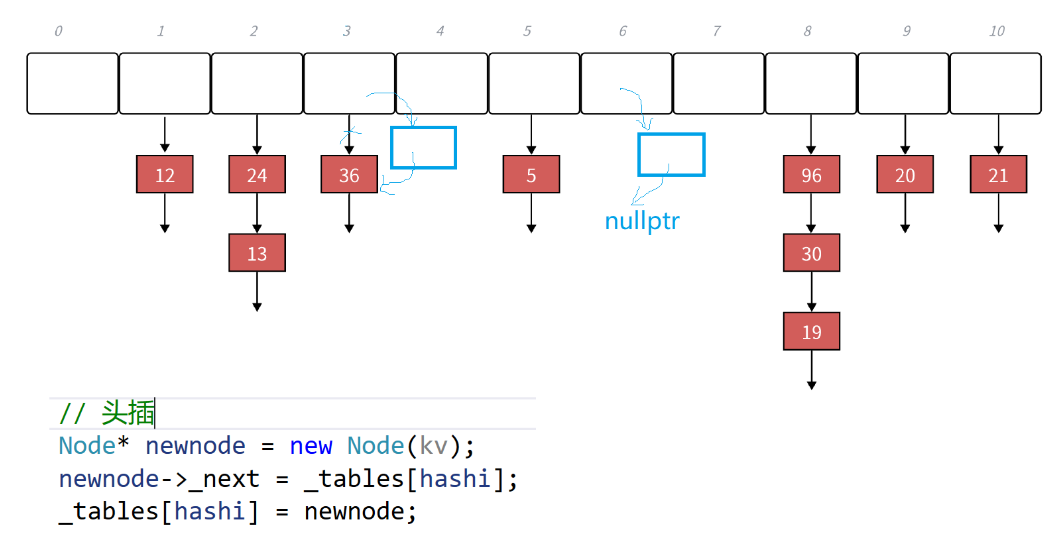
我们看上面的图片,当我们要插入一个结点到3这个哈希桶的时候,我们要进行头插,(有一个点就是,我们的每个哈希桶的最开始的位置的结点的地址存放到了这个哈希桶的最上面,也就是存到了我们的哈希表中)。所以_tables[hashi]这个就是哈希桶第一个结点的地址。
哈希桶没有结点的话也是一样的,,我们看当我们插入结点到6这个哈希桶的时候,因为这个哈希桶没有节点,所以_tables[hashi]这个里面就是空的,没有指针,我们指向它就是指向nullptr,然后让他作为我们的_tables[hashi]。
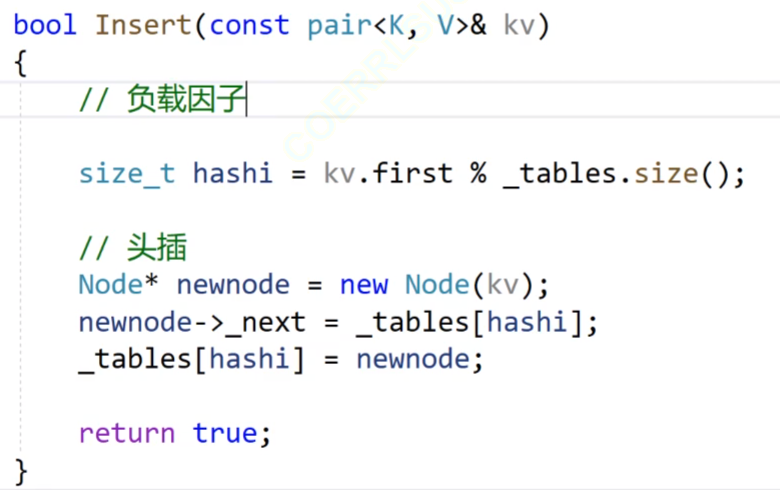
这个就是我们的普通的insert函数的实现。
当然我们的insert也不能是无限的进行插入,我们也要进行扩容,我们扩容的条件我们就设置为当我们的负载因子为1的时候,我们就进行扩容。
我们的扩容有两种方法:
扩容:
第一种:
那我们的扩容要怎么扩呢?

![]()
我们先看上面的这种扩容的方法,我们开一个新的哈希表,使用素数表的方法,我们遍历一下旧表,遍历旧的哈希表,如果哈希表里面有数据的话,那么这个位置下面就一定挂着哈希桶,如果有的话,我们就把他insert到我们的新的哈希表里面,代码的最后,我们插入结束以后,我们交换哈希表的_tables,_tables是一个vector,交换哈希表的vector数据。我们的旧的哈希表拿到新的vector数据,新的哈希表拿到旧的哈希表的vector。。。
那出了作用域以后,新的哈希表就要被销毁,它里面的vector里面存的结点都是动态开辟的,我们需要销毁。。。补上一个析构函数; 哈希表实例化的对象newht是在这个函数创建的,出了作用域就会自动的调用析构函数来销毁。
析构函数补充:

析构函数会遍历哈希表的vector销毁里面的哈希桶存储的结点。
但是我们直接说结论,那就是这个方法是很不好的,
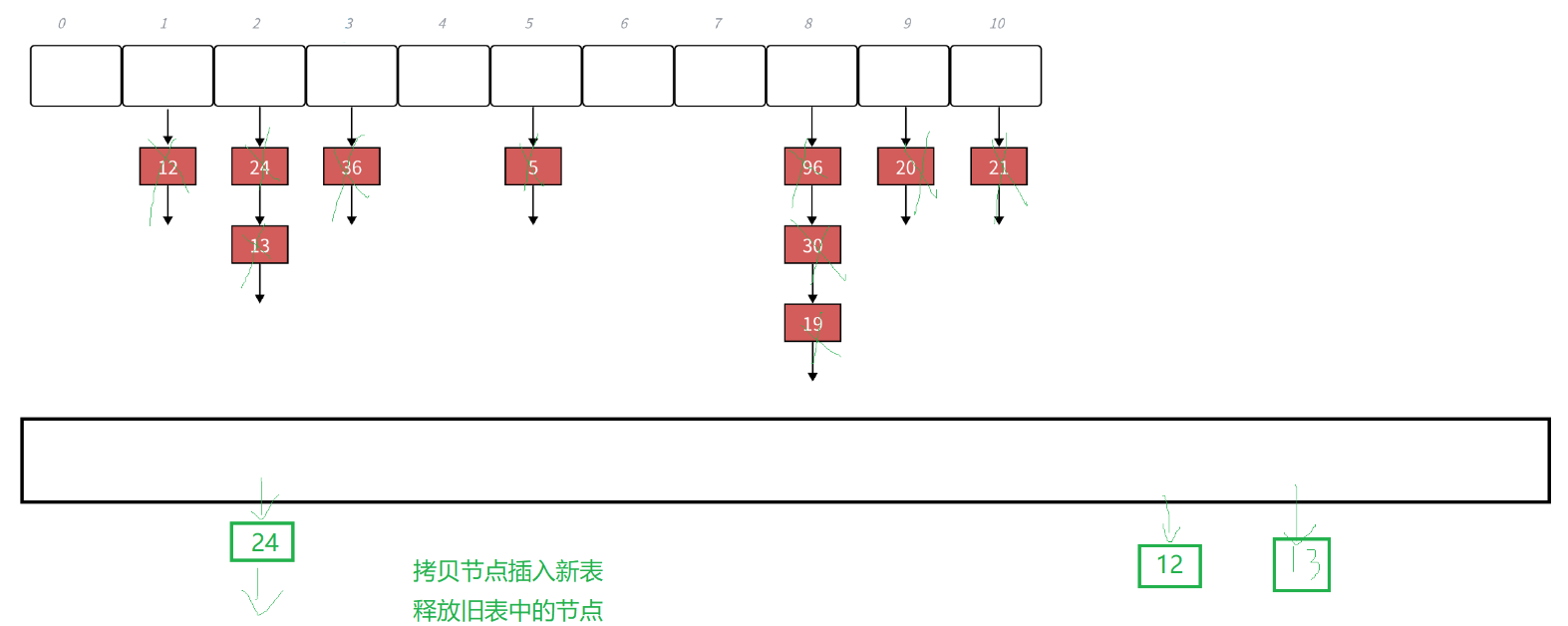
我们看这个图片:我们上面的方法是创建新的哈希表(你要清楚我们的哈希表里面包含了我们的vector和n,它不只是一个vector),我们把旧的哈希表的vector的里面的结点拷贝一份到新的哈希表的vector里面去,然后拷贝完后,交换哈希表的vector,然后销毁旧表的vector。
这样是不是消耗比较大呀,我们把结点拷贝一份,然后销毁原版,。我们能不能直接把旧表的结点移动到新表里面去。
我们下面的就是直接把结点移动到vector里面去;
第二种:
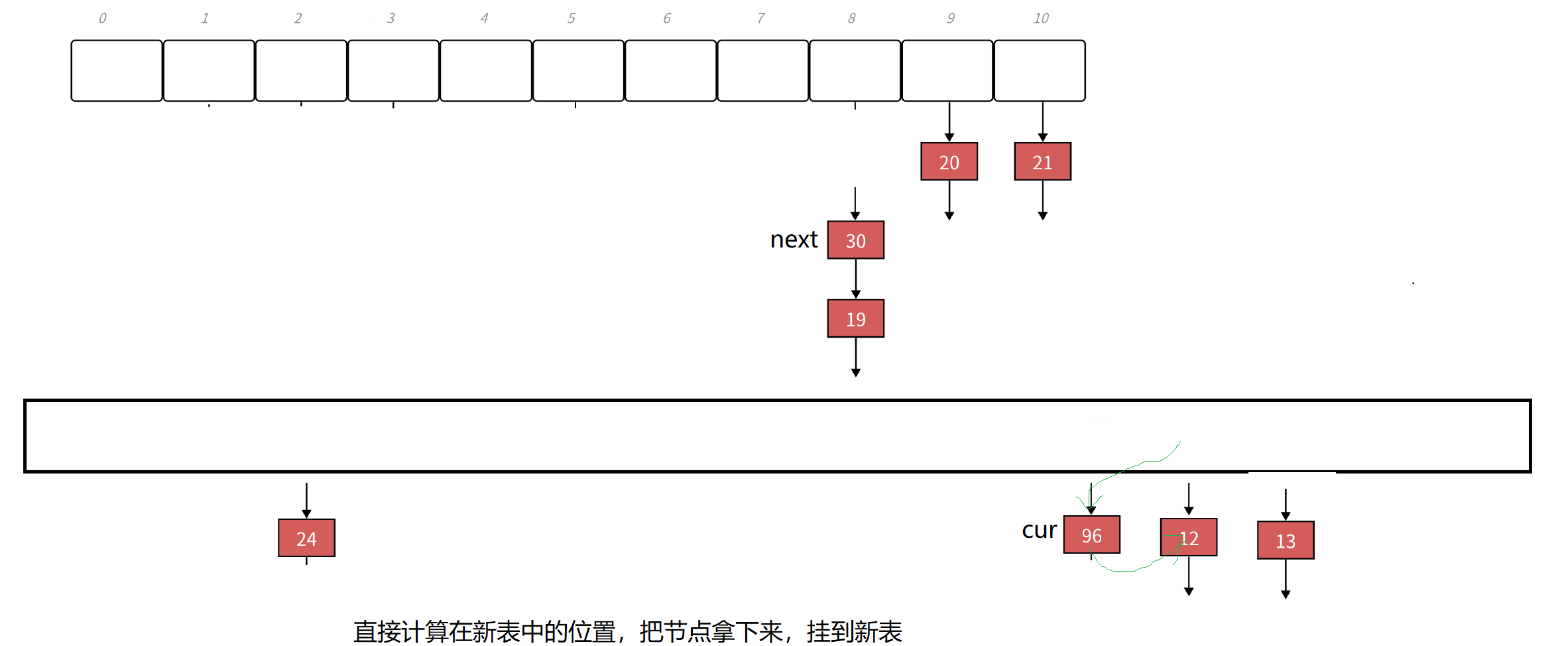
那我们就不能复用insert这个函数了,insert的话,他就会给你主动开辟一个结点来进行。
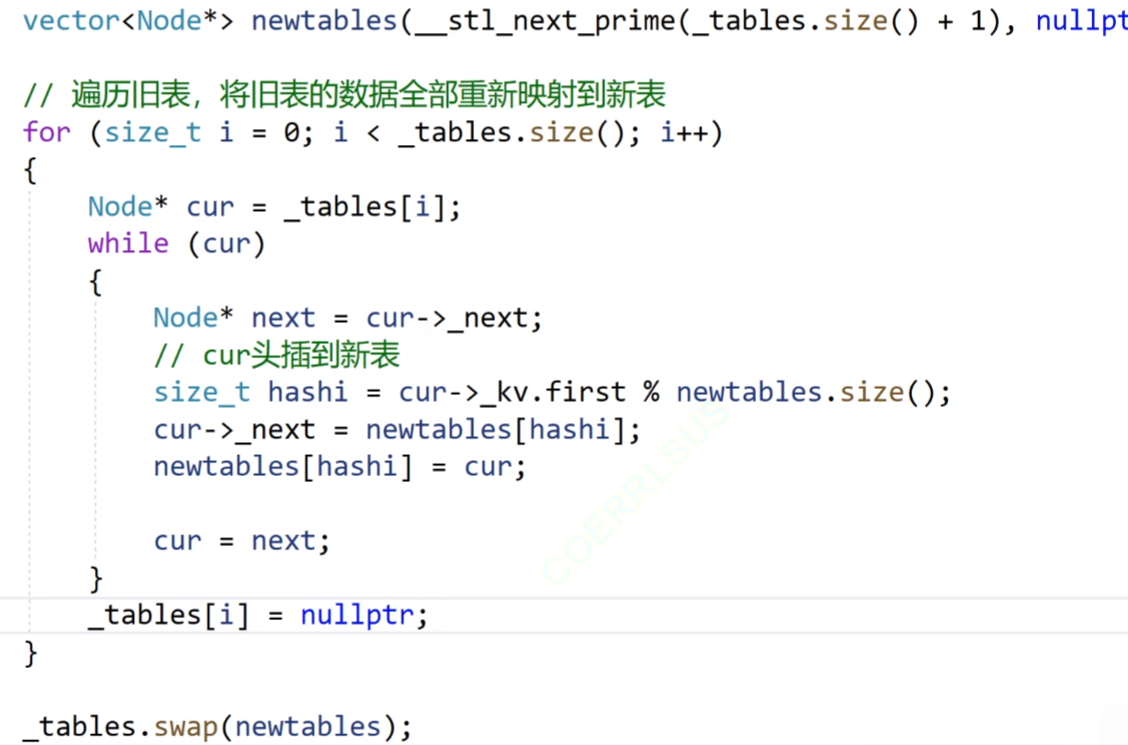
我们看这个代码,我们这次不创建新的哈希表,我们创建一个vector来(还是使用素数表),然后我们遍历原本的哈希表的vector,遇到哈希桶的话,我们就把结点移动到我们新建的vector上。
最后把这个vector和原来的哈希表的vector进行交换。
这个第二种的效率是非常好的,我们推荐使用第二种方式;
Find():
我们继续看这个函数,这个是我们的查找函数的实现:

我们直接根据这个key找到这个哈希位置,然后遍历这个位置的哈希桶,遍历每个结点看是不是我们要的,是的话就返回。
我们这里的话我们传进来的key我们使用了仿函数Hash套起来了,这个Hash函数是为了把传进来的数据key设置为可以取模类型的int类型,计算出,元素在哈希表中的位置。
Erase():
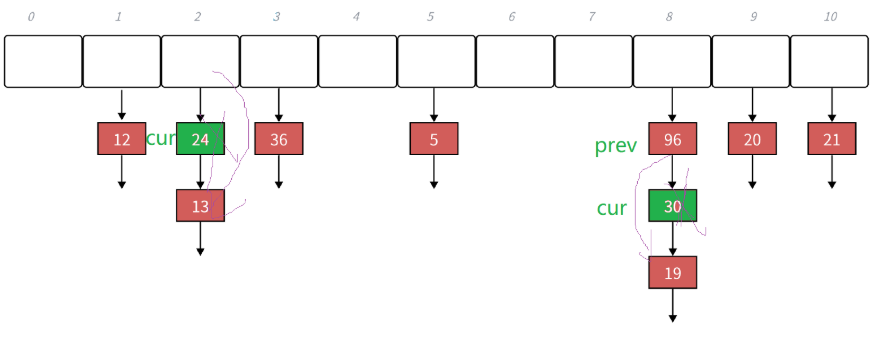

补充:

使用哈希表封装实现unordered_set和unordered_map的实现:

Hash仿函数的话,他是把我们传进来的值转换为int类型的可以进行取模来计算出,元素在哈希表中的位置。
