机器学习-人与机器生数据的区分模型测试 -数据筛选
内容继续机器学习-人与机器生数据的区分模型测试
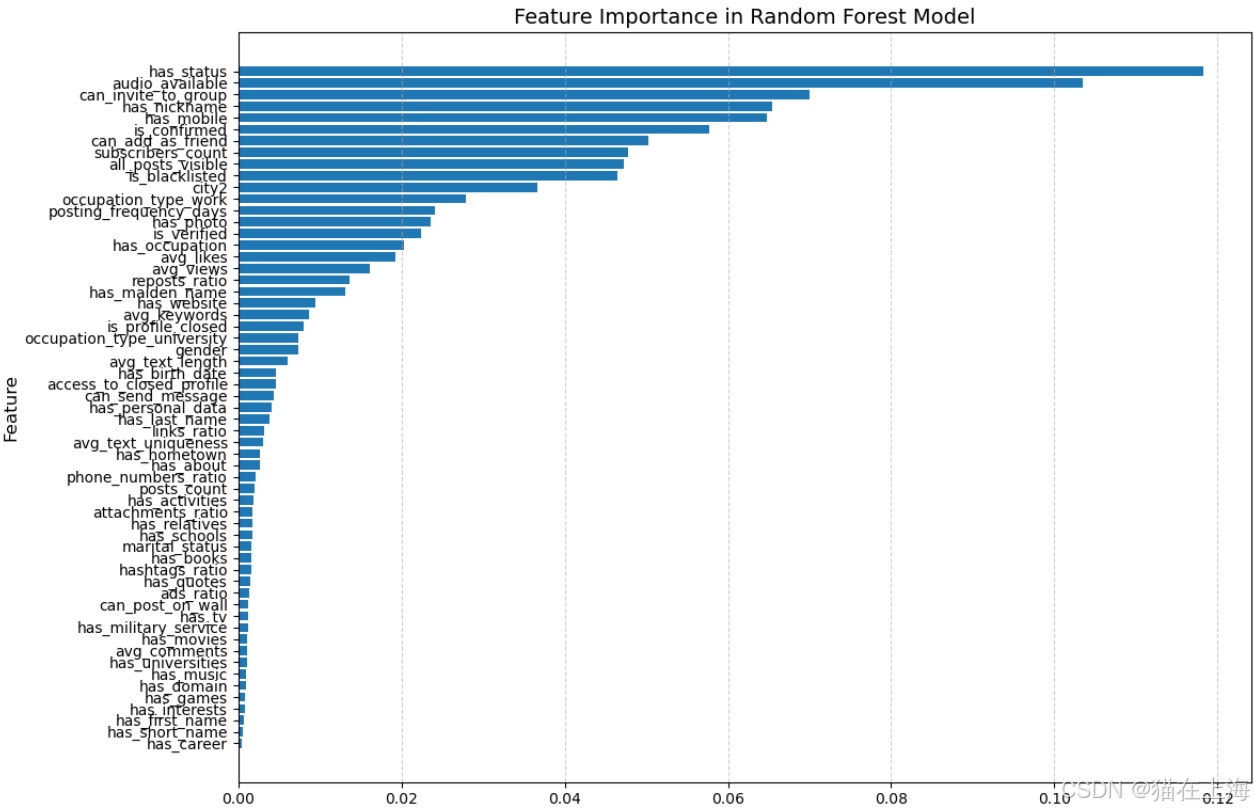
使用随机森林的弱学习树来筛选相对稳定的特征数据
# 随机森林筛选特征
X = data.drop(['city', 'target'], axis=1) # 去除修改前的城市名称列和目标变量列
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)rf_model = RandomForestClassifier(n_estimators=100, random_state=42) # 假设使用随机森林模型
rf_model.fit(X_train, y_train)feature_importances = rf_model.feature_importances_
feature_names = X.columns
# 打印特征重要性
for feature_name, importance in zip(feature_names, feature_importances):print(f"{feature_name}: {importance}")#特征有消息放入DATAFRAME中
feature_importances_df = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importances})
feature_importances_df = feature_importances_df.sort_values(by='Importance', ascending=False)
feature_importances_df.index = range(1, len(feature_importances_df) + 1)
#feature_importances_df.to_csv('feature_importances.csv', index=False)# 绘制优化后的特征重要性图
plt.figure(figsize=(12, 8))
plt.barh(feature_importances_df['Feature'], feature_importances_df['Importance'],height=0.8,color='#1f77b4' # 可选:调整颜色:ml-citation{ref="3" data="citationList"}
)
plt.gca().invert_yaxis()
plt.xlabel('Feature Importance', fontsize=12)
plt.ylabel('Feature', fontsize=12)
plt.title('Feature Importance in Random Forest Model', fontsize=14)
plt.grid(axis='x', linestyle='--', alpha=0.6) # 可选:添加网格线:ml-citation{ref="3" data="citationList"}
plt.tight_layout()
plt.savefig('feature_importance.png', dpi=300) # 可选:保存高清图:ml-citation{ref="3" data="citationList"}
plt.show()
计算得出以下特征
其他指标计算有效性
IV值
#定义计算VIF函数
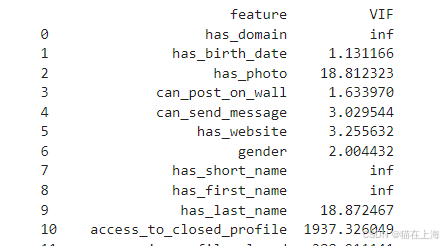
def calculate_vif(data):vif_data = pd.DataFrame()vif_data["feature"] = data.columnsvif_data["VIF"] = [variance_inflation_factor(data.values, i) for i in range(data.shape[1])]return vif_datavif_results = calculate_vif(X) # X为自变量数据框
print(vif_results)
#VIF ≥ 10时,存在显著共线性
相关系数矩阵
corr_matrix = X.corr() # X为自变量数据框
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.show()
共线性
X_matrix = X.values # X为自变量数据框
cond_number = np.linalg.cond(X_matrix)
print("条件数:", cond_number)
#条件数 > 100时,可能存在显著共线性
容忍度
#容忍度是VIF的倒数,反映变量独立性。
tol = 1 / np.array([variance_inflation_factor(X.values, i) for i in range(X.shape[1])])
print("容忍度:", tol)
#容忍度 < 0.1时,可能存在显著共线性
特征筛选
# 选择重要特征
threshold = 0.01 # 设定阈值
important_features = feature_names[feature_importances > threshold]#筛选前30个特征
important_features = feature_importances_df['Feature'][:30]# 构建新的数据集
new_data = data[important_features]
new_data['target'] = data['target'] # 将目标变量添加到新的数据集中df_temp =temp[important_features]
df_temp['target'] = temp['target']# 划分训练集和测试集
X = new_data.drop('target', axis=1)
y = new_data['target']X_temp =df_temp.drop('target', axis=1)
y_temp = df_temp['target']#重新划分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler() # 假设使用标准化方法
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
上述代码的运行效果
IV值
相关性矩阵

共线与容忍度