26、思维链Chain-of-Thought(CoT)论文笔记
思维链Chain-of-Thought(CoT)
- **1、研究背景与核心目标**
- **2、思维链提示的方法设计**
- 2.1 COT方法
- 2.2 传统方法
- 3、实验设计与关键数据集
- 3.1 算术推理
- 3.2 常识推理
- 3.3 符号推理
- 4、关键实验结果
- 1. 算术推理:思维链提示显著提升多步问题解决率
- 2. 常识推理:PaLM 540B超越人类表现
- 3. 符号推理:支持长度泛化
- 5、机制分析与局限性
- 6、结论
- 7、关键问题与答案
- 1. 思维链提示的核心机制是什么?
- 2. 思维链提示在不同任务中的表现如何?
- 3. 思维链提示的主要局限性是什么?
- **8、经典论文与方法解析**
- **1. 经典论文:《Chain of Thought Prompting Elicits Reasoning in Large Language Models》(Wei et al., 2022)**
- **2. 长思维链扩展:《Tree of Thought: Deliberate Problem Solving with Large Language Models》(Yao et al., 2023)**
- **3. 应对长上下文的优化:《Long Chain of Thought Reasoning in Large Language Models》(Zhang et al., 2023)**
- **CoT的局限性与未来方向**
- 9、提示词工程框架:CoT、ToT、GoT、PoT
- 10、COT思维链(Chain of Thought)
论文题目:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 在大型语言模型中提示推理的思维链
COT论文地址:https://arxiv.org/abs/2201.11903
[Submitted on 28 Jan 2022 (v1), last revised 10 Jan 2023 (this version, v6)]
1、研究背景与核心目标
-
大模型的推理瓶颈
尽管语言模型规模扩大能提升性能(如GPT-3、PaLM),但在算术、常识、符号推理等多步推理任务中表现有限。传统少样本提示(Standard Prompting)仅提供“问题-答案”示例,无法引导模型分解复杂问题。 -
核心思路
结合“自然语言推理步骤”与“少样本提示”,通过在提示中加入中间推理过程(如“首先计算…然后相加…”),让模型模仿人类思维路径,实现多步推理的可解释性与准确性提升。
2、思维链提示的方法设计
2.1 COT方法
研究目标与核心方法
- 核心问题:如何提升大模型在算术、常识、符号推理等复杂任务上的表现?
- 创新方法:
提出思维链提示(CoT Prompting),在少样本提示中加入自然语言推理步骤(如“先计算…再相加…”),将问题分解为中间步骤,引导模型生成连贯推理路径。- 示例:标准提示仅给“问题-答案”,思维链提示增加“问题-推理步骤-答案”(如)。
-
提示结构
在少样本示例中加入三元组:<输入, 思维链(中间推理步骤), 输出>。- 例:算术题中,先分解问题为“初始数量→新增数量→总和”,再给出答案。
-
关键特性
- 分解问题:将多步任务拆分为可处理的中间步骤,分配更多计算资源到复杂环节。
- 可解释性:推理链揭示模型决策逻辑,便于调试错误。
- 泛化性:适用于算术、常识、符号推理等多类任务,依赖语言本身的逻辑性。

-
示例

- 标准提示(Standard prompting)。对于基线,我们考虑了由 Brown et al. (2020) 推广的标准小样本提示,其中在输出测试时示例的预测之前,先给语言模型输入-输出对的上下文示例。示例的格式为问题和答案。该模型直接给出了答案,如图 1 所示(左)。
- 思维链提示(Chain-of-thought prompting)。我们提出的方法是在少样本提示中为每个示例增加一个与答案相关的思维链,如图1(右)所示。由于大多数数据集仅包含评估集,我们手动构建了一组包含八个带思维链的少样本提示示例——图1(右)展示了一个思维链示例,完整的示例集见附录表20。(这些特定示例未经过提示工程优化;鲁棒性分析见第3.4节和附录A.2。)为了研究这种形式的思维链提示是否能成功引出一系列数学应用题的正确推理,我们对除AQuA外的所有基准测试使用了这组八个思维链示例(AQuA为多项选择题,非自由回答)。对于AQuA,我们使用了训练集中的四个示例和解答,见附录表21。


2.2 传统方法
论文旨在解决大型语言模型(LLMs)在复杂推理任务(如算术、常识、符号推理)中表现不足的问题。传统方法要么依赖大量标注数据进行训练/微调,要么使用少样本提示,但前者成本高,后者在推理任务中效果有限。因此,论文提出一种结合自然语言推理步骤与少样本提示的新方法,即思维链提示。
二、核心思路:融合两种方法的优势
文中提到的“两个想法”及其局限性如下:
-
想法一:自然语言推理步骤(Rationales)
- 核心:通过生成自然语言中间步骤(如“首先计算…然后相加…”)辅助推理。
- 现有方法:
- 从头训练:如Ling等人(2017)让模型生成自然语言中间步骤。
- 微调预训练模型:如Cobbe等人(2021)使用标注的推理链微调模型。
- 神经符号方法:使用形式语言(如逻辑表达式)替代自然语言(Roy & Roth, 2015等)。
- 局限性:需要大量高质量标注的推理链,成本远高于普通输入-输出对。
-
想法二:少样本提示(Few-Shot Prompting)
- 核心:通过少量输入-输出示例(如“问题-答案”对)激活模型的上下文学习能力,无需微调。
- 优势:适用于简单问答任务(如Brown等人(2020)的GPT-3)。
- 局限性:在推理任务中效果差,且模型规模扩大后性能提升不明显(Rae等人,2021)。
-
思维链提示:结合两者的创新点
- 方法:在少样本提示中加入三元组〈输入, 思维链, 输出〉,其中“思维链”是自然语言中间推理步骤(如图1所示)。
- 目标:
- 利用自然语言分解复杂问题,避免神经符号方法的形式化限制。
- 借助少样本提示的灵活性,减少对大量标注数据的依赖。
- 关键优势:
- 无需微调:直接使用预训练模型,通过提示激活推理能力。
- 单模型通用:一个模型可处理多种任务,保持泛化性。
3、实验设计与关键数据集
| 任务类型 | 数据集 | 样本量 | 特点 |
|---|---|---|---|
| 算术推理 | GSM8K | 1.3K | 多步数学应用题,如“计算购物总费用” |
| SVAMP | 1K | 结构多样的算术题,含陷阱条件 | |
| 常识推理 | CSQA | - | 常识问答,如“哪里能找到人群?” |
| StrategyQA | - | 多跳策略推理,如“电影是否刺激边缘系统” | |
| 符号推理 | 字母拼接 | - | 拼接单词末尾字母(如“Lady Gaga”→“ya”) |
| 硬币翻转 | - | 跟踪硬币翻转状态,支持长度泛化 |
3.1 算术推理
算术推理的思路链示例:



3.2 常识推理

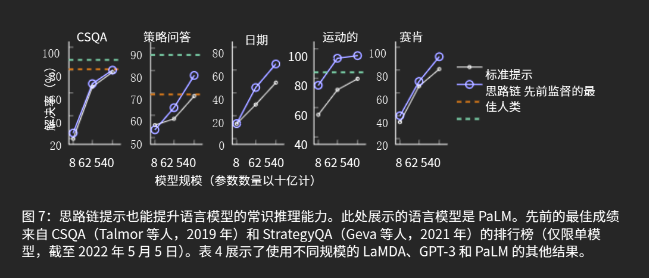
3.3 符号推理

4、关键实验结果
1. 算术推理:思维链提示显著提升多步问题解决率
- GSM8K基准:
模型 标准提示解决率 思维链提示解决率 提升幅度 PaLM 540B 17.9% 56.9% +39.0% GPT-3 175B 15.6% 46.9% +31.3% - 关键发现:
- 模型规模是关键:≤10B参数模型无效,≥100B模型效果显著(如LaMDA 137B从6.5%→14.3%,)。
- 消融实验:仅用方程提示(如“5×3=15”)效果差(GSM8K仅5.4%),自然语言推理步骤不可替代()。
2. 常识推理:PaLM 540B超越人类表现
- StrategyQA任务:
- 标准提示解决率:68.6% → 思维链提示:77.8%(超越人类专家84%,)。
- SayCan机器人规划:
- 思维链提示使PaLM 540B规划准确率达91.7%,显著高于标准提示(80.8%)。
3. 符号推理:支持长度泛化
- 4步硬币翻转任务:
- PaLM 540B思维链提示准确率100%,标准提示仅49.3%()。
- 3词字母拼接:
- LaMDA 137B思维链提示准确率77.5%,标准提示仅5.8%。
5、机制分析与局限性
- 涌现特性:
思维链推理是模型规模的涌现能力,小模型生成“流畅但逻辑错误”的推理链(如PaLM 62B在算术题中常漏步骤,)。 - 误差类型:
- 大模型(540B)主要犯“计算错误”(如加法失误),小模型(62B)多为“语义理解错误”(如误读题意,)。
- 局限性:
- 需要≥100B参数模型,小模型无效;
- 推理路径可能不准确(46%错误案例为“ minor mistakes”,);
- 依赖人工设计提示示例,存在提示敏感性(不同标注者效果波动±5%,)。
6、结论
思维链提示通过自然语言中间步骤分解问题,显著提升大模型复杂推理能力,且无需微调、支持多任务。其效果随模型规模增大而涌现,为开发通用推理模型提供了新方向,但小模型应用和推理可靠性仍需优化。
7、关键问题与答案
1. 思维链提示的核心机制是什么?
答案:思维链提示通过在提示中提供自然语言中间推理步骤(如“先计算购买数量,再求和”),引导模型将多步问题分解为可处理的子步骤,激活模型的推理能力。这种方法利用大模型的少样本学习能力,通过示例模仿人类思维过程,尤其在≥100B参数的模型中效果显著,例如PaLM 540B在GSM8K任务中解决率提升39%()。
2. 思维链提示在不同任务中的表现如何?
答案:
- 算术推理:PaLM 540B在GSM8K(多步应用题)解决率从17.9%提升至56.9%,超越微调的GPT-3(46.9%);
- 常识推理:在StrategyQA(多跳策略问题)中,PaLM 540B从68.6%提升至77.8%,超过人类专家(84%);
- 符号推理:在4步硬币翻转任务中,PaLM 540B准确率达100%,而标准提示仅49.3%()。
3. 思维链提示的主要局限性是什么?
答案:
- 模型规模依赖:仅在≥100B参数模型中有效,小模型(如LaMDA 2B)生成的推理链逻辑混乱,解决率低于标准提示;
- 推理不可靠性:约54%的错误案例存在“语义理解错误”或“关键步骤缺失”,例如PaLM 62B在计算购物费用时漏加小费();
- 提示敏感性:不同标注者撰写的提示效果波动较大(如硬币翻转任务解决率从71.4%到99.6%),需人工优化提示质量()。
8、经典论文与方法解析
1. 经典论文:《Chain of Thought Prompting Elicits Reasoning in Large Language Models》(Wei et al., 2022)
- 核心贡献:提出CoT提示法,通过“分步引导”让大模型生成推理过程。
- 方法:在提示中加入“Let’s think step by step”或示例推理步骤,引导模型分解问题。
- 实验:在数学题数据集GSM8K上,PaLM-540B使用CoT提示后准确率从17.9%提升至57.1%。
举例:数学题推理
问题:“小明买了10个苹果,吃了3个,又分给朋友2个,剩下的苹果平均分给2人,每人得几个?”
传统回答(无CoT):
(10-3-2)/2=2.5 → 每人得2个(错误,未考虑小数问题)。
CoT回答:
第一步:计算剩余苹果数,10-3=7个。 第二步:分给朋友后剩余7-2=5个。 第三步:5个苹果分给2人,5÷2=2.5个。 但苹果不能切分,故每人得2个,剩余1个。
关键:显式步骤暴露逻辑漏洞(是否允许小数),避免直接得出错误答案。
2. 长思维链扩展:《Tree of Thought: Deliberate Problem Solving with Large Language Models》(Yao et al., 2023)
- 核心思想:将线性思维链升级为树状结构,在关键节点生成多个推理分支,通过评估选择最优路径(类似“搜索”)。
- 适用场景:需要探索不同可能性的长推理(如围棋策略、程序调试)。
- 方法:
- 分阶段生成:将问题划分为多个阶段,每个阶段生成有限个候选推理步骤。
- 状态评估:使用模型评估每个分支的可行性(如“该步骤是否接近解”)。
- 迭代搜索:基于评估结果选择分支,递归展开推理树。
举例:逻辑谜题推理
问题:“岛上有骑士(只说真话)和无赖(只说假话),A说‘B是骑士’,B说‘我们两人不同类’,问A和B的身份?”
Tree of Thought推理过程:
- 阶段1:假设A是骑士
- 分支1:A说真话→B是骑士。
- 子分支:B说“我们不同类”→若B是骑士,此话为真→A和B应不同类,矛盾。故排除此分支。
- 分支1:A说真话→B是骑士。
- 阶段2:假设A是无赖
- 分支1:A说假话→B不是骑士(即B是无赖)。
- 子分支:B说“我们不同类”→若B是无赖,此话为假→A和B同类,符合假设。故结论:A和B均为无赖。
关键:通过树状分支排除矛盾路径,避免线性推理的单一性错误。
- 子分支:B说“我们不同类”→若B是无赖,此话为假→A和B同类,符合假设。故结论:A和B均为无赖。
- 分支1:A说假话→B不是骑士(即B是无赖)。
3. 应对长上下文的优化:《Long Chain of Thought Reasoning in Large Language Models》(Zhang et al., 2023)
- 挑战:长推理链超出模型上下文长度(如GPT-4支持8k tokens,但复杂推理可能需要更长序列)。
- 解决方案:
- 分段推理:将推理链拆分为多个短段落,逐段生成并缓存中间结果。
- 检索增强:对涉及外部知识的步骤(如历史事件时间、科学常数),调用检索工具补充信息。
- 注意力机制优化:通过位置编码或记忆模块强化对早期步骤的关注。
举例:历史事件推理
问题:“分析第一次世界大战对20世纪经济政策的长期影响。”
分段CoT:
- 段落1:分析战争直接后果(如欧洲经济衰退、美国崛起为债权国)。
- 段落2:推导战后政策(如凡尔赛和约赔款对德国经济的冲击,引发大萧条)。
- 段落3:联系宏观经济理论发展(如凯恩斯主义对政府干预的倡导)。
关键:通过分段避免上下文溢出,同时利用检索确认赔款数额、政策时间线等细节。
CoT的局限性与未来方向
- 幻觉问题:模型可能生成看似合理但错误的推理步骤(如数学计算错误)。
- 效率问题:长CoT生成耗时较长,需优化解码速度。
- 训练数据偏差:依赖高质量推理数据,若训练集中缺乏多步推理案例,效果受限。
未来方向:
- 混合推理系统:结合符号推理(如逻辑规则)与神经网络,提升可靠性。
- 自动提示优化:通过强化学习自动生成最优CoT提示格式。
- 多模态CoT:融合图像、公式等信息,支持跨模态推理(如图表分析)。
9、提示词工程框架:CoT、ToT、GoT、PoT
其他提示词工程框架,思维链CoT主要是线性的,多个推理步骤连成一个链条。在思维链基础上,又衍生出ToT、GoT、PoT等多种推理模式。这些和CoT一样都属于提示词工程的范畴。CoT、ToT、GoT、PoT等提示词工程框架大幅提升了大模型的推理能力,让我们能够使用大模型解决更多复杂问题,提升了大模型的可解释性和可控性,为大模型应用的拓展奠定了基础。
https://blog.csdn.net/kaka0722ww/article/details/147950677
10、COT思维链(Chain of Thought)
2022 年 Google 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这些推理的中间步骤就被称为思维链(Chain of Thought)。
思维链提示(CoT Prompting),在少样本提示中加入自然语言推理步骤(如“先计算…再相加…”),将问题分解为中间步骤,引导模型生成连贯推理路径。
-
示例:标准提示仅给“问题-答案”,思维链提示增加“问题-推理步骤-答案”(如)。
-
区别于传统的 Prompt 从输入直接到输出的映射 <input——>output> 的方式,CoT 完成了从输入到思维链再到输出的映射,即 <input——>reasoning chain——>output>。如果将使用 CoT 的 Prompt 进行分解,可以更加详细的观察到 CoT 的工作流程。
-
示例对比(传统 vs. CoT)
-
传统提示
问题:1个书架有3层,每层放5本书,共有多少本书? 答案:15本 -
CoT 提示
问题:1个书架有3层,每层放5本书,共有多少本书? 推理: 1. 每层5本书,3层的总书数 = 5 × 3 2. 5 × 3 = 15 答案:15本
-
关键类型
-
零样本思维链(Zero-Shot CoT)
无需示例,仅通过提示词(如“请分步骤思考”)触发模型生成思维链。适用于快速引导模型进行推理。 -
少样本思维链(Few-Shot CoT)
提供少量带思维链的示例,让模型模仿示例结构进行推理。例如,先给出几个问题及其分解步骤,再让模型处理新问题。

如图所示,一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。一般而言指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
以是否包含示例为区分,可以将 CoT 分为 Zero-Shot-CoT 与 Few-Shot-CoT,在上图中,Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。而 Few-Shot-Cot 则在示例中详细描述了“解题步骤”,让大模型照猫画虎得到推理能力。
提示词工程框架( 链式提示Chain):其他提示词工程框架,思维链CoT主要是线性的,多个推理步骤连成一个链条。在思维链基础上,又衍生出ToT、GoT、PoT等多种推理模式。这些和CoT一样都属于提示词工程的范畴。CoT、ToT、GoT、PoT等提示词工程框架大幅提升了大模型的推理能力,让我们能够使用大模型解决更多复杂问题,提升了大模型的可解释性和可控性,为大模型应用的拓展奠定了基础。
参考:
https://blog.csdn.net/kaka0722ww/article/details/147950677
https://www.zhihu.com/tardis/zm/art/670907685?source_id=1005