第J1周:ResNet-50算法实战与解析
🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍖 原作者:K同学啊
我的环境
语言环境:Python3.8·
编译器:Jupyter Lab
深度学习环境:Pytorchtorch1.12.1+cu113
torchvision0.13.1+cu113
一、准备工作
二、导入数据
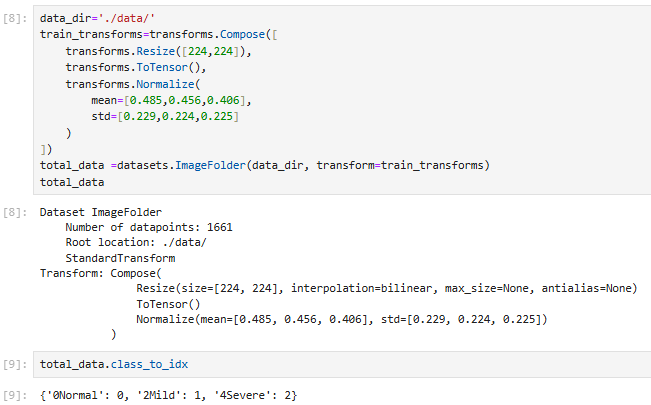
三、划分数据集

四、搭建网络
import torch
import torch.nn as nn
import torchsummary as summary
import torchvision.models as modelsdef identity_block(input_tensor, kernel_size, filters, stage, block):"""构建残差网络的恒等映射块Args:input_tensor: 输入张量kernel_size: 卷积核大小filters: [f1, f2, f3] 形式的过滤器数量列表stage: 阶段编号block: 块编号"""filters1, filters2, filters3 = filtersname_base = f'{stage}{block}_identity_block_'# 第一个 1x1 卷积层x = nn.Conv2d(input_tensor.size(1), filters1, 1, bias=False)(input_tensor)x = nn.BatchNorm2d(filters1)(x)x = nn.ReLU(inplace=True)(x)# 3x3 卷积层x = nn.Conv2d(filters1, filters2, kernel_size, padding=kernel_size//2, bias=False)(x)x = nn.BatchNorm2d(filters2)(x)x = nn.ReLU(inplace=True)(x)# 第二个 1x1 卷积层x = nn.Conv2d(filters2, filters3, 1, bias=False)(x)x = nn.BatchNorm2d(filters3)(x)# 添加跳跃连接x = x + input_tensorx = nn.ReLU(inplace=True)(x)return xdef conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2,2)):"""构建残差网络的卷积块Args:input_tensor: 输入张量kernel_size: 卷积核大小filters: [f1, f2, f3] 形式的过滤器数量列表stage: 阶段编号block: 块编号strides: 步长元组"""filters1, filters2, filters3 = filtersname_base = f'{stage}{block}_conv_block_'# 主路径x = nn.Conv2d(input_tensor.size(1), filters1, 1, stride=strides, bias=False)(input_tensor)x = nn.BatchNorm2d(filters1)(x)x = nn.ReLU(inplace=True)(x)x = nn.Conv2d(filters1, filters2, kernel_size, padding=kernel_size//2, bias=False)(x)x = nn.BatchNorm2d(filters2)(x)x = nn.ReLU(inplace=True)(x)x = nn.Conv2d(filters2, filters3, 1, bias=False)(x)x = nn.BatchNorm2d(filters3)(x)# shortcut 路径shortcut = nn.Conv2d(input_tensor.size(1), filters3, 1, stride=strides, bias=False)(input_tensor)shortcut = nn.BatchNorm2d(filters3)(shortcut)# 添加跳跃连接x = x + shortcutx = nn.ReLU(inplace=True)(x)return xdef ResNet50(input_shape=[224,224,3], num_classes=1000):"""构建 ResNet50 模型Args:input_shape: 输入图像的形状 [H, W, C]num_classes: 分类类别数"""# 输入层inputs = torch.randn(1, input_shape[2], input_shape[0], input_shape[1])# 初始卷积块 - 修改 ZeroPadding2d 为 pad 操作x = nn.functional.pad(inputs, (3, 3, 3, 3)) # 替换 ZeroPadding2dx = nn.Conv2d(input_shape[2], 64, 7, stride=2, bias=False)(x)x = nn.BatchNorm2d(64)(x)x = nn.ReLU(inplace=True)(x)x = nn.MaxPool2d(3, stride=2, padding=1)(x)# Stage 2x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1,1))x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')# Stage 3x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')# Stage 4x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')for block in ['b', 'c', 'd', 'e', 'f']:x = identity_block(x, 3, [256, 256, 1024], stage=4, block=block)# Stage 5x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')# 分类层x = nn.AdaptiveAvgPool2d((1, 1))(x)x = torch.flatten(x, 1)x = nn.Linear(2048, num_classes)(x)# 修改模型创建和前向传播的方式class ResNet(nn.Module):def __init__(self):super(ResNet, self).__init__()# 在这里定义所有层def forward(self, x):# 定义前向传播return xmodel = ResNet()# 移除 load_weights,改用 PyTorch 的加载方式model.load_state_dict(torch.load("resnet50_pretrained.pth"))return modelmodel = models.resnet50().to(device)
modelResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer2): Sequential((0): Bottleneck((conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(3): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer3): Sequential((0): Bottleneck((conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(3): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(4): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(5): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer4): Sequential((0): Bottleneck((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
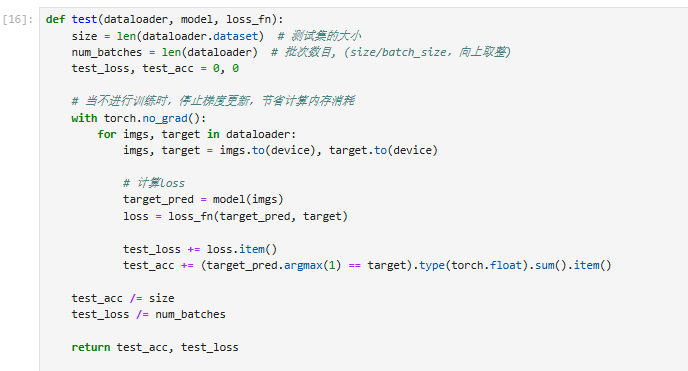
五、编写训练函数和测试函数
六、设置超参数
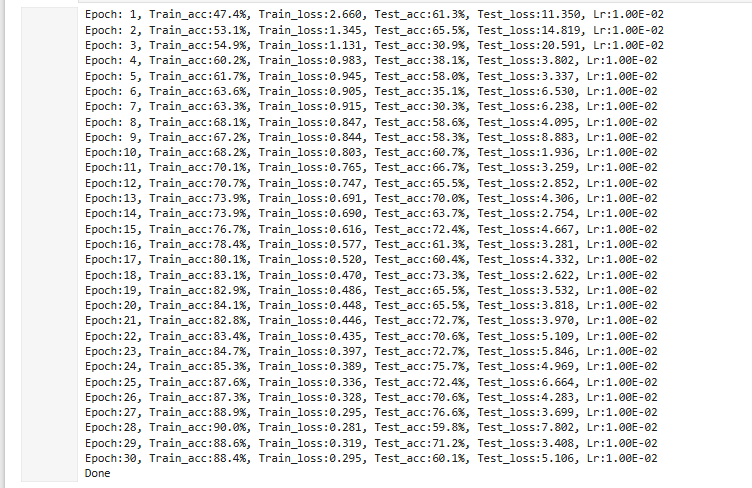
七、训练
八、可视化
八、总结
ResNet是由微软研究院提出的,应该是在2015年的ImageNet竞赛中取得了很好的成绩。残差块是它的核心概念,对吧?残差块通过跳跃连接(shortcut connections)将输入直接传递到后面的层,这样可以让网络更容易训练深层结构。那ResNet-50中的50层具体是怎么组成的呢?
ResNet有不同的版本,比如ResNet-18、34、50、101、152,数字代表层数。50层的应该比更小的版本更深,结构更复杂。那ResNet-50的结构具体是怎样的?可能由多个残差块堆叠而成,每个残差块里面有几个卷积层?
对了,ResNet中的残差块有两种类型,一种是基础的残差块,用于较浅的网络如ResNet-34,另一种是瓶颈结构(bottleneck),可能用于更深的网络如ResNet-50。瓶颈结构应该是指通过1x1的卷积层先减少通道数,再做3x3的卷积,然后再用1x1恢复通道数,这样可以减少计算量,同时保持网络深度。
所以ResNet-50可能由多个这样的瓶颈块组成。那每个阶段的块数应该是怎样的?比如,可能有四个阶段(stage),每个阶段包含不同数量的残差块。比如第一个阶段可能处理较大的特征图,之后每个阶段通过步长为2的卷积进行下采样,特征图尺寸减半,通道数增加。
比如,初始的层可能是一个7x7的卷积层,接着是池化层,然后是四个阶段的残差块。每个阶段的块数目可能是3,4,6,3,这样加起来总层数可能达到50层?需要计算一下每个块贡献的层数。瓶颈块每个块包含三个卷积层:1x1,3x3,1x1。所以每个块有3层,四个阶段的块数如果是3,4,6,3,总块数是3+4+6+3=16个块,每个块3层,就是16 * 3=48层,加上前面的7x7卷积层和池化层,还有最后的全连接层,可能总数接近50层?所以ResNet-50的结构大致如此。
另外,跳跃连接的结构可能有不同的处理方式,当输入和输出的通道数或尺寸不一致时,可能用1x1的卷积来调整通道数或进行下采样。例如,在进入每个阶段的第一个残差块时,可能需要调整shortcut连接的通道数,这时会使用一个1x1卷积,步长为2来减小尺寸并调整通道数。
那ResNet-50的创新点主要是残差学习和瓶颈结构,这样可以让网络更深而不出现梯度消失的问题。传统深层网络训练时,随着层数增加,准确率会饱和甚至下降,而残差网络通过引入跳跃连接,使得网络更容易学习恒等映射,从而让训练更深的网络变得可行。