Transformer网络结构
一、整体结构
Transformer由编码器(Encoder)和解码器(Decoder)堆叠组成,整体结构如图:
输入序列 → [编码器] × N → 中间表示 → [解码器] × N → 输出序列- 编码器:将输入序列映射为高阶特征表示(Context Vector)。
- 解码器:基于编码器输出和已生成部分输出,自回归地预测下一个元素。
- 堆叠层数:通常 N=6(基础版),复杂任务可增至 12 或 24 层。
二、核心组件详解
1. 自注意力机制(Self-Attention)
目标:捕捉序列中任意两个元素间的依赖关系,无论距离远近。
数学公式:
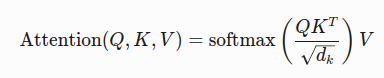
Q(Query):当前元素的查询向量
K(Key): 序列中所有元素的键向量
V(Value): 序列中所有元素的值向量
缩放因子:防止点积结果过大导致梯度消失
工作流程:
1. 输入向量通过线性变换生成Q、K、V
2. 计算Q与所有K的点积得分
3. 缩放得分并应用softmax归一化
4. 加权求和V得到输出
2. 多头注意力(Multi-Head Attention)
动机:单一注意力头只能捕捉一种模式,多头可并行学习多种关系。
实现:
将Q、K、V分割为h个头(通常h=8)
每个头独立进行自注意力计算
拼接所有头的输出并通过线性变换融合
公式:
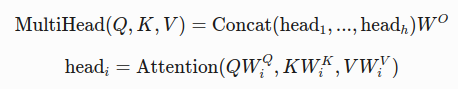
3. 位置编码(Positional Encoding)
问题:自注意力机制本身无法感知序列顺序
解决方案:为输入嵌入添加位置编码向量
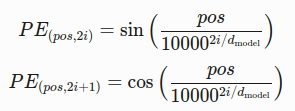
pos:元素在序列中的位置
i:维度索引
4. 前馈神经网络(Feed-Forward Network, FFN)
作用:对每个位置的表示进行非线性变换
结构:两个线性层+ReLU激活
公式:
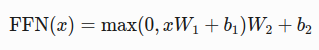
5. 残差连接与层归一化
残差连接:将子层输入直接加到输出,缓解梯度消失
![]()
层归一化:对每个样本的所有特征维度归一化,稳定训练过程
三、编码器与解码器差异
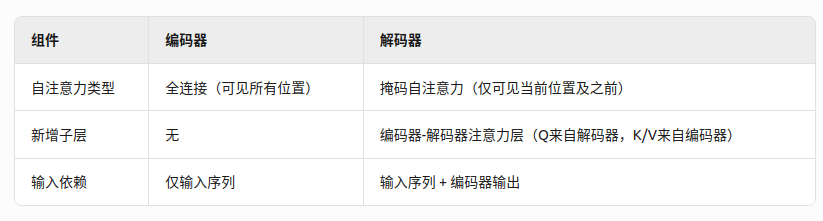
解码器工作流程:
1. 掩码自注意力:生成输出时无法看到未来信息
2. 编码器-解码器注意力:对齐输入与输出序列
3. 前馈网络:进一步特征提取
四、关键设计思想
1. 并行计算
自注意力可同时处理所有位置,远块于RNN的序列化计算
2. 长距离依赖
任意位置直接交互,解决RNN的梯度消失问题
3. 可解释性
注意力权重可视化分析模型关注区域