掌握 LangChain 文档处理核心:Document Loaders 与 Text Splitters 全解析

🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是LangChain
2、LangChain 在智能应用中的作用
二、Document Loaders 概述
1、什么是 Document Loader
2、常见的 Loader 类型
三、Text Splitters 概述
1、为什么需要 Text Splitter
2、常见的文本切分策略
四、实战示例
1、使用 PDFLoader + RecursiveCharacterTextSplitter 构建文档块
2、多文档加载并批量切分
一、引言
1、什么是LangChain
想象一下,你正在和 ChatGPT 聊天,问它一个复杂的问题,比如:“我上传的这份 PDF 文档里,第三章说的那个算法和第五章的原理有啥关系?”
这时候,你希望 AI 不光能看懂问题,还能读懂文档、记住上下文、把答案说清楚,对吧?😎
这,就是 LangChain 登场的地方!
🌟 简单一句话:
LangChain 是一个帮你构建 “更聪明的 AI 应用” 的框架。
🧩 它能做什么?
LangChain 像一个多才多艺的管家,替你打理 AI 应用的多个方面:
| 能力 | 举个栗子 🌰 |
|---|---|
| 📄 文档读取 | 支持 PDF、Word、网页、Notion 等多种格式! |
| ✂️ 文本切分 | 把长文章变成模型“能吃得下”的小块块 |
| 📦 存储与检索 | 把文档变成向量存在“记忆库”里,方便快速查找 |
| 🧠 调用大模型 | 接入 OpenAI、Claude、Ollama 等模型对话 |
| 🪜 工作流链条 | 把多个步骤串成“智能流程”,比如 读取→提问→总结 |
🤔 举个真实的例子:
你想构建一个 智能客服机器人,它能自动读取你的公司文档、PDF 手册、产品说明书,并且回答用户的问题。
你只要这样做:
-
✅ 用 LangChain 的 Document Loader 读取资料
-
✂️ 用 Text Splitter 把文档切成合适的大小
-
📦 存到向量数据库中,比如 FAISS 或 Elasticsearch
-
🤖 用户提问 → LangChain 帮你搜索相关文档片段
-
💬 调用大模型回答问题,还能引用来源!
是不是有点小惊艳?✨
🛠️ 为什么开发者喜欢它?
-
模块化:想换个模型、数据库?一行代码改完!
-
灵活性:适合快速搭建原型,也能打造企业级系统
-
社区活跃:文档全、插件多,成长飞快!
🏁 总结
LangChain = LLM 的超级助理工具箱🧰 + AI 应用的魔法管家🪄
如果你想让 AI 不止聊天,还能 读文档、处理流程、接数据源、当助手——LangChain 会是你的好搭档!

2、LangChain 在智能应用中的作用
在过去,我们想让 AI 做事,大多是“一个模型回答一个问题”——比如问 ChatGPT:“天气怎么样?”它会给你一个答案。
但当我们想让 AI 真正“工作起来”,比如:
-
📄 阅读上百页的 PDF 文档
-
📚 理解多个文件之间的关系
-
🧠 记住用户的历史提问
-
⚙️ 调用外部工具,比如数据库、搜索引擎、API
-
🔁 串联多个步骤,像人一样完成一项任务
👉 光靠一个大模型可不够了!这时,就轮到 LangChain 登场了!
🧰 LangChain 的作用是什么?
可以简单理解为:
LangChain 是连接大模型(LLM)与真实世界的桥梁🌉,让你的 AI 应用更聪明、更有用、更像“工具人”。
✅ 它解决了哪些问题?
| 智能应用需求 | LangChain 帮你搞定 ✔️ |
|---|---|
| 加载和处理各种格式文档 | 使用 Document Loaders |
| 将大文本拆分为小块供模型处理 | 使用 Text Splitters |
| 存储、检索知识片段 | 集成向量数据库(如 FAISS、Chroma 等) |
| 结合上下文做连续对话 | 支持 Memory 模块 |
| 自动调用外部工具 / API | Agent + Tool 模块 |
| 多步骤任务处理流程 | 使用 Chain(链式执行)机制 |
🧠 举个例子:
你要做一个 “AI 法律助手”,目标是能:
-
📂 读取几十份法律文书
-
🤔 回答用户关于具体条款的问题
-
💡 根据上下文推荐可能适用的法规
-
📬 自动生成答复邮件或草案
用 LangChain 的做法大致是这样:
-
用 Document Loaders 加载文书内容 📄
-
用 Text Splitters 切分成模型能处理的小段 ✂️
-
用 Embedding + 向量数据库 存储和快速检索 🧠
-
用 LLM + Chain 回答用户提问,引用相关文档 💬
-
用 Agent + Tool 自动生成邮件并发送 📧
是不是已经能脑补出整个系统架构了?😆
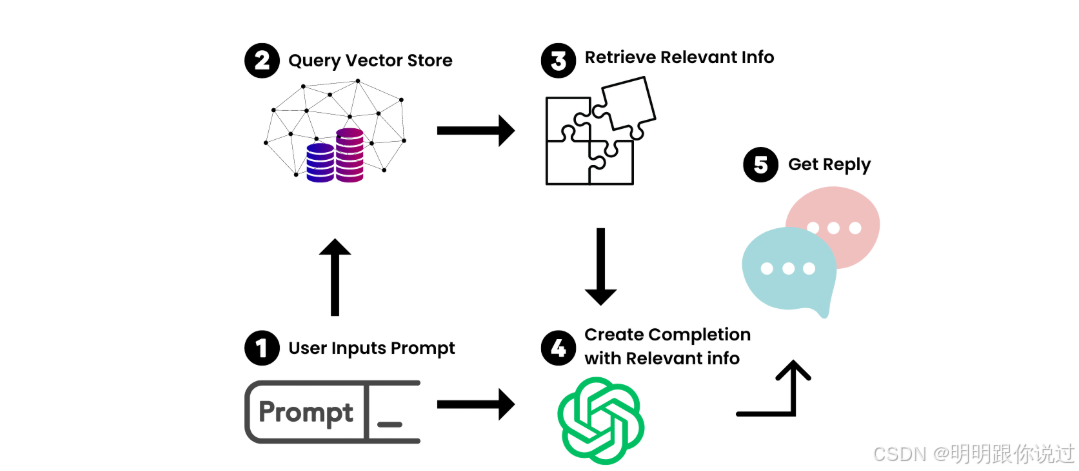
二、Document Loaders 概述
1、什么是 Document Loader
在构建 AI 应用时,我们经常会遇到这样的任务:
“把一份 PDF 文档、网页、Markdown 文件、甚至 Notion 页面内容,喂给大模型,让它理解并回答问题。”
问题来了:这些内容格式五花八门,模型又只接受纯文本或结构化数据,我们该怎么办?🤔
这时,LangChain 提供的 Document Loader(文档加载器) 就派上用场啦!
Document Loader 就像一个“格式转换器”+“文件导入助手”,负责把各种各样的文档 👉 变成大模型能理解的“纯文本+元信息”结构。
📦 一个典型的加载结果长这样:
{"page_content": "这里是文档的正文内容……","metadata": {"source": "my_file.pdf","page": 2}
}这个结构非常适合后续切分、嵌入向量、检索和问答等操作。
📚 支持哪些格式?
LangChain 内置或扩展支持的 Document Loaders 非常多,几乎覆盖常见的所有数据源:
| 类型 | 举例 |
|---|---|
| 📄 文件类 | .txt, .pdf, .docx, .md, .csv 等 |
| 🌐 网络类 | 网页、博客、RSS、Sitemap |
| 📋 协作类 | Notion、Google Docs、Slack、Confluence |
| 🗃️ 数据类 | JSON、SQL、Elasticsearch、MongoDB 等 |
| 🧩 其他 | 自定义 Loader,只要你能解析,都能加! |
Document Loader 是智能应用中第一个“入口守门员”👮♂️,它帮你把“各种格式的知识”变成“模型可读的文本”。
没有它,大模型就只能瞪着 PDF 干瞪眼了 😂
2、常见的 Loader 类型
1️⃣ 本地文件加载器(File Loaders)
这些 Loader 适用于你电脑里的各种文档,比如:
| 格式 | Loader 名称 | 说明 |
|---|---|---|
.txt | TextLoader | 加载纯文本文件 |
.pdf | PyPDFLoader, PDFMinerLoader 等 | 支持按页加载 PDF 文档 |
.docx | UnstructuredWordDocumentLoader | 解析 Word 文件 |
.md | UnstructuredMarkdownLoader | 加载 Markdown 文件 |
.csv | CSVLoader | 逐行加载 CSV 文件内容 |
📌 提示:PDF 支持的 Loader 有多个,可按需选择,比如:
-
PyPDFLoader: 按页加载,保留分页信息 -
PDFPlumberLoader: 更适合带复杂格式的 PDF
2️⃣ 网络内容加载器(Web Loaders)
想让 AI 看网页、博客、Sitemap?这些 Loader 派上用场:
| 数据源 | Loader 名称 | 说明 |
|---|---|---|
| 网页 | WebBaseLoader | 读取网页内容(可自定义解析器) |
| RSS | RSSFeedLoader | 加载 RSS 订阅内容 |
| Sitemap | SitemapLoader | 扫描整站结构并加载页面内容 |
3️⃣ 协作平台加载器(SaaS & Cloud Docs)
适用于现代团队的“云端知识库”,比如:
| 平台 | Loader 名称 | 说明 |
|---|---|---|
| Notion | NotionDBLoader | 加载 Notion 数据库中的页面 |
| Google Docs | GoogleDriveLoader | 加载 Google 文档、表格等 |
| GitHub | GitHubRepoLoader | 加载 GitHub 仓库中的代码文件或文档 |
| Slack | SlackLoader | 加载 Slack 聊天记录 |
📝 很适合用于构建企业内部知识问答系统!
4️⃣ 数据库 / 数据源加载器(DB/Data Source)
当你的知识存储在结构化数据库或其他系统中时:
| 数据源 | Loader 名称 | 说明 |
|---|---|---|
| SQL 数据库 | SQLDatabaseLoader | 连接数据库并提取数据 |
| Elasticsearch | ElasticsearchLoader | 加载已有索引中的数据 |
| MongoDB | MongoDBLoader | 读取 MongoDB 集合内容 |
| JSON | JSONLoader | 加载本地或远程 JSON 文件 |
🔗 有些数据库 Loader 可与 ORM / SQLAlchemy 结合使用。
5️⃣ 自定义/非结构化内容加载器
当你遇到“杂七杂八”的文档,比如 HTML、扫描图像、邮件正文……也不用怕:
| 类型 | Loader 名称 | 说明 |
|---|---|---|
| 任意文本块 | UnstructuredFileLoader | 自动识别结构,适配多种格式(PDF, HTML, EML等) |
| 邮件 | UnstructuredEmailLoader | 提取 EML/MSG 邮件内容 |
| 图片 | UnstructuredImageLoader | OCR 图像并提取文字内容(需 Tesseract) |
🧠 “Unstructured” 系列 Loader 是 LangChain 的秘密武器,适配面非常广!
✅ 总结一张图:Loader 类型一览表
📁 本地文件类 → Text, PDF, Word, Markdown, CSV
🌐 网络页面类 → HTML 网页, RSS, Sitemap
☁️ 协作平台类 → Notion, Google Docs, GitHub, Slack
🗃️ 数据源/数据库类 → SQL, MongoDB, Elasticsearch, JSON
🌀 非结构化类 → Email, HTML, OCR 图片, 多格式文档

三、Text Splitters 概述
1、为什么需要 Text Splitter
当我们使用大语言模型(LLM)处理文档时,比如问它:
“请总结这份 200 页的产品白皮书”📄
你可能会遇到👇这种“灵魂打击”:
❌ 模型回复:文本太长,我读不下去了!
因为 大多数模型对输入长度是有限制的(比如 GPT-4 的上下文长度是几千到几万 token,不等于几万字)。文档太长会:
-
❌ 超出 token 限制,直接报错
-
❌ 信息太杂,模型难以理解上下文
-
❌ 检索性能下降,影响回答质量
于是,LangChain 中的 “Text Splitter(文本切分器)” 就成了救场英雄 🦸♂️!
🧠 Text Splitter 是干嘛的?
通俗来说:
Text Splitter 就是一个“聪明的剪刀 ✂️”,它把一整段大文本,裁剪成模型可以处理的小段落,并尽量保留上下文逻辑。
✅ 为什么一定要切分?
| 原因 | 举个例子 🌰 |
|---|---|
| 📏 模型有输入长度限制 | 一次最多只能看几千 token |
| 🔍 检索更精准 | 小段落更容易关联关键词 |
| 🧠 上下文更清晰 | 避免模型迷失在长篇大论中 |
| 🧪 后续处理更灵活 | 每段可以独立做嵌入、摘要、问答等操作 |

2、常见的文本切分策略
🧱 1. CharacterTextSplitter —— 纯文本切分砖头式 🧱
📌 按固定字符数切分文本,最基础的策略。
-
优点:简单粗暴,适用于没有结构的纯文本
-
缺点:容易在中间截断句子,影响上下文理解
🧠 适合场景:纯文本日志、没有结构的长段文字
🧠 2. RecursiveCharacterTextSplitter —— 递归智能剪刀 ✂️
📌 优先按段落 > 句子 > 单词 > 字符切分,保持最大完整性。
-
优点:保留语义结构,尽可能避免切断上下文
-
缺点:略比
CharacterTextSplitter慢一些,但更智能
🌟 这是 LangChain 默认推荐使用的切分器!
🧠 适合场景:通用文本、PDF、网页内容、问答任务等
🔡 3. TokenTextSplitter —— 模型视角的切分器 🔍
📌 按 Token 数量切分文本,而不是字符数!
-
优点:精确控制模型的输入上限,避免超出上下文窗口
-
缺点:需要引入 Tokenizer(如 OpenAI 或 HuggingFace)
🔍 每个 token ≈ 0.75 个英文单词,适合多语言文本处理
🧠 适合场景:需要严格控制 token 长度(如 GPT-3.5/4)
📄 4. MarkdownTextSplitter —— Markdown 专用 ✍️
📌 识别标题、列表、代码块等 Markdown 结构,有结构感地切分。
-
优点:支持 Markdown 语法,切分结果更有层次感
-
缺点:不适合非 Markdown 文档
🧠 适合场景:知识库、技术文档、博客文章
🧬 5. SpacyTextSplitter —— 语言学视角的切分器 📚
📌 用 NLP 工具 Spacy 对文本按句子切分,更具语言理解力。
-
优点:语义层面更精细,尤其适合自然语言句子
-
缺点:依赖第三方库,处理速度较慢
🧠 适合场景:高质量问答、摘要、学术文章
🧾 一张表对比:快速选择适合的切分器 ✅
| Splitter 名称 | 切分方式 | 优点 | 适用场景 |
|---|---|---|---|
CharacterTextSplitter | 按字符数切分 | 简单快速 | 纯文本 |
RecursiveCharacterTextSplitter | 递归结构切分 | 最推荐,保留语义 | 通用文档、问答系统 |
TokenTextSplitter | 按 token 数切分 | 精准控制输入 | Token 限制敏感任务 |
MarkdownTextSplitter | 识别 Markdown 结构 | 有层次感 | 技术文档、博客 |
SpacyTextSplitter | 按句子切分 | 更符合语言逻辑 | NLP 高质量处理 |
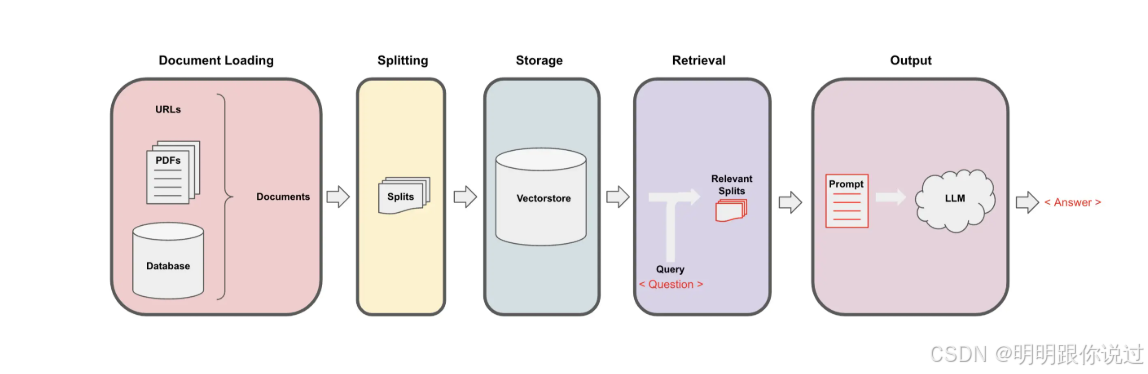
四、实战示例
1、使用 PDFLoader + RecursiveCharacterTextSplitter 构建文档块
🧠 系统目标
构建一个能同时处理:
-
✅ 文本内容(用于问答/摘要)
-
🖼 图片内容(用于图文搜索、OCR 或视觉问答)
🧱 系统组件架构
[PDF 文档]
│
├── PDF 文本块提取 ---> 文本切分(RecursiveCharacterTextSplitter)
│ ↓
│ 文本文档块 (List[Document])
│
├── PDF 图片提取 ---> 图片切片、OCR(可选)
↓
图片数据块 (List[ImageDocument])
│
└── 图文融合文档构建 ---> 图文统一格式:带文本+图片的 Document
↓
最终图文文档块 (List[FusedDocument])
✅ 第一步:提取文本块
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter# 加载 PDF 文本
pdf_loader = PyPDFLoader("example.pdf")
pages = pdf_loader.load()# 切分文本块
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
text_chunks = splitter.split_documents(pages)第二步:提取图片块 + 可选切分/OCR
import fitz # PyMuPDF
from PIL import Image
from io import BytesIOimage_chunks = []doc = fitz.open("example.pdf")for page_num, page in enumerate(doc):images = page.get_images(full=True)for img_index, img in enumerate(images):xref = img[0]base_image = doc.extract_image(xref)image_bytes = base_image["image"]image_ext = base_image["ext"]image = Image.open(BytesIO(image_bytes))# 可选:切分图片或运行 OCRimage_chunk = {"page": page_num + 1,"index": img_index + 1,"image": image,"description": f"第{page_num+1}页的图片{img_index+1}"}image_chunks.append(image_chunk)💡 OCR 可选:可结合
pytesseract提取图片中的文字以增强图文问答。
🔗 第三步:图文融合文档块
我们把图像信息整合进 LangChain 的 Document 中(或自定义类):
from langchain.schema import Documentfused_documents = []# 文本块先入
for chunk in text_chunks:fused_documents.append(chunk)# 图片块转为 Document(注意可自定义内容结构)
for image_data in image_chunks:doc = Document(page_content=f"[图像] {image_data['description']}",metadata={"type": "image","page": image_data["page"],"image_obj": image_data["image"]})fused_documents.append(doc)📌 建议:将图像保存为本地路径或上传后使用 URL,再嵌入 metadata。
🤖 最终用途(示例)
构建向量索引(仅文本内容 + OCR 图像文字):
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings# 只索引文本文档
vectorstore = FAISS.from_documents(text_chunks, OpenAIEmbeddings())问答应用(图文支持):
-
用户提问时,匹配文本块
-
如果命中含图文 metadata 的块,可联动前端展示图片
-
图片块也可通过关键词 OCR 搜索检索
2、多文档加载并批量切分
要实现 多 PDF 文档的批量加载 + 切分(支持后续统一向量化、入库),我们可以使用 PyPDFLoader 或 UnstructuredPDFLoader,配合 RecursiveCharacterTextSplitter 进行统一处理。
下面是完整且实用的代码示例 ✅
🧠 完整代码逻辑:
import os
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter# 设置你的 PDF 文件夹路径
pdf_folder = "./docs"# 初始化空列表收集所有文档
all_documents = []# 遍历目录下所有 PDF 文件
for filename in os.listdir(pdf_folder):if filename.endswith(".pdf"):file_path = os.path.join(pdf_folder, filename)# 加载当前 PDFloader = PyPDFLoader(file_path)documents = loader.load()# 添加文档元信息(可选)for doc in documents:doc.metadata["source_file"] = filenameall_documents.extend(documents)print(f"总共加载了 {len(all_documents)} 个页面 📝")# 切分文档块
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = splitter.split_documents(all_documents)print(f"切分后文档块数: {len(split_docs)} ✅")📌 输出样例:
总共加载了 85 个页面 📝
切分后文档块数: 431 ✅🧰 补充建议
| 功能 | 方法 |
|---|---|
| 📌 元信息添加 | 用于记录文件名、页码等,方便溯源 |
| 🧠 多格式支持 | 用 UnstructuredLoader 支持 Word、HTML、TXT 等 |
| 💾 存入向量库 | 用 FAISS.from_documents() 或 Chroma.from_documents() |
| 🔐 大模型向量化 | 使用 OpenAIEmbeddings、HuggingFaceEmbeddings 等 |
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!