【学习笔记】因果推理导论第1课
因果推理导论第1课 为何要做因果推理
- 一、辛普森悖论
- 一个例子
- 二、相关不代表因果性
- 三、什么揭示因果
- 四、观测研究
- 五、结论
本节课通过
一、辛普森悖论
一个例子
书中举了一个疫情两种治疗方法A,B,分析哪一个治疗方法更好的例子.
- 首先已知B治疗方法更稀缺,因此观测数据样本上,使用A方案VS B方案的大概是7:3;
- 然后已知每个病人在接受治疗时的病情,有两种(mild /severe)
- 最后统计所观测到的数据样本的死亡率,其统计表格如下所示
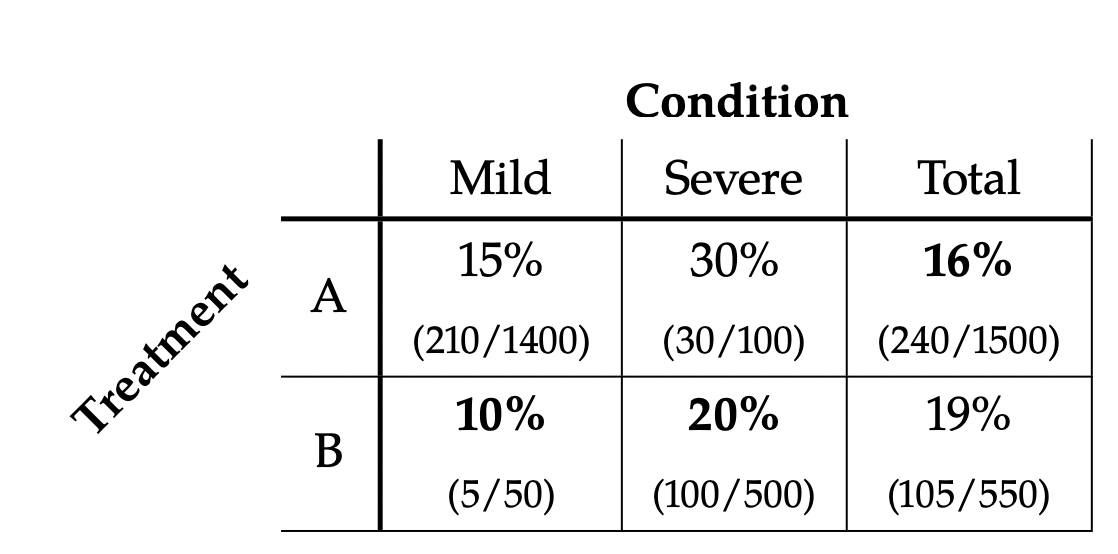
从上表直观的分析可以得出,总体上A方案死亡率更低,A更好;如果区分病情上看,B方案在每个组下的死亡率更低,B更好.这个就是典型的辛普森悖论了.
那么导致这个的原因在于两者的样本数差异,我们可以看到轻度患者主要采用A治疗方案,所以A的总体统计上是这部分在起作用,而重度患者主要采用B治疗方案,所以B的总体统计上是这部分在起作用.ok,原因我们知道了,但是对我们分析目的并无大帮助,因为我们无法改变这一样本分布,因此正确答案是我们需要知道因果结构下,来做分析结论.
如下图所示,图1.1是病情是治疗方法与死亡率的因,那么B方案更好,怎么理解呢,医生根据病情给治疗方案,其重症给治疗方案B,可以看到统计表中B的死亡率更低,假设我们都采取B方案的话,整体的死亡率是要低于A的(轻症小于A,重症也小于A);反过来可以知道B治疗方案与高死亡率相关性更高(使用降低更多死亡率,不应用更高死亡率);那么图1.2是治疗病情与死亡率的因,这种情况选择A更好,其理解上就是,采用何种治疗方案会影响其病情的变化,而病情与治疗都会影响死亡率.
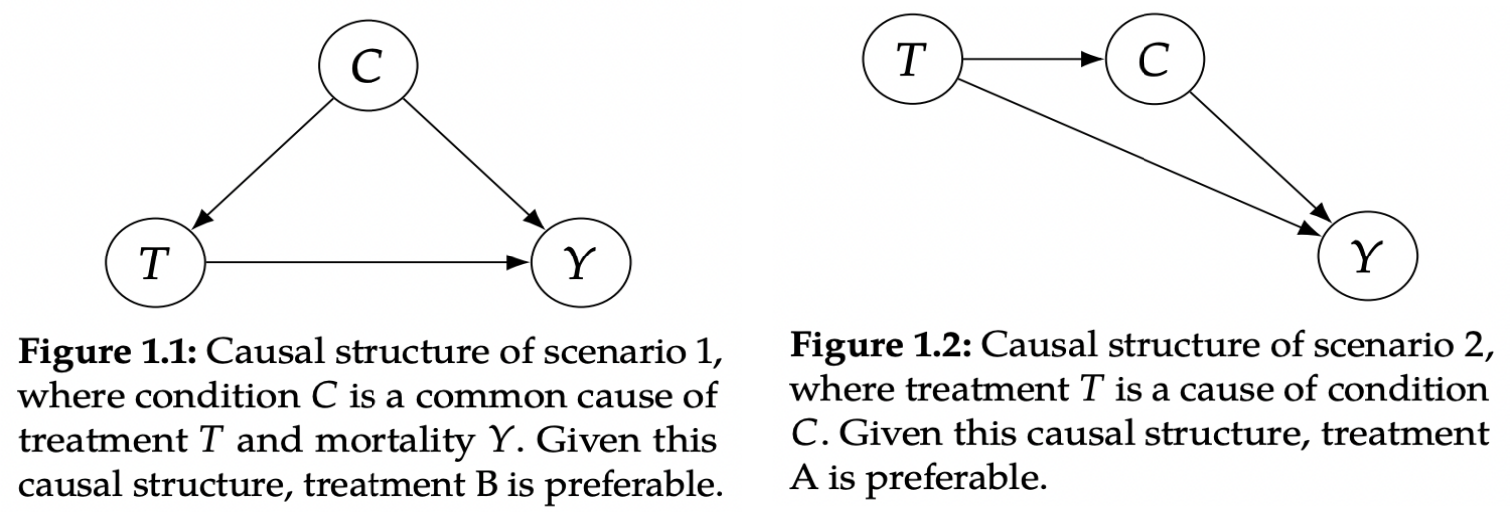
已知B方案更稀缺,因此要使用B方案要等待其是重症患者才使用,这样如果我们选择B治疗方案的话,轻度患者就要等到重症患者才会给治疗,而变成重症了后死亡率要比轻症高的多,且轻症患者体量大,我们可以想象使用B治疗方案,会有大批轻症患者要等待治疗变成重症患者,从而导致重症患者增加与死亡率的提升.因此选择A治疗方案更好.
这个例子就说明了在辛普森悖论下,因果的重要性.
二、相关不代表因果性
同样举一个例子说明,有人发现穿鞋睡第二天大概率会头疼,说明第二天头疼与头一天晚上穿鞋有关,但是他俩是因果关系吗?实际上是因为头一天晚上人喝酒喝多了后大概率会不脱鞋睡觉,而宿醉会让第二天起床的时候头疼,因为我们事先并不知道穿鞋睡的跟头疼的人是不是头天晚上喝酒了,所以我们从直观上只能看到穿鞋睡觉与头疼密切相关,因此相关关系中通常混合了因果关系与其它的一些相关因素.
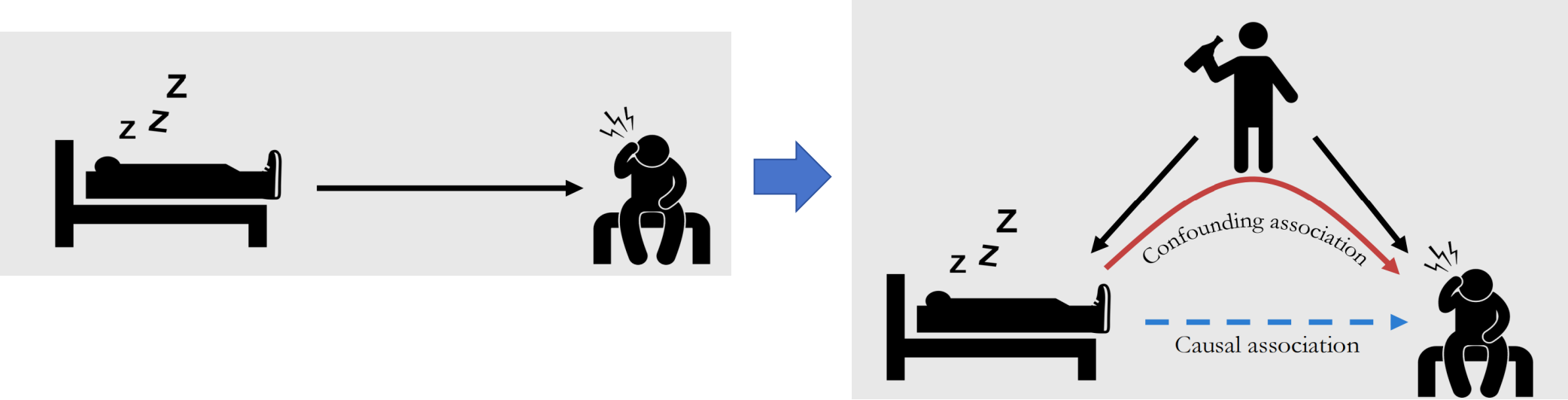
正因为相关不等于因果,如此我们才需要做因果推理来揭露事件内部根因,来做出有效的决策与措施.
三、什么揭示因果
在这之前我们先介绍一个词潜在结果,比如我们头疼,吃了药就好了,没有吃药就继续疼,直觉告诉我们药能治头疼(是因果作用),如果吃了药还是头疼,那这药就不能治头疼(不是因果作用).这就是潜在的结果.
我们如果将其用数学进行表示,这样因果效应可以通过是否吃药的效果相减得到.但是在实际操作中一个人吃了药,就没有办法观测到他不吃药的效果;不吃药又观测不到吃了药的效果,这个就是因果推理中的根本问题

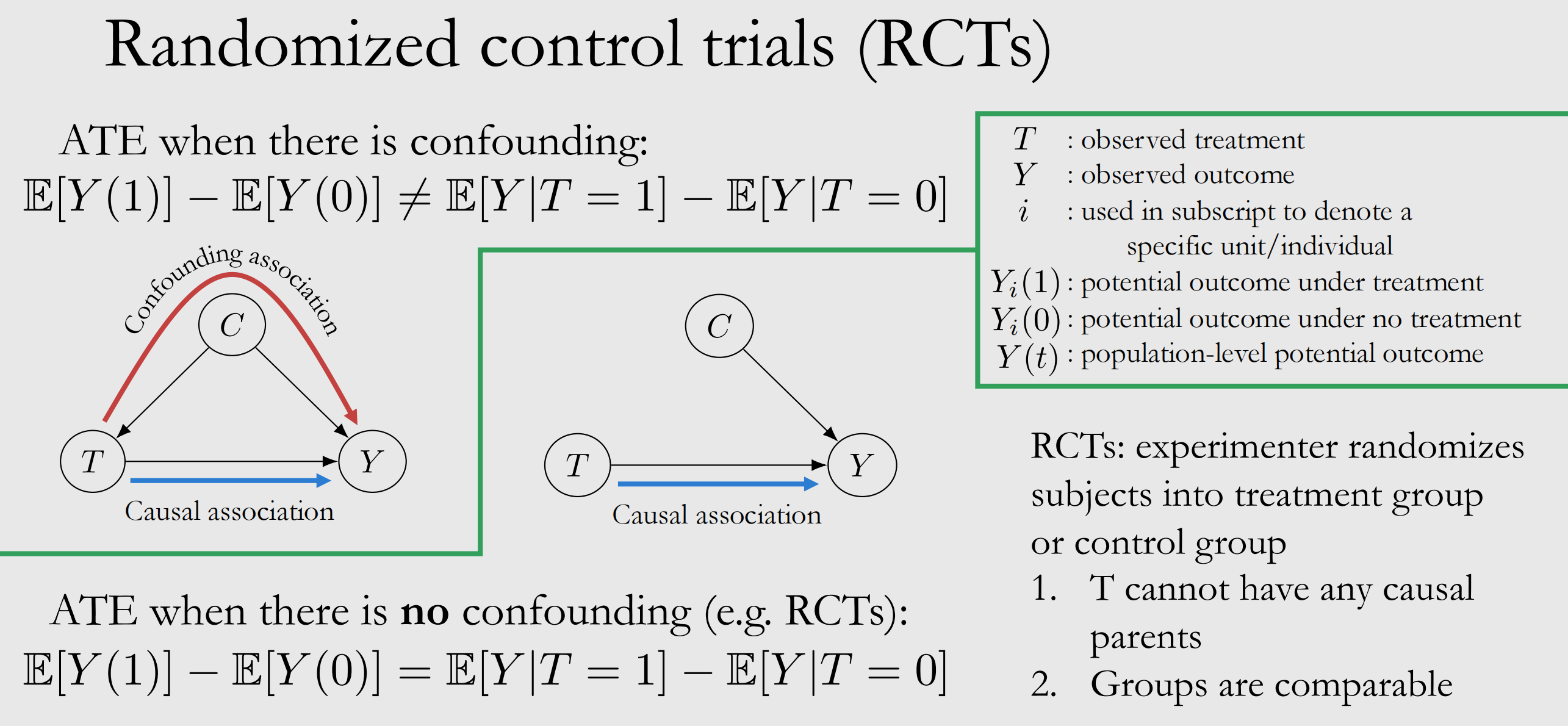
因此我们就通过计算平均治疗效果来解决这个问题,其计算如下图表示,其均值就等于治疗的期望减去不治疗的期望,但是实际中我们只能观测得到治疗后与不治疗的结果,并不能直接得到治疗的效果与不治疗的效果;观测的结果即为条件期望,如果这俩期望相等的话我们就能直接计算得到因果效应了,很不幸的是,这俩通常不相等,这是因为我们的观测中通常混杂了多个因素,如下图所示我们采取治疗T时,治疗本身受到了C的影响,此时在T条件下的观测就混杂了多个因素.

那么我们如果将T与C的联系切断,即剔除了混杂因素的影响,这样是不是就可以满足条件期望等于期望了?如下图所示,绿线下方便是通过随机性分组,实现了两者的相等.下面举个例子来理解这个为什么随机性可以使得其相等,以喝酒为C,是否穿鞋睡觉为T,Y为是否头疼;我们前面说T与Y的相关是混杂因素的,因为喝酒的人大概率会穿鞋睡觉,喝酒的人第二天大概率会头疼,喝酒这个因素影响了两者的关系;如果这个时候我们在喝酒与不喝酒人群中都随机选择穿鞋睡觉,这样穿鞋与不穿鞋两组人群就不再受到喝酒影响,两组人群就具备了可比较性,从而使得等式相等.这表明我们做好随机性的控制实验,条件期望将等于期望.
四、观测研究
第三点说到做好随机实验可很方便的算出因果效应,但是实际应用的,往往很难实现随机实验,比如验证抽烟对肺癌的影响,我们不能强迫人们去抽烟吧;再比如看基因对乳腺癌的影响,我们也无法随机改变基因的构成.因此由于道德约束,经费限制,不可划分,无法实现等原因会让我们无法做到随机实验.
进而我们只能针对能观测得到的信息进行因果推理,那么对观测进行研究就很有必要了.
从前面我们知道观测到的相关混杂了其他因素,如果我们能控制这部分混杂的因素,且这部分因素能够得到,那么就有办法将其影响消除,从而得到因果效应,其具体调整方法如下图所示:
- 首先混杂因素用W来表示,那么条件w下使用t治疗的效果期望等于条件w,t治疗方法下的效果期望
- 然后目标是要求t治疗的效果期望,因此要消除W的影响,通过求取w的边际期望可以得到,其公式如第2个公式所示

这样,我们就可以计算因果效应E[Y(1)]-E[Y(0)].
还记得我们开头的那个疫情按例吗?我们使用这个案例来计算一下A,B方案的治疗效应,其中混杂因素就是病情轻度与重度,求该边际期望就是计算混杂因素的概率乘以其因素与治疗下的观测效果,以红色框为例,是计算重度因素下的期望 - 首先所有因素下的样本为2050,其中重度样本为600 ,因此重度因素的概率为600/2050
- 然后在重度因素下采用不同的治疗其效果如左侧红色框所示,其边际计算如右侧红框所示
- 最后的总计算得到B方案更好.
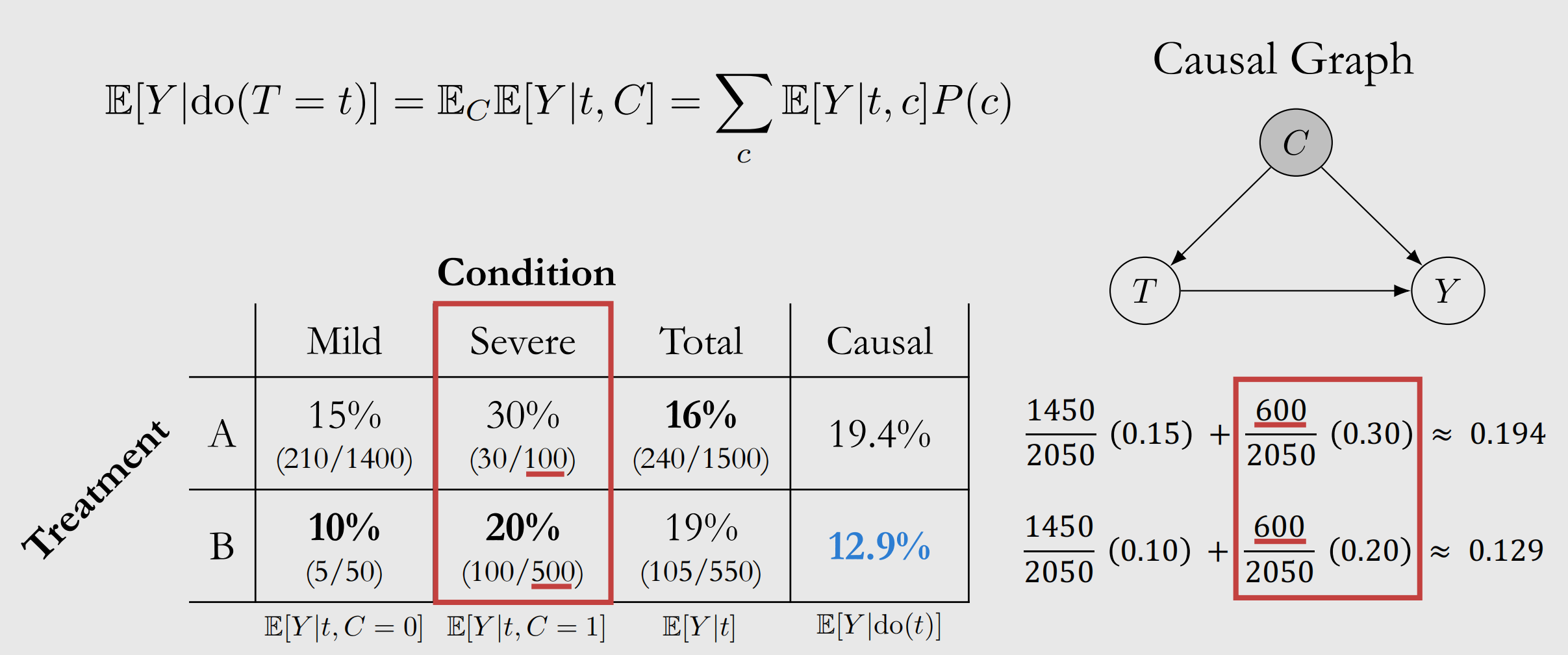
进一步看原先版本与最新版本的计算差别,原先版本可以看到不同因素的概率是不一样的,A B治疗的分母也不一样,从数据表现上也可以看到这就是为什么原来的直观计算混杂了其它因素,导致结论出现偏差.

五、结论
本节课说明了因果推理的动因是观测到的相关不等于因果,然后解释了为什么相关不等于因果,因为相关中混杂了其他因素;随后说明了可以通过随机实验剔除掉混杂因素,但是实际应用中很难实现;因此引出了通过控制混杂因素使用观测数据计算因果的直观方法,并通过疫情治疗的例子进一步理解.