Python爬虫入门
爬虫(Web Crawler),也称为网络爬虫或蜘蛛程序,是一种自动从互联网上抓取数据的程序。它通过模拟人类浏览网页的行为访问网站的页面,提取页面中的信息,并将其存储到本地或数据库中。爬虫广泛应用于搜索引擎、数据分析、内容推荐等领域。
一个简单的Python爬虫通常包括以下几个步骤:
1.发送请求。使用requests或requests_html等库向目标网站发送HTTP请求,获取网页内容。
2.解析网页。使用BeautifulSoup或lxml等库解析网页内容,提取所需的数据。
3.存储数据。将提取的数据存储到本地文件或数据库中。
发送请求
import requests #requests是一个流行的HTTP库,用于发送网络请求,简单易用
r=requests.get("https://blog.csdn.net/2402_88126487?spm=1000.2115.3001.5343")#发送request请求返回的r是一个response类的实例,代表服务器给我们的响应
print(r) #会得到响应 <Response [200]> 200是状态码响应实例包含的属性有:
r.status_code #响应的状态码,返回200代表请求成功
r.headers #返回的http的headers
r.encoding #可以查看以及变更当前编码
r.encoding='utf-8' #若网页中文乱码则手动设置编码
r.text #返回的网页内容 (通常返回的是网页的HTML代码)http的请求头(headers,数据类型是字典,各个键值对对应我们要传入的信息)会包含一些传送给服务器的信息。当我们正常通过浏览器浏览网页时,浏览器会发送get请求,请求头的User-Agent带有浏览器的类型及版本还有电脑的操作系统等;用requests库的函数发送请求时也会自动生成headers(但不会带有浏览器相关信息),服务器可能会以此判断请求是来自浏览器还是程序。有些网站只想服务真正的用户,会根据User-Agent拒绝来自程序的请求,此时我们可以篡改headers的User-Agent属性帮我们把爬虫程序伪装成正常浏览器,可以绕过简单的反爬机制
普通网站一般不需要设置请求头,都是可以爬取的,本人是爬取了太多次这个豆瓣网,被反爬住了,此时要设置一下。以下是一个简单的代码示例
import requests #导包
url="https://movie.douban.com/top250?start=0" #目标网站
#定义请求头
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}
r=requests.get(url, headers=headers) #发送请求
if r.status_code!=200: #请求失败raise Exception("error")
print(r.text) #网页源代码(str类型)一个网页有三大技术要素:HTML(定义网页的结构与信息)、CSS(定义网页样式)、JavaScript(定义用户与网页的交互逻辑)
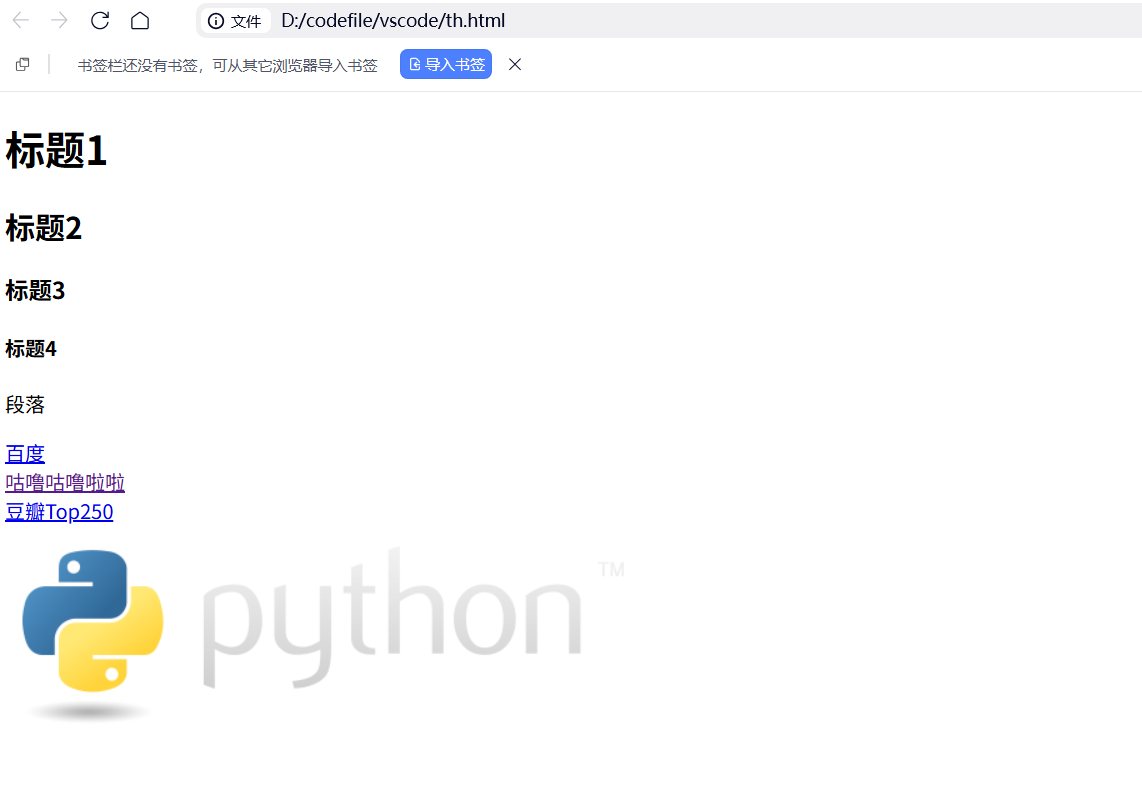
我们爬虫时最关心的是网页上的数据信息,所以主要是和HTML打交道,一个简单朴素的html如下,<>里的是HTML标签,大多数标签都是成对出现的,前一个为起始标签,后一个带'/'的是闭合标签。起始标签+闭合标签+它们之间的内容可以被看作是一个HTML元素,<html>标签是HTML文档的根,所有其它元素都要放到这个元素的里面。
<!DOCTYPE HTML> <!--告知浏览器这个文件的类型是HTMLl-->
<html> <!--整个HTML文档--><head> <!--文档头--><mata http-quiv=Content-Typr contnt="text/html;charset=utf-8"> <!--描述网页文档的属性--><title>网页标签</title> <!--文档标题--></head><body> <!--文档的主体内容--><h1>标题1</h1> <!--一级标题--><h2>标题2</h2> <!--二级标题--><h3>标题3</h3><h4>标题4</h4><div id="content" class="default"> <!--块元素--><p>段落</p> <!--文本的段落(不同<p>默认进行换行)--><a href="http://www.baidu.com">百度</a><br> <!--<a>是超链接标签,<br>是换行标签--><a href="https://blog.csdn.net/2402_88126487?spm=1000.2115.3001.5343">咕噜咕噜啦啦</a><br><a href="https://movie.douban.com/top250?start=0">豆瓣Top250</a><br> <img src="http://www.python.org/static/img/python-logo.png"/> <!--图片--></div></body>
</html>想知道自己写的HTML文档长什么样,可以用编辑器(如著名的vscode,其实它也可以写python)写一个.html后缀的文件,然后通过浏览器打开即可
| 其它常见标签 | 属性 | 用途 |
|---|---|---|
| <b>,<I>,<u> | 加粗,斜体,下划线 | |
| <span> | 行内元素(容器,可以把其它元素放入) | |
| <img> | scr(表示图片的路径) | 图片 |
| <a> | href(跳转的url地址) | 超链接 |
| <ol>,<ul> | 有序列表,无序列表(里面的元素都要用<li>标签) | |
| <li> | 列表元素 | |
| <table> | 表格 |
解析网页
BeautifulSoup是一个用于解析HTML和XML文档的库,它提供了简单易用的API(应用程序编程接口),把看起来混乱的HTML内容解析成树状结构,方便我们从网页中提取数据。
from bs4 import BeautifulSoup #从bs4库引入BeautifulSoup类
import requests
content=requests.get("https://www.baidu.com/").text
soup=BeautifulSoup(content,"html.parser") #创建BeautifulSoup对象,BeautifulSoup(html字符串,html解析器,html文档的编码)#BeautifulSoup除了能解析html之外还能解析一些其它类型的内容,所以需要第二个参数指定解析器
BeautifulSoup实例包含许多属性和方法
soup.p #返回HTML里的第一个p元素(连带其所包含的内容)
soup.img #返回第一个img元素
soup.find() #查找第一个匹配的标签,返回第一个匹配的标签对象
soup.find_all() #查找所有匹配的标签,返回一个包含所有匹配标签的列表
p=soup.find('p')
text=p.get_text() #提取标签中的文本内容这是一个百度主页页面,我们来试着提取出网页上显示的所有热搜的排名、文本内容和超链接
(提前声明,这个任务失败,将在后期再解决,若想短期入门请跳至下一个任务)

查看网页源代码,分析想要信息的特点
右键,点击“检查” 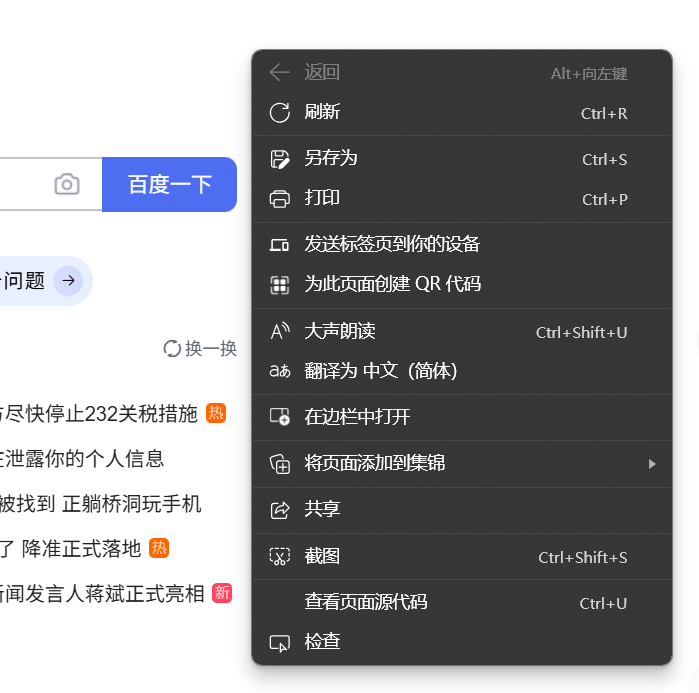
“查看网页源代码”也能查看源代码,但是“检查”可以直接定位到元素,如下图,移动鼠标会显示对应的网页元素

点击左上角的“箭头”图标还可以直接返回到网页元素对应的源代码
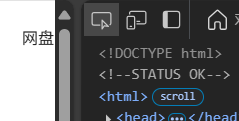
可以发现,热搜信息在<div id="s-hotsearch-wrapper" ……</div>这个区域块里面。html中一个节点如果有id属性,则是全局唯一的,class则不是全局唯一的 ,所以我们可以通过id直接定位到这个区域块(一个网页中会有许多重复的标签,有时要一步步精准定位)。还可以观察到一条热搜信息存储在一个<li>标签中,超链接在<a>标签,排名和文本内容分别在两个<span>标签

那么就可以开始编写代码了
from bs4 import BeautifulSoup
import requests
r=requests.get("https://www.baidu.com/")
if r.status_code!=200:raise Exception("error")
content=r.text
soup=BeautifulSoup(content,"html.parser")
rs=soup.find('div',id="s-hotsearch-wrapper")
print(rs.get_text())
写到这我运行了一下代码,出现如下报错,分析地没有问题啊,怎么会这样呢?
>>> %Run -c $EDITOR_CONTENT
Traceback (most recent call last):File "<string>", line 10, in <module>
AttributeError: 'NoneType' object has no attribute 'get_text'
>>> #rs的值为None,这意味着soup.find('div', id="s-hotsearch-wrapper")没有找到匹配的元素这是因为百度首页的HTML结构已经发生变化,导致你指定的id不再有效。百度的部分内容是通过JavaScript动态加载的(隔段时间刷新一下就改变了),而requests库无法获取这些动态内容。
如何解决,我们下不知道多少期再见~
抱歉抱歉,我应该提前想到的,百度热搜页面肯定是动态加载的呀,十分抱歉。回来回来,那我们再来个可静态爬取的网站,我找到了个专门给人练习爬虫的网站
All products | Books to Scrape - Sandbox
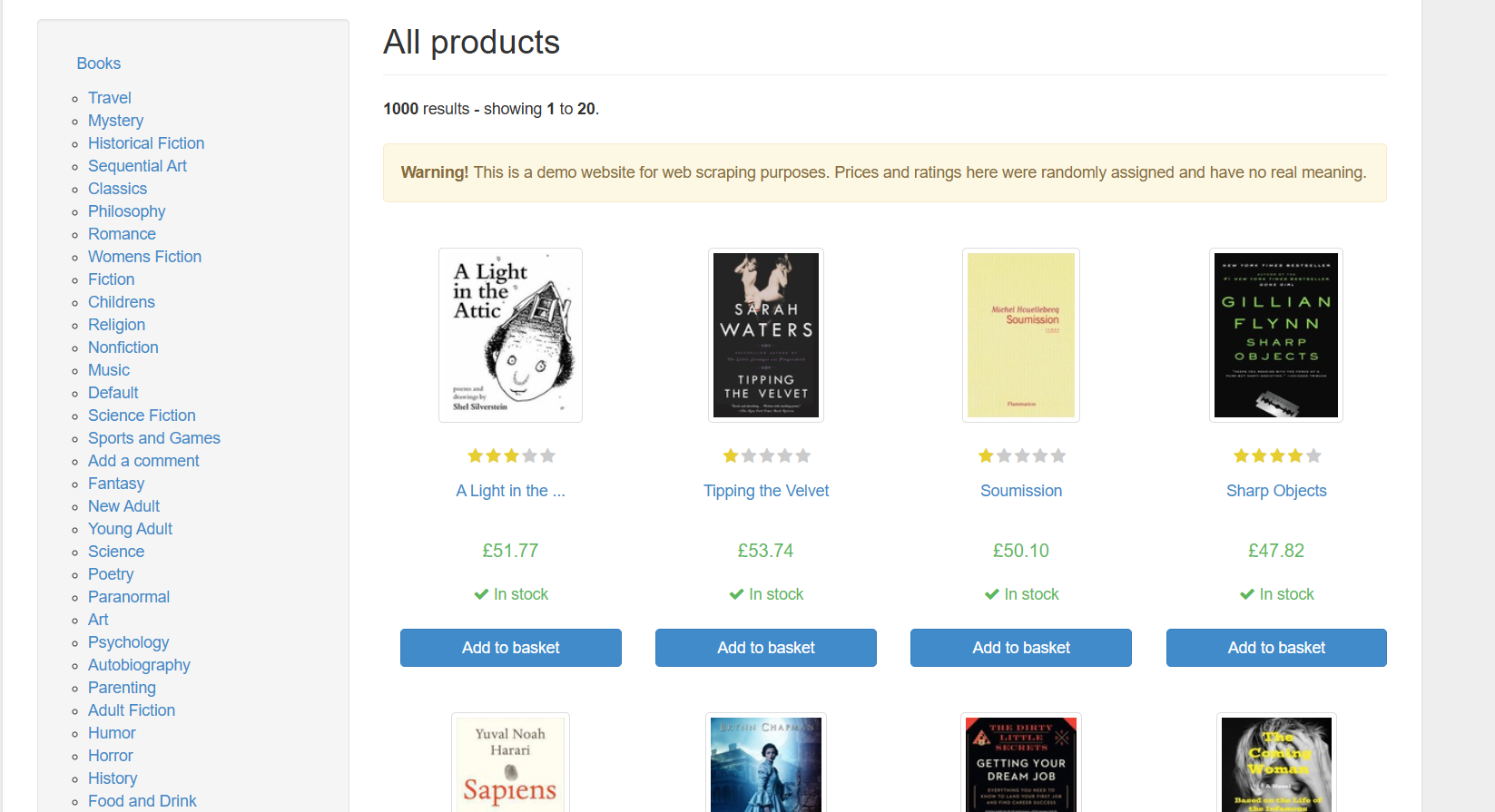
我们来试着爬取第一页所有的书名和价格
点击箭头,快速定位到想提取元素位置
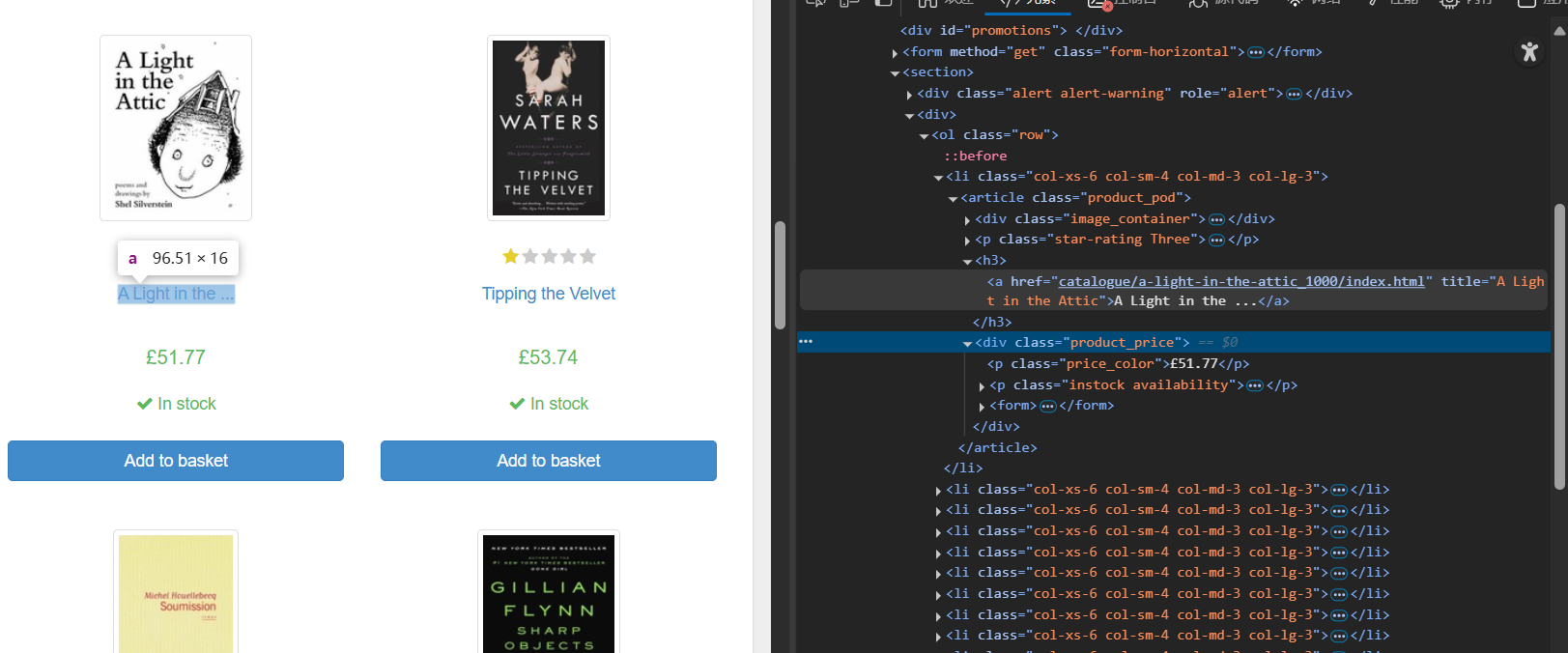
可以发现,所有书名都是在<h3>标签下的<a>标签中,价格都是在class属性为"price_color"的<p>标签中,可以编写代码了
import requests
from bs4 import BeautifulSoup
r=requests.get("http://books.toscrape.com/")
if r.status_code!=200:raise Exception("error")
content=r.text
soup=BeautifulSoup(content,"html.parser")
books=[['书名','价格']] #二维列表存储数据
titles=[]
prices=[]
all_articles=soup.find_all('h3') #返回一个包含所有h3元素的列表
for article in all_articles: #遍历所有h3元素,找到它之下的a元素,获取其中文字title=article.find('a').get_text()titles.append(title)
all_price=soup.find_all('p',class_="price_color") #class加一个_,与python内置的class区分
for price in all_price:prices.append(price.get_text()) #返回文本内容(若不想要货币符号,可以用字符串切片price.get_text()[2:])
for i in range(len(titles)):books.append([titles[i],prices[i]])
import pprint #可以漂亮地打印我们的数据
pprint.pprint(books)运行结果如下

再来一种更简洁的写法(观察到每本书的信息都在article标签中)
import requests
from bs4 import BeautifulSoup
r=requests.get("http://books.toscrape.com/")
if r.status_code!=200:raise Exception("error")
content=r.text
soup=BeautifulSoup(content,"html.parser")
books=[['书名','价格']]
all_articles=soup.find_all('article')
for article in all_articles: title=article.find('h3').find('a').get('title') #完整的书名应该在a标签的title属性price=article.find('p',class_="price_color").get_text()books.append([title,price])
import pprint
pprint.pprint(books)
存储数据
我们可以直接用二维列表存储,也可以写到文件里,但现实中更常用的是写到一个Excel表里去
pandas是一个强大的数据分析库,它提供了方便的数据操作和导出功能(接着上面的代码)
import pandas as pd #导入pandas库,并给它起了一个别名pd
data=pd.DataFrame(books) #.DataFrame()是pandas库中的一个函数,用于创建一个DataFrame对象,DataFrame是二维表格型数据结构,类似于SQL表或Excel表格,有行索引和列索引
data.to_excel('书目名称与价格.xlsx') #to_excel()是DataFrame对象的一个方法,用于将DataFrame导出为Excel文件表格展示如下
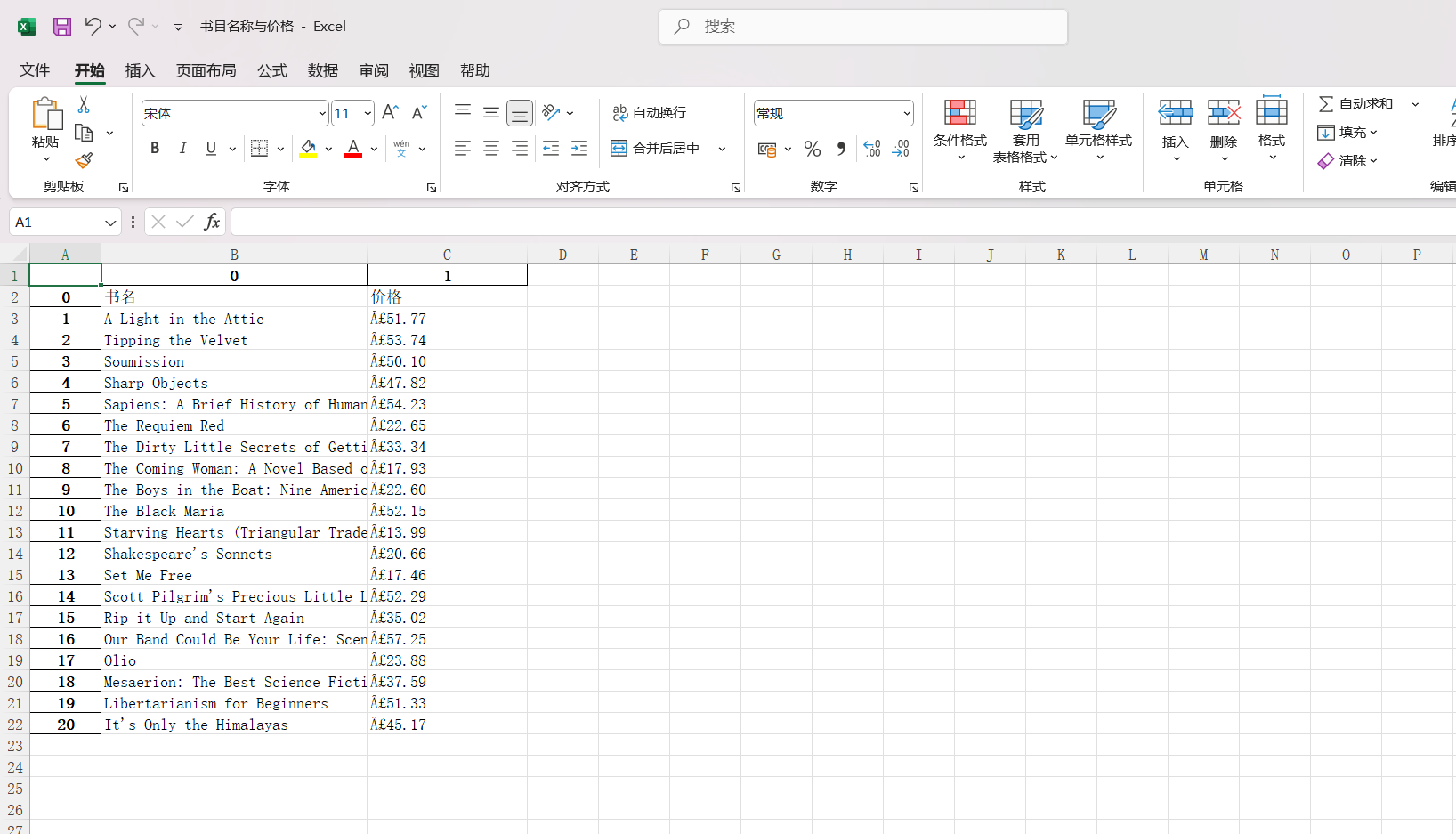
好啦,那你已经会写一个简单的爬虫程序咯~~~
拓展
我们前面只是爬取了第一页的数据,而这个网站总共有50页,每页20本书籍信息。我们来试着爬取前10页所有书籍的信息并将价格最高的前20本书存储到表格中
(主播试了50页,直接timeout转也转不出来,以后进步到更高阶了再分享方法给大家吧)
可以观察到,每页的url基本一致,就是page-后面的数字改了一下
 那么我们可以通过一下代码得到所有页面的url
那么我们可以通过一下代码得到所有页面的url
import requests
for n in range(1,11):url=f"http://books.toscrape.com/catalogue/page-{n}.html" #格式化字符串(f-string),{n}会被替换为循环变量n的值r=requests.get(url)整体代码如下,其实就是+了点pandas库的使用,还是简单的吧
import requests
from bs4 import BeautifulSoup
import pandas as pd
books=[]
def get_htmls(): #获取所有页面的htmlhtmls=[]for n in range(1,11):url=f"http://books.toscrape.com/catalogue/page-{n}.html" #格式化字符串(f-string),{n}会被替换为循环变量n的值r=requests.get(url)if r.status_code!=200:raise Exception("error")htmls.append(r.text)return htmlsdef parser_single_html(html): #解析单个html,添加数据soup=BeautifulSoup(html,"html.parser")all_articles=soup.find_all('article') for article in all_articles: title=article.find('h3').find('a').get_text() price=article.find('p',class_="price_color").get_text()books.append([title,price])htmls=get_htmls()
for html in htmls: parser_single_html(html)#解析所有页面df=pd.DataFrame(books,columns=['书名','价格']) #设置列名
#df.columns=['书名','价格'] 也可以通过属性设置
top20=df.sort_values(by='价格',ascending=False)[0:20] #使用sort_values方法,按“价格”降序排序,取前20个
top20.to_excel('Top20.xlsx')
表格展示如下
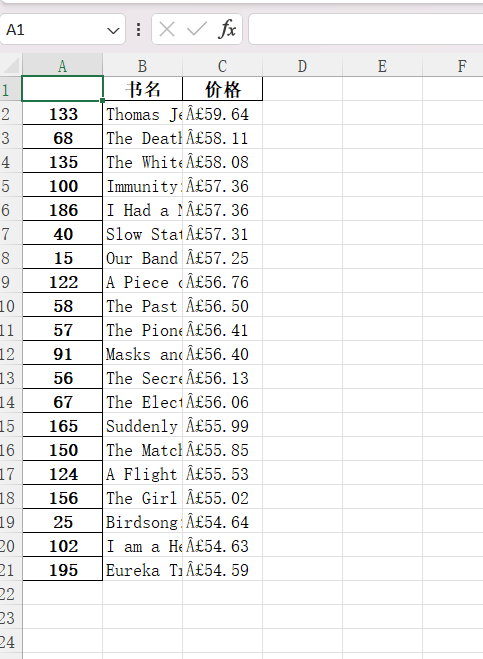
行索引为书籍原来的序号,若想重新设置行索引可添加以下代码
top20.reset_index(drop=True) #重新生成从0开始的索引(覆盖原索引)#若想生成从1开始
top20=top20.reset_index(drop=True)
top20.index+=1
#或者
top20.index=range(1,21)