Linux操作系统实战:中断源码的性能分析(转)
Linux中断是指在Linux操作系统中,当硬件设备或软件触发某个事件时,CPU会中断正在执行的任务,并立即处理这个事件。它是实现实时响应和处理外部事件的重要机制,Linux中断可以分为两种类型:硬件中断和软件中断(也称为异常)。硬件中断是由外部设备引发的,如磁盘I/O完成、网络数据包到达等;而软件中断是由CPU内部产生的,如除零错误、页面故障等。
当一个中断被触发时,CPU会根据预定义好的中断向量表找到相应的处理程序,并跳转执行该程序。在Linux内核源码中,各种硬件设备及其对应的中断处理程序都有相应的驱动程序进行管理,通过对Linux中断源码分析,可以深入了解内核是如何管理和响应不同类型的中断,在调试和性能优化方面也具有重要作用。同时,掌握 Linux 中断机制对于编写高性能、稳定的驱动程序以及理解操作系统内核运行原理非常有帮助。
一、Linux中断系统概述
在 Linux 系统的庞大体系中,中断系统犹如其 “神经系统”,占据着核心地位。它是硬件与软件之间进行高效交互的关键桥梁,对系统的响应性以及并发处理能力起着决定性作用。当系统中的硬件设备需要及时处理某些事件时,中断机制便会迅速发挥作用,促使 CPU 暂停当前正在执行的任务,转而优先处理这些紧急事务,处理完成后再返回原任务继续执行。这种机制确保了系统能够快速响应外部事件,极大地提升了系统的并发处理能力和整体性能。
1.1 中断基础概念
中断,简单来说,是指计算机在执行程序的过程中,当遇到急需处理的事件时,会暂停当前正在运行的程序,转去执行相应的服务程序,待处理完毕后再自动返回原程序继续执行,这一过程就称为中断。从硬件层面来看,中断是由硬件设备产生的电子信号,这些信号通过中断请求线(IRQ)发送到中断控制器,再由中断控制器将其传递给 CPU。例如,当键盘有按键被按下时,键盘控制器会立即产生一个中断信号,通过特定的中断请求线发送给中断控制器,进而通知 CPU 有按键事件需要处理。
从软件层面分析,当中断信号被 CPU 接收后,CPU 会暂停当前执行的指令,保存当前程序的执行状态(如寄存器的值、程序计数器的值等)到堆栈中,然后跳转到对应的中断处理程序(ISR,Interrupt Service Routine)去执行相应的处理操作。中断处理程序完成任务后,会从堆栈中恢复之前保存的程序执行状态,使 CPU 继续执行原来被中断的程序。在整个系统运行过程中,中断扮演着至关重要的角色,它使得 CPU 能够及时响应各种外部设备的请求,实现了硬件与软件之间的高效协同工作,避免了 CPU 对外部设备状态的持续轮询,大大提高了系统的效率和资源利用率。
1.2 Linux 中断的分类
在 Linux 系统中,中断主要分为硬件中断和软件中断两大类,它们各自具有独特的特点和应用场景。
硬件中断:硬件中断是由外部硬件设备(如键盘、鼠标、网卡、硬盘等)触发的中断。其特点是异步性,即可能在任何时间发生,不受 CPU 控制。硬件中断具有较高的优先级,一旦发生,会立即打断 CPU 当前正在执行的任务,使 CPU 迅速响应并处理相应的事件。例如,当网卡接收到网络数据包时,会立即产生一个硬件中断,通知 CPU 有新的数据需要处理。硬件中断在系统中的应用场景非常广泛,涵盖了各种外部设备与 CPU 之间的交互。在实时控制系统中,传感器的数据采集设备通过硬件中断及时将采集到的数据传递给 CPU 进行处理,确保系统能够对外部环境的变化做出快速响应。
软件中断:软件中断则是由软件指令触发的中断,它是一种在操作系统内部使用的中断机制,用于实现系统调用、任务调度、定时器处理等功能。软件中断通常是由内核在特定情况下主动触发的,其优先级相对较低。例如,当用户程序需要调用系统函数(如文件读写、进程创建等)时,会通过软中断指令(如 x86 架构中的 int 0x80 或 syscall 指令)将用户态切换到内核态,内核根据调用号找到对应的系统调用处理函数进行处理,处理完成后再返回用户态。软件中断在操作系统的任务调度方面发挥着重要作用。内核通过软件中断来实现进程的上下文切换,当一个进程的时间片用完或者有更高优先级的进程需要运行时,内核会触发软件中断,暂停当前进程的执行,保存其上下文信息,然后调度其他进程运行。
1.3可编程中断控制器(PIC、APIC)
为了方便说明,这里我们将PIC和APIC统称为中断控制器。中断控制器是作为中断(IRQ)和CPU核之间的一个桥梁而存在的,每个CPU内部都有一个自己的中断控制器,中断线并不是直接与CPU核相连,而是与CPU内部或外部的中断控制器相连。而为什么叫做可编程中断控制器,是因为其本身有一定的寄存器,CPU可以通过操作设置中断控制器屏蔽某个中断引脚的信号,实现硬件上的中断屏蔽。中断控制器也可以级联提供更多的中断线,具体如下:
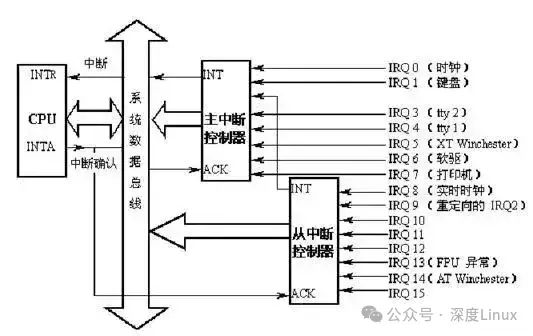
如上图,CPU的INTR与中断控制器的INT相连,INTA与ACK相连,当一个外部中断发生时(比如键盘中断IRQ1),中断控制器与CPU交互操作如下:
-
IRQ1发生中断,主中断控制器接收到中断信号,检查中断屏蔽寄存器IRQ1是否被屏蔽,如果屏蔽则忽略此中断信号。
-
将中断控制器中的中断请求寄存器对应的IRQ1位置位,表示收到IRQ1中断。
-
中断控制器拉高INT引脚电平,告知CPU有中断发生。
-
CPU每执行完一条指令时,都会检查INTR引脚是否被拉高,这里已被拉高。
-
CPU检查EFLAGS寄存器的中断运行标志位IF是否为1,若为1,表明允许中断,通过INTA向中断控制器发出应答。
-
中断控制器接收到应答信号,将IRQ1的中断向量号发到数据总线上,此时CPU会通过数据总线读取IRQ1的中断向量号。
-
最后,如果中断控制器需要EOI(End of Interrupt)信号,CPU则会发送,否则中断控制器自动将INT拉低,并清除IRQ1对应的中断请求寄存器位。
在linux内核中,用struct irq_chip结构体描述一个可编程中断控制器,它的整个结构和调度器中的调度类类似,里面定义了中断控制器的一些操作,如下:
struct irq_chip {/* 中断控制器的名字 */const char *name;/* 控制器初始化函数 */unsigned int (*irq_startup)(struct irq_data *data);/* 控制器关闭函数 */void (*irq_shutdown)(struct irq_data *data);/* 使能irq操作,通常是直接调用irq_unmask(),通过data参数指明irq */void (*irq_enable)(struct irq_data *data);/* 禁止irq操作,通常是直接调用irq_mask,严格意义上,他俩其实代表不同的意义,disable表示中断控制器根本就不响应该irq,而mask时,中断控制器可能响应该irq,只是不通知CPU */void (*irq_disable)(struct irq_data *data);/* 用于CPU对该irq的回应,通常表示cpu希望要清除该irq的pending状态,准备接受下一个irq请求 */void (*irq_ack)(struct irq_data *data);/* 屏蔽irq操作,通过data参数表明指定irq */void (*irq_mask)(struct irq_data *data);/* 相当于irq_mask() + irq_ack() */void (*irq_mask_ack)(struct irq_data *data);/* 取消屏蔽指定irq操作 */void (*irq_unmask)(struct irq_data *data);/* 某些中断控制器需要在cpu处理完该irq后发出eoi信号 */void (*irq_eoi)(struct irq_data *data);/* 用于设置该irq和cpu之间的亲和力,就是通知中断控制器,该irq发生时,那些cpu有权响应该irq */int (*irq_set_affinity)(struct irq_data *data, const struct cpumask *dest, bool force);int (*irq_retrigger)(struct irq_data *data);/* 设置irq的电气触发条件,例如 IRQ_TYPE_LEVEL_HIGH(电平触发) 或 IRQ_TYPE_EDGE_RISING(边缘触发) */int (*irq_set_type)(struct irq_data *data, unsigned int flow_type);/* 通知电源管理子系统,该irq是否可以用作系统的唤醒源 */int (*irq_set_wake)(struct irq_data *data, unsigned int on);void (*irq_bus_lock)(struct irq_data *data);void (*irq_bus_sync_unlock)(struct irq_data *data);void (*irq_cpu_online)(struct irq_data *data);void (*irq_cpu_offline)(struct irq_data *data);void (*irq_suspend)(struct irq_data *data);void (*irq_resume)(struct irq_data *data);void (*irq_pm_shutdown)(struct irq_data *data);void (*irq_calc_mask)(struct irq_data *data);void (*irq_print_chip)(struct irq_data *data, struct seq_file *p);int (*irq_request_resources)(struct irq_data *data);void (*irq_release_resources)(struct irq_data *data);unsigned long flags;
};二、中断管理机制剖析
深入探究 Linux 中断管理机制,如同探索一座精密而复杂的 “机械迷宫”,其底层原理涵盖多个关键方面,包括中断向量表与中断描述符的协同工作、中断请求队列的高效管理以及中断上下文与进程上下文的清晰界定。这些要素相互配合,确保 Linux 系统在面对各种中断请求时,能够有条不紊地协调系统资源,实现高效稳定的运行。
2.1 中断向量表与中断描述符
中断向量表在 Linux 中断管理中扮演着 “索引目录” 的关键角色,它是一个由中断向量组成的数组,每个中断向量都对应着一个唯一的中断号,这些中断号就像是一个个 “页码”,指向特定的中断处理程序。在 x86 架构中,中断向量表的大小通常为 256 个表项,其中 0 - 31 号向量被系统保留,用于处理 CPU 内部的异常和特殊中断,如除零错误、页面错误等;32 - 255 号向量则用于外部设备的中断。中断向量表的主要功能是为中断处理提供快速的索引,当硬件设备产生中断信号时,CPU 通过中断控制器获取中断号,然后以这个中断号作为索引,在中断向量表中迅速定位到对应的中断处理程序入口地址,从而实现对中断的快速响应。
PU把中断向量表的向量类型分为三种类型:任务门、中断门、陷阱门。CPU为了防止恶意程序访问中断,限制了中断门的权限,而在某些时候,用户程序又必须使用中断,所以Linux把中断描述符的中断向量类型改为了5种:中断门,系统门,系统中断门,陷阱门,任务门。这个中断向量表的基地址保存在idtr寄存器中。
-
中断门:用户程序不能访问的CPU中断门(权限字段为0),所有的中断处理程序都是这个,被限定在内核态执行。会清除IF标志,屏蔽可屏蔽中断。
-
系统门:用户程序可以访问的CPU陷阱门(权限字段为3)。我们的系统调用就是通过向量128(0x80)系统门进入的。
-
系统中断门:能够被用户进程访问的CPU陷阱门(权限字段为3),作为一个特别的异常处理所用。
-
陷阱门:用户进程不能访问的CPU陷阱门(权限字段为0),大部分异常处理程序入口都为陷阱门。
-
任务门:用户进程不能访问的CPU任务门(权限字段为0),''Double fault"异常处理程序入口。
当我们发生异常或中断时,系统首先会判断权限字段(安全处理),权限通过则进入指定的处理函数,而所有的中断门的中断处理函数都是同一个,它首先是一段汇编代码,汇编代码操作如下:
-
执行SAVE_ALL宏,保存中断向量号和寄存器上下文至当前运行进程的内核栈或者硬中断请求栈(当内核栈大小为8K时保存在内核栈,若为4K,则保存在硬中断请求栈)。
-
调用do_IRQ()函数。
-
跳转到ret_from_intr,这是一段汇编代码,主要用于判断是否需要进行调度。
中断描述符则是连接中断向量与中断处理程序的 “桥梁”,它包含了丰富的信息,用于详细描述中断的属性和处理方式。每个中断向量都有一个与之对应的中断描述符,这些描述符通常存储在中断描述符表(IDT,Interrupt Descriptor Table)中。中断描述符主要包含以下关键信息:段选择子,用于指定中断处理程序所在的代码段;
偏移量,指示中断处理程序在代码段中的具体位置;访问权限和标志位,这些信息用于控制中断的优先级、特权级以及中断处理过程中的一些特殊行为,如中断是否可屏蔽、是否会导致任务切换等。通过这些信息,中断描述符为 CPU 提供了准确的指令,使其能够顺利地跳转到正确的中断处理程序,并在处理中断时遵循相应的规则和权限。
在处理一个外部设备的中断时,CPU 首先根据中断号在中断向量表中找到对应的中断描述符,从中获取段选择子和偏移量,然后通过这两个信息计算出中断处理程序的实际地址,进而跳转到该地址执行中断处理程序,完成对设备中断的响应和处理。
2.2 中断请求队列与处理流程
中断请求队列是Linux系统为了高效管理中断请求而采用的一种数据结构,它类似于一个 “任务队列”,用于存放多个中断请求。在实际的计算机系统中,由于硬件资源的限制,多个设备可能会共享同一条中断请求线(IRQ),这就导致多个设备的中断请求需要通过同一个中断向量来处理。为了区分这些不同设备的中断请求,Linux 系统为每个中断向量设置了一个中断请求队列,将共享同一中断向量的所有设备的中断请求组织成一个队列。
中断请求队列的数据结构主要由两部分组成:irq_desc 结构体数组和 irqaction 结构体链表。irq_desc 结构体数组是中断请求队列的核心,数组中的每个元素都对应着一个中断向量,它包含了与该中断向量相关的各种信息,如中断的状态(是否被禁用、是否正在处理等)、中断控制器的信息以及指向 irqaction 结构体链表的指针。irqaction 结构体链表则用于存储具体的中断处理信息,每个链表节点代表一个设备的中断请求,包含了设备的中断处理函数指针、中断标志位、设备名称以及设备 ID 等信息。通过这种数据结构,Linux 系统能够清晰地管理和调度共享同一中断向量的多个设备的中断请求。
每个能够产生中断的设备或者模块都会在内核中注册一个中断服务例程(ISR),当产生中断时,中断处理程序会被执行,在中断处理程序中,首先会保存中断向量号和上下文,之后执行中断线对应的中断服务例程。对于CPU来说,中断线是非常宝贵的资源,而由于计算机的发展,外部设备数量和种类越来越多,导致了中断线资源不足的情况,linux为了应对这种情况,实现了两种中断线分配方式,分别是:共享中断线,中断线动态分配。
-
共享中断线:多个设备共用一条中断线,当此条中断线发生中断时,因为不可能预先知道哪个特定的设备产生了中断,因此,这条中断线上的每个中断服务例程都会被执行,以验证是哪个设备产生的中断(一般的,设备产生中断时,会标记自己的状态寄存器,中断服务例程通过检查每个设备的状态寄存器来查找产生中断的设备)。
-
中断线动态分配:一条中断线在可能使用的时刻才与一个设备驱动程序关联起来,这样一来,即使几个硬件设备并不共享中断线,同一个中断向量也可以由这几个设备在不同时刻运行。
共享中断线的分配方式是比较常见的,一次典型的基于共享中断线的中断处理流程如下:
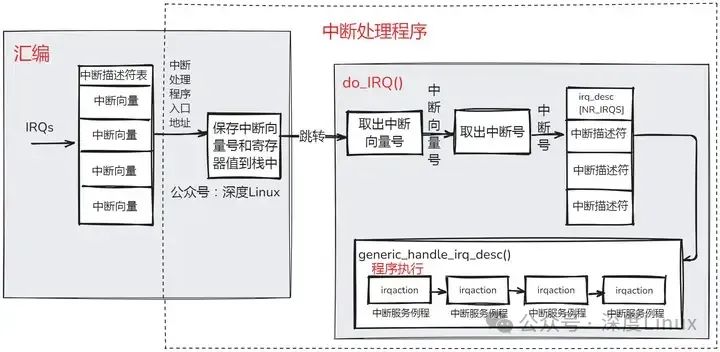
由于中断处于中断上下文中,所以在中断处理过程中,会有以下几个特性:
-
中断处理程序正在运行时,CPU会通知中断控制器屏蔽产生此中断的中断线。此中断线发出的信号被暂时忽略,当中断处理程序结束时恢复此中断线。
-
在中断服务例程的设计中,原则上是立即处理紧急的操作,将非紧急的操作延后处理(交给软中断进行处理)。
-
中断处理程序是运行在中断上下文,但是其是代表进程运行的,因此它所代表的进行必须处于TASK_RUNNING状态,否则可能出现僵死情况,因此在中断处理程序中不能执行任何阻塞过程
当硬件设备产生中断请求时,Linux 系统的中断处理流程可以分为以下几个关键步骤:
-
中断触发与识别:硬件设备通过中断请求线向中断控制器发送中断信号,中断控制器接收到信号后,根据信号的来源和配置,生成相应的中断号,并将其发送给 CPU。
-
中断响应与上下文切换:CPU 在接收到中断号后,暂停当前正在执行的任务,保存当前任务的上下文信息(如寄存器的值、程序计数器的值等)到堆栈中,然后根据中断号在中断向量表中查找对应的中断处理程序入口地址,开始进入中断处理程序执行。
-
中断请求队列处理:中断处理程序首先根据中断号找到对应的 irq_desc 结构体,从中获取 irqaction 结构体链表的指针,然后遍历链表,依次调用每个设备的中断处理函数。在调用中断处理函数之前,中断处理程序会根据中断标志位进行一些必要的检查和准备工作,如判断中断是否可屏蔽、是否需要保存和恢复中断现场等。
-
中断处理与返回:设备的中断处理函数执行完成后,返回一个状态值,指示中断处理的结果。中断处理程序根据返回值进行相应的处理,如如果所有设备的中断处理函数都返回成功,则清除中断标志,通知中断控制器中断处理已完成;如果有设备的中断处理函数返回失败,则可能需要进行一些错误处理,如重新发送中断请求或通知用户程序。最后,中断处理程序从堆栈中恢复之前保存的任务上下文信息,将 CPU 的控制权交还给被中断的任务,使其继续执行。
2.3 中断上下文与进程上下文
中断上下文和进程上下文是 Linux 系统中两个重要的概念,它们分别代表了系统在不同运行状态下的环境和资源。中断上下文是指系统在处理中断时所处的环境,当硬件设备产生中断请求时,CPU 会暂停当前正在执行的任务,进入中断处理程序执行,此时系统就处于中断上下文。在中断上下文下,系统主要关注的是如何快速响应和处理中断事件,因此中断处理程序通常具有较高的优先级,并且不能进行一些可能导致阻塞的操作,如睡眠、访问文件系统等。
中断上下文的特点是短暂而高效,它的存在是为了确保系统能够及时处理硬件设备的请求,保证系统的实时性和稳定性。在处理网络数据包接收中断时,中断处理程序需要迅速读取网络设备的缓冲区,将数据包复制到系统内存中,并通知相关的网络协议栈进行后续处理,这个过程必须在短时间内完成,以避免数据包丢失或网络延迟增加。
进程上下文则是指系统在执行进程时所处的环境,每个进程都有自己独立的进程上下文,包括进程的地址空间、寄存器的值、程序计数器的值以及堆栈等。在进程上下文下,系统可以进行各种复杂的操作,如文件读写、内存分配、进程调度等,这些操作可以根据进程的需求进行灵活的调度和管理。进程上下文的切换相对较为复杂,需要保存和恢复大量的上下文信息,因此开销较大。当一个进程需要进行系统调用时,它会通过软中断进入内核态,此时系统会将进程上下文切换到内核态的进程上下文,执行系统调用的处理函数,处理完成后再将上下文切换回用户态的进程上下文。
在中断处理过程中,中断上下文和进程上下文会相互切换,这种切换对于系统的性能和稳定性有着重要的影响。当中断发生时,系统会从当前的进程上下文切换到中断上下文,执行中断处理程序;中断处理完成后,再切换回原来的进程上下文,继续执行被中断的任务。
在这个过程中,如果中断处理程序执行时间过长,可能会导致其他进程的响应时间变长,影响系统的整体性能;如果中断处理程序在执行过程中进行了一些不恰当的操作,如修改了进程上下文的关键数据,可能会导致系统出现错误或崩溃。因此,在设计和优化中断处理程序时,需要充分考虑中断上下文和进程上下文的特点和限制,合理安排中断处理的流程和操作,以确保系统的高效稳定运行。
三、中断实现原理
3.1中断初始化
中断向量表,中断描述符表,中断描述符,中断控制器描述符,中断服务例程。可以说这几个结构组成了整个内核中断框架主体,所以内核对整个中断的初始化工作大多集中在了这几个结构上。
在系统中,当一个中断产生时,首先CPU会从中断向量表中获取相应的中断向量,并根据中断向量的权限位判断是否处于该权限,之后跳转至中断处理函数,在中断处理函数中会根据中断向量号获取中断描述符,并通过中断描述符获取此中断对应的中断控制器描述符,然后对中断控制器执行应答操作,最后执行此中断描述符中的中断服务例程链表,最后执行软中断。
而整个初始化的过程与中断处理过程相应,首先先初始化中断向量表,再初始化中断描述符表和中断描述符。中断控制器描述符是系统预定编写好的静态变量,如i8259A中断控制器对应的变量就是i8259A_chip。这时一个中断已经初始化完毕,之后驱动需要使用此中断时系统会将驱动中的中断处理加入到该中断的中断服务例程链表中。
如下图:

①初始化中断向量
虽然称之为中断向量表,其实对于CPU来说只是一个起始地址,此地址开始每向上8个字节为一个中断向量。我们的CPU上有一个idtr寄存器,它专门用于保存中断向量表地址,当产生一个中断时,CPU会自动从idtr寄存器保存的中断向量表地址处获取相应的中断向量,然后判断权限并跳转至中断处理函数。当计算机刚启动时,首先会启动引导程序(BIOS),在BIOS中会把中断向量表存放在内存开始位置(0x00000000)。
BIOS会有自己的一些默认中断处理函数,而当BIOS处理完后,会将计算机控制器转交给linux,而linux会在使用BIOS的中断向量表的同时重新设置新的中断向量表(新的地址保存在配置中的CONFIG_VECTORS_BASE),之后会完全使用新的中断向量表。
一般的,我们也把中断向量表中的中断向量称为门描述符,其大小为64位,其主要保存了段选择符、权限位和中断处理程序入口地址。CPU主要将门分为三种:任务门,中断门,陷阱门。虽然CPU把门描述符分为了三种,但是linux为了处理更多种情况,把门描述符分为了五种,分别为中断门,系统门,系统中断门,陷阱门,任务门;但其存储结构与CPU定义的门不变。结构如下:

在一个门描述符中:
-
P:代表的是段是否处于内存中,因为linux从不把整个段交换的硬盘上,所以P都被置为1。
-
DPL:代表的是权限,用于限制对这个段的存取,当其为0时,只有CPL=0(内核态)才能够访问这个段,当其为3时,任何等级的CPL(用户态及内核态)都可以访问。
-
段选择符:除了任务门设置为TSS段,陷阱门和中断门都设置为__KERNER_CS(内核代码段)。
-
偏移量:就是中断处理程序入口地址。
门描述符的初始化主要分为两部分,我们知道,中断向量表中保存的是中断和异常,所以整个中断描述符的初始化需要分为中断初始化和异常初始化。而中断向量表的初始化情况是,第一部分是经过一段汇编代码对整个中断向量表进行初始化,第二部分是在系统进入start_kernel()函数后分别对异常和中断进行初始化。在linux中,中断向量表用idt_table[NR_VECTORS]数组进行描述,中断向量(门描述符)在系统中用struct desc_struct结构表示,具体我们可以往下看。
第一部分 - 汇编代码(arch/x86/kernel/head_32.S):
/** setup_once** The setup work we only want to run on the BSP.** Warning: %esi is live across this function.*/
__INIT
setup_once:movl $idt_table,%edi # idt_table就是中断向量表,地址保存到edi中movl $early_idt_handlers,%eax # early_idt_handlers地址保存到eax中,early_idt_handlers是二维数组,每行9个字符movl $NUM_EXCEPTION_VECTORS,%ecx # NUM_EXCEPTION_VECTORS地址保存到ecx中,ecx用于循环,NUM_EXCEPTION_VECTORS为32
1:movl %eax,(%edi) # 将eax的值保存到edi保存的地址中movl %eax,4(%edi) # 将eax的值保存到edi保存的地址+4中/* interrupt gate, dpl=0, present */movl $(0x8E000000 + __KERNEL_CS),2(%edi) # 将(0x8E000000 + __KERNEL_CS)一共4个字节保存到edi保存的地址+2的位置中addl $9,%eax # eax += 9,指向early_idt_handlers数组下一列addl $8,%edi # edi += 8,就是下一个门描述符地址loop 1b # 根据ecx是否为0进行循环# 前32个中断向量初始化结果:# |63 48|47 32|31 16|15 0|# |early_idt_handlers[i](高16位)| 0x8E00 | __KERNEL_CS |early_idt_handlers[i](低16位)| movl $256 - NUM_EXCEPTION_VECTORS,%ecx # 256 - 32 保存到ecx,进行新一轮的循环movl $ignore_int,%edx # ignore_int保存到edxmovl $(__KERNEL_CS << 16),%eax # (__KERNEL_CS << 16)保存到eaxmovw %dx,%ax movw $0x8E00,%dx 2:movl %eax,(%edi)movl %edx,4(%edi)addl $8,%edi # edi += 8,就是下一个门描述符地址loop 2b# 其他中断向量初始化结果:# |63 48|47 32|31 16|15 0|# | ignore_int(高16位) | 0x8E00 | __KERNEL_CS | ignore_int(低16位) |如果CPU是486,之后会通过 lidt idt_descr 命令将中断向量表(idt_descr)地址放入idtr寄存器;如果不是,则暂时不会将idt_descr放入idtr寄存器(在trap_init()函数再执行这步操作)。idtr寄存器一共是48位,低16位保存的是中断向量表长度,高32位保存的是中断向量表基地址。我们可以看看idt_descr的形式,如下:
idt_descr:.word IDT_ENTRIES*8-1 # 这里放入的是表长度, 256 * 8 - 1.long idt_table # idt_table地址放在这,idt_table定义在/arch/x86/kernel/trap.h中/* 我们再看看 idt_table 是怎么定义的,idt_table代表的就是中断向量表 */
/* 代码地址:arch/x86/kernel/Traps.c */
gate_desc idt_table[NR_VECTORS] __page_aligned_bss;/* 继续,看看 gate_desc ,用于描述一个中断向量 */
#ifdef CONFIG_X86_64
typedef struct gate_struct64 gate_desc;
#else
typedef struct desc_struct gate_desc;
#endif/* 我们看看32位下的 struct desc_struct,此结构就是一个中断向量(门描述符) */
struct desc_struct {union {struct {unsigned int a;unsigned int b;};struct {u16 limit0;u16 base0;unsigned base1: 8, type: 4, s: 1, dpl: 2, p: 1;unsigned limit: 4, avl: 1, l: 1, d: 1, g: 1, base2: 8;};};
} __attribute__((packed));可以看出,在汇编代码初始化部分,所有的门描述符的DPL权限位都设置为0(用户态不可访问),段选择符设置为__KERNEL_CS内核代码段。而对于中断处理函数设置则不同,前32个门描述符的中断处理函数为early_idt_handlers,之后的门描述符的中断处理函数为ignore_int。而在linux中,0~19的中断向量是用于异常和陷阱。20~31的中断向量是intel保留使用的。
②初始化异常向量
异常向量作为在中断向量表中的前20个向量(0~19),在汇编代码中已经将其的处理函数设置为early_idt_handlers,而进入start_kernel()函数后,系统会在trap_init()函数中重新设置它们的处理函数,由于异常和陷阱的特殊性,它们并没有像中断这样复杂的数据结构,单纯的,每个异常和陷阱有它们自己的中断处理函数,系统只是简单地把中断处理函数放入异常和陷阱的门描述符中。在了解trap_init()函数之前,我们需要先了解如下几个函数:
/* 设置一个中断门* n:中断号 * addr:中断处理程序入口地址*/
#define set_intr_gate(n, addr) \do { \BUG_ON((unsigned)n > 0xFF); \_set_gate(n, GATE_INTERRUPT, (void *)addr, 0, 0, \__KERNEL_CS); \_trace_set_gate(n, GATE_INTERRUPT, (void *)trace_##addr,\0, 0, __KERNEL_CS); \} while (0)/* 设置一个系统中断门 */
static inline void set_system_intr_gate(unsigned int n, void *addr)
{BUG_ON((unsigned)n > 0xFF);_set_gate(n, GATE_INTERRUPT, addr, 0x3, 0, __KERNEL_CS);
}/* 设置一个系统门 */
static inline void set_system_trap_gate(unsigned int n, void *addr)
{BUG_ON((unsigned)n > 0xFF);_set_gate(n, GATE_TRAP, addr, 0x3, 0, __KERNEL_CS);
}/* 设置一个陷阱门 */
static inline void set_trap_gate(unsigned int n, void *addr)
{BUG_ON((unsigned)n > 0xFF);_set_gate(n, GATE_TRAP, addr, 0, 0, __KERNEL_CS);
}/* 设置一个任务门 */
static inline void set_task_gate(unsigned int n, unsigned int gdt_entry)
{BUG_ON((unsigned)n > 0xFF);_set_gate(n, GATE_TASK, (void *)0, 0, 0, (gdt_entry<<3));
}这几个函数用于设置不同门的API函数,他们的参数n都为中断号,而他们都会调用_set_gate()函数,只是参数不同,_set_gate()函数如下:
/* 设置一个门描述符,并写入中断向量表* gate: 中断号* type: 门类型* addr: 中断处理程序入口* dpl: 权限位* ist: 64位系统才使用* seg: 段选择符*/
static inline void _set_gate(int gate, unsigned type, void *addr,unsigned dpl, unsigned ist, unsigned seg)
{gate_desc s;/* 生成一个门描述符 */pack_gate(&s, type, (unsigned long)addr, dpl, ist, seg);/** does not need to be atomic because it is only done once at* setup time*//* 将新的门描述符写入中断向量表中的gate项,使用memcpy进行写入 */write_idt_entry(idt_table, gate, &s);/* 用于跟踪? 暂时还不清楚这个 trace_idt_table 的用途 */write_trace_idt_entry(gate, &s);
}
了解了以上的设置门描述符的函数,我们再看看trap_init()函数:
void __init trap_init(void)
{int i;/* 使用了EISA总线 */
#ifdef CONFIG_EISAvoid __iomem *p = early_ioremap(0x0FFFD9, 4);if (readl(p) == 'E' + ('I'<<8) + ('S'<<16) + ('A'<<24))EISA_bus = 1;early_iounmap(p, 4);
#endif/* Interrupts/Exceptions */
//enum {
// X86_TRAP_DE = 0, /* 0, 除0操作 Divide-by-zero */
// X86_TRAP_DB, /* 1, 调试使用 Debug */
// X86_TRAP_NMI, /* 2, 非屏蔽中断 Non-maskable Interrupt */
// X86_TRAP_BP, /* 3, 断点 Breakpoint */
// X86_TRAP_OF, /* 4, 溢出 Overflow */
// X86_TRAP_BR, /* 5, 越界异常 Bound Range Exceeded */
// X86_TRAP_UD, /* 6, 无效操作码 Invalid Opcode */
// X86_TRAP_NM, /* 7, 无效设备 Device Not Available */
// X86_TRAP_DF, /* 8, 双重故障 Double Fault */
// X86_TRAP_OLD_MF, /* 9, 协处理器段超限 Coprocessor Segment Overrun */
// X86_TRAP_TS, /* 10, 无效任务状态段(TSS) Invalid TSS */
// X86_TRAP_NP, /* 11, 段不存在 Segment Not Present */
// X86_TRAP_SS, /* 12, 栈段错误 Stack Segment Fault */
// X86_TRAP_GP, /* 13, 保护错误 General Protection Fault */
// X86_TRAP_PF, /* 14, 页错误 Page Fault */
// X86_TRAP_SPURIOUS, /* 15, 欺骗性中断 Spurious Interrupt */
// X86_TRAP_MF, /* 16, X87 浮点数异常 Floating-Point Exception */
// X86_TRAP_AC, /* 17, 对齐检查 Alignment Check */
// X86_TRAP_MC, /* 18, 设备检查 Machine Check */
// X86_TRAP_XF, /* 19, SIMD 浮点数异常 Floating-Point Exception */
// X86_TRAP_IRET = 32, /* 32, 汇编指令异常 IRET Exception */
//};set_intr_gate(X86_TRAP_DE, divide_error);/* 在32位系统上其效果等同于 set_intr_gate */set_intr_gate_ist(X86_TRAP_NMI, &nmi, NMI_STACK);/* int4 can be called from all */set_system_intr_gate(X86_TRAP_OF, &overflow);set_intr_gate(X86_TRAP_BR, bounds);set_intr_gate(X86_TRAP_UD, invalid_op);set_intr_gate(X86_TRAP_NM, device_not_available);
#ifdef CONFIG_X86_32set_task_gate(X86_TRAP_DF, GDT_ENTRY_DOUBLEFAULT_TSS);
#elseset_intr_gate_ist(X86_TRAP_DF, &double_fault, DOUBLEFAULT_STACK);
#endifset_intr_gate(X86_TRAP_OLD_MF, coprocessor_segment_overrun);set_intr_gate(X86_TRAP_TS, invalid_TSS);set_intr_gate(X86_TRAP_NP, segment_not_present);set_intr_gate(X86_TRAP_SS, stack_segment);set_intr_gate(X86_TRAP_GP, general_protection);set_intr_gate(X86_TRAP_SPURIOUS, spurious_interrupt_bug);set_intr_gate(X86_TRAP_MF, coprocessor_error);set_intr_gate(X86_TRAP_AC, alignment_check);
#ifdef CONFIG_X86_MCEset_intr_gate_ist(X86_TRAP_MC, &machine_check, MCE_STACK);
#endifset_intr_gate(X86_TRAP_XF, simd_coprocessor_error);/* 将前32个中断号都设置为已使用状态 */for (i = 0; i < FIRST_EXTERNAL_VECTOR; i++)set_bit(i, used_vectors);#ifdef CONFIG_IA32_EMULATION/* 设置0x80系统调用的系统中断门 */set_system_intr_gate(IA32_SYSCALL_VECTOR, ia32_syscall);set_bit(IA32_SYSCALL_VECTOR, used_vectors);
#endif#ifdef CONFIG_X86_32/* 设置0x80系统调用的系统门 */set_system_trap_gate(SYSCALL_VECTOR, &system_call);set_bit(SYSCALL_VECTOR, used_vectors);
#endif/** Set the IDT descriptor to a fixed read-only location, so that the* "sidt" instruction will not leak the location of the kernel, and* to defend the IDT against arbitrary memory write vulnerabilities.* It will be reloaded in cpu_init() *//* 将中断向量表设置在一个固定的只读的位置,以便“sidt”指令不会泄漏内核的位置,和保护中断向量表可以处于任意内存写的漏洞。它将会在 cpu_init() 中被加载到idtr寄存器 */__set_fixmap(FIX_RO_IDT, __pa_symbol(idt_table), PAGE_KERNEL_RO);idt_descr.address = fix_to_virt(FIX_RO_IDT);/* 执行CPU的初始化,对于中断而言,在 cpu_init() 中主要是将 idt_descr 放入idtr寄存器中 */cpu_init();/* x86_init是一个定义了很多x86体系上的初始化操作,这里执行的另一个trap_init()函数为空函数,什么都不做 */x86_init.irqs.trap_init();#ifdef CONFIG_X86_64/* 64位操作 *//* 将 idt_table 复制到 debug_idt_table 中 */memcpy(&debug_idt_table, &idt_table, IDT_ENTRIES * 16);set_nmi_gate(X86_TRAP_DB, &debug);set_nmi_gate(X86_TRAP_BP, &int3);
#endif
}在代码中,used_vectors变量是一个bitmap,它用于记录中断向量表中哪些中断已经被系统注册和使用,哪些未被注册使用。trap_init()已经完成了异常和陷阱的初始化。对于linux而言,中断号0~19是专门用于陷阱和故障使用的,以上代码也表明了这一点,而20~31一般是intel用于保留的。而我们的外部IRQ线使用的中断为32~255(代码中32号中断被用作汇编指令异常中断)。
所以,在trap_init()代码中,专门对0~19号中断的门描述符进行了初始化,最后将新的中断向量表起始地址放入idtr寄存器中。在trap_init()中我们看到每个异常和陷阱都有他们自己的处理函数,不过它们的处理函数的处理方式都大同小异,如下:
#代码地址:arch/x86/kernel/entry_32.S# 11号异常处理函数入口
ENTRY(segment_not_present)RING0_EC_FRAMEASM_CLACpushl_cfi $do_segment_not_presentjmp error_codeCFI_ENDPROC
END(segment_not_present)# 12号异常处理函数入口
ENTRY(stack_segment)RING0_EC_FRAMEASM_CLACpushl_cfi $do_stack_segmentjmp error_codeCFI_ENDPROC
END(stack_segment)# 17号异常处理函数入口
ENTRY(alignment_check)RING0_EC_FRAMEASM_CLACpushl_cfi $do_alignment_checkjmp error_codeCFI_ENDPROC
END(alignment_check)# 0号异常处理函数入口
ENTRY(divide_error)RING0_INT_FRAMEASM_CLACpushl_cfi $0 # no error codepushl_cfi $do_divide_errorjmp error_codeCFI_ENDPROC
END(divide_error)在trap_init()函数中调用了cpu_init()函数,在此函数中会将新的中断向量表地址放入idtr寄存器中,而具体内核是如何实现的呢,之前已经说明,idtr寄存器的低16位保存的是中断向量表长度,高32位保存的是中断向量表基地址,相对于的,内核定义了一个struct desc_ptr结构专门用于保存idtr寄存器内容,其如下:
/* 代码地址:arch/x86/include/asm/Desc_defs.h */
struct desc_ptr {unsigned short size;unsigned long address;
} __attribute__((packed)) ;/* 代码地址:arch/x86/kernel/cpu/Common.c */
/* 专门用于保存需要写入idtr寄存器值的变量,这里可以看出,中断向量表长度为256 * 16 - 1,地址为idt_table */
struct desc_ptr idt_descr = { NR_VECTORS * 16 - 1, (unsigned long) idt_table };在cpu_init()中,会调用load_current_idt()函数进行写入,如下:
static inline void load_current_idt(void)
{if (is_debug_idt_enabled())/* 开启了中断调试,用的是 debug_idt_descr 和 debug_idt_table */load_debug_idt();else if (is_trace_idt_enabled())/* 开启了中断跟踪,用的是 trace_idt_descr 和 trace_idt_table */load_trace_idt();else/* 普通情况,用的是 idt_descr 和 idt_table */load_idt((const struct desc_ptr *)&idt_descr);
}/* load_idt()的定义 */
#define load_idt(dtr) native_load_idt(dtr)/* native_load_idt()的定义 */
static inline void native_load_idt(const struct desc_ptr *dtr)
{asm volatile("lidt %0"::"m" (*dtr));
}到这,异常和陷阱已经初始化完毕,内核也已经开始使用新的中断向量表了,BIOS的中断向量表就已经遗弃,不再使用了。
③初始化中断
内核是在异常和陷阱初始化完成的情况下才会进行中断的初始化,中断的初始化也是处于start_kernel()函数中,分为两个部分,分别是early_irq_init()和init_IRQ()。early_irq_init()是第一步的初始化,其工作主要是跟硬件无关的一些初始化,比如一些变量的初始化,分配必要的内存等。init_IRQ()是第二步,其主要就是关于硬件部分的初始化了。首先我们先看看中断描述符表irq_desc[NR_IRQS]:
/* 中断描述符表 */
struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {[0 ... NR_IRQS-1] = {.handle_irq = handle_bad_irq,.depth = 1,.lock = __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),}
};可以看到,irq_desc数组有NR_IRQS个元素,NR_IRQS并不是256-32,实际上,虽然中断向量表中一共有256项(前32项用作异常和intel保留),但并不是所有中断向量都会使用到,所以中断描述符表也不一定是256-32项,CPU可以使用多少个中断是由中断控制器(PIC、APIC)或者内核配置决定的,我们看看NR_IRQS的定义:
/* IOAPIC为外部中断控制器 */
#ifdef CONFIG_X86_IO_APIC
#define CPU_VECTOR_LIMIT (64 * NR_CPUS)
#define NR_IRQS \(CPU_VECTOR_LIMIT > IO_APIC_VECTOR_LIMIT ? \(NR_VECTORS + CPU_VECTOR_LIMIT) : \(NR_VECTORS + IO_APIC_VECTOR_LIMIT))
#else /* !CONFIG_X86_IO_APIC: NR_IRQS_LEGACY = 16 */
#define NR_IRQS NR_IRQS_LEGACY
#endif这时我们可以先看看early_irq_init()函数:
int __init early_irq_init(void)
{int count, i, node = first_online_node;struct irq_desc *desc;/* 初始化irq_default_affinity变量,此变量用于设置中断默认的CPU亲和力 */init_irq_default_affinity();printk(KERN_INFO "NR_IRQS:%d\n", NR_IRQS);/* 指向中断描述符表irq_desc */desc = irq_desc;/* 获取中断描述符表长度 */count = ARRAY_SIZE(irq_desc);for (i = 0; i < count; i++) {/* 为kstat_irqs分配内存,每个CPU有自己独有的kstat_irqs数据,此数据用于统计 */desc[i].kstat_irqs = alloc_percpu(unsigned int);/* 为 desc->irq_data.affinity 和 desc->pending_mask 分配内存 */alloc_masks(&desc[i], GFP_KERNEL, node);/* 初始化中断描述符的锁 */raw_spin_lock_init(&desc[i].lock);/* 设置中断描述符的锁所属的类,此类用于防止死锁 */lockdep_set_class(&desc[i].lock, &irq_desc_lock_class);/* 一些变量的初始化 */desc_set_defaults(i, &desc[i], node, NULL);}return arch_early_irq_init();
}更多的初始化在desc_set_defaults()函数中:
static void desc_set_defaults(unsigned int irq, struct irq_desc *desc, int node,struct module *owner)
{int cpu;/* 中断号 */desc->irq_data.irq = irq;/* 中断描述符的中断控制器芯片为 no_irq_chip */desc->irq_data.chip = &no_irq_chip;/* 中断控制器的私有数据为空 */desc->irq_data.chip_data = NULL;desc->irq_data.handler_data = NULL;desc->irq_data.msi_desc = NULL;/* 设置中断状态 desc->status_use_accessors 为初始化状态_IRQ_DEFAULT_INIT_FLAGS */irq_settings_clr_and_set(desc, ~0, _IRQ_DEFAULT_INIT_FLAGS);/* 中断默认被禁止,设置 desc->irq_data->state_use_accessors = IRQD_IRQ_DISABLED */irqd_set(&desc->irq_data, IRQD_IRQ_DISABLED);/* 设置中断处理回调函数为 handle_bad_irq,handle_bad_irq作为默认的回调函数,此函数中基本上不做什么处理,就是在屏幕上打印此中断信息,并且desc->kstat_irqs++ */desc->handle_irq = handle_bad_irq;/* 嵌套深度为1,表示被禁止1次 */desc->depth = 1;/* 初始化此中断发送次数为0 */desc->irq_count = 0;/* 无法处理的中断次数为0 */desc->irqs_unhandled = 0;/* 在/proc/interrupts所显名字为空 */desc->name = NULL;/* owner为空 */desc->owner = owner;/* 初始化kstat_irqs中每个CPU项都为0 */for_each_possible_cpu(cpu)*per_cpu_ptr(desc->kstat_irqs, cpu) = 0;/* SMP系统才使用的初始化,设置* desc->irq_data.node = first_online_node * desc->irq_data.affinity = irq_default_affinity* 清除desc->pending_mask*/desc_smp_init(desc, node);
}整个early_irq_init()在这里就初始化完毕了,相对来说比较简单,可以说early_irq_init()只是初始化了中断描述符表中的所有元素。
在看init_IRQ()前需要看看legacy_pic这个变量,它其实就是CPU内部的中断控制器i8259A,定义了与i8259A相关的一些处理函数和中断数量,如下:
struct legacy_pic default_legacy_pic = {.nr_legacy_irqs = NR_IRQS_LEGACY,.chip = &i8259A_chip,.mask = mask_8259A_irq,.unmask = unmask_8259A_irq,.mask_all = mask_8259A,.restore_mask = unmask_8259A,.init = init_8259A,.irq_pending = i8259A_irq_pending,.make_irq = make_8259A_irq,
};struct legacy_pic *legacy_pic = &default_legacy_pic;在X86体系下,CPU使用的内部中断控制器是i8259A,内核就定义了这个变量进行使用,在init_IRQ()中会将所有的中断描述符的中断控制器芯片指向i8259A,具体我们先看看init_IRQ()代码:
void __init init_IRQ(void)
{int i;/** On cpu 0, Assign IRQ0_VECTOR..IRQ15_VECTOR's to IRQ 0..15.* If these IRQ's are handled by legacy interrupt-controllers like PIC,* then this configuration will likely be static after the boot. If* these IRQ's are handled by more mordern controllers like IO-APIC,* then this vector space can be freed and re-used dynamically as the* irq's migrate etc.*//* nr_legacy_irqs() 返回 legacy_pic->nr_legacy_irqs,为16* vector_irq是一个int型的数组,长度为中断向量表长,其保存的是中断向量对应的中断号(如果中断向量是异常则没有中断号)* i8259A中断控制器使用IRQ0~IRQ15这16个中断号,这里将这16个中断号设置到CPU0的vector_irq数组的0x30~0x3f上。*/for (i = 0; i < nr_legacy_irqs(); i++)per_cpu(vector_irq, 0)[IRQ0_VECTOR + i] = i;/* x86_init是一个结构体,里面定义了一组X86体系下的初始化函数 */x86_init.irqs.intr_init();
}x86_init.irqs.intr_init()是一个函数指针,其指向native_init_IRQ(),我们可以直接看看native_init_IRQ():
void __init native_init_IRQ(void)
{int i;/* Execute any quirks before the call gates are initialised: *//* 这里又是执行x86_init结构中的初始化函数,pre_vector_init()指向 init_ISA_irqs */x86_init.irqs.pre_vector_init();/* 初始化中断向量表中的中断控制器中默认的一些中断门初始化 */apic_intr_init();/** Cover the whole vector space, no vector can escape* us. (some of these will be overridden and become* 'special' SMP interrupts)*//* 第一个外部中断,默认是32 */i = FIRST_EXTERNAL_VECTOR;/* 在used_vectors变量中找出所有没有置位的中断向量,我们知道,在trap_init()中对所有异常和陷阱和系统调用中断都置位了used_vectors,没有置位的都为中断* 这里就是对所有中断设置门描述符*/for_each_clear_bit_from(i, used_vectors, NR_VECTORS) {/* IA32_SYSCALL_VECTOR could be used in trap_init already. *//* interrupt[]数组保存的是外部中断的中断门信息* 这里将中断向量表中空闲的中断向量设置为中断门,interrupt是一个函数指针数组,其将31~255数组元素指向interrupt[i]函数*/set_intr_gate(i, interrupt[i - FIRST_EXTERNAL_VECTOR]);}/* 如果外部中断控制器需要,则安装一个中断处理例程irq2到中断IRQ2上 */if (!acpi_ioapic && !of_ioapic && nr_legacy_irqs())setup_irq(2, &irq2);#ifdef CONFIG_X86_32/* 在x86_32模式下,会为当前CPU分配一个中断使用的栈空间 */irq_ctx_init(smp_processor_id());
#endif
}在native_init_IRQ()中,又使用了x86_init变量中的pre_vector_init函数指针,其指向init_ISA_irqs()函数:
void __init init_ISA_irqs(void)
{/* CHIP默认是i8259A_chip */struct irq_chip *chip = legacy_pic->chip;int i;#if defined(CONFIG_X86_64) || defined(CONFIG_X86_LOCAL_APIC)/* 使用了CPU本地中断控制器 *//* 开启virtual wire mode */init_bsp_APIC();
#endif/* 其实就是调用init_8259A(),进行8259A硬件的初始化 */legacy_pic->init(0);for (i = 0; i < nr_legacy_irqs(); i++)/* i为中断号,chip是irq_chip结构,最后是中断回调函数 * 设置了中断号i的中断描述符的irq_data.irq_chip = i8259A_chip* 设置了中断回调函数为handle_level_irq*/irq_set_chip_and_handler(i, chip, handle_level_irq);
}在init_ISA_irqs()函数中,最主要的就是将内核使用的外部中断的中断描述符的中断控制器设置为i8259A_chip,中断回调函数为handle_level_irq。
回到native_init_IRQ()函数,当执行完x86_init.irqs.pre_vector_init()之后,会执行apic_initr_init()函数,这个函数中会初始化一些中断控制器特定的中断函数(这些中断游离于之前描述的中断体系中,它们没有自己的中断描述符,中断向量中直接保存它们自己的中断处理函数,类似于异常与陷阱的调用情况),具体我们看看:
static void __init apic_intr_init(void)
{smp_intr_init();#ifdef CONFIG_X86_THERMAL_VECTOR/* 中断号为: 0xfa,处理函数为: thermal_interrupt */alloc_intr_gate(THERMAL_APIC_VECTOR, thermal_interrupt);
#endif
#ifdef CONFIG_X86_MCE_THRESHOLDalloc_intr_gate(THRESHOLD_APIC_VECTOR, threshold_interrupt);
#endif#if defined(CONFIG_X86_64) || defined(CONFIG_X86_LOCAL_APIC)/* self generated IPI for local APIC timer */alloc_intr_gate(LOCAL_TIMER_VECTOR, apic_timer_interrupt);/* IPI for X86 platform specific use */alloc_intr_gate(X86_PLATFORM_IPI_VECTOR, x86_platform_ipi);
#ifdef CONFIG_HAVE_KVM/* IPI for KVM to deliver posted interrupt */alloc_intr_gate(POSTED_INTR_VECTOR, kvm_posted_intr_ipi);
#endif/* IPI vectors for APIC spurious and error interrupts */alloc_intr_gate(SPURIOUS_APIC_VECTOR, spurious_interrupt);alloc_intr_gate(ERROR_APIC_VECTOR, error_interrupt);/* IRQ work interrupts: */
# ifdef CONFIG_IRQ_WORKalloc_intr_gate(IRQ_WORK_VECTOR, irq_work_interrupt);
# endif#endif
}在apic_intr_init()函数中,使用了alloc_intr_gate()函数进行处理,这个函数的处理也很简单,置位该中断号所处used_vectors位置,调用set_intr_gate()设置一个中断门描述符,到这里整个中断及异常都已经初始化完成了。
-
在linux系统中,中断一共有256个,0~19主要用于异常与陷阱,20~31是intel保留,未使用。32~255作为外部中断进行使用。特别的,0x80中断用于系统调用。
-
机器上电时,BIOS会初始化一个中断向量表,当交接给linux内核后,内核会自己新建立一个中断向量表,之后完全使用自己的中断向量表,舍弃BIOS的中断向量表。
-
在x86上系统默认使用的中断控制器为i8259A。
-
中断描述符的初始化过程中,内核会将中断描述符的默认中断控制器设置为i8259A,中断处理回调函数为handle_level_irq()。
-
外部中断的门描述的中断处理函数都为interrupt[i]。
中断的初始化大体上分为两个部分,第一个部分为汇编代码的中断向量表的初次初始化,第二部分为C语言代码,其又分为异常与陷阱的初始化和中断的初始化。如图:
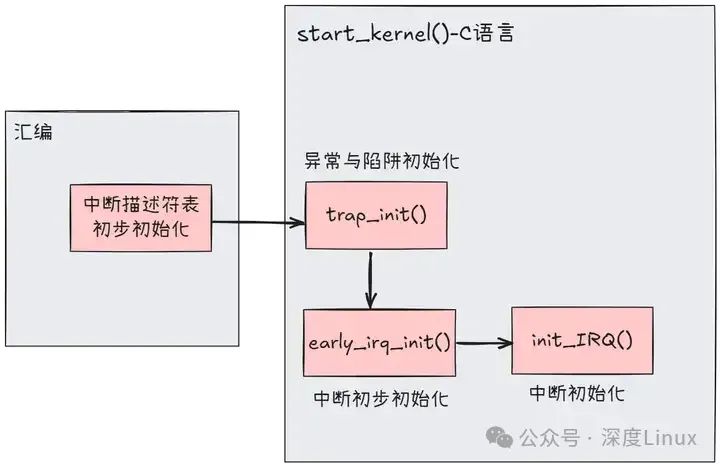
在汇编的中断向量表初始化过中,其主要对整个中断向量表进行了初始化,其主要工作是:
-
所有的门描述符的权限位为0;
-
所有的门描述符的段选择符为__KERNEL_CS;
-
0~31的门描述符的中断处理程序为early_idt_handlers[i](0 <= i <= 31);
-
其他的门描述符的中断处理程序为ignore_int;
而trap_init()所做的异常与陷阱初始化,就是修改中断向量表的前19项(异常和中断),主要修改他们的中断处理函数入口和权限位,特殊的如任务门还会设置它们的段选择符。在trap_init()中就已经把所有的异常和陷阱都初始化完成了,并会把新的中断向量表地址放入idtr寄存器,开始使用新的中断向量表。
在early_irq_init()中,主要工作是初始化整个中断描述符表,将数组中的每个中断描述符中的必要变量进行初始化,最后在init_IRQ()中,主要工作是初始化中断向量表中的所有中断门描述符,对于一般的中断,内核将它们的中断处理函数入口设置为interrupt[i],而一些特殊的中断会在apic_intr_init()中进行设置。之后,init_IRQ()会初始化内部和外部的中断控制器,最后将一般的中断使用的中断控制器设置为i8259A,中断处理函数为handle_level_irq(电平触发)。
3.2中断运行流程
(2)禁止调度和抢占
首先我们需要了解,当系统处于中断上下文时,是禁止发生调度和抢占的。进程的thread_info中有个preempt_count成员变量,其作为一个变量,包含了3个计数器和一个标志位,如下:
| 位 | 描述 | 解释 |
|---|---|---|
| 0~7 | 抢占计数器 | 也可以说是锁占用数 |
| 8~15 | 软中断计数器 | 记录软中断被禁用次数,0表示可以进行软中断。 |
| 16~27 | 硬中断计数器 | 表示中断处理嵌套次数,irq_enter()增加它,irq_exit()减少它。 |
| 28 | PREEMPT_ACTIVE标志 | 表示正在进行内核抢占,设置此标志也禁止了抢占。 |
当进入到中断时,中断处理程序会调用irq_enter()函数禁止抢占和调度。当中断退出时,会通过irq_exit()减少其硬件计数器。我们需要清楚的就是,无论系统处于硬中断还是软中断,调度和抢占都是被禁止的。
(2)中断产生
我们需要先明确一下,中断控制器与CPU相连的三种线:INTR、数据线、INTA。
在硬件电路中,中断的产生发生一般只有两种,分别是:电平触发方式和边沿触发方式。当一个外部设备产生中断,中断信号会沿着中断线到达中断控制器。中断控制器接收到该外部设备的中断信号后首先会检测自己的中断屏蔽寄存器是否屏蔽该中断。
如果没有,则设置中断请求寄存器中中断向量号对应的位,并将INTR拉高用于通知CPU,CPU每当执行完一条指令时都会去检查INTR引脚是否有信号(这是CPU自动进行的),如果有信号,CPU还会检查EFLAGS寄存器的IF标志位是否禁止了中断(IF = 0),如果CPU未禁止中断,CPU会自动通过INTA信号线应答中断控制器。CPU再次通过INTA信号线通知中断控制器,此时中断控制器会把中断向量号送到数据线上,CPU读取数据线获取中断向量号。到这里实际上中断向量号已经发送给CPU了,如果中断控制器是AEIO模式,则会自动清除中断向量号对应的中断请求寄存器的位,如果是EIO模式,则等待CPU发送的EIO信号后在清除中断向量号对应的中断请求寄存器的位。
用步骤描述就是:
-
中断控制器收到中断信号
-
中断控制器检查中断屏蔽寄存器是否屏蔽该中断,若屏蔽直接丢弃
-
中断控制器设置该中断所在的中断请求寄存器位
-
通过INTR通知CPU
-
CPU收到INTR信号,检查是否屏蔽中断,若屏蔽直接无视
-
CPU通过INTA应答中断控制器
-
CPU再次通过INTA应答中断控制器,中断控制器将中断向量号放入数据线
-
CPU读取数据线上的中断向量号
-
若中断控制器为EIO模式,CPU发送EIO信号给中断控制器,中断控制器清除中断向量号对应中断请求寄存器位
SMP系统
在SMP系统,也就是多核情况下,外部的中断控制器有可能会于多个CPU相连,这时候当一个中断产生时,中断控制器有两种方式将此中断送到CPU上,分别是静态分发和动态分发。区别就是静态分发设置了指定中断送往指定的一个或多个CPU上。动态分发则是由中断控制器控制中断应该发往哪个CPU或CPU组。
CPU已经接收到了中断信号以及中断向量号。此时CPU会自动跳转到中断描述符表地址,以中断向量号作为一个偏移量,直接访问中断向量号对应的门描述符。在门描述符中,有个特权级(DPL),系统会先检查这个位,然后清除EFLAGS的IF标志位(这也说明了发发生中断时实际上CPU是禁止其他可屏蔽中断的),之后转到描述符中的中断处理程序中。在上一篇文章我们知道,所有的中断门描述符的中断处理程序都被初始化成了interrupt[i],它是一段汇编代码。
(3)中断和异常发生时CPU自动完成的工作
我们先注意看一下中断描述符表,里面的每个中断描述符都有一个段选择符和一个偏移量以及一个DPL(特权级),而偏移量其实就是中断处理程序的入口地址,当中断或异常发生时:
-
CPU首先会确定是中断或异常的向量号,然后根据这个向量号作为偏移量,通过读取idtr中保存的中断向量表(IDT)的基地址获取相应的门描述符。并从门描述符中拿出其中的段选择符
-
根据段选择符从GDT中获取这个段的段描述符(为什么只从GDT中获取?因为初始化所有中段描述符时使用的段选择符几乎都是__USER_CS,__KERNEL_CS,TSS,这几个段选择符对应的段描述符都保存在GDT中)。而这几个段描述符中的基地址都是0x00000000,所以偏移量就是中断处理程序入口地址。
-
这时还没有进入到中断处理程序,CPU会先使用CS寄存器的当前特权级(CPL)与中断向量描述符中对应的段描述符的DPL进行比较,如果DPL的值 <= CPL的值,则通过检查,而DPL的值 > CPL的值时,会产生一个"通用保护"异常。这种情况发生的可能性很小,因为在上一篇初始化的文章中也可以看出来,中断初始化所用的段选择符都是__KERNEL_CS,而异常的段选择符几乎也都是__KERNEL_CS,只除了极特殊的几个除外。也就是大多数中断和异常的段选择符DPL都是0,CPL无论是在内核态(CPL = 0)或者是用户态(CPL = 3),都可以执行这些中断和异常。这里的检查可以理解为检查是否需要切换段。
-
如果是用户程序的异常(非CPU内部产生的异常),这里还需要再进行多一步的检查(中断和CPU内部异常则不用进行这步检查), 我们回忆一下中断初始化的文章,里面介绍了门描述符,在门描述符中也有一个DPL位,用户程序的异常还要对这个位进行检查,当前特权级CPL的值 <= DPL的值时,则通过检查,否则不能通过检查,而只有系统门和系统中断门的DPL是3,其他的异常门的DPL都为0。这样做的好处是避免了用户程序访问陷阱门、中断门和任务门。 (这里可以理解为进入此"门"的权限, 所以只有系统门和系统中断门是程序能够主动进入的, 也就是我们做系统调用走的门)
-
如果以上检查都通过,并且CS寄存器的特权级发生变化(用户态陷入内核),则CPU会访问此CPU的TSS段(通过tr寄存器),在TSS段中读取当前进程的SS和ESP到SS和ESP寄存器中,这样就完成了用户态栈到内核态栈的切换。之后把之前的SS寄存器和ESP寄存器的值保存到当前内核栈中。
-
将eflags、CS、EIP寄存器的值压入内核栈中。这样就保存了返回后需要执行的上下文。
-
最后将刚才获取到的段选择符加载到CS寄存器(CS段切换),段描述符加载到CS对应的非编程寄存器中,也就是CS寄存器保存的是__KERNEL_CS,CS寄存器的非编程寄存器中保存的是对应的段描述符。而根据段描述符中的段基址+段内偏移量(保存在门描述符中),则得到了处理程序入口地址,实际上我们知道段基址是0x00000000,段内偏移量实际上就是处理程序入口地址,这个门描述符的段内偏移量会被放到IP寄存器中。
①interrupt[i]
interrupt[i]的每个元素都相同,执行相同的汇编代码,这段汇编代码实际上很简单,它主要工作就是将中断向量号和被中断上下文(进程上下文或者中断上下文)保存到栈中,最后调用do_IRQ函数。
# 代码地址:arch/x86/kernel/entry_32.S# 开始
1: pushl_cfi $(~vector+0x80) /* Note: always in signed byte range */ # 先会执行这一句,将中断向量号取反然后加上0x80压入栈中.if ((vector-FIRST_EXTERNAL_VECTOR)%7) <> 6jmp 2f # 数字定义的标号为临时标号,可以任意重复定义,例如:"2f"代表正向第一次出现的标号"2:",3b代表反向第一次出现的标号"3:".endif.previous # .previous使汇编器返回到该自定义段之前的段进行汇编,则回到上面的数据段.long 1b # 在数据段中执行标号1的操作.section .entry.text, "ax" # 回到代码段
vector=vector+1 .endif .endr
2: jmp common_interruptcommon_interrupt:ASM_CLACaddl $-0x80,(%esp) # 此时栈顶是(~vector + 0x80),这里再加上-0x80,实际就是中断向量号取反,用于区别系统调用,系统调用是正数,中断向量是负数SAVE_ALL # 保存现场,将寄存器值压入栈中TRACE_IRQS_OFF # 关闭中断跟踪movl %esp,%eax # 将栈指针保存到eax寄存器,供do_IRQ使用call do_IRQ # 调用do_IRQjmp ret_from_intr # 跳转到ret_from_intr,进行中断返回的一些处理
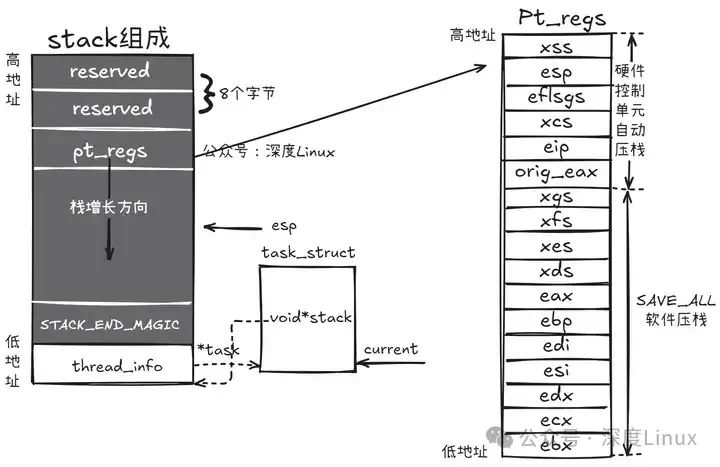
ENDPROC(common_interrupt)CFI_ENDPROC需要注意这里面有一个SAVE_ALL是用于保存用户态寄存器值的,在上面的文章中有提到CPU会自动保存原来特权级的段和栈到内核栈中,但是通用寄存器并不会保存,所以这里会有个SAVE_ALL来保存通用寄存器的值。所以当SAVE_ALL执行完后,所有的上下文都已经保存完毕,最后结果如下:
②do_IRQ
这是中断处理的核心函数,来到这里时,系统已经做了两件事
-
系统屏蔽了所有可屏蔽中断(清除了CPU的IF标志位,由CPU自动完成)
-
将中断向量号和所有寄存器值保存到内核栈中
在do_IRQ中,首先会添加硬中断计数器,此行为导致了中断期间禁止调度发送,此后会根据中断向量号从vector_irq[]数组中获取对应的中断号,并调用handle_irq()函数出来该中断号对应的中断出来例程。
__visible unsigned int __irq_entry do_IRQ(struct pt_regs *regs)
{/* 将栈顶地址保存到全局变量__irq_regs中,old_regs用于保存现在的__irq_regs值,这一行代码很重要,实现了嵌套中断情况下的现场保存与还原 */struct pt_regs *old_regs = set_irq_regs(regs);/* 获取中断向量号,因为中断向量号是以取反方式保存的,这里再次取反 */unsigned vector = ~regs->orig_ax;/* 中断向量号 */unsigned irq;/* 硬中断计数器增加,硬中断计数器保存在preempt_count */irq_enter();/* 这里开始禁止调度,因为preempt_count不为0 *//* 退出idle进程(如果当前进程是idle进程的情况下) */exit_idle();/* 根据中断向量号获取中断号 */irq = __this_cpu_read(vector_irq[vector]);/* 主要函数是handle_irq,进行中断服务例程的处理 */if (!handle_irq(irq, regs)) {/* EIO模式的应答 */ack_APIC_irq();/* 该中断号并没有发生过多次触发 */if (irq != VECTOR_RETRIGGERED) {pr_emerg_ratelimited("%s: %d.%d No irq handler for vector (irq %d)\n",__func__, smp_processor_id(),vector, irq);} else {/* 将此中断向量号对应的vector_irq设置为未定义 */__this_cpu_write(vector_irq[vector], VECTOR_UNDEFINED);}}/* 硬中断计数器减少 */irq_exit();/* 这里开始允许调度 *//* 恢复原来的__irq_regs值 */set_irq_regs(old_regs);return 1;
}do_IRQ()函数中最重要的就是handle_irq()处理了,我们看看:
bool handle_irq(unsigned irq, struct pt_regs *regs)
{struct irq_desc *desc;int overflow;/* 检查栈是否溢出 */overflow = check_stack_overflow();/* 获取中断描述符 */desc = irq_to_desc(irq);/* 检查是否获取到中断描述符 */if (unlikely(!desc))return false;/* 检查使用的栈,有两种情况,如果进程的内核栈配置为8K,则使用进程的内核栈,如果为4K,系统会专门为所有中断分配一个4K的栈专门用于硬中断处理栈,一个4K专门用于软中断处理栈,还有一个4K专门用于异常处理栈 */if (user_mode_vm(regs) || !execute_on_irq_stack(overflow, desc, irq)) {if (unlikely(overflow))print_stack_overflow();/* 执行handle_irq */desc->handle_irq(irq, desc);}return true;
}好的,最后执行中断描述符中的handle_irq指针所指函数,我们回忆一下,在初始化阶段,所有的中断描述符的handle_irq指针指向了handle_level_irq()函数,文章开头我们也说过,中断产生方式有两种:一种电平触发、一种是边沿触发。handle_level_irq()函数就是用于处理电平触发的情况,系统内建了一些handle_irq函数,具体定义在include/linux/irq.h文件中,我们罗列几种常用的:
-
handle_simple_irq() 简单处理情况处理函数
-
handle_level_irq() 电平触发方式情况处理函数
-
handle_edge_irq() 边沿触发方式情况处理函数
-
handle_fasteoi_irq() 用于需要EOI回应的中断控制器
-
handle_percpu_irq() 此中断只需要单一CPU响应的处理函数
-
handle_nested_irq() 用于处理使用线程的嵌套中断
我们主要看看handle_level_irq()函数函数,有兴趣的朋友也可以看看其他的,因为触发方式不同,通知中断控制器、CPU屏蔽、中断状态设置的时机都不同,它们的代码都在kernel/irq/chip.c中。
/* 用于电平中断,电平中断特点:* 只要设备的中断请求引脚(中断线)保持在预设的触发电平,中断就会一直被请求,所以,为了避免同一中断被重复响应,必须在处理中断前先把mask irq,然后ack irq,以便复位设备的中断请求引脚,响应完成后再unmask irq*/
void
handle_level_irq(unsigned int irq, struct irq_desc *desc)
{raw_spin_lock(&desc->lock);/* 通知中断控制器屏蔽该中断线,并设置中断描述符屏蔽该中断 */mask_ack_irq(desc);/* 检查此irq是否处于运行状态,也就是检查IRQD_IRQ_INPROGRESS标志和IRQD_WAKEUP_ARMED标志。大家可以看看,还会检查poll */if (!irq_may_run(desc))goto out_unlock;desc->istate &= ~(IRQS_REPLAY | IRQS_WAITING);/* 增加此中断号所在proc中的中断次数 */kstat_incr_irqs_this_cpu(irq, desc);/** If its disabled or no action available* keep it masked and get out of here*//* 判断IRQ是否有中断服务例程(irqaction)和是否被系统禁用 */if (unlikely(!desc->action || irqd_irq_disabled(&desc->irq_data))) {desc->istate |= IRQS_PENDING;goto out_unlock;}/* 在里面执行中断服务例程 */handle_irq_event(desc);/* 通知中断控制器恢复此中断线 */cond_unmask_irq(desc);out_unlock:raw_spin_unlock(&desc->lock);
}这个函数还是比较简单,看handle_irq_event()函数:
irqreturn_t handle_irq_event(struct irq_desc *desc)
{struct irqaction *action = desc->action;irqreturn_t ret;desc->istate &= ~IRQS_PENDING;/* 设置该中断处理正在执行,设置此中断号的状态为IRQD_IRQ_INPROGRESS */irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS);raw_spin_unlock(&desc->lock);/* 主要,具体看 */ret = handle_irq_event_percpu(desc, action);raw_spin_lock(&desc->lock);/* 取消此中断号的IRQD_IRQ_INPROGRESS状态 */irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS);return ret;
}再看handle_irq_event_percpu()函数:
irqreturn_t
handle_irq_event_percpu(struct irq_desc *desc, struct irqaction *action)
{irqreturn_t retval = IRQ_NONE;unsigned int flags = 0, irq = desc->irq_data.irq;/* desc中的action是一个链表,每个节点包含一个处理函数,这个循环是遍历一次action链表,分别执行一次它们的处理函数 */do {irqreturn_t res;/* 用于中断跟踪 */trace_irq_handler_entry(irq, action);/* 执行处理,在驱动中定义的中断处理最后就是被赋值到中断服务例程action的handler指针上,这里就执行了驱动中定义的中断处理 */res = action->handler(irq, action->dev_id);trace_irq_handler_exit(irq, action, res);if (WARN_ONCE(!irqs_disabled(),"irq %u handler %pF enabled interrupts\n",irq, action->handler))local_irq_disable();/* 中断返回值处理 */switch (res) {/* 需要唤醒该中断处理例程的中断线程 */case IRQ_WAKE_THREAD:/** Catch drivers which return WAKE_THREAD but* did not set up a thread function*//* 该中断服务例程没有中断线程 */if (unlikely(!action->thread_fn)) {warn_no_thread(irq, action);break;}/* 唤醒线程 */__irq_wake_thread(desc, action);/* Fall through to add to randomness */case IRQ_HANDLED:flags |= action->flags;break;default:break;}retval |= res;/* 下一个中断服务例程 */action = action->next;} while (action);add_interrupt_randomness(irq, flags);/* 中断调试会使用 */if (!noirqdebug)note_interrupt(irq, desc, retval);return retval;
}其实代码上很简单,我们需要注意几个屏蔽中断的方式:清除EFLAGS的IF标志、通知中断控制器屏蔽指定中断、设置中断描述符的状态为IRQD_IRQ_INPROGRESS。在上述代码中这三种状态都使用到了,我们具体解释一下:
-
清除EFLAGS的IF标志:CPU禁止中断,当CPU进入到中断处理时自动会清除EFLAGS的IF标志,也就是进入中断处理时会自动禁止中断。在SMP系统中,就是单个CPU禁止中断。
-
通知中断控制器屏蔽指定中断:在中断控制器处就屏蔽中断,这样该中断产生后并不会发到CPU上。在SMP系统中,效果相当于所有CPU屏蔽了此中断。系统在执行此中断的中断处理函数才会要求中断控制器屏蔽该中断,所以没必要在此中断的处理过程中中断控制器再发一次中断信号给CPU。
-
设置中断描述符的状态为IRQD_IRQ_INPROGRESS:在SMP系统中,同一个中断信号有可能发往多个CPU,但是中断处理只应该处理一次,所以设置状态为IRQD_IRQ_INPROGRESS,其他CPU执行此中断时都会先检查此状态(可看handle_level_irq()函数)。
所以在SMP系统下,对于handle_level_irq而言,一次典型的情况是:中断控制器接收到中断信号,发送给一个或多个CPU,收到的CPU会自动禁止中断,并执行中断处理函数,在中断处理函数中CPU会通知中断控制器屏蔽该中断,之后当执行中断服务例程时会设置该中断描述符的状态为IRQD_IRQ_INPROGRESS,表明其他CPU如果执行该中断就直接退出,因为本CPU已经在处理了。
四、中断的上半部与下半部处理
在 Linux 中断处理的复杂体系中,中断的处理过程被巧妙地划分为上半部和下半部,这种设计模式旨在实现中断处理的高效性与及时性,充分满足系统对不同类型任务处理的需求。
4.1 上半部:快速响应硬件
上半部在中断处理流程中扮演着至关重要的 “先锋官” 角色,其主要任务是对硬件中断进行迅速响应,执行那些对时间极为敏感、需要立即完成的关键操作。当硬件设备产生中断信号时,上半部会立即被触发,它会迅速读取硬件设备的状态信息,以了解中断产生的具体原因和相关情况,然后及时清除中断标志,向硬件设备表明中断已经被响应,避免中断信号的持续干扰。在处理网卡中断时,上半部会迅速读取网卡的寄存器状态,获取数据包的基本信息,并清除网卡的中断标志,确保网卡能够继续正常工作,接收后续的数据包。
上半部在中断处理中具有关键作用,它是系统与硬件设备之间的 “快速通道”,能够确保硬件设备的请求得到及时处理,维持系统的实时性和稳定性。由于硬件中断可能随时发生,并且具有较高的优先级,如果上半部不能快速执行,就会导致其他中断无法及时响应,从而使系统的响应速度大幅下降,甚至可能影响整个系统的正常运行。因此,上半部的代码通常需要经过精心优化,以确保其能够在最短的时间内完成任务,快速释放中断线,让系统能够及时处理其他中断请求。上半部还需要与下半部密切配合,将那些耗时较长、对时间敏感度较低的任务传递给下半部进行处理,从而实现中断处理的高效分工。
4.2 下半部:延迟处理任务
下半部作为中断处理的 “后续保障部队”,主要负责处理那些在上半部无法完成的耗时任务。这些任务通常与硬件设备的基本操作关联不大,但又需要对中断事件进行进一步的处理和分析。当下半部被触发时,它会根据上半部传递过来的信息,对中断事件进行深入处理,如数据的进一步加工、存储、传输等。在处理磁盘中断时,上半部可能只是简单地读取磁盘控制器的状态并清除中断标志,而将数据从磁盘缓冲区读取到内存中的操作则会交给下半部来完成。
下半部在处理耗时任务时具有明显的优势,它能够避免阻塞系统的运行。由于下半部的任务通常不需要立即完成,因此可以在系统相对空闲的时候进行处理,不会影响系统对其他紧急事件的响应能力。下半部在执行任务时可以打开中断,允许其他中断的发生,这使得系统在处理耗时任务的同时,仍然能够及时响应其他硬件设备的请求,提高了系统的并发处理能力。下半部与上半部之间存在着紧密的协作关系,上半部负责快速响应硬件中断,为下半部的处理提供必要的信息和准备工作;下半部则根据上半部的结果,对中断事件进行全面而细致的处理,完成整个中断处理的任务。
4.3 软中断、Tasklet 和工作队列
在 Linux 系统中,下半部的实现主要依赖于软中断、Tasklet 和工作队列这三种机制,它们各自具有独特的特点和适用场景,为 Linux 系统的中断处理提供了丰富的选择。
我们看到中断实际分为了两个部分,俗称就是一部分是硬中断,一部分是软中断。软中断是专门用于处理中断过程中费时费力的操作,而为什么系统要分硬中断和软中断呢?问得明白点就是为什么需要软中断。我们可以试着想想,如果只有硬中断的情况下,我们需要在中断处理过程中执行一些耗时的操作,比如浮点数运算,复杂算法的运算时,其他的外部中断就不能得到及时的响应,因为在硬中断过程中中断是关闭着的,甚至一些很紧急的中断会得不到响应,系统稳定性和及时性都受到很大影响。
所以linux为了解决上述这种情况,将中断处理分为了两个部分,硬中断和软中断。首先一个外部中断得到响应时,会先关中断,并进入到硬中断完成较为紧急的操作,然后开中断,并在软中断执行那些非紧急、可延时执行的操作;在这种情况下,紧急操作可以立即执行,而其他的外部中断也可以获得一个较为快速的响应。这也是软中断存在的必要性。在软中断过程中是不可以被抢占也不能被阻塞的,也不能在一个给定的CPU上交错执行。
(1)软中断详解
软中断是在中断框架中专门用于处理非紧急操作的,在SMP系统中,软中断可以并发地运行在多个CPU上,但在一些路径在需要使用自旋锁进行保护。在系统中,很多东西都分优先级,软中断也不例外,有些软中断要求更快速的响应运行,在内核中软中断一共分为10个,同时也代表着10种不同的优先级,系统用一个枚举变量表示:
enum
{HI_SOFTIRQ=0, /* 高优先级tasklet */ /* 优先级最高 */TIMER_SOFTIRQ, /* 时钟相关的软中断 */NET_TX_SOFTIRQ, /* 将数据包传送到网卡 */NET_RX_SOFTIRQ, /* 从网卡接收数据包 */BLOCK_SOFTIRQ, /* 块设备的软中断 */BLOCK_IOPOLL_SOFTIRQ, /* 支持IO轮询的块设备软中断 */TASKLET_SOFTIRQ, /* 常规tasklet */SCHED_SOFTIRQ, /* 调度程序软中断 */HRTIMER_SOFTIRQ, /* 高精度计时器软中断 */RCU_SOFTIRQ, /* RCU锁软中断,该软中断总是最后一个软中断 */ /* 优先级最低 */NR_SOFTIRQS /* 软中断数,为10 */
};注释中的tasklet我们之后会说明,这里先无视它。每一个优先级的软中断都使用一个struct softirq_action结构来表示,在这个结构中,只有一个成员变量,就是action函数指针,因为不同的软中断它的处理方式可能不同,从优先级表中就可以看出来,有块设备的,也有网卡处理的。系统将这10个软中断用softirq_vec[10]的数组进行保存。
/* 用于描述一个软中断 */
struct softirq_action
{/* 此软中断的处理函数 */ void (*action)(struct softirq_action *);
};/* 10个软中断描述符都保存在此数组 */
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;系统一般使用open_softirq()函数进行软中断描述符的初始化,主要就是将action函数指针指向该软中断应该执行的函数。在start_kernel()进行系统初始化中,就调用了softirq_init()函数对HI_SOFTIRQ和TASKLET_SOFTIRQ两个软中断进行了初始化
void __init softirq_init(void)
{int cpu;for_each_possible_cpu(cpu) {per_cpu(tasklet_vec, cpu).tail =&per_cpu(tasklet_vec, cpu).head;per_cpu(tasklet_hi_vec, cpu).tail =&per_cpu(tasklet_hi_vec, cpu).head;}/* 开启常规tasklet */open_softirq(TASKLET_SOFTIRQ, tasklet_action);/* 开启高优先级tasklet */open_softirq(HI_SOFTIRQ, tasklet_hi_action);
}/* 开启软中断 */
void open_softirq(int nr, void (*action)(struct softirq_action *))
{softirq_vec[nr].action = action;
}
可以看到,TASKLET_SOFTIRQ的action操作使用了tasklet_action()函数,HI_SOFTIRQ的action操作使用了tasklet_hi_action()函数,这两个函数我们需要结合tasklet进行说明。我们也可以看看其他的软中断使用了什么函数:
open_softirq(TIMER_SOFTIRQ, run_timer_softirq);
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
open_softirq(BLOCK_SOFTIRQ, blk_done_softirq);
open_softirq(BLOCK_IOPOLL_SOFTIRQ, blk_iopoll_softirq);
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
open_softirq(HRTIMER_SOFTIRQ, run_hrtimer_softirq);
open_softirq(RCU_SOFTIRQ, rcu_process_callbacks);实很明显可以看出,除了TASKLET_SOFTIRQ和HI_SOFTIRQ,其他的软中断更多地是用于特定的设备和环境,对于我们普通的IO驱动和设备而已,使用的软中断几乎都是TASKLET_SOFTIRQ和HI_SOFTIRQ,而系统为了对这些不同IO设备进行统一的处理,就在TASKLET_SOFTIRQ和HI_SOFTIRQ的action函数中使用到了tasklet。
对于每个CPU,都有一个irq_cpustat_t的数据结构,里面有一个__softirq_pending变量,这个变量很重要,用于表示该CPU的哪个软中断处于挂起状态,在软中断处理时可以根据此值跳过不需要处理的软中断,直接处理需要处理的软中断。内核使用local_softirq_pending()获取此CPU的__softirq_pending的值。
当使用open_softirq设置好某个软中断的action指针后,该软中断就会开始可以使用了,其实更明了地说,从中断初始化完成开始,即使所有的软中断都没有使用open_softirq()进行初始化,软中断都已经开始使用了,只是所有软中断的action都为空,系统每次执行到软中断都没有软中断需要执行罢了。
在每个CPU上一次软中断处理的一个典型流程是:
-
硬中断执行完毕,开中断。
-
检查该CPU是否处于嵌套中断的情况,如果处于嵌套中,则不执行软中断,也就是在最外层中断才执行软中断。
-
执行软中断,设置一个软中断执行最多使用时间和循环次数(10次)。
-
进入循环,获取CPU的__softirq_pending的副本。
-
执行此__softirq_pending副本中所有需要执行的软中断。
-
如果软中断执行完毕,退出中断上下文。
-
如果还有软中断需要执行(在软中断期间又发发生了中断,产生了新的软中断,新的软中断记录在CPU的__softirq_pending上,而我们的__softirq_pending只是个副本)。
-
检查此次软中断总共使用的时间和循环次数,条件允许继续执行软中断,循环次数减一,并跳转到第4步。
我们具体看一下代码,首先在irq_exit()中会检查是否需要进行软中断处理:
void irq_exit(void)
{
#ifndef __ARCH_IRQ_EXIT_IRQS_DISABLEDlocal_irq_disable();
#elseWARN_ON_ONCE(!irqs_disabled());
#endifaccount_irq_exit_time(current);/* 减少preempt_count的硬中断计数器 */preempt_count_sub(HARDIRQ_OFFSET);/* in_interrupt()会检查preempt_count上的软中断计数器和硬中断计数器来判断是否处于中断嵌套中 *//* local_softirq_pending()则会检查该CPU的__softirq_pending变量,是否有软中断挂起 */if (!in_interrupt() && local_softirq_pending())invoke_softirq();tick_irq_exit();rcu_irq_exit();trace_hardirq_exit(); /* must be last! */
}我们再进入到invoke_softirq():
static inline void invoke_softirq(void)
{if (!force_irqthreads) {
#ifdef CONFIG_HAVE_IRQ_EXIT_ON_IRQ_STACK/** We can safely execute softirq on the current stack if* it is the irq stack, because it should be near empty* at this stage.*//* 软中断处理函数 */__do_softirq();
#else/** Otherwise, irq_exit() is called on the task stack that can* be potentially deep already. So call softirq in its own stack* to prevent from any overrun.*/do_softirq_own_stack();
#endif} else {/* 如果强制使用软中断线程进行软中断处理,会通知调度器唤醒软中断线程ksoftirqd */wakeup_softirqd();}
}重头戏就在__do_softirq()中,我已经注释好了,方便大家看:
asmlinkage __visible void __do_softirq(void)
{/* 为了防止软中断执行时间太长,设置了一个软中断结束时间 */unsigned long end = jiffies + MAX_SOFTIRQ_TIME;/* 保存当前进程的标志 */unsigned long old_flags = current->flags;/* 软中断循环执行次数: 10次 */int max_restart = MAX_SOFTIRQ_RESTART;/* 软中断的action指针 */struct softirq_action *h;bool in_hardirq;__u32 pending;int softirq_bit;/** Mask out PF_MEMALLOC s current task context is borrowed for the* softirq. A softirq handled such as network RX might set PF_MEMALLOC* again if the socket is related to swap*/current->flags &= ~PF_MEMALLOC;/* 获取此CPU的__softirq_pengding变量值 */pending = local_softirq_pending();/* 用于统计进程被软中断使用时间 */account_irq_enter_time(current);/* 增加preempt_count软中断计数器,也表明禁止了调度 */__local_bh_disable_ip(_RET_IP_, SOFTIRQ_OFFSET);in_hardirq = lockdep_softirq_start();/* 循环10次的入口,每次循环都会把所有挂起需要执行的软中断执行一遍 */
restart:/* 该CPU的__softirq_pending清零,当前的__softirq_pending保存在pending变量中 *//* 这样做就保证了新的软中断会在下次循环中执行 */set_softirq_pending(0);/* 开中断 */local_irq_enable();/* h指向软中断数组头 */h = softirq_vec;/* 每次获取最高优先级的已挂起软中断 */while ((softirq_bit = ffs(pending))) {unsigned int vec_nr;int prev_count;/* 获取此软中断描述符地址 */h += softirq_bit - 1;/* 减去软中断描述符数组首地址,获得软中断号 */vec_nr = h - softirq_vec;/* 获取preempt_count的值 */prev_count = preempt_count();/* 增加统计中该软中断发生次数 */kstat_incr_softirqs_this_cpu(vec_nr);trace_softirq_entry(vec_nr);/* 执行该软中断的action操作 */h->action(h);trace_softirq_exit(vec_nr);/* 之前保存的preempt_count并不等于当前的preempt_count的情况处理,也是简单的把之前的复制到当前的preempt_count上,这样做是防止最后软中断计数不为0导致系统不能够执行调度 */if (unlikely(prev_count != preempt_count())) {pr_err("huh, entered softirq %u %s %p with preempt_count %08x, exited with %08x?\n",vec_nr, softirq_to_name[vec_nr], h->action,prev_count, preempt_count());preempt_count_set(prev_count);}/* h指向下一个软中断,但下个软中断并不一定需要执行,这里只是配合softirq_bit做到一个处理 */h++;pending >>= softirq_bit;}rcu_bh_qs();/* 关中断 */local_irq_disable();/* 循环结束后再次获取CPU的__softirq_pending变量,为了检查是否还有软中断未执行 */pending = local_softirq_pending();/* 还有软中断需要执行 */if (pending) {/* 在还有软中断需要执行的情况下,如果时间片没有执行完,并且循环次数也没到10次,继续执行软中断 */if (time_before(jiffies, end) && !need_resched() &&--max_restart)goto restart;/* 这里是有软中断挂起,但是软中断时间和循环次数已经用完,通知调度器唤醒软中断线程去执行挂起的软中断,软中断线程是ksoftirqd,这里只起到一个通知作用,因为在中断上下文中是禁止调度的 */wakeup_softirqd();}lockdep_softirq_end(in_hardirq);/* 用于统计进程被软中断使用时间 */account_irq_exit_time(current);/* 减少preempt_count中的软中断计数器 */__local_bh_enable(SOFTIRQ_OFFSET);WARN_ON_ONCE(in_interrupt());/* 还原进程标志 */tsk_restore_flags(current, old_flags, PF_MEMALLOC);
}流程就和上面所说的一致,如果还有不懂,可以去内核代码目录/kernel/softirq.c查看源码。
(2)tasklet
软中断有多种,部分种类有自己特殊的处理,如从NET_TX_SOFTIRQ和NET_RT_SOFTIRQ、BLOCK_SOFTIRQ等,而如HI_SOFTIRQ和TASKLET_SOFTIRQ则是专门使用tasklet。它是在I/O驱动程序中实现可延迟函数的首选方法,如上一句所说,它建立在HI_SOFTIRQ和TASKLET_SOFTIRQ这两种软中断之上,多个tasklet可以与同一个软中断相关联,系统会使用一个链表组织他们,而每个tasklet执行自己的函数处理。而HI_SOFTIRQ和TASKLET_SOFTIRQ这两个软中断并没有什么区别,他们只是优先级上的不同而已,系统会先执行HI_SOFTIRQ的tasklet,再执行TASKLET_SOFTIRQ的tasklet。同一个tasklet不能同时在几个CPU上执行,一个tasklet在一个时间上只能在一个CPU的软中断链上,不能同时在多个CPU的软中断链上,并且当这个tasklet正在执行时,其他CPU不能够执行这个tasklet。也就是说,tasklet不必要编写成可重入的函数。
系统会为每个CPU维护两个链表,用于保存HI_SOFTIRQ的tasklet和TASKLET_SOFTIRQ的tasklet,这两个链表是tasklet_vec和tasklet_hi_vec,它们都是双向链表,如下:
struct tasklet_head {struct tasklet_struct *head;struct tasklet_struct **tail;
};static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);在softirq_init()函数中,会将每个CPU的tasklet_vec链表和tasklet_hi_vec链表进行初始化,将他们的头尾相连,实现为一个空链表。由于tasklet_vec和tasklet_hi_vec处理方式几乎一样,只是软中断的优先级别不同,我们只需要理解系统如何对tasklet_vec进行处理即可。需要注意的是,tasklet_vec链表都是以顺序方式执行,并不会出现后一个先执行,再到前一个先执行(在软中断期间被中断的情况)。
介绍完tasklet_vec和tasklet_hi_vec链表,我们来看看tasklet,tasklet简单来说,就是一个处理函数的封装,类似于硬中断中的irqaction结构。一般来说,在一个驱动中如果需要使用tasklet进行软中断的处理,只需要一个中断对应初始化一个tasklet,它可以在每次中断产生时重复使用。系统使用tasklet_struct结构进行描述一个tasklet,而且对于同一个tasklet_struct你可以选择放在tasklet_hi_vec链表或者tasklet_vec链表上。我们来看看:
struct tasklet_struct
{struct tasklet_struct *next; /* 指向链表下一个tasklet */unsigned long state; /* tasklet状态 */atomic_t count; /* 禁止计数器,调用tasklet_disable()会增加此数,tasklet_enable()减少此数 */void (*func)(unsigned long); /* 处理函数 */unsigned long data; /* 处理函数使用的数据 */
};tasklet状态主要分为以下两种:
-
TASKLET_STATE_SCHED:这种状态表示此tasklet处于某个tasklet链表之上(可能是tasklet_vec也可能是tasklet_hi_vec)。
-
TASKLET_STATE_RUN:表示此tasklet正在运行中。
这两个状态主要就是用于防止tasklet同时在几个CPU上运行和在同一个CPU上交错执行。
而func指针就是指向相应的处理函数。在编写驱动时,我们可以使用tasklet_init()函数或者DECLARE_TASKLET宏进行一个task_struct结构的初始化,之后可以使用tasklet_schedule()或者tasklet_hi_schedule()将其放到相应链表上等待CPU运行。我们使用一张图描述一下软中断和tasklet结合运行的情况:
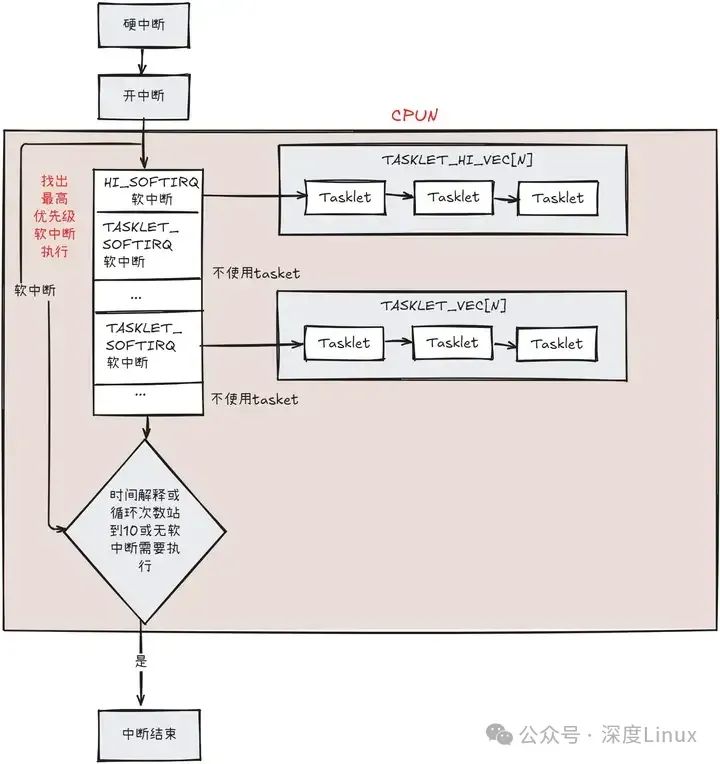
我们知道,每个软中断都有自己的action函数,在HI_SOFTIRQ和TASKLET_SOFTIRQ的action函数中,就用到了它们对应的TASKLET_HI_VEC链表和TASKLET_VEC链表,并依次顺序执行链表中的每个tasklet结点。
在SMP系统中,我们会遇到一个问题:两个CPU都需要执行同一个tasklet的情况,虽然一个tasklet只能放在一个CPU的tasklet_vec链表或者tasklet_hi_vec链表上,但是这种情况是有可能发生的,我们设想一下,中断在CPU1上得到了响应,并且它的tasklet放到了CPU1的tasklet_vec上进行执行,而当中断的tasklet上正在执行时,此中断再次发生,并在CPU2上进行了响应,此时CPU2将此中断的tasklet放到CPU2的tasklet_vec上,并执行到此中断的tasklet。
实际上,为了处理这种情况,在HI_SOFTIRQ和TASKLET_SOFTIRQ的action函数中,会先将对应的tasklet链表取出来,并把对应的tasklet链表的head和tail清空,如果在执行过程中,某个tasklet的state为TASKLET_STATE_RUN状态,说明其他CPU正在处理这个tasklet,这时候当前CPU则会把此tasklet加入到当前CPU已清空的tasklet链表的末尾,然后设置__softirq_pending变量,这样,在下次循环软中断的过程中,会再次检查这个tasklet。也就是如果其他CPU的这个tasklet一直不退出,当前CPU就会不停的置位tasklet的pending,然后不停地循环检查。
我们可以看看TASKLET_SOFTIRQ的action处理:
static void tasklet_action(struct softirq_action *a)
{struct tasklet_struct *list;local_irq_disable();/* 将tasklet链表从该CPU中拿出来 */list = __this_cpu_read(tasklet_vec.head);/* 将该CPU的此软中断的tasklet链表清空 */__this_cpu_write(tasklet_vec.head, NULL);__this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&tasklet_vec.head));local_irq_enable();/* 链表已经处于list中,并且该CPU的tasklet_vec链表为空 */while (list) {struct tasklet_struct *t = list;list = list->next;/* 检查并设置该tasklet为TASKLET_STATE_RUN状态 */if (tasklet_trylock(t)) {/* 检查是否被禁止 */if (!atomic_read(&t->count)) {/* 清除其TASKLET_STATE_SCHED状态 */if (!test_and_clear_bit(TASKLET_STATE_SCHED,&t->state))BUG();/* 执行该tasklet的func处理函数 */t->func(t->data);/* 清除该tasklet的TASKLET_STATE_RUN状态 */tasklet_unlock(t);continue;}tasklet_unlock(t);}/* 以下为tasklet为TASKLET_STATE_RUN状态下的处理 *//* 禁止中断 */local_irq_disable();/* 将此tasklet添加的该CPU的tasklet_vec链表尾部 */t->next = NULL;*__this_cpu_read(tasklet_vec.tail) = t;__this_cpu_write(tasklet_vec.tail, &(t->next));/* 设置该CPU的此软中断处于挂起状态,设置irq_cpustat_t的__sofirq_pending变量,这样在软中断的下次执行中会再次执行此tasklet */__raise_softirq_irqoff(TASKLET_SOFTIRQ);/* 开启中断 */local_irq_enable();}
}(3)软中断处理线程
当有过多软中断需要处理时,为了保证进程能够得到一个满意的响应时间,设计时给定软中断一个时间片和循环次数,当时间片和循环次数到达但软中断又没有处理完时,就会把剩下的软中断交给软中断处理线程进行处理,这个线程是一个内核线程,其作为一个普通进程,优先级是120。其核心处理函数是run_ksoftirqd(),其实此线程的处理也很简单,就是调用了上面的__do_softirq()函数,我们可以具体看看:
/* 在smpboot_thread_fun的一个死循环中被调用 */
static void run_ksoftirqd(unsigned int cpu)
{/* 禁止中断,在__do_softirq()中会开启 */local_irq_disable();/* 检查该CPU的__softirq_pending是否有软中断被挂起 */if (local_softirq_pending()) {/** We can safely run softirq on inline stack, as we are not deep* in the task stack here.*//* 执行软中断 */__do_softirq();rcu_note_context_switch(cpu);/* 开中断 */local_irq_enable();/* 检查是否需要调度 */cond_resched();return;}/* 开中断 */local_irq_enable();
}五、中断性能分析
5.1性能指标解读
在 Linux 系统中,中断性能的评估涉及多个关键指标,这些指标如同精密仪器上的刻度,精准地反映着系统的运行状态和性能表现。
中断响应时间是其中最为关键的指标之一,它是指从硬件设备发出中断请求的那一刻起,到 CPU 开始执行对应的中断处理程序所经历的时间间隔。这一指标直接体现了系统对外部事件的即时反应能力,在实时性要求极高的应用场景中,如工业自动化控制系统,传感器不断产生中断请求以汇报设备的运行状态,此时中断响应时间的长短将直接影响系统对设备状态变化的捕捉和应对速度。若响应时间过长,可能导致设备控制的延迟,进而引发生产事故。
中断处理频率同样不容忽视,它表示在单位时间内系统处理中断的次数。中断处理频率反映了系统对外部事件的处理效率和负载程度。在网络服务器中,网卡会频繁产生中断以通知系统有新的数据包到达,若中断处理频率过高,可能意味着网络流量过大,系统需要投入大量的资源来处理这些中断,从而影响其他任务的执行效率。过高的中断处理频率还可能导致 CPU 频繁切换上下文,增加系统的开销。
此外,中断处理时间也是一个重要的考量因素,它指的是中断处理程序从开始执行到执行完毕所花费的时间。中断处理时间的长短直接影响系统的整体性能和响应能力。如果中断处理时间过长,会导致 CPU 长时间被中断处理程序占用,无法及时处理其他任务,从而使系统的响应速度变慢,甚至可能造成系统的卡顿或死机。在处理磁盘 I/O 中断时,如果中断处理程序需要花费大量时间来读写磁盘数据,就会导致其他任务的执行被阻塞,影响系统的整体运行效率。
5.2 性能分析工具与方法
在 Linux 系统中,有许多实用的工具可用于中断性能分析,这些工具就像一把把精准的 “手术刀”,帮助系统管理员和开发者深入剖析系统中断性能,找出潜在的问题和瓶颈。
top 命令是一款常用的系统性能分析工具,它能够实时显示系统中各个进程的资源占用状况,包括 CPU、内存等,同时也提供了有关中断的重要信息。在 top 命令的输出结果中,“% hi” 字段表示硬中断占用 CPU 的百分比,“% si” 字段表示软中断占用 CPU 的百分比。通过观察这两个字段的值,我们可以直观地了解到系统中硬中断和软中断对 CPU 资源的消耗情况。如果 “% hi” 值过高,说明硬件中断频繁,可能是某些硬件设备出现故障或配置不当,需要进一步检查硬件连接和驱动程序;如果 “% si” 值过高,则可能表示系统中存在大量的软件中断,如网络数据包的处理、内核定时器的管理等,需要优化相关的软件代码或调整系统配置。
sar(System Activity Reporter)命令是另一个功能强大的系统性能分析工具,它可以从多个方面对系统的活动进行详细报告,其中就包括中断信息。使用 sar -I 命令可以查看系统的中断统计信息,包括每个中断源的中断次数、中断频率等。通过分析这些数据,我们可以深入了解系统中各个中断源的活动情况,找出中断频繁的设备或驱动程序。sar -I SUM 命令可以统计系统总的中断次数和中断频率,sar -I 1,2 命令可以分别查看中断源 1 和中断源 2 的中断统计信息。
除了 top 和 sar 命令外,还有一些其他的工具和方法也可用于中断性能分析。/proc/interrupts 文件记录了系统中所有中断源的中断次数和中断处理程序的相关信息,通过查看这个文件,我们可以获取系统中断的详细状态。proc/softirqs 文件则提供了软中断的运行情况,包括各种软中断的类型和计数。使用 perf 工具可以对系统进行性能剖析,它能够跟踪中断处理程序的执行过程,分析中断处理过程中的性能瓶颈,从而为优化提供有力的依据。
六、中断性能优化策略
6.1 优化中断处理程序
编写高效的中断处理程序是提升中断性能的关键所在,其要点涵盖多个重要方面。首要原则是尽量精简中断处理程序中的操作,摒弃一切不必要的计算和数据处理任务。在处理网络中断时,若仅需提取数据包的关键信息(如源 IP 地址、目的 IP 地址等),就应避免对整个数据包进行复杂的解析和处理,可将这些操作推迟到中断处理程序之后的其他任务中执行。中断处理程序应尽可能缩短执行时间,以减少对 CPU 资源的占用,从而使系统能够及时响应其他中断请求。在处理硬件设备的中断时,应迅速读取设备状态、完成必要的操作后,立即返回,避免在中断处理程序中执行耗时较长的 I/O 操作、复杂的算法计算等。
合理运用算法和数据结构同样至关重要。对于频繁访问的数据,应采用高效的数据结构进行存储和管理,以减少数据访问的时间开销。使用哈希表来存储设备状态信息,能够快速定位和获取所需数据,大大提高中断处理的效率。在算法选择上,应优先选择时间复杂度较低的算法,以确保在最短的时间内完成任务。在对数据进行排序时,选择快速排序算法而非冒泡排序算法,因为快速排序算法的平均时间复杂度为 O (n log n),而冒泡排序算法的时间复杂度为 O (n^2),在数据量较大时,快速排序算法的效率优势将更加明显。
6.2 中断亲和性设置
中断亲和性是指将特定的中断固定分配给指定的 CPU 核心进行处理,这一技术能够显著提升 CPU 缓存的利用率。在多核心 CPU 系统中,每个核心都拥有独立的缓存,当一个中断被分配到某个核心上处理时,该核心的缓存中会存储与该中断相关的数据和指令。如果后续的中断也能被分配到同一个核心上处理,就可以直接从缓存中读取数据,避免了缓存未命中带来的性能损耗,从而提高中断处理的速度和效率。在网络服务器中,将网卡中断固定分配给特定的核心处理,能够确保该核心的缓存中始终保存着与网络数据包处理相关的数据,如网络协议栈的相关信息、数据包的缓存等,当新的网络数据包到达时,该核心能够迅速从缓存中获取所需信息,快速处理中断,提高网络数据的处理速度。
设置中断亲和性的方法在 Linux 系统中较为直观。可以通过修改 /proc/irq/[中断号]/smp_affinity 文件来实现,该文件中的每一位对应一个 CPU 核心,通过设置相应位的值为 1,即可将中断绑定到对应的核心上。例如,要将中断号为 8 的中断绑定到 CPU 核心 0 和核心 1 上,可以执行命令 “echo 3 > /proc/irq/8/smp_affinity”(因为 3 的二进制表示为 0011,对应 CPU 核心 0 和核心 1)。也可以使用工具如 irqbalance 来自动管理中断亲和性,irqbalance 能够根据系统的负载情况,动态地调整中断的分配,使中断均匀地分布在各个 CPU 核心上,避免某个核心因中断负载过重而导致性能下降。
6.3 中断合并与节流
中断合并和节流是两种行之有效的优化技术,它们能够有效降低中断频率,提升系统性能。中断合并的原理是将多个连续的中断请求合并为一个中断进行处理。在网络设备中,当有大量的网络数据包到达时,如果每个数据包都产生一个中断,会导致中断频率过高,占用大量的 CPU 资源。通过中断合并技术,可以将多个数据包的中断请求合并为一个,当一定数量的数据包到达或者经过一定的时间间隔后,才产生一个中断,通知 CPU 进行处理。这样可以减少中断的次数,降低 CPU 的中断处理开销,提高系统的整体性能。
中断节流则是通过限制中断的产生频率,来控制中断对系统资源的占用。它的实现方式是在一定的时间间隔内,只允许产生一定数量的中断。在磁盘 I/O 操作中,如果磁盘频繁地产生中断,会影响系统的其他任务。通过设置中断节流,规定每 10 毫秒只允许产生一次磁盘中断,这样可以避免磁盘中断过于频繁,使 CPU 能够更合理地分配资源,同时处理其他任务。中断节流可以通过修改设备驱动程序或者使用系统提供的相关工具来实现,具体的设置参数需要根据系统的实际情况和应用需求进行调整。
6.4 案例分析与实践
在某服务器应用场景中,系统面临着高并发网络请求的挑战,大量的网络中断使得 CPU 负载居高不下,系统性能严重下降。通过深入分析,发现网络中断处理程序存在效率低下的问题,其中包含许多不必要的操作和复杂的算法,导致中断处理时间过长。中断亲和性设置不合理,网络中断在各个 CPU 核心上分布不均衡,部分核心因中断负载过重而出现性能瓶颈。
针对这些问题,采取了一系列优化措施。对网络中断处理程序进行了全面优化,去除了不必要的操作,简化了算法,将一些复杂的数据处理任务推迟到中断处理之后的工作队列中执行,大大缩短了中断处理时间。通过修改 /proc/irq/[中断号]/smp_affinity 文件,将网络中断合理地分配到多个 CPU 核心上,实现了中断亲和性的优化,使各个核心的负载更加均衡。还启用了中断合并和节流机制,减少了网络中断的频率,降低了 CPU 的中断处理开销。
经过优化后,系统性能得到了显著提升。CPU 负载从原来的经常超过 90% 降低到了 50% 左右,网络请求的响应时间从平均几十毫秒缩短到了几毫秒,系统的并发处理能力大幅提高,能够稳定地应对高并发的网络请求,满足了业务的发展需求。通过这个案例可以看出,综合运用中断性能优化策略,能够有效地解决系统中的中断性能问题,提升系统的整体性能和稳定性。在实际的系统优化过程中,需要根据具体的问题和需求,有针对性地选择和实施优化措施,不断调整和优化,以达到最佳的性能效果。