new optimizers for dl
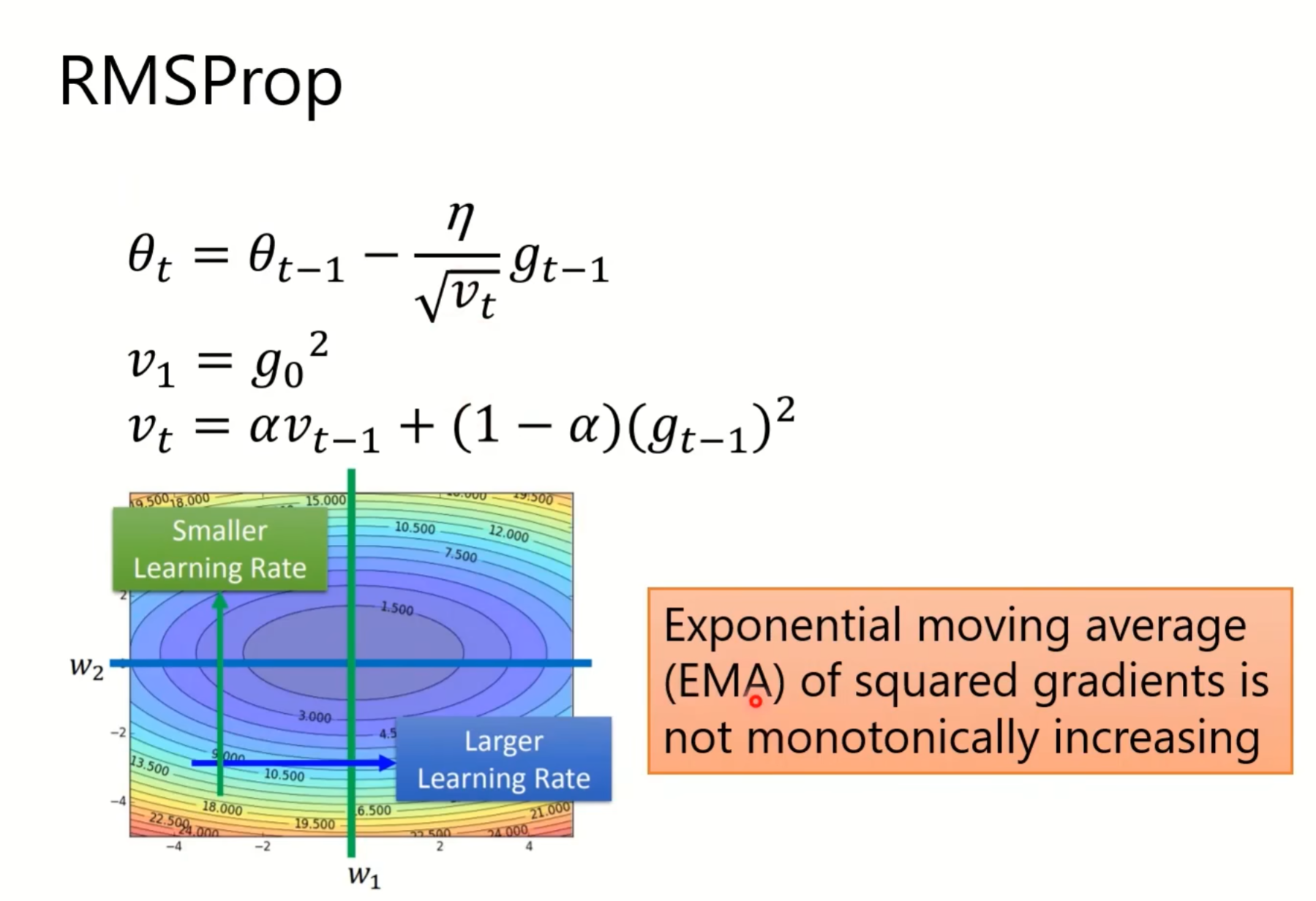
学习深度学习可能接触过这几个optimizer: SGD, SGDM(SGD with momentum), adagrad, RMSProp, adam
我们用optimization其实就是去找一组参数可以是loss最小
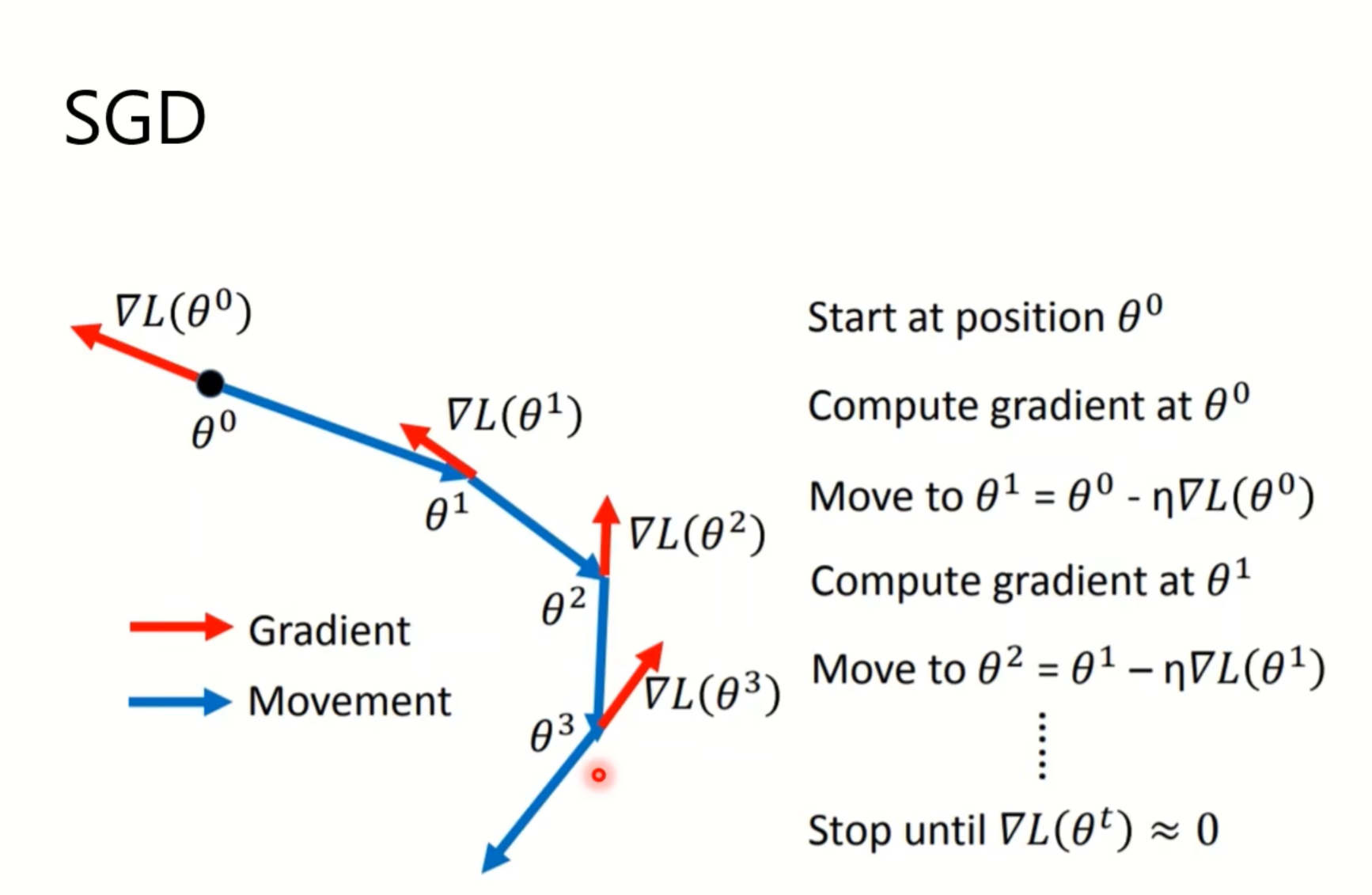
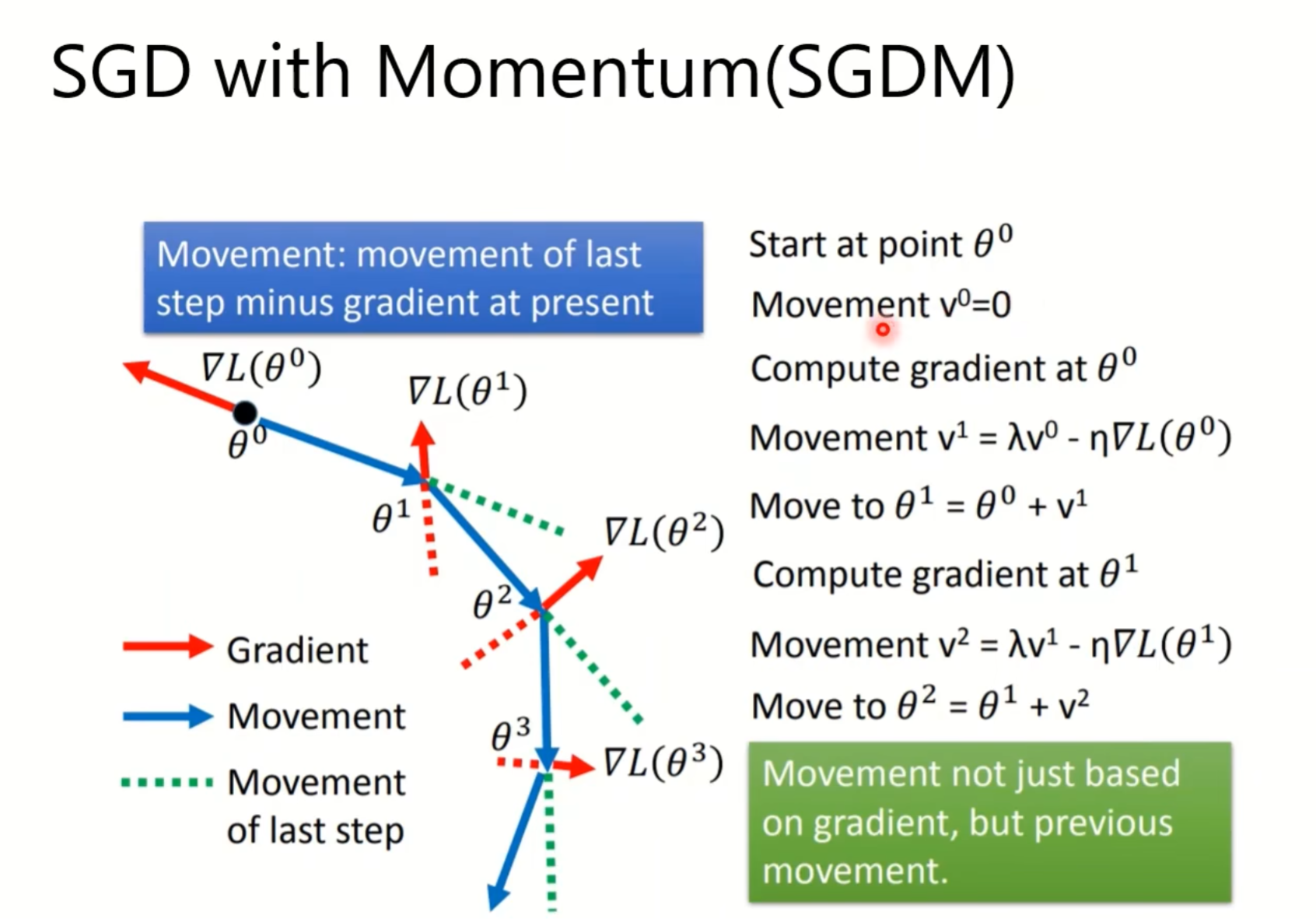
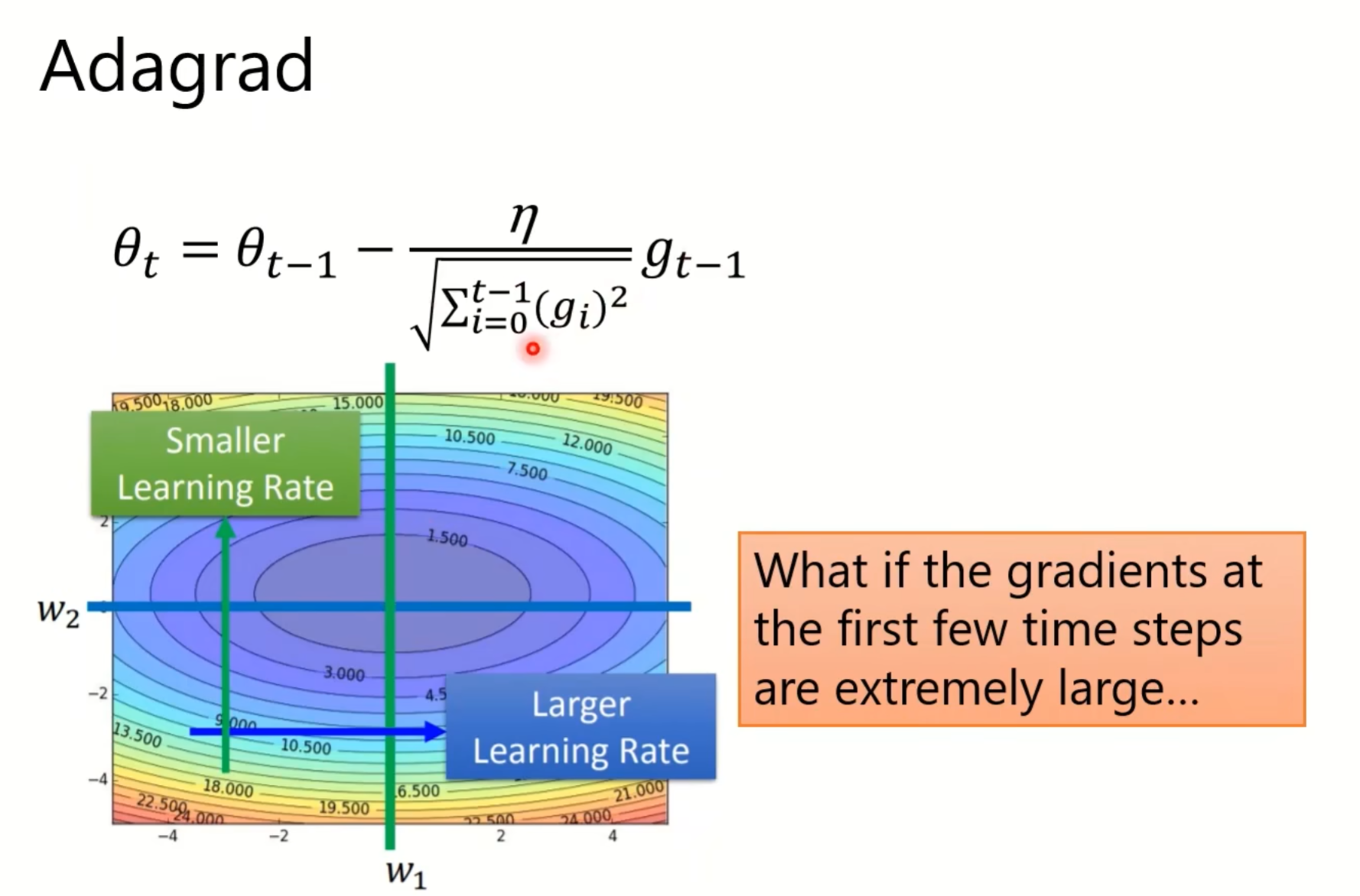

接下来是一些optimizers的应用:

最常用,也是最好用的两个optim就是adam 和 sgdm,他们之间会有些差别:
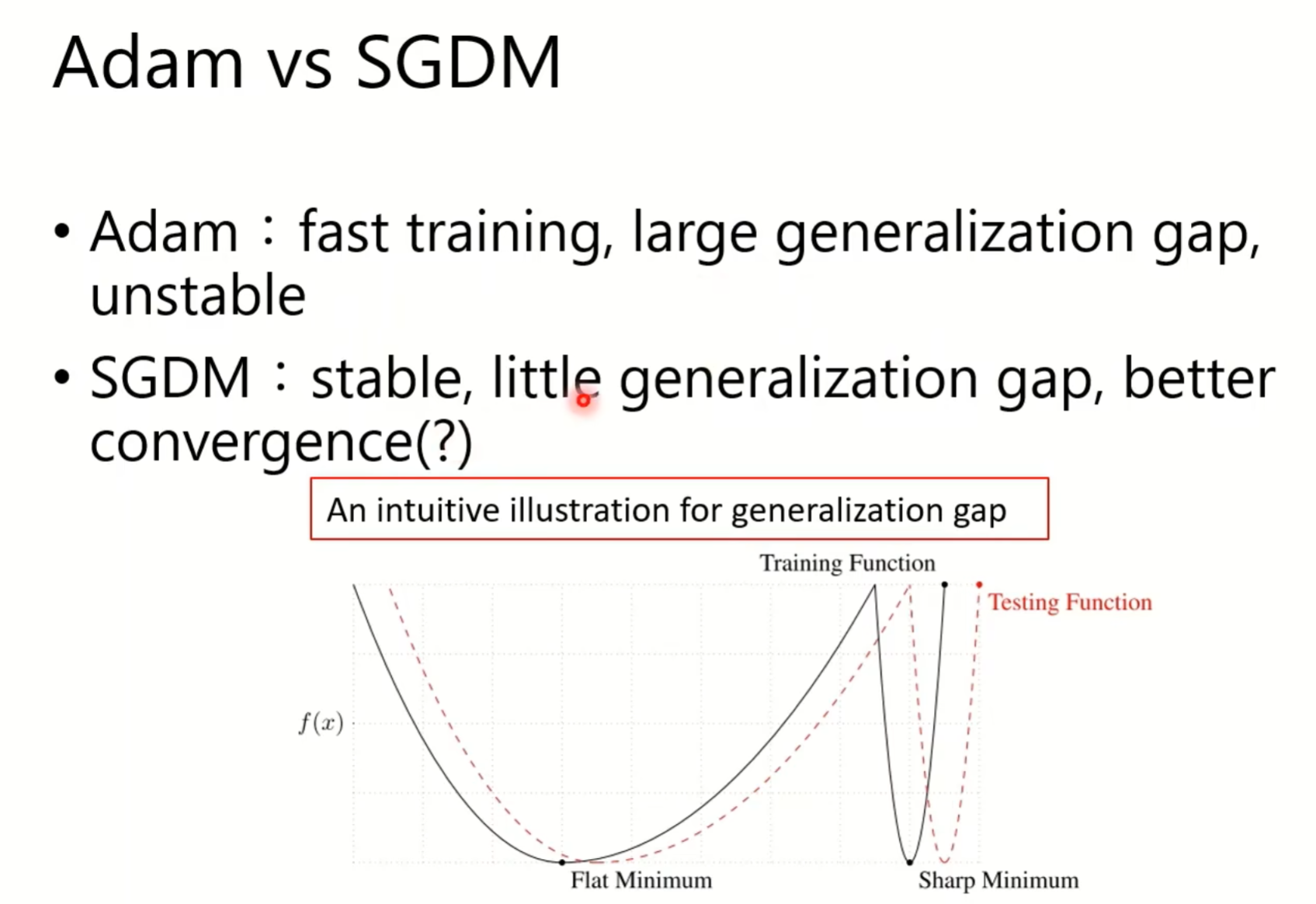
如图可见,training时候的loss function和test的时候因为data set的不同,所以会不一样,但相似,如果是flat minimum的话,不会有太大的区别,但是sharp minimum就有很大区别了
我们想要去优化adam,我们就要看为什么adam不稳定,收敛效果和泛化效果不如sgdm:因为单次更新的最大移动距离受限以及非信息性梯度可能对参数更新产生过大影响,如下图所示
gradient突然变大后,任然根据先前的这个状态去调整 ,被先前的gradient牵着鼻子走,图中的小gradient影响了大的gradient,导致移动的不够多,所以有人提出了这样子的一个策略:amsgrad
max函数会记得之前有过的大的这个vt,在大部分gradient很小的时候也不会忘记看过很大的gradient,但这样也会导致一个问题,就是可能又回到了adagrad遇到的问题,越到后面lr越小,步子越小
所以又有人想要去解决这些问题,让gradient大的时候,lr也不是很小(因为train到后面,lr不是很大,就是很小)
我们最想要的,就是根据train data 自动调整lr,于是后面就出来了amsgrad,
但是,因为有一个lower bound和一个higher bound,其实我们也无法做到adaptive,无法自动调整这个lr,那么,既然我们没办法去调整adam,我们就转向调整sgdm,sgdm的缺点是比较慢,无法自动调整lr,我们就在想,能不能先找到合适的lr,让它快一点 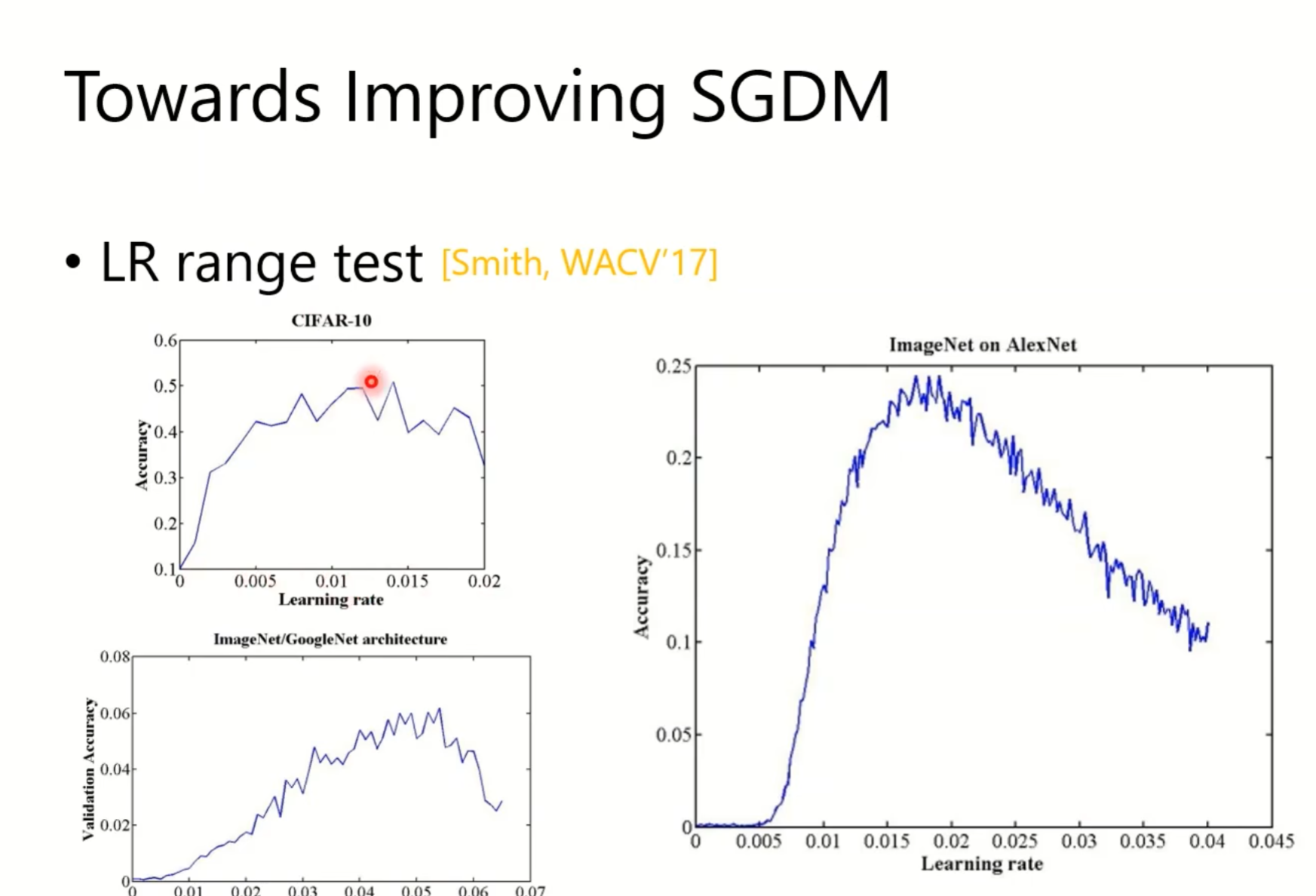
一般lr局中的时候,效果会比较好
接下来的这个循环的lr,则是鼓励model不要停留在一个状态,也相当于自动调节lr(gradient大的时候,lr小)
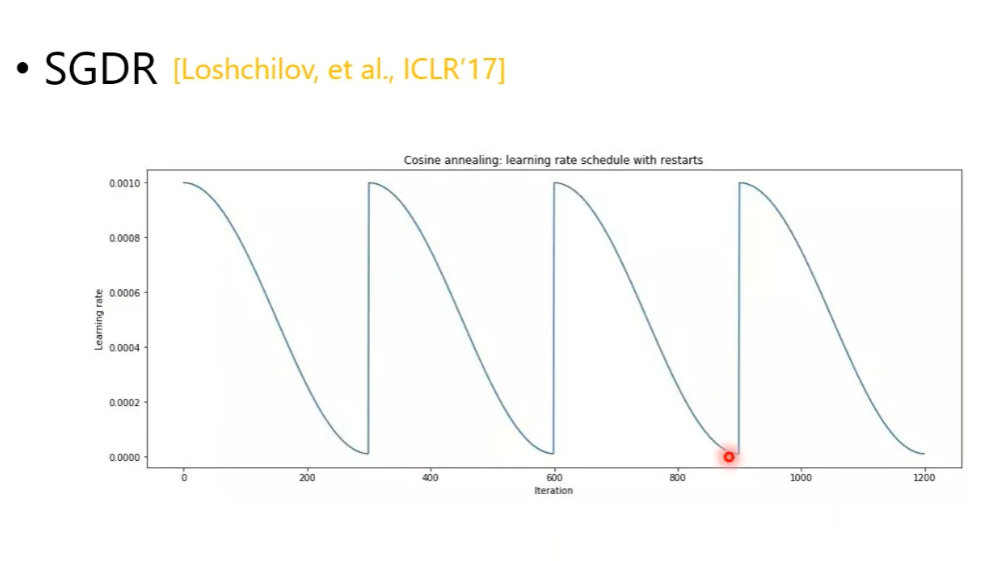
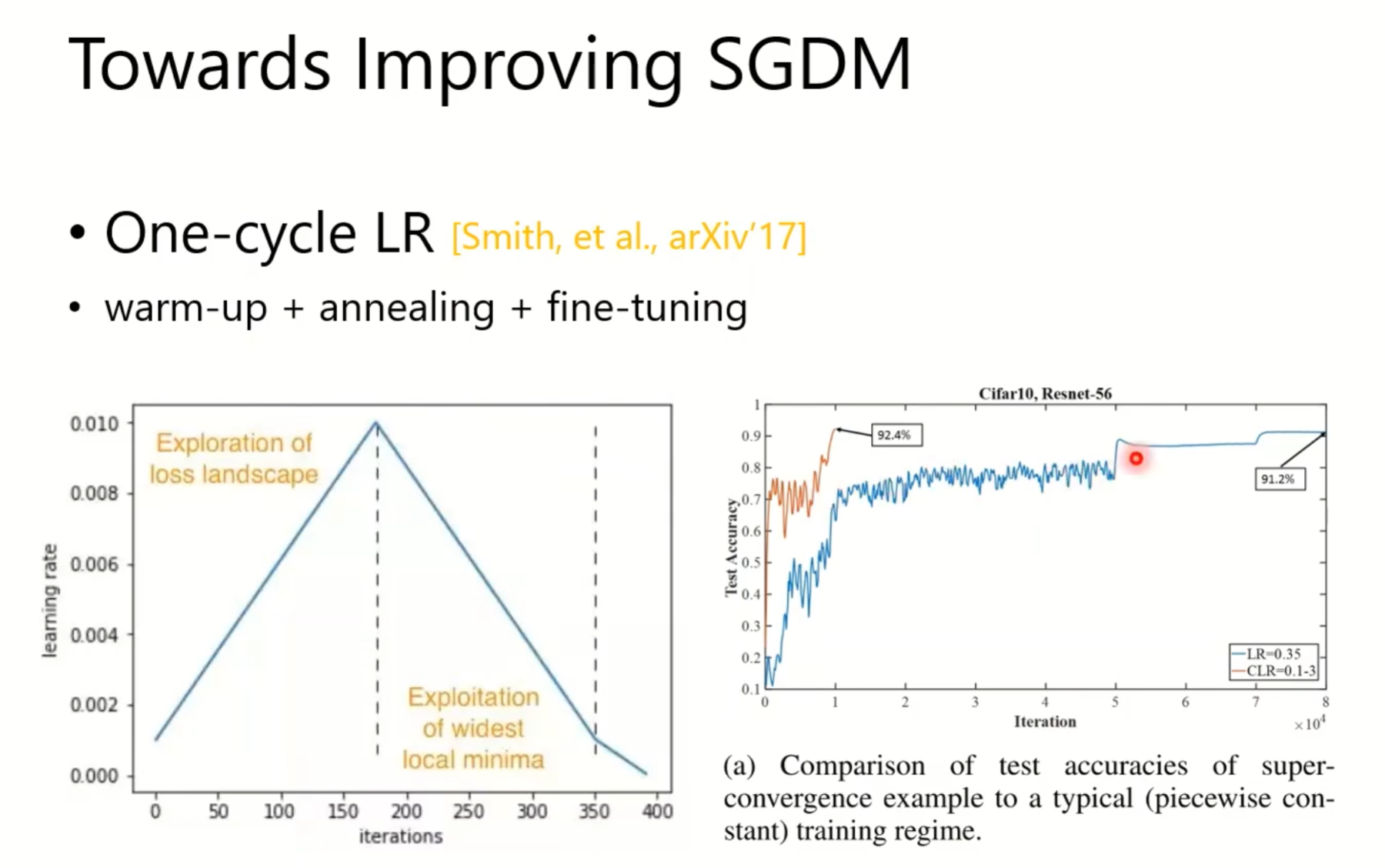
adam需不需要warm up?需要,因为一开始data set可能会导致gradient比较乱,是lr比较不符合预期,所以一开始要让它走的小步一点,虽然得到的值不一定好,但不会暴走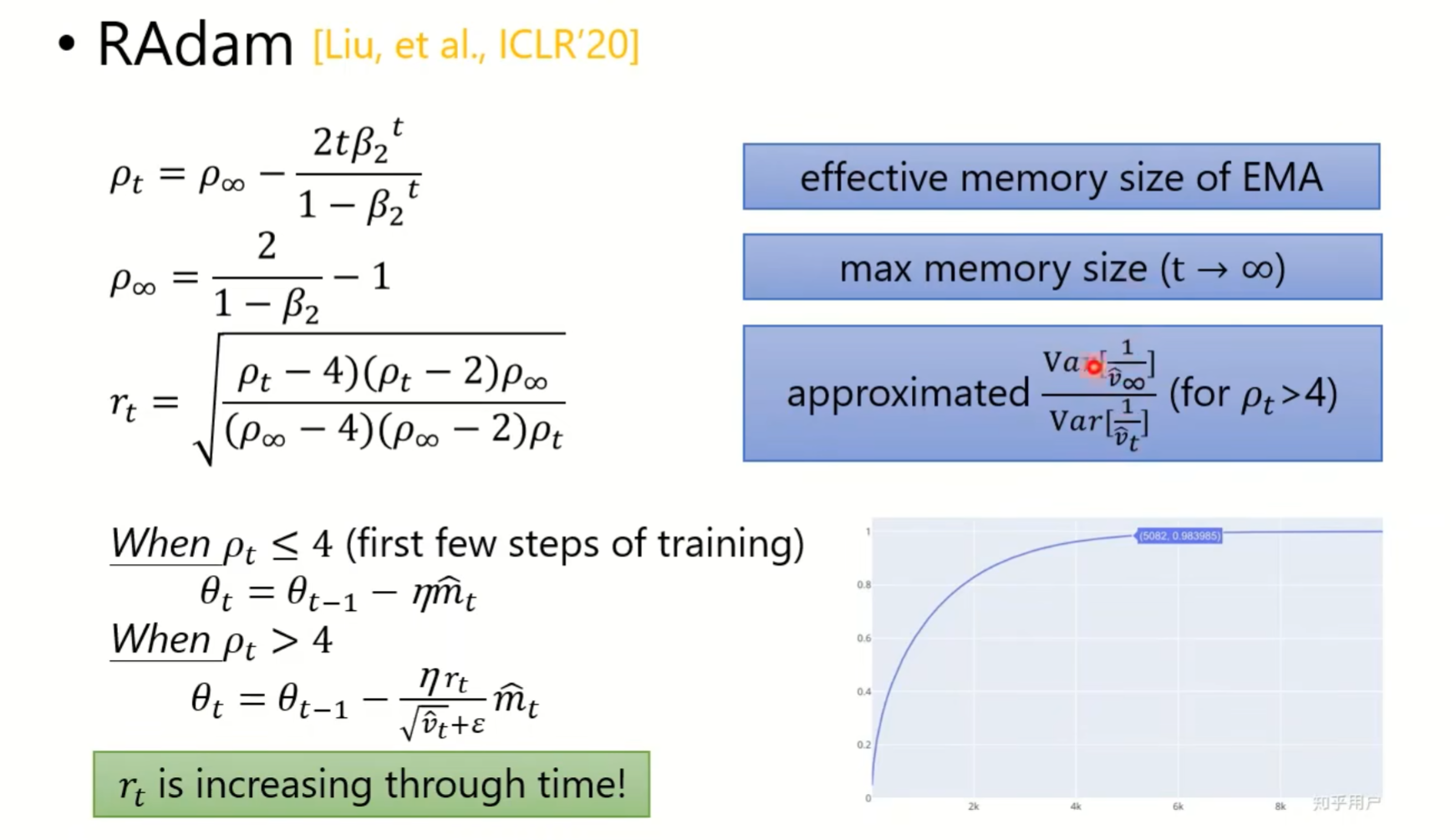
对于上图中的radam,