继续预训练 LLM ——数据筛选的思路
GPT生成数据微调qwen-2.5多模态模型实战项目
作者:柠檬养乐多
原文地址:https://zhuanlan.zhihu.com/p/30645776656
qwen2.5-vl是阿里通义实验室推出的qwen系列最新多模态大模型,在许多指标上已经超过或接近了gpt-4o。更为方便的是,qwen团队提供了2.5B、7B等多个尺寸的较小模型,即使是较小的2.5B也在OCR、VQA任务上有一定效果。在实操中,我们常常需要部署类似的开源小模型,但是其效果很难达到闭源模型效果。本项目采用最简单的蒸馏思想,采用gpt和给定prompt、给定图片数据集直接生成微调所用的数据集,然后用ms-swift框架进行微调。

项目目前使用Lora微调。Lora原理可参见:知乎|深入浅出 Lora。
Github代码仓(star一下呀):
gpt_distill_2qwen
地址:https://github.com/QQsugar2000/gpt_distill_2qwen
环境需求
-
显卡:由于qwen-vl有2.5b模型,lora下训练所占显存甚至少于10G,所以有张差不多的卡就可以用了;当然,实测一些任务起码要7b模型才能做到差不多的效果
-
安装modelscope的swift微调框架,python版本最好是3.10,配置好cuda、cudnn等
-
可以使用命令:
pip install ms-swift -U
pip install qwen-vl-utils==0.0.8
数据准备
整体思路是用给定的prompt和图片生成问题,然后使用GPT API生成答案,拿这个答案去微调qwen。注意,这种方法并不保证生成的数据质量,因为GPT API生成的数据可能并不准确。
-
在 script/config/prompt.py中配置Prompt:系统Prompt (system_prompt,选填):用于配置大模型生成数据时使用的系统Prompt,例如:“你是一个XX助手”。用户Prompt:直接发送给大模型的Prompt,默认只需配置此项。示例prompt是对UI图片的功能理解。
-
配置图片数据集:clone代码仓后cd到对应目录,将图片放入data/image目录,之后运行
python process_all_image.py \--image_folder data/image \--output_json data/responses.json \--max_retries 3
本项目已经尽量简化微调所需要的数据和文件结构,如果你有一些开源图片数据集,把里面的图片拿出来放进相应目录即可。
如果需要自定义数据集,你也可以参考responses.json中的结构或者看官方文档:自定义数据集 - swift 3.3.0.dev0 文档。如下,每条messages是一次和模型的对话数据,其中包括system(这条没有也可以,是选填的),user、assistant,user的content字段就是你的prompt,assistant的则是微调数据的回复。
process_all_image.py的作用就是批量对gpt api发送请求,将发回的回复整理成这样的数据。
{"messages": [{"role": "system","content": "你是一个智能助手,请根据用户输入的组件功能语义,生成对应的组件描述。"},{"role": "user","content": "帮我分析这个组件传递的功能,例如展示数据、描述数据变化趋势等"},{"role": "assistant","content": "{\n \"组件名\": \"费用概况组件\",\n \"功能\": [\n {\n \"描述\": \"展示用户账户的财务状况\",\n \"细节\": [\n \"显示可用额度和现余额,以帮助用户了解账户中的资金情况\",\n \"分项显示可开票金额和代金券的信息\"\n ]\n },\n {\n \"描述\": \"提供与财务相关的快捷操作入口\",\n \"细节\": [\n \"提供充值、提现、汇款认领等操作入口,方便用户快速处理资金流动\",\n \"提供开票相关操作以便用户管理发票事务\"\n ]\n },\n {\n \"描述\": \"通过模块化布局增强信息的清晰度\",\n \"细节\": [\n \"采用分块设计使不同财务信息区分开来,提升信息的可读性\",\n \"各部分信息详尽且精炼,便于用户快速了解不同财务状态\"\n ]\n }\n ]\n}"}]
}
转换函数:
def generate_responses(image_folder_path, output_json_path, max_retries=2):"""处理指定文件夹中的所有图片,生成响应并保存到指定的 JSON 文件。:param image_folder_path: 图片文件夹路径:param output_json_path: 输出 JSON 文件路径:param max_retries: 最大重试次数"""# 读取文件夹中的所有图片image_files = [f for f in os.listdir(image_folder_path) if f.endswith('.png')]# 存储生成的所有响应responses = []# 遍历图片文件并生成响应for image_file in image_files:image_path = os.path.join(image_folder_path, image_file)# 尝试调用 image_to_response 并捕获异常retries = 0success = Falsewhile retries <= max_retries:try:# 生成图片响应temp = image_to_response(image_path) #这里就是用gpt生成回复的函数# 组装消息条目message_entry = {"messages": [{"role": "system","content": system_prompt # system_prompt 是系统指令},{"role": "user","content": prompt # prompt 是用户传入的大模型指令},{"role": "assistant","content": temp # 这里是返回的response}]}# 将当前条目添加到响应列表responses.append(message_entry)success = Truebreak # 如果成功,跳出重试循环except Exception as e:# 捕获异常并增加重试次数retries += 1print(f"处理 {image_file} 时出现错误: {e}. 正在进行第 {retries} 次重试...")if retries <= max_retries:time.sleep(2) # 延迟 2 秒后再试else:print(f"处理 {image_file} 失败,已达到最大重试次数。")# 如果达到最大重试次数,保存已处理的部分数据并中断with open(output_json_path, 'w', encoding='utf-8') as f:json.dump(responses, f, ensure_ascii=False, indent=4)print(f"生成的响应已保存到断点文件 '{output_json_path}',处理已中断。")exit(1)# 如果所有图片处理成功,则将响应保存到 JSON 文件if success:with open(output_json_path, 'w', encoding='utf-8') as f:json.dump(responses, f, ensure_ascii=False, indent=4)print(f"生成的响应已保存到 {output_json_path}")
微调模型
微调命令
python train.py \--model_id_or_path Qwen/Qwen2.5-VL-7B-Instruct \--dataset data/sft_data.json \--output_dir checkpoints \--num_train_epochs 10 \--split_dataset_ratio 0.05
必填的是model_id_or_path和dataset,一个是模型类型,一个是数据集路径,其他参数可自行修改。
重要参数说明:(其他参数见github readme)
--cuda_devices:CUDA设备ID,默认值为 0。用于指定要使用的CUDA设备。
--model_id_or_path:模型的路径或ID,必填项。指定你要使用的模型路径或ID。
--output_dir:输出目录,默认值为 checkpoint。模型训练过程中的输出将保存在此目录。
--dataset:数据集路径,必填项。指定训练使用的数据集路径。
--data_seed:数据划分的随机种子,默认值为 42。用于控制数据集划分时的随机性。
--max_length:最大token长度,默认值为 2048。指定模型输入的最大token长度。
--split_dataset_ratio:验证集的划分比例,默认值为 0.01。用于划分训练集与验证集的比例。
--num_proc:数据加载时的进程数,默认值为 4。指定数据加载时使用的并行进程数。
--lora_rank:LoRA的秩,默认值为 8。指定LoRA的秩。
--lora_alpha:LoRA的alpha值,默认值为 32。指定LoRA的alpha值。 训练相关配置
--learning_rate:训练时的学习率,默认值为 1e-4。指定优化器的学习率。
--per_device_train_batch_size:每个设备的训练批量大小,默认值为 1。设置每个设备的训练批量大小。
--per_device_eval_batch_size:每个设备的评估批量大小,默认值为 1。设置每个设备的评估批量大小。
--gradient_accumulation_steps:梯度累积的步数,默认值为 16。指定梯度累积的步数。
--num_train_epochs:训练的总周期数,默认值为 5。设置训练的总周期数。
调参经验:
用大模型蒸馏小模型,生成的数据量、prompt和输入数据的质量根据具体任务做决定。
例如,如果你只是希望生成的数据格式能够更加统一,达到gpt的水准,可能几十条数据即可,这种情况下训10-30个epoch,loss就降得很好了;如果你的数据量达到了千条,这样可能在一个业务场景下能够训出来一个输出格式相对适配的小模型,最好精心设计不同的prompt,按照上面的生成数据方法多生成几个json,然后合并再拿来训练,这种情况需要训50-100个epoch;如果需要适配一个业务场景甚至模型能够学到gpt的一些内化知识,需要大几千甚至上万条数据。
训练速度:在单卡3090上训练2.5b模型,100条数据,30个epoch,10分钟即可跑完;7b模型,500条数据,50个epoch,需要2个小时完成
推理测试
训好模型存好checkpoint之后,即可使用推理脚本测试效果。
推理之前,你可能需要修改推理使用的prompt,在script/config/infer_request.py中配置,之后运行inference.py即可。
python run_infer.py \ --model_path Qwen/Qwen2.5-VL-7B-Instruct \ --checkpoint_path checkpoints \ --cuda_device 0
输入参数说明
-
--model_path:模型的路径或ID,必填项。指定你要使用的模型路径或ID。
-
--checkpoint_path:训练后的checkpoints保存目录,必填项。
-
--cuda_device:使用的GPU设备,默认值为 0。指定使用的GPU设备。
效果演示
这里放了一些我做的UI VQA任务的效果。该任务旨在提取UI图片的结构化功能,并作为json数据返回,这个能力能够用在UI图片的检索里面。
任务的prompt范例:
帮我分析这个图片里组件传递的功能语义,功能语义描述了这个组件的抽象功能,例如展示数据、描述数据变化趋势等,请用json方式返回格式化的数据。例如,环形图通过环形的比例来比较不同类别的数据份额,直观地展示各部分占整体的比例关系,帮助用户快速感知不同类别的相对大小;环形的设计使中心区域可用于显示汇总数值,增强信息的整体理解;颜色的区分进一步加强对数据特征及其状态的认知,提高图表的可读性,示例如下:
{"组件名": "环形图组件","功能": [{"描述": "展示数据的整体结构和各部分的占比","细节": ["通过环形的比例来比较不同类别的数据份额","帮助用户快速感知不同类别的相对大小"]},{"描述": "在中心区域突出显示汇总或关键数值","细节": ["环形图中心可放置总量或其他关键信息","增强用户对整体数值的认知和理解"]},{"描述": "通过颜色区分不同数据类别或状态","细节": ["使用不同颜色来表示不同类别或状态","提高图表可读性并便于快速对比"]}]
}
基本思路是写清楚自己的需求,然后给出例子。这也是VQA任务常见的prompt方法,注意,一定要结构清晰有条理,然后例子要定义清楚,如果没有例子,模型的返回有极大的随机性,基本上不能作为json去读取。
例如,我们对这样一个UI图片做类似的任务:
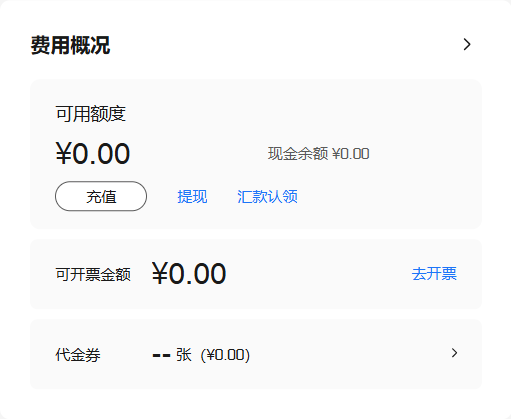
采用GPT4o模型,加上上面的prompt,回复是:
{"组件名": "费用概况组件","功能": [{....这里省略一些不重要的部分},{"描述": "提供提现和汇款认领功能","细节": ["提现按钮允许用户将可用余额转出","汇款认领链接帮助用户确认和领取已到账的款项"]},{"描述": "展示可开票金额,便于财务管理","细节": ["可开票金额部分显示用户当前可以申请发票的金额","提供去开票链接,引导用户进行开票操作"]}]
}
如果没有微调的qwen2.5-3b返回是这样:
"组件名": "费用概况组件","功能": [{....},{"描述": "提供充值和提现选项","细节": ["包含一个'充值'按钮用于增加可用额度","包含一个'提现'按钮用于减少可用额度"]},{"描述": "显示可开票金额","细节": ["显示可开票金额为0元","方便用户了解当前是否可以开具发票"]},....
}
微调后的返回:
{"组件名": "费用概况组件","功能": [{......},{"描述": "提供充值和提现选项","细节": ["包含一个'充值'链接用于增加可用额度","提供一个'提现'链接以便用户将资金转出""提供‘汇款认领’操作链接"]},{"描述": "展示可开票金额","细节": ["显示当前可开票金额为0元","提供一个'去开票'链接以开始开具发票"]}.....]
可以看到,微调后的模型返回更全面,而且很明显学习到了“链接”这件事。当然,你会发现没有微调的模型返回很多时候也差不多,这里我就不多加推测了。
结合之前做微调和prompt工程的一些经验,总结下来大概是这样:
如果需要学习一些固定的返回格式,或者控制模型输出的多样性,可以用少量数据训练,甚至几十张都可以;如果需要学习场景下的一些内化知识,例如上面的,模型应当能够认出来“链接”这种东西,可能需要1k-几k不等的数据以覆盖不同情况;当然,调节epoch和学习率啥的也很重要,不然很容易过拟合失去通用能力。
