操作系统-物理结构
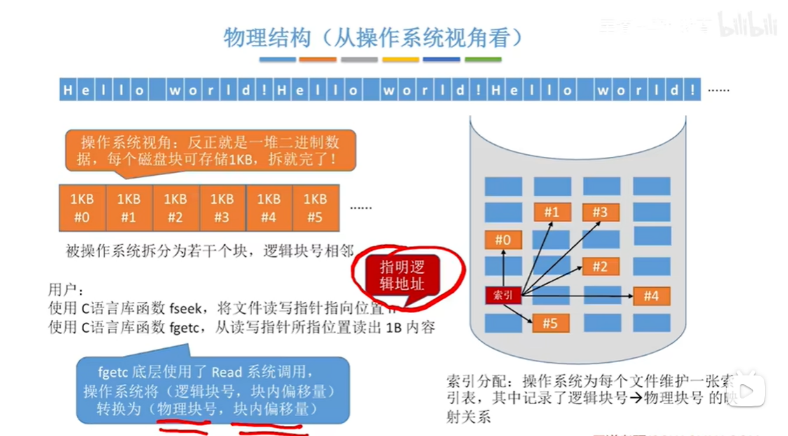
操作系统使用read系统调用,将逻辑地址转(对于用户来说逻辑地址容易计算,因为各个逻辑块都相邻)成了逻辑块号和块内偏移量,并根据分配存储方式,将逻辑块号转成物理块号和块内偏移量
对于用户来说的文件的一个个字符,对于操作系统来说就是一堆二进制文件,并根据1个磁盘块存储1KB的数据,将文件数据分别存储到为0、1、2、3、等若干逻辑块,这些逻辑块号相邻,具体的物理块号是否相邻,要看采取的分配存储方式,是连续存储(逻辑上相邻的物理上也相邻)、链接分配还是索引分配方式
顺序文件
1.无结构文件
2.有结构文件:顺序文件、索引文件、索引顺序文件【有结构文件就是一条条记录】
顺序文件
过程如下:
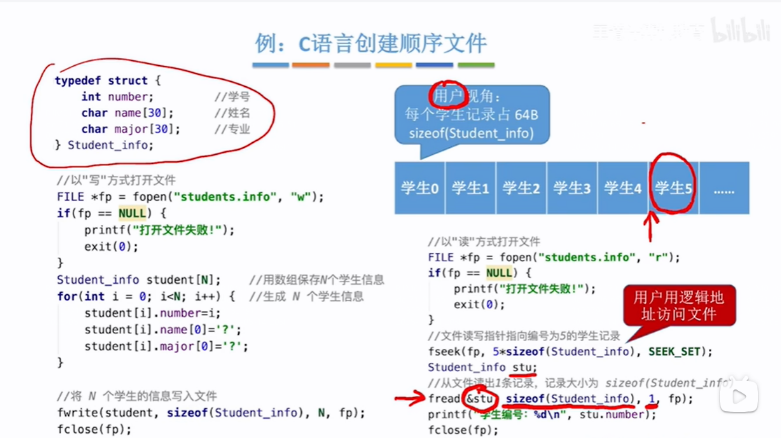
用户视角每个学生记录(每个struct结构体)占64B原因:number--int类型4B,name--char类型30个字符长度30B(那应该1个字符1B),major--char类型30个字符长度30B,总共30+30+4=64B,也可用sizeOf(Student_info)函数来直接计算该struct结构体的大小
先将N个学生记录写入文件对象:
采用w写的形式使用fopen函数打开students.info文件,并返回fp文件对象,即fp指针指向students.info文件,然后分配student[N]数组空间用来存放N个学生记录,最后调用fwrite函数写入student,fwrite函数中的参数student表示要写入数据的起始地址即数组的起始地址,sizeof(Student_info)即一个学生记录的所占的空间大小,参数N表示要写入几条记录,fp表示要将数据写入的文件对象,调用fwrite函数中这N个struct结构体数据就被保存到磁盘里边
读出第5个学生的信息:
使用fopen函数并且采用r读的形式打开students.info文件,返回文件对象让fp指针指向该文件对象,再使用fseek函数会让文件读写指针从开头位置算起(即学生0位置)偏移5*sizeof(Student_info)位置,即第5个指针(学生5)存放的起始位置,再使用fread函数可以读出参数为1即1条记录的sizeOf(Student_info)大小,然后把读出的记录赋给sut变量,这样就从fp文件里读出了5号学生对应的记录
对于用户来说,每条学生记录是连续存放的,并且每条记录所占的空间大小是相同的,这样就很容易算出要读出记录的逻辑地址(是因为知道第一个记录的地址,所以因为连续存放和大小相同能够很快地计算出要读出记录的逻辑地址?)
对于操作系统来说,是把整个文件的大小按照1块磁盘块的存储文件的大小,分成了多个磁盘块,即一个个相邻的逻辑块,然后在读到内存的过程中,又使用了逻辑块和物理块号的映射(具体如何映射跟开篇说得一样看采用了什么分配存储方式)
链接分配
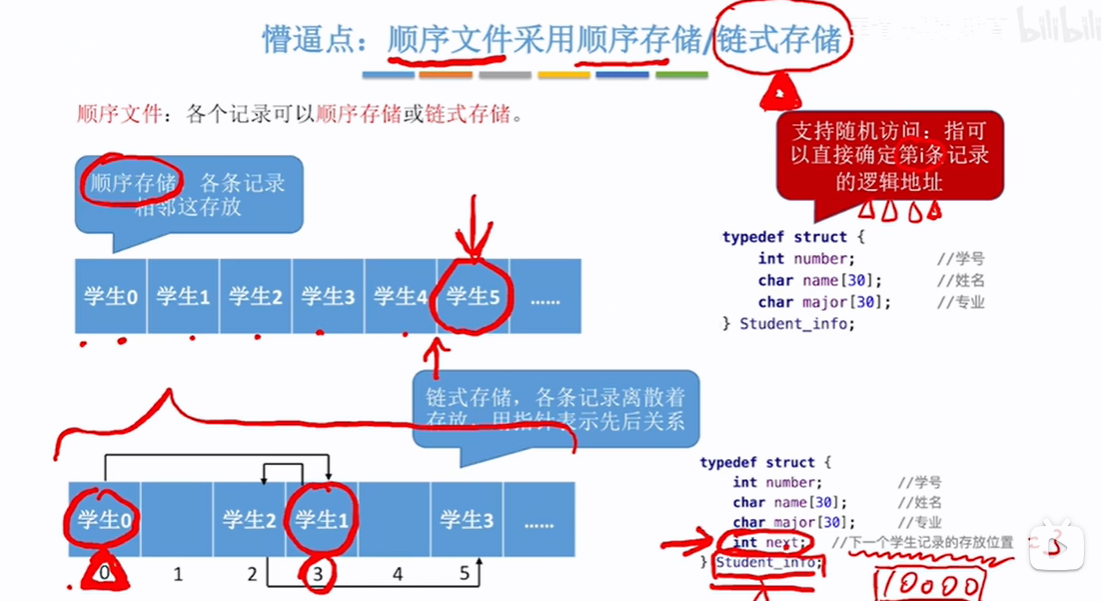
过程:因为是链接分配,即各个记录并不是连续存放(是离散存放),所以添加了next指向下一条记录的指针来确定下一条记录的位置,这个要找到第i条记录的位置(第i条记录逻辑地址)需要把第i-1条记录位置都找到,即不支持直接随机访问(直接访问),但是顺序存储支持
但是在用户的角度来看,即使实际是离散存放,这些记录还是占用了一整片的连续空间
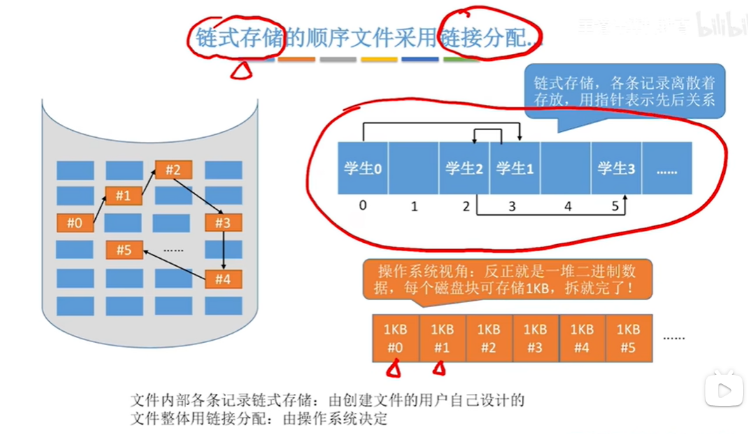
对于操作系统来说,即使是链式存储的顺序文件,也会被拆分成一个个磁盘块,这些物理块在磁盘的存储方式可能操作系统采用的是连续分配或者链接分配
文件的逻辑结构的链式存储是由用户实现,即文件的内部这些记录的先后顺序。需要用户来关心
文件的物理结构即操作系统把文件分成了一个个逻辑块,这些逻辑块在磁盘存储的时候,操作系统会用链接的方式来记录这些逻辑块的先后顺序,物理块的存储如链接分配是由操作系统实现,用户不需要关心
索引分配
过程:定义一个索引项的结构体IndexTable,并把它使用fopen函数的w写形式写到文件里,字段是学号和学生记录逻辑地址,一个index table对应一个索引项,然后再建立一个学生记录的struct,把各个学生记录建立一个Student_info数组,各个索引项会建立起学号和各个学生信息的映射关系(每个索引项都有Student_info的逻辑地址 addr),比如一个文件的前1MB存放索引项,剩下空间用来存放一条条学生信息,当要根据学号找到某个学生金鸡路时,可先把1M索引项读入内存,找到目标学生索引项,再根据目标学生的IndexTable里的addr信息找到学生记录逻辑地址,再去读取这个逻辑地址对应的学生信息
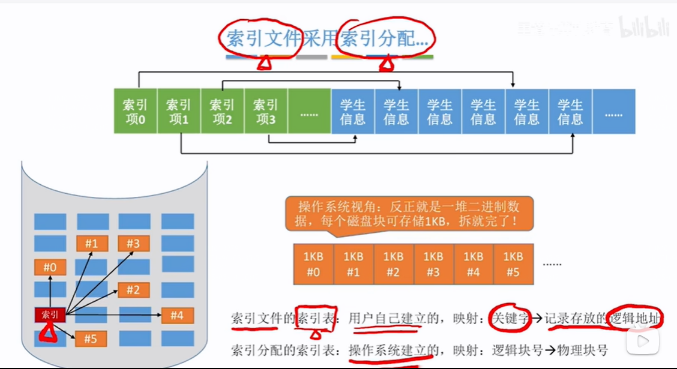
在用户来看文件依然是连续存储的,但是实际操作系统会把大文件分成一个个磁盘块(逻辑块),这些逻辑块存放在磁盘里,然后可以用连续分配、链接分配、索引分配等方式来记录这些磁盘块的先后顺序,即索引分配,操作系统会维护一个索引表来记录各个逻辑块号到物理块号的映射关系
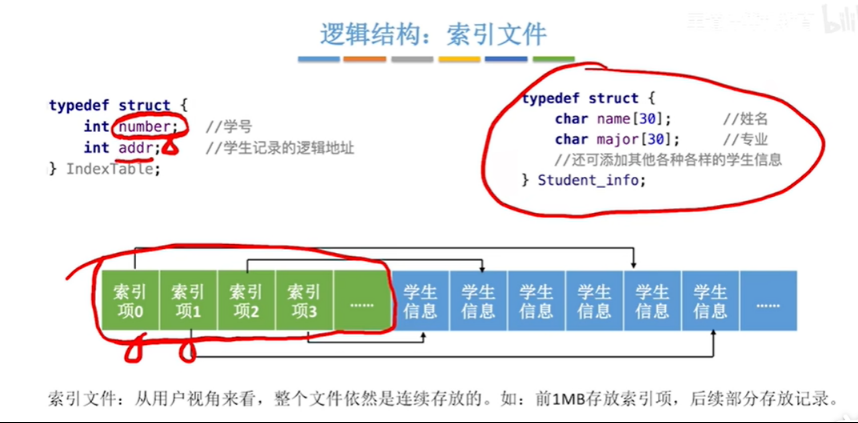
文件的逻辑结构的索引文件: 用来记录文件记录的关键字到记录存放的逻辑地址的映射关系,由用户自己建立
索引分配索引表:
总结
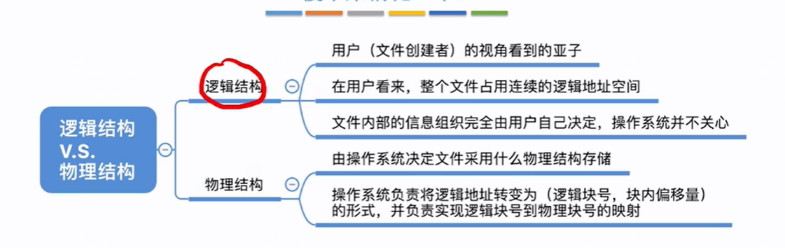
总结:对于用户来说文件占用连续的逻辑地址空间,要访问某块的数据就提供某块的逻辑地址,操作系统要考虑这么大个文件是怎么存储的,在用户提供了逻辑地址之后,操作系统负责将逻辑地址转成逻辑块号,并将逻辑块号转成物理块号
有些记录可能有问题,,,,,,