因果推断 | 用SHAP分值等价因果效应值进行反事实推理
CIMLA:利用机器学习和归因模型进行反事实推断也是由这篇论文[ Interpretable AI for inference of causal molecular relationships from omics data]引出的学习笔记。我们先来拆解一下CIMLA再来用代码简单实践一下。
论文链接:https://arxiv.org/pdf/2304.12523
笔者之前的关联文章:
- 机器学习模型可解释性进行到底 —— SHAP值理论(一)
- 因果推断杂记——因果推断与线性回归、SHAP值理论的关系(十九)(算是证实我之前的一个想法)
- 智能营销增益(Uplift Modeling)模型——模型介绍(一)
文章目录
- 1 CIMLA原理
- 1.1 局部处理效应(LTE)
- 1.2 LTE计算步骤
- 2 CIMLA与之前因果推断方法的差异
- 2.1 LTE 与 ITE、CATE 的差异
- 2.2 CIMLA与Uplift Model 的t-learner的差异
- 3 商业应用场景
- 4 代码实践一把
- 4.1 优惠券推荐:LTE的估计代码
- 4.2 模拟Uplift Two-Learner 模型
- 5 参考
1 CIMLA原理
1.1 局部处理效应(LTE)
针对 TF ( t ) 对目标基因 ( g ) 的直接因果影响,局部处理效应(LTE)定义为:
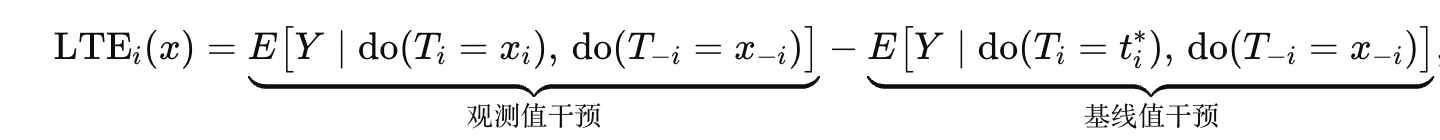
由于直接测量 LTE 难以实现,本文提出一个可估计代理(LTE的的加权平均值):
α t , g ( x ) = E ψ [ L T E t , g ( x , ψ ) ] \alpha_{t,g}(x) = E_\psi [LTE_{t,g}(x, \psi)] αt,g(x)=Eψ[LTEt,g(x,ψ)]
其中 ψ _\psi ψ表示所有允许的因果图分布
在满足一定假设下(包括:无未知混杂、正性、一致性、互不干扰)因果假设下,可证明模型上的 SHAP 值 ϕ i ( j ) ( x ) \phi_i^{(j)}(x) ϕi(j)(x)近似于上述因果量:
τ i ( x ) ≈ ϕ i ( j ) ( x ) . \tau_i(x)\;\approx\;\phi_i^{(j)}(x). τi(x)≈ϕi(j)(x).
这个差值 Δ i ( x ) \Delta_i(x) Δi(x)反映了在不同条件下,第 i i i个特征对模型预测影响的差异,从而近似了局部处理效应。
这里可以看到有几个假设前提,核心还是以下两个:
无未知混杂(No Confounding)或者所有混杂因素 (Sufficiency of Measured Covariates)都纳入考虑,因果推断中最核心的假设
例子:如果某个客户群体天生购买意愿高,并且他们恰好被优先发送了优惠券(未测量到“天生购买意愿”),模型会学到“收到优惠券”与“高购买率”相关,SHAP 值会很高,但这部分关联是由“天生购买意愿”引起的,而不是优惠券的真实效果。
解决方式为:
- 设计 A/B 测试时避免“邀请好友”类激励,或对不同实验单元物理/社交隔离
- 收集尽可能全面的用户特征(历史行为、人口属性、上下文因素等)
- 正确的模型形式 (Correct Model Specification):
还有就是SHAP值模拟的ML模型本身:模型拟合真实条件期望,用于归因的模型 𝑀 𝑗 𝑀𝑗 Mj必须能客观地估计 E [ Y ∣ X , T = j ] E[Y∣X,T=j] E[Y∣X,T=j],否则SHAP值反映的仅是模型偏差而非真实因果效应,若模型不能拟合真实条件期望,SHAP仅暴露“相关性”而非“因果”
1.2 LTE计算步骤
局部处理效应(LTE)或者说SHAP值的计算过程,具体如下图:
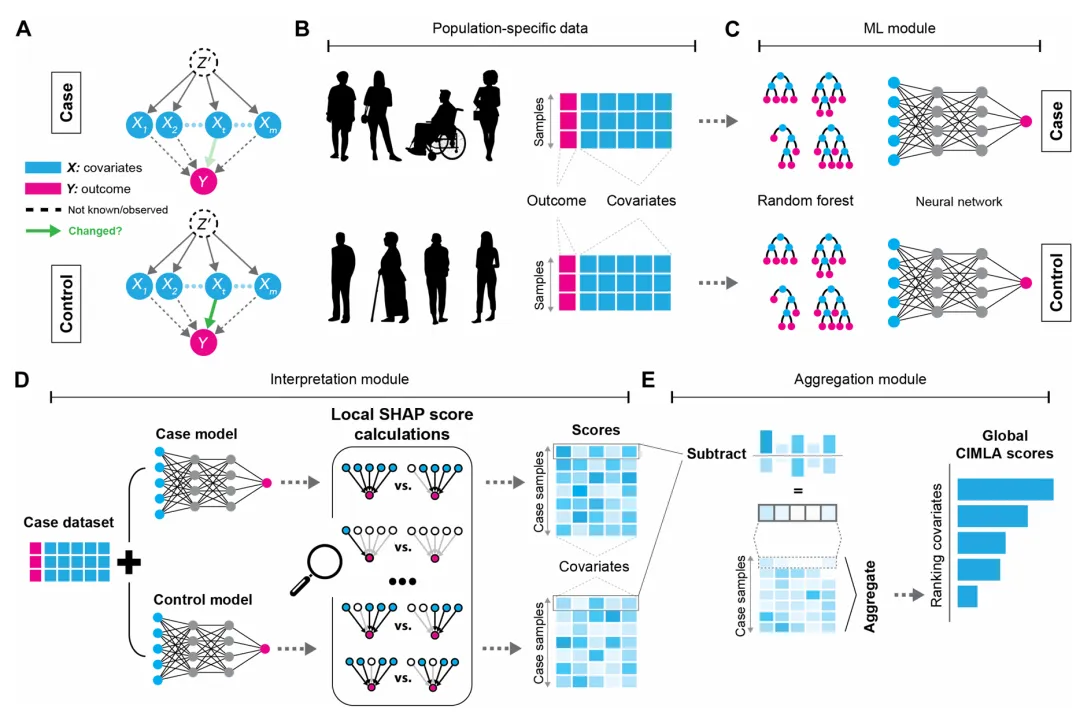
差异化基因调控网络dGRN的推理旨在识别不同生物条件之间基因调控关系的差异。以下是详细的推理步骤及涉及的公式:
步骤1:模型训练
使用两个数据集 D 1 \mathcal{D}_1 D1和 D 0 \mathcal{D}_0 D0分别训练模型 M 1 M_1 M1和 M 0 M_0 M0。这两个模型分别捕捉了不同生物条件下的基因调控模式。
这意味着,实验组和对照组各自建立了一个独立的模型。
步骤2:SHAP值计算 — 反事实推理环节
对每个样本 x x x,计算其在两个模型下的SHAP值 ϕ i ( 1 ) ( x ) \phi_i^{(1)}(x) ϕi(1)(x)和 ϕ i ( 0 ) ( x ) \phi_i^{(0)}(x) ϕi(0)(x)。这些SHAP值用于量化每个基因(特征)在模型预测中的重要性。
步骤3:样本级差值计算
定义样本级差值 Δ i ( x ) \Delta_i(x) Δi(x),用于量化不同条件下基因调控的差异:
Δ i ( x ) = ϕ i ( 1 ) ( x ) − ϕ i ( 0 ) ( x ) \Delta_i(x) = \phi_i^{(1)}(x) - \phi_i^{(0)}(x) Δi(x)=ϕi(1)(x)−ϕi(0)(x)
这个差值 Δ i ( x ) \Delta_i(x) Δi(x)反映了在不同条件下,第 i i i个特征对模型预测影响的差异,从而近似了局部处理效应。
步骤4:全局评分计算
在实验组样本 x ∼ D 1 x\sim \mathcal{D}_1 x∼D1上计算差值 Δ i ( x ) \Delta_i(x) Δi(x)的均方根(RMS),作为全局评分 Λ i \Lambda_i Λi:
Λ i = E x ∼ D 1 [ Δ i ( x ) 2 ] \Lambda_i = \sqrt{\mathbb{E}_{x\sim\mathcal{D}_1}\bigl[\Delta_i(x)^2\bigr]} Λi=Ex∼D1[Δi(x)2]
这个全局评分 Λ i \Lambda_i Λi衡量了第 i i i个基因在不同生物条件下的平均调控差异强度。
步骤5:排序与网络构建
依据全局评分 Λ i \Lambda_i Λi对转录因子-基因边进行排序。评分较高的边表示在不同生物条件下调控差异显著的基因对,从而构成差异化基因调控网络(dGRN)。
最终,得分高者即为在两条件下直接调控强度差异最大的 TF–基因调控边,完成 dGRN 推断。
2 CIMLA与之前因果推断方法的差异
2.1 LTE 与 ITE、CATE 的差异
ITE(个体处理效应):对样本 𝑖 𝑖 i,二值处理下潜在结果差,反映个体若接受 vs 未接受处理,结果变化量
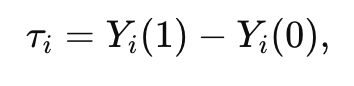
CATE(条件平均处理效应):在协变量 𝑋=𝑥 条件下的平均效应,评估在特定人群子集上的平均响应
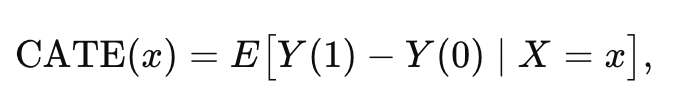
LTE,针对 TF ( t ) 对目标基因 ( g ) 的直接因果影响,局部处理效应(LTE)定义为:
LTE是基于已训练的机器学习模型计算得出的一个度量,它是模型预测结果的归因,论文试图赋予这种局部模型解释(SHAP 值)一定的因果含义,认为它在特定假设下可以近似于反映变量之间直接影响的因果数量的平均值。
应用场景:论文中识别不同生物条件下基因调控关系的差异,从而推断差异化基因调控网络(dGRN)。
LTE 与 ITE的相同之处:
- 如果特征贡献的差异能够准确反映处理对个体结果的影响,那么LTE和ITE可能在数值上接近或表现出一定的相关性。
LTE 与 ITE的差异之处:
- 概念基础: ITE 是基于潜在结果框架定义的,是一个标准的因果推断概念。论文中的 LTE 是基于机器学习模型解释工具 (SHAP) 导出的一个度量。
- 目标: ITE 旨在度量真实的因果效应。论文中的 LTE 是利用模型解释来估计或近似某个因果数量,或者说用模型的局部归因来洞察潜在的因果影响。
- 严格性: ITE 是因果推断中理论上严谨定义的效应量。论文中的 LTE 是将模型归因与因果概念联系起来,其因果解释的强度依赖于模型的准确性、数据的特性以及研究所依赖的特定假设。
2.2 CIMLA与Uplift Model 的t-learner的差异
之前研究的智能营销增益(Uplift Modeling)模型——模型介绍(一)提到有t-learner,看上去实现步骤相似,来简单对比一下大概的差异。
| 特征 | Uplift two‑learner | CIMLA(Counterfactual Inference by ML & Attribution) |
|---|---|---|
| 模型结构 | 单一模型,输入:特征 + 处理指示 | 单一或双模型,后续借助SHAP形成counterfactual |
| 训练目标 | 直接最小化转化差异预测误差 | 训练预测模型(处理组 & 对照组),再做归因 |
| 效应估计 | 模型输出差分 Y ^ ( 1 ) − Y ^ ( 0 ) \hat{Y}(1)-\hat{Y}(0) Y^(1)−Y^(0) | SHAP值归因,精确定义LTE偏导 |
3 商业应用场景
笔者感觉LTE 与 ITE下uplift model 有相似的“功能”,那么写了一大篇其实就想说,uplift model 下的t-learner是概率相加,没有正负向;
LTE借助SHAP 是带有正负向符号的,那么LTE看上去就是:因果效应评估 + 归因 于一身了,还是蛮有趣的,笔者之前在一些项目中也用过,不过此时这篇论文相当于给了一种“合理性”的解释。
当然LTE(或者说SHAP值)对Uplift model 可以是一种互相补充的关系:
- 将 SHAP 作为 Uplift 模型预测结果的解释工具:归因能力
Uplift 模型预测的是 uplift score,但并不能直接告诉你为什么某个客户的 uplift score 高。可以将 SHAP 应用于 Uplift 模型本身(如果模型结构允许),解释 Uplift 模型预测的 uplift score 是如何由客户特征贡献的。这可以帮助理解 Uplift 模型发现异质性的原因。 - LTE(或者说SHAP值) 在某些情况下,后者可能更容易实现,或者提供了对模型内部决策过程的更深入理解。虽然不直接是因果效应,但对
模型认为哪些特征使得优惠券对这个客户的预测购买概率有高贡献的理解本身就很有价值,在无法进行 RCT 或 Uplift 模型难以实施的情况下,基于 SHAP 的 LTE 方法提供了一种利用可解释 AI 进行更智能、更可解释的个性化营销的替代思路,尽管其因果解释需要更谨慎
4 代码实践一把
论文团队有给出开源库:https://github.com/PayamDiba/CIMLA
不过理论比代码更重要,这里就用CHATGPT 模拟生成一个案例代码。
4.1 优惠券推荐:LTE的估计代码
# 导入必要库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import xgboost as xgb
import shap
import matplotlib.pyplot as plt# 1. 模拟用户数据集
np.random.seed(42)
n_users = 210
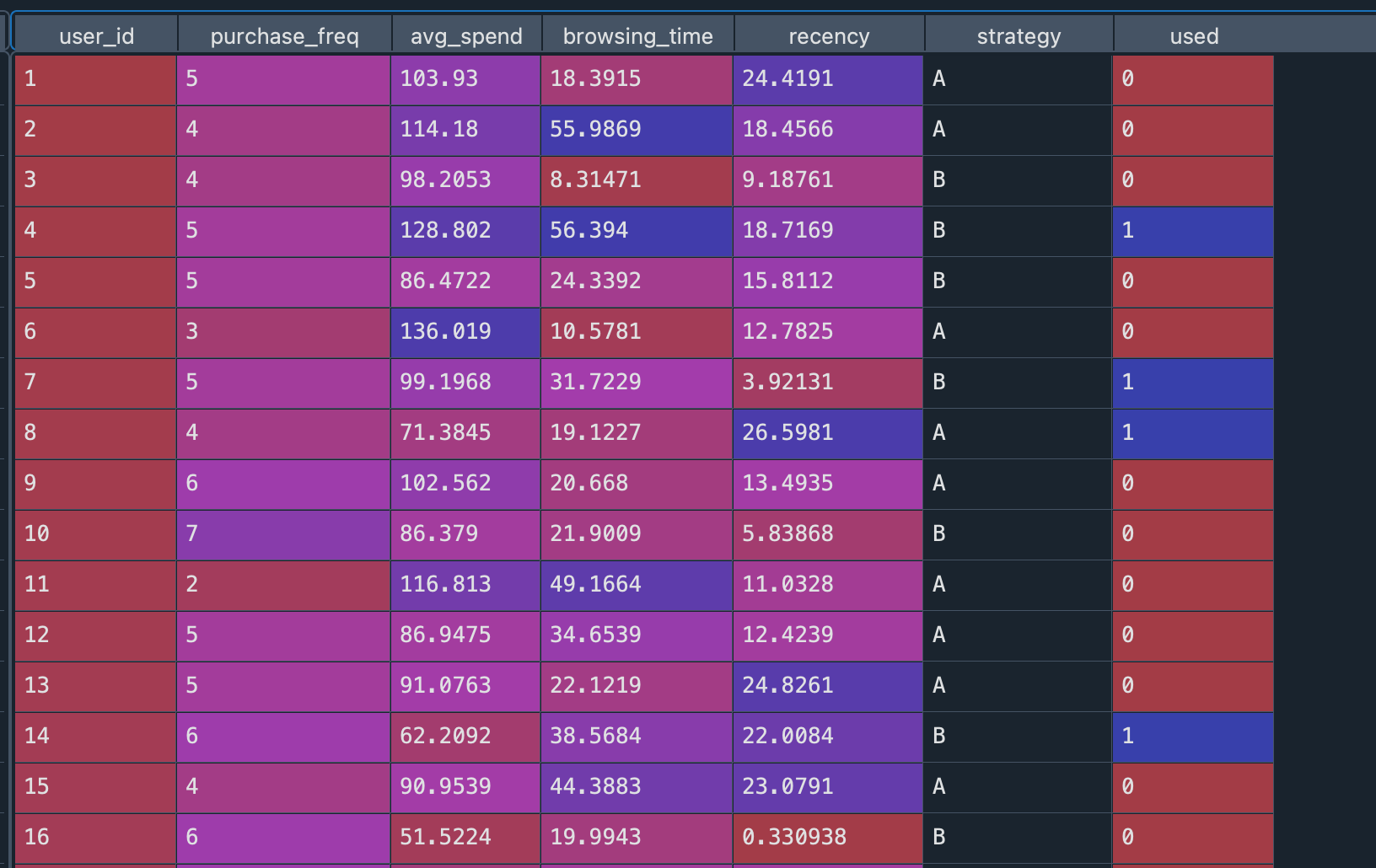
# 构建 DataFrame,包含用户ID及4个特征
data = pd.DataFrame({'user_id': range(1, n_users + 1),'purchase_freq': np.random.poisson(lam=5, size=n_users), # 历史消费频次'avg_spend': np.random.normal(loc=100, scale=20, size=n_users), # 平均消费金额'browsing_time': np.random.uniform(5, 60, size=n_users), # 浏览时长(分钟)'recency': np.random.uniform(0, 30, size=n_users) # 距离上次购买天数
})# 2. 随机分组:策略A(满减券)与策略B(折扣券)
permuted_idx = np.random.permutation(data.index) # 生成 0..19 的随机排列 :contentReference[oaicite:0]{index=0}
half = n_users // 2 # 一半样本数 = 10
# 将随机排列的前 10 个索引标记为 “A”,其余 10 个标记为 “B”
data['strategy'] = '' # 先创建空列
data.loc[permuted_idx[:half], 'strategy'] = 'A' # 索引前半分配 A
data.loc[permuted_idx[half:], 'strategy'] = 'B' # 索引后半分配 B
print(data['strategy'].value_counts())# 3. 模拟优惠券使用情况(标签)
data['used'] = 0
for idx, row in data.iterrows():if row['strategy'] == 'A':# 满减券对历史消费频次敏感,基础概率0.1,每增加一次消费频次增加0.03概率prob = 0.1 + 0.03 * row['purchase_freq']else:# 折扣券对平均消费额敏感,基础概率0.1,每增加1元消费额增加0.002概率prob = 0.1 + 0.002 * row['avg_spend']# 根据概率生成二元标签data.at[idx, 'used'] = int(np.random.rand() < prob)# 4. 对策略A/B分别训练XGBoost模型并保存训练集&测试集
models = {}
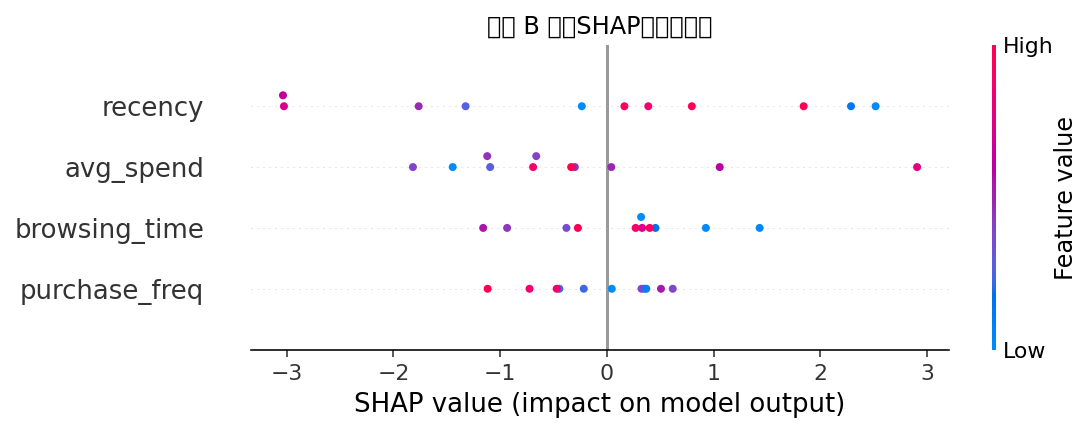
for strat in ['A', 'B']:df_sub = data[data['strategy'] == strat]X = df_sub[['purchase_freq', 'avg_spend', 'browsing_time', 'recency']]y = df_sub['used']# 划分训练/测试集,30%作为测试X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)print(f'[优惠券类型-{strat}] train 的长为{len(X_train)},test 的长为{len(X_test)}')# 初始化并训练XGBoost分类器model = xgb.XGBClassifier(use_label_encoder=False, eval_metric='logloss')model.fit(X_train, y_train)# 存储models[strat] = {'model': model, 'X_train': X_train, 'X_test': X_test}# 5. 计算SHAP值,并绘制全局特征重要性总结图
shap_values = {}
for strat, info in models.items():model = info['model']X_train = info['X_train']X_test = info['X_test']# 构建SHAP解释器explainer = shap.Explainer(model, X_train)shap_vals = explainer(X_test)shap_values[strat] = shap_vals# 全局summary图plt.figure()shap.summary_plot(shap_vals.values, X_test, show=False)plt.title(f"策略 {strat} 全局SHAP特征重要性")plt.tight_layout()plt.show()# 6. 计算每个用户在策略A/B下针对purchase_freq特征的局部SHAP差异,并给出推荐
# 提取purchase_freq列的SHAP值
phi_A = shap_values['A'].values[:, list(models['A']['X_test'].columns).index('purchase_freq')]
phi_B = shap_values['B'].values[:, list(models['B']['X_test'].columns).index('purchase_freq')]
len(phi_A),len(phi_B)# 将X_test索引对应用户id
test_users_A = models['A']['X_test'].index
test_users_B = models['B']['X_test'].index
len(test_users_A)# 构造DataFrame存放差异和用户
df_decision = pd.DataFrame({'user_id': list(data.loc[test_users_A, 'user_id']),'phi_A': phi_A,'phi_B': phi_B
})# len(list(data.loc[test_users_A, 'user_id']))# 计算增量效应
df_decision['delta_phi'] = df_decision['phi_A'] - df_decision['phi_B']
# 推荐策略:delta_phi>0 推荐A,否则推荐B
df_decision['recommendation'] = np.where(df_decision['delta_phi'] > 0, 'A (满减券)', 'B (折扣券)'
)# 7. 输出推荐结果
print("个性化优惠券推荐结果:")
print(df_decision[['user_id', 'delta_phi', 'recommendation']])
这里模拟了一些用户RFM的特征,strategy是设置了两张优惠券,A/B,现在做了一个投放AB实验,最后回收了used的使用量数据,来进行建模。
shap值的展示图:
最终:
个性化优惠券推荐结果:user_id delta_phi recommendation
0 53 0.530882 A (满减券)
1 130 0.380628 A (满减券)
2 128 -0.414267 B (折扣券)
3 104 -1.467391 B (折扣券)
4 88 1.491573 A (满减券)
5 191 -0.333272 B (折扣券)
6 208 -1.550986 B (折扣券)
7 96 -1.103726 B (折扣券)
8 18 -1.141814 B (折扣券)
9 1 -1.582291 B (折扣券)
10 28 1.420080 A (满减券)
4.2 模拟Uplift Two-Learner 模型
# 1. 同样模拟数据集(可复用 data)
data_uplift = data.copy()
# 将策略列转换为二元处理变量
data_uplift['treatment'] = np.where(data_uplift['strategy']=='A', 1, 0)# 2. 对处理组/对照组分别训练模型
models_uplift = {}
for grp, t_val in [('treat',1), ('control',0)]:df_grp = data_uplift[data_uplift['treatment']==t_val]X = df_grp[['purchase_freq', 'avg_spend', 'browsing_time', 'recency']]y = df_grp['used']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)model = xgb.XGBClassifier(use_label_encoder=False, eval_metric='logloss')model.fit(X_train, y_train)models_uplift[grp] = {'model': model, 'X_train': X_train, 'X_test': X_test}# 3. 计算两模型对同一批用户的预测差异
# 选取所有用户特征集进行推断
X_all = data_uplift[['purchase_freq', 'avg_spend', 'browsing_time', 'recency']]
pred_treat = models_uplift['treat']['model'].predict_proba(X_all)[:,1]
pred_ctrl = models_uplift['control']['model'].predict_proba(X_all)[:,1]# 4. Uplift 值 = 处理 - 对照
data_uplift['uplift'] = pred_treat - pred_ctrl# 5. SHAP 分析:解释 treatment 模型
explainer_up = shap.Explainer(models_uplift['treat']['model'], models_uplift['treat']['X_train'])
shap_vals_up = explainer_up(models_uplift['treat']['X_test'])
plt.figure()
shap.summary_plot(shap_vals_up.values, models_uplift['treat']['X_test'], show=False)
plt.title("[Uplift] Treatment 模型全局特征重要性")
plt.tight_layout()
plt.show()# 6. 根据 uplift 值给出推荐:uplift>0 推荐策略A,否则B
data_uplift['recommend'] = np.where(data_uplift['uplift']>0, 'A (满减券)', 'B (折扣券)')
print("[Uplift Two-Learner 推荐结果]")
print(data_uplift[['user_id','uplift','recommend']])
计算逻辑为:Uplift 值 = 处理概率值 - 对照概率值
uplift treatment的shap影响:
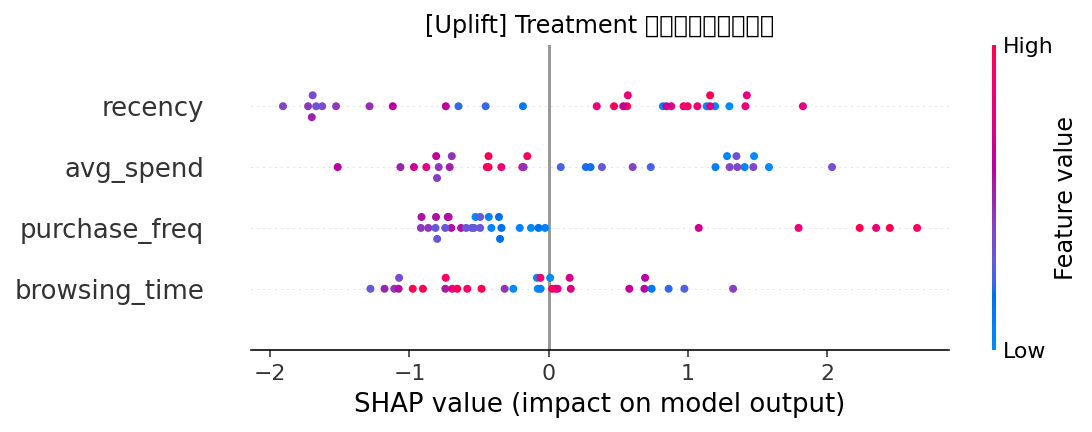
最终输出:
[Uplift Two-Learner 推荐结果]user_id uplift recommend
0 1 -0.356126 B (折扣券)
1 2 -0.057634 B (折扣券)
2 3 0.065955 A (满减券)
3 4 -0.863082 B (折扣券)
4 5 0.002057 A (满减券)
.. ... ... ...
205 206 -0.049409 B (折扣券)
206 207 -0.663924 B (折扣券)
207 208 -0.761671 B (折扣券)
208 209 0.114482 A (满减券)
209 210 -0.823822 B (折扣券)[210 rows x 3 columns]
5 参考
CIMLA:利用机器学习和归因模型进行反事实推断