嵌入式系统中WAV音频文件格式详解与处理实践
WAV (Waveform Audio File Format) 文件是一种非常常见的数字音频格式,由微软和IBM联合开发,广泛应用于Windows、Macintosh和Linux等操作系统。它能够直接存储声音波形,因此也被称为波形文件。它基于 RIFF (Resource Interchange File Format) 文件结构。
1. 核心概念:RIFF 和 Chunks (块)
理解 WAV 必须先理解 RIFF。RIFF 是一种通用的文件容器格式,它将文件内容组织成一个个带有标签和大小信息的 块 (Chunks)。
一个基本的 RIFF 块结构如下:
- Chunk ID (4 字节): 一个 4 字符的代码(通常是 ASCII),用于标识块的类型 (例如 ‘RIFF’, 'fmt ', ‘data’)。
- Chunk Size (4 字节): 一个 32 位无符号整数(小端字节序),表示紧随其后的数据部分的大小(字节数),不包括 Chunk ID 和 Chunk Size 自身这 8 个字节。
- Chunk Data (可变大小): 实际的数据内容,其大小由前面的 Chunk Size 字段指定。如果数据大小是奇数,通常会填充一个字节 (值为 0) 使其总大小为偶数,但这填充字节不计入 Chunk Size。
2. WAV 文件的整体结构
2.1 WAV 文件的基本头部
WAV 文件本身就是一个 RIFF 文件,其最外层的块具有以下特征:
- Chunk ID: 固定为
'RIFF'(0x52494646)。 - Chunk Size: 整个文件的大小减去 8 字节(即减去 ‘RIFF’ ID 和这个 Size 字段本身的大小)。
- Format (4 字节): 紧随 Chunk Size 之后,固定为
'WAVE'(0x57415645)。这标识了该 RIFF 文件是用于存储波形音频的。
所以,一个 WAV 文件的开头总是 RIFF <文件大小-8> WAVE。
2.2 WAV 文件内部的 Chunks
在 'WAVE' 标识符之后,包含了一系列的子块 (Sub-chunks),每个子块也遵循 Chunk ID + Chunk Size + Chunk Data 的结构。对于一个标准的 PCM (未压缩) WAV 文件,最重要的两个子块是**fmt 块 (Format Chunk)😗* 描述音频数据的格式, data 块 (Data Chunk): 包含实际的音频样本数据:
-
格式块 (
fmtChunk):- Chunk ID:
'fmt '(注意末尾有个空格,0x666d7420)。 - Chunk Size: 描述了
fmt块数据部分的大小。对于标准的 PCM 格式,这通常是 16 字节。但对于非 PCM 格式或扩展格式,可能更大。 - Chunk Data (以标准 16 字节 PCM 为例):
AudioFormat(2 字节): 音频数据的格式代码。1表示 PCM (线性量化,即未压缩)。其他值表示不同的压缩格式(如 ADPCM)。NumChannels(2 字节): 声道数。1= 单声道 (Mono),2= 立体声 (Stereo),等等。SampleRate(4 字节): 采样率 (Hz)。每秒钟对一个声道采集的样本数,例如 8000, 16000, 44100, 48000。ByteRate(4 字节): 字节率(每秒数据字节数)。计算公式:SampleRate * NumChannels * BitsPerSample / 8。这个值对于播放时的缓冲很重要。BlockAlign(2 字节): 块对齐值。表示包含所有声道的一个“原子”采样单元所需的总字节数。计算公式:NumChannels * BitsPerSample / 8。播放器通常需要一次性处理至少BlockAlign字节的数据。BitsPerSample(2 字节): 位深度。每个样本点使用的位数,例如 8, 16, 24, 32。决定了音频的动态范围。
- 注意: 如果
Chunk Size大于 16,后面可能跟着扩展信息,例如对于非 PCM 格式,会有一个Extra Format Bytes字段。
- Chunk ID:
-
数据块 (
dataChunk):- Chunk ID:
'data'(0x64617461)。 - Chunk Size: 音频数据的总大小(字节数)。等于
文件总样本数 * BlockAlign。 - Chunk Data: 包含了实际的、原始的音频样本数据。
- 数据类型:
- 8 位样本 (
BitsPerSample=8): 通常是无符号字节 (unsigned char),范围 0-255,静音值为 128。 - 16 位样本 (
BitsPerSample=16): 通常是有符号短整型 (signed short),范围 -32768 到 32767,静音值为 0。 - 24/32 位样本:通常是有符号整数。
- 8 位样本 (
- 声道交错: 对于多声道音频(如立体声),样本是交错存储的。例如,一个 16 位立体声文件的数据会像这样排列:
[左声道样本1 (2字节)] [右声道样本1 (2字节)] [左声道样本2 (2字节)] [右声道样本2 (2字节)] ...。每个 (左, 右) 对构成一个BlockAlign(这里是 4 字节)。 - 字节序: 对于多字节样本(16位、24位、32位),WAV 文件普遍使用小端字节序 (Little-Endian)。即最低有效字节在前。例如,16 进制值
0x1234存储为34 12。
- 数据类型:
- Chunk ID:
其他可能的 Chunks
除了 fmt 和 data 这两个必需块之外,WAV 文件还可以包含其他可选块,例如:
factChunk: 对于非 PCM 格式,通常需要fact块来存储文件的总样本帧数。PCM 格式不需要它。LISTChunk: 用于存储元数据(Metadata),如标题、艺术家、版权信息等。常见的LIST类型有INFO(信息列表)和adtl(关联数据列表,如提示点、标签)。bextChunk (Broadcast Wave Extension): 包含了广播行业常用的信息,如时间码、响度值等。BWF (Broadcast Wave Format) 是 WAV 的一个扩展。cueChunk: 存储提示点(Cue points),用于标记文件中的特定位置。- 以及其他自定义块。
3. WAV 文件结构示意图
一个典型的 PCM (脉冲编码调制,即未压缩) WAV 文件结构大致如下:
+-------------------+
| 'RIFF' (ID) | 4 bytes
| ChunkSize | 4 bytes (整个文件大小 - 8 bytes)
| 'WAVE' (Format) | 4 bytes
+-------------------+ <-- RIFF Chunk Header
| 'fmt ' (ID) | 4 bytes
| Subchunk1Size | 4 bytes (fmt chunk 的大小, 通常是 16 for PCM)
| AudioFormat | 2 bytes (1 = PCM)
| NumChannels | 2 bytes (1 = Mono, 2 = Stereo, etc.)
| SampleRate | 4 bytes (采样率, e.g., 44100 Hz)
| ByteRate | 4 bytes (SampleRate * NumChannels * BitsPerSample / 8)
| BlockAlign | 2 bytes (NumChannels * BitsPerSample / 8)
| BitsPerSample | 2 bytes (每个样本的位数, e.g., 8, 16, 24)
| (Optional Extra) | (扩展 fmt chunk 可能有)
+-------------------+ <-- fmt Chunk
| (Optional Chunks) | (e.g., 'LIST', 'fact')
| ... |
+-------------------+
| 'data' (ID) | 4 bytes
| Subchunk2Size | 4 bytes (音频数据的总大小,字节数)
| |
| Audio Data | Subchunk2Size bytes
| (Actual Samples) |
| ... |
+-------------------+ <-- data Chunk4.基于 C 语言对 .wav 格式音频的解析
// WAV文件基本头部结构体
typedef struct {char riff[4]; // "RIFF"标识uint32_t file_size; // 整个文件的大小-8char wave[4]; // "WAVE"标识
} wav_riff_header_t;// WAV文件格式块结构体
typedef struct {char fmt_id[4]; // "fmt "标识uint32_t fmt_size; // 格式块大小uint16_t audio_format; // 音频格式,PCM=1uint16_t num_channels; // 通道数,单声道=1,双声道=2uint32_t sample_rate; // 采样率,如44100uint32_t byte_rate; // 每秒字节数uint16_t block_align; // 数据块对齐uint16_t bits_per_sample; // 采样精度,8/16/24/32位
} wav_fmt_header_t;// WAV块通用结构
typedef struct {char id[4]; // 块ID,如"data"uint32_t size; // 块大小
} wav_chunk_header_t;// 解析WAV文件并定位到数据块
bool parse_wav_file(FILE *file, wav_info_t *info) {// 读取RIFF头wav_riff_header_t riff_header;if (fread(&riff_header, 1, sizeof(wav_riff_header_t), file) != sizeof(wav_riff_header_t)) {ESP_LOGE(TAG, "读取RIFF头失败");return false;}// 验证RIFF和WAVE标识if (strncmp(riff_header.riff, "RIFF", 4) != 0 || strncmp(riff_header.wave, "WAVE", 4) != 0) {ESP_LOGE(TAG, "无效的WAV文件 - 缺少RIFF/WAVE标识");return false;}bool found_fmt = false;bool found_data = false;wav_fmt_header_t fmt_header;// 扫描文件中的块,直到找到fmt和data块while (!found_data) {wav_chunk_header_t chunk_header;if (fread(&chunk_header, 1, sizeof(wav_chunk_header_t), file) != sizeof(wav_chunk_header_t)) {if (feof(file)) {ESP_LOGE(TAG, "到达文件末尾但未找到data块");return false;}ESP_LOGE(TAG, "读取块头失败");return false;}ESP_LOGI(TAG, "发现块: %.4s, 大小: %lu字节", chunk_header.id, chunk_header.size);if (strncmp(chunk_header.id, "fmt ", 4) == 0) {// 这是格式块if (fread(&fmt_header.audio_format, 1, chunk_header.size > sizeof(fmt_header) - 8 ? sizeof(fmt_header) - 8 : chunk_header.size, file) < 16) {ESP_LOGE(TAG, "读取fmt块失败");return false;}found_fmt = true;// 如果fmt块大于我们读取的部分,跳过余下部分if (chunk_header.size > sizeof(fmt_header) - 8) {fseek(file, chunk_header.size - (sizeof(fmt_header) - 8), SEEK_CUR);}// 验证音频格式是PCMif (fmt_header.audio_format != 1) {ESP_LOGE(TAG, "不支持的WAV格式 - 仅支持PCM格式 (格式代码: %d)", fmt_header.audio_format);return false;}// 保存音频信息info->audio_format = fmt_header.audio_format;info->num_channels = fmt_header.num_channels;info->sample_rate = fmt_header.sample_rate;info->bits_per_sample = fmt_header.bits_per_sample;ESP_LOGI(TAG, "WAV信息 - 采样率: %lu, 位宽: %d, 通道数: %d", info->sample_rate, info->bits_per_sample, info->num_channels);} else if (strncmp(chunk_header.id, "data", 4) == 0) {// 这是数据块info->data_size = chunk_header.size;found_data = true;ESP_LOGI(TAG, "找到data块,大小: %lu字节", info->data_size);break; // 找到数据块,可以开始播放} else {// 其他块,跳过ESP_LOGI(TAG, "跳过未知块: %.4s", chunk_header.id);if (fseek(file, chunk_header.size, SEEK_CUR) != 0) {ESP_LOGE(TAG, "跳过未知块失败");return false;}}}if (!found_fmt) {ESP_LOGE(TAG, "未找到fmt块");return false;}return found_data;
}
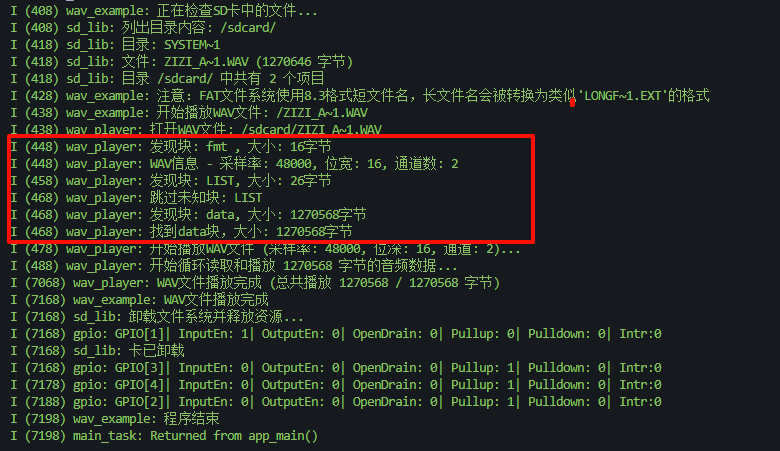
以上是一段嵌入式系统基于 C 语言的经典对wav音频格式的解析,以下是执行结果示例:
4. WAV 格式的变种
-
PCM (Pulse Code Modulation): 最常见,存储未压缩的原始音频样本。
-
ADPCM (Adaptive Differential Pulse Code Modulation): 一种压缩格式,文件尺寸较小,但音质有损。
-
IEEE Float: 使用浮点数存储样本,通常用于音频处理中间阶段,提供更大的动态范围。
-
MPEG Layer-3 (MP3): 虽然不常见,但技术上 WAV 容器也可以包含 MP3 编码的数据。
-
Extensible Format: 为了克服 fmt 块的一些限制(例如支持超过 2 声道、更高的位深度/采样率、更精确的声道映射),引入了可扩展格式。它使用更大的 fmt 块 (通常 Chunk Size 为 40 字节),包含一个 SubFormat GUID 来精确指定编码类型。
PCM 优缺点
-
优点:
-
音质 (PCM): 未压缩的 PCM 格式能提供无损的原始音频质量。
-
简单性: 结构相对简单,易于解析和处理。
-
广泛支持: 尤其是在 Windows 和专业音频软件中得到极好的支持。
-
-
缺点:
- 文件大小 (PCM): 未压缩导致文件体积巨大。
5. 嵌入式系统处理 WAV 音频流程
-
系统与外设初始化:
- 文件系统初始化:如果WAV文件存储在SD卡、Flash等外部存储器上,需要先初始化对应的文件系统(如FATFS)。
- 音频输出接口初始化 (如I2S、DAC):
- 配置GPIO引脚用于音频数据传输(如BCK, WS/LRC, DATA_OUT)。
- 设置音频参数:模式(主/从,发送/接收)、采样率、位深度、声道格式。
- 配置DMA(直接内存访问):设置DMA缓冲区数量和大小,以实现后台数据传输,减轻CPU负担。
- 安装并启动音频驱动。
-
打开WAV文件:
- 根据提供的文件名(可能需要拼接完整路径,如挂载点前缀)以二进制只读模式 (
"rb") 打开WAV文件。 - 检查文件是否成功打开,如果失败则进行错误处理(如打印错误日志、返回错误码)。
- 根据提供的文件名(可能需要拼接完整路径,如挂载点前缀)以二进制只读模式 (
-
解析WAV文件头部信息:
- 读取并验证RIFF头:
- 使用
fread读取文件开头的wav_riff_header_t结构体。 - 检查RIFF标识是否为
"RIFF",WAVE标识是否为"WAVE"。如果不是,则文件格式无效。
- 使用
- 查找并解析"fmt "块 (Format Chunk):
- 循环读取块头 (
wav_chunk_header_t),获取块ID和块大小。 - 当找到ID为
"fmt "的块时:- 使用
fread读取fmt块的内容到wav_fmt_header_t结构体中(或至少读取其核心参数部分)。 - 关键信息提取:获取采样率 (
sample_rate)、声道数 (num_channels)、采样位深度 (bits_per_sample)、音频格式 (audio_format)。 - 格式验证:检查
audio_format是否为PCM (通常为1),因为嵌入式系统通常直接处理PCM数据。如果不是支持的格式,则报错。 - 如果
fmt块的大小超出了结构体预期的大小(可能有扩展字段),使用fseek跳过剩余部分。
- 使用
- 循环读取块头 (
- 查找并记录"data"块 (Data Chunk):
- 继续循环读取块头。
- 当找到ID为
"data"的块时:- 记录该块的大小 (
info->data_size),这就是实际音频数据的总长度。 - 此时,文件指针已经定位在音频数据的起始位置,准备开始读取数据进行播放。
- 记录该块的大小 (
- 如果找到 “data” 块,则头部解析成功。
- 处理其他块:对于不关心的块(如 “LIST”, “INFO”, “fact” 等),读取其块头后,使用
fseek(file, chunk_header.size, SEEK_CUR)跳过该块的数据内容。 - 如果未找到 "fmt " 块或 “data” 块,则认为WAV文件无效或损坏。
- 读取并验证RIFF头:
-
(可选) 动态调整音频输出接口配置:
- 将从WAV文件 "fmt " 块中解析出的音频参数(采样率、位深度)与当前音频输出接口(如I2S)的配置进行比较。
- 如果参数不匹配(例如,WAV是44.1kHz,而I2S当前配置为48kHz):
- 卸载当前的音频驱动。
- 使用从WAV文件获取的新参数更新音频接口的配置结构体。
- 重新初始化并启动音频驱动。
- 这一步确保了音频数据能以正确的速率和格式播放,避免声音失真。
-
分配音频数据缓冲区:
- 使用
malloc(或其他内存分配函数) 分配一个或多个缓冲区,用于从WAV文件读取音频数据,然后传递给音频输出接口。缓冲区大小通常是根据DMA能力和系统内存来确定的(例如几KB)。 - (可选) 分配转换缓冲区:如果WAV文件的声道数或位深度与音频输出接口硬件直接支持的不完全一致(例如,WAV是单声道,而I2S配置为双声道输出),可能需要一个额外的缓冲区来进行格式转换。
- 使用
-
循环读取和播放音频数据:
- 进入一个循环,直到满足以下任一条件:
- 已播放的字节数达到 “data” 块中声明的音频数据总大小。
fread返回0或错误,表示已到达文件末尾或发生读取错误。
- 从文件读取数据:在循环中,使用
fread从WAV文件读取一块数据到主缓冲区。 - (可选) 音频数据处理/转换:
- 声道转换:如果WAV是单声道,而输出需要双声道,则将单声道样本复制到左右声道。例如,对于16位PCM,将每个单声道样本
s变为s, s。 - 位深度转换:较少见,但如果需要,也在此处处理。
- 音量控制/DSP效果:如果需要,也可以在此阶段对样本数据进行处理。
- 声道转换:如果WAV是单声道,而输出需要双声道,则将单声道样本复制到左右声道。例如,对于16位PCM,将每个单声道样本
- 向音频输出接口写入数据:
- 将准备好的数据(可能是原始读取的,也可能是转换后的)通过音频接口的写入函数(如
i2s_write)发送出去。 - 获取实际写入的字节数,用于流量控制和错误检查。
- 将准备好的数据(可能是原始读取的,也可能是转换后的)通过音频接口的写入函数(如
- 更新已播放字节数。
- 任务调度:在循环中可以加入适当的延时 (
vTaskDelay),以允许其他任务运行,避免长时间占用CPU。
- 进入一个循环,直到满足以下任一条件:
-
播放完成与资源清理:
- 当循环结束(播放完毕或出错)后:
- 检查
ferror(file)确定是否因文件读取错误退出。 - (可选) 等待DMA缓冲区清空:确保所有已写入音频接口的数据都被硬件实际播放出去。可以调用特定函数清零DMA缓冲或简单延时。
- 释放内存:使用
free释放之前分配的所有缓冲区。 - 关闭文件:使用
fclose关闭WAV文件。 - 卸载/关闭音频接口:如果不再需要,可以卸载音频驱动,释放相关硬件资源。
- 检查
- 当循环结束(播放完毕或出错)后:
-
错误处理:
- 在流程的每一步都应有适当的错误检测和处理机制。
- 发生错误时,记录日志,释放已分配的资源,并返回相应的错误代码。
。- (可选) 等待DMA缓冲区清空:确保所有已写入音频接口的数据都被硬件实际播放出去。可以调用特定函数清零DMA缓冲或简单延时。
- 释放内存:使用
free释放之前分配的所有缓冲区。 - 关闭文件:使用
fclose关闭WAV文件。 - 卸载/关闭音频接口:如果不再需要,可以卸载音频驱动,释放相关硬件资源。
-
错误处理:
- 在流程的每一步都应有适当的错误检测和处理机制。
- 发生错误时,记录日志,释放已分配的资源,并返回相应的错误代码。