解密企业级大模型智能体Agentic AI 关键技术:MCP、A2A、Reasoning LLMs-强化学习算法AlphaGo
解密企业级大模型智能体Agentic AI 关键技术:MCP、A2A、Reasoning LLMs-强化学习算法AlphaGo
大家看这边是alphago zero的训练过程。
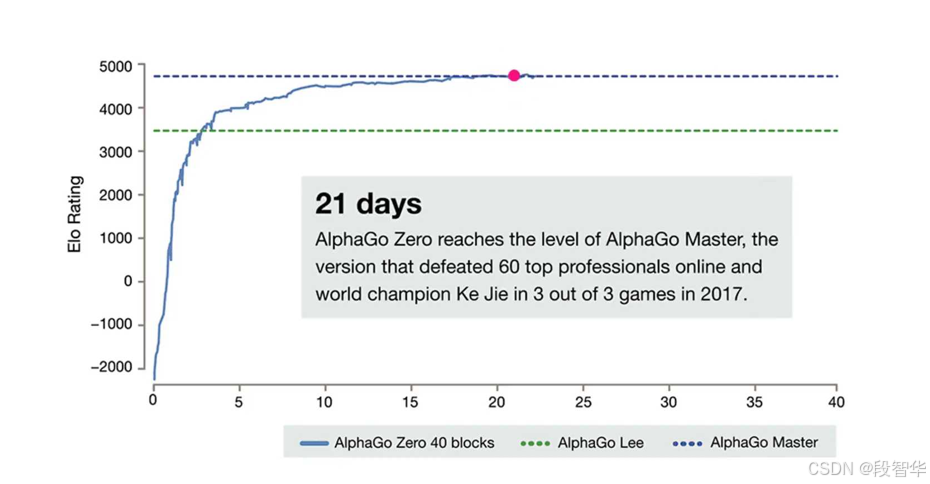
我说的训练过程是随着时间的推移的变化,你看见这个红点了, 其实你看你,你首先应该最开始应该关注的是这个绿色的点。这个绿色的点是代表了什么?你从最开始的时候,大家注意,这个叫alphago zero,他这边是zero的这种状态。它基本的一种意思是说我没有前置的一些,比如说cold start等等之类,它直接使用强化学习的方式。大家可以看啊,它它这个红色点会在几个不同的阶段,给你标注出它的关键的这个转折点。
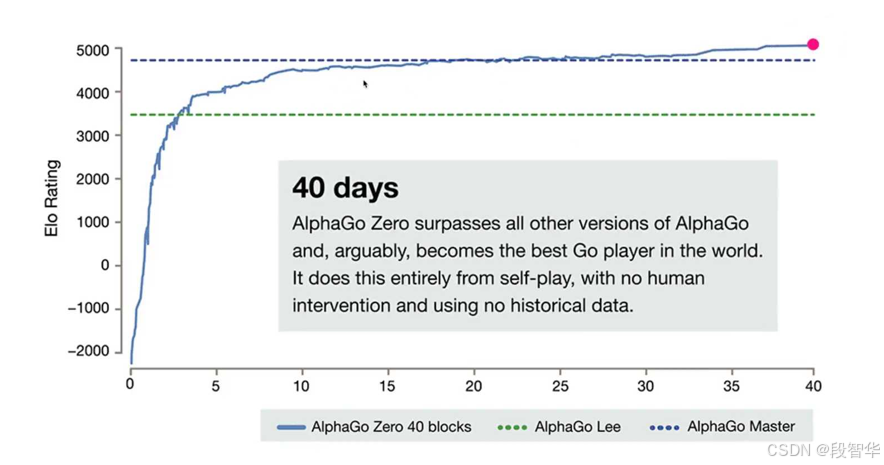
在最开始的时候,他并没有prior knowledge,所以他开始很糟糕。然后三天之后,他就具备了这个alphago 的能力,这就相当于人类的顶级的水平了。然后21天之后他就完成了这个alphago master , 他采用了一些例如SFT等相关的内容。然后40天以后他超越了所有的版本的alphago 的内容,所以这个是强化学习。
大家可以看随着时间的推移,他能够不断的自我的成长学习。当然所谓的成长的学习就是不断的进行explore和exploit。然后他不断的找最佳的模式,或者我们统称之为学习的过程,叫learn from experience。这是google的 deep mind给我们的具体的信息,在这幅图中这是DeepSeek R1 zero给我们的信息。
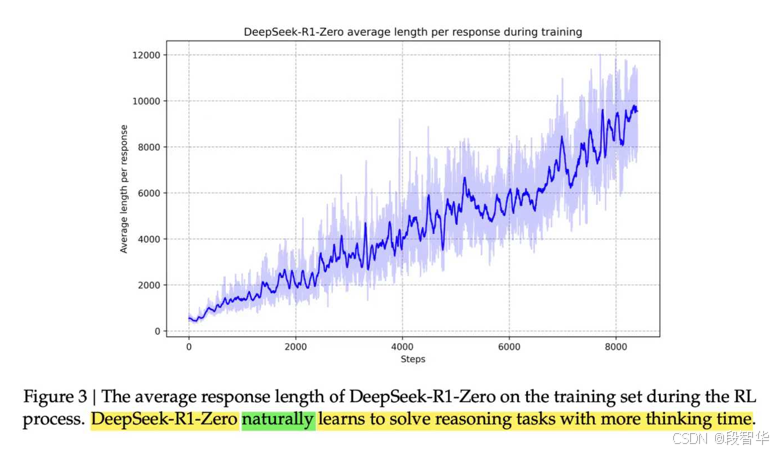
随着我们训练的不同,或者说您可以认为随着训练实践的不断的增加,然后他的这个reason capability越来越强。但在这里代表reasoning capability,你可以认为是length,就是他输出的这个长度,就思考的过程越来越多。但可能会有人说,你思考过程越来越多,不一定代表这个reason capability越来越强,这个说法没问题,但从模型的角度讲,你可以认为这个趋势是正确的。所谓趋势就是当你能够思考的内容越来越多,思考的步骤越来越多,维度越来越多的时候,他的推理能力越来越强。
