音频特征工具Librosa包的使用
深入探索Mamba模型架构与应用 - 商品搜索 - 京东
DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东
要使用深度学习与语音特征进行抽取,首先需要准备能够对语音特征进行解析的工具。
Librosa是一个用于音频、音乐分析与处理的Python工具包,常见的时频处理、特征提取、绘制声音图形等功能应有尽有,功能十分强大。Librosa提供了多种音频读取和写入的方法,支持多种音频格式的读取和写入,如WAV、FLAC、MP3等。Librosa提供了多种音频特征提取的方法,如MFCC、Chromagram等。此外,Librosa还提供了多种音频可视化的方法,如绘制声谱图、绘制频谱图等。
下面将使用Librosa完成音频信号的特征提取和可视化,并对其涉及的内容进行详细讲解。
15.1.1 基于Librosa的音频信号读取
音频信号是日常生活中最常见且人们接触最多的信号类型,它们以具有频率、带宽、分贝等参数的音频信号形式存在。典型的音频信号可以表示为振幅随时间变化的函数,如图15-1所示。
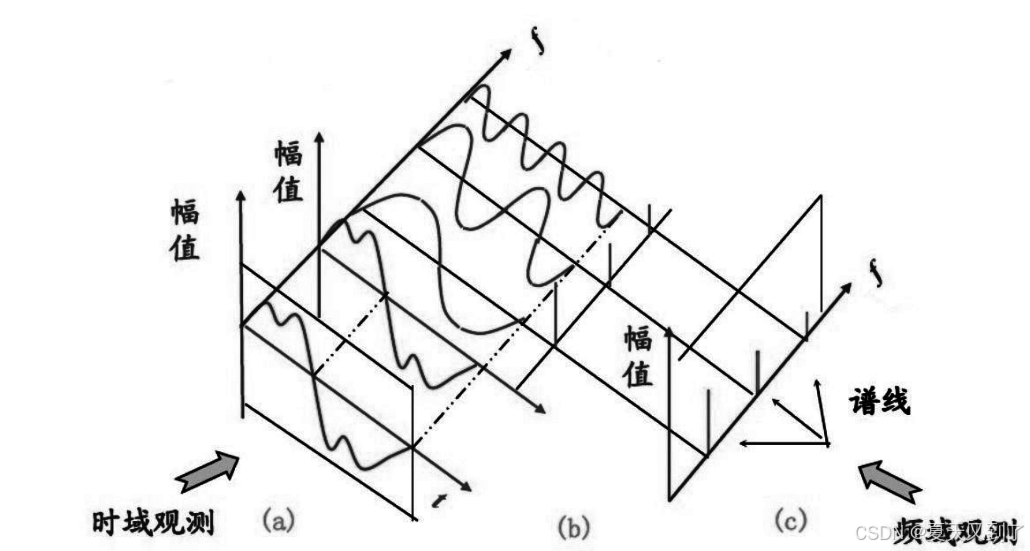
图15-1 音频信号的分解
而落实到具体的音频文件上来说,音频文件的格式多种多样,可以使用计算机读取和分析它们。比如:
- MP3格式。
- WMA(Windows媒体音频)格式。
- WAV(波形音频文件)格式。
对于已经存储在计算机中的音频文件,需要使用特定的Python库进行处理。在这里,作者选择的是Librosa。这是一个Python第三方库,主要用于分析音频信号,尤其适合音乐分析。Librosa涵盖了构建音乐信息检索(Music Information Retrieval,MIR)系统的具体细节。它提供了详尽的文档记录,以及丰富的示例和教程。
1. 采用Librosa对音频进行读取
为了简化起见,在这里首先使用Librosa对音频信号进行读取,代码如下:
import librosa as lbaudio_path = "../第三章/carsound.wav"audio, sr = lb.load(audio_path)
print(len(audio),type(audio))
print(sr,type(sr))
此时的load函数直接根据音频地址对数据进行读取,这里读取出的两个参数,audio为音频序列,而sr则是音频的采样率,输出结果如下:
88200 <class 'numpy.ndarray'>
22050 <class 'int'>
第一行是音频的长度与生成的数据类型,而第二行是音频的采样率。此时,如果想更换采样率对音频信号进行采集,则可以使用如下代码:
audio, sr = lb.load(audio_path,sr=16000)同样,可以对结果进行打印,请读者自行尝试。
对于将音频采样率修正后的复制和写入操作,读者可以使用SciPy库来完成,代码如下:
from scipy.io import wavfilewavfile.write("example.wav",sr, audio)读者可以自行尝试。
2. 音频可视化
对于获取的音频,读者可以使用以下代码对音频进行生成:
import matplotlib.pyplot as pltimport librosa.displaylibrosa.display.waveshow(audio, sr=sr)plt.show()这里使用waveshow函数对读取到的音频进行转换,并将结果输出。形成的图形如图15-2所示。
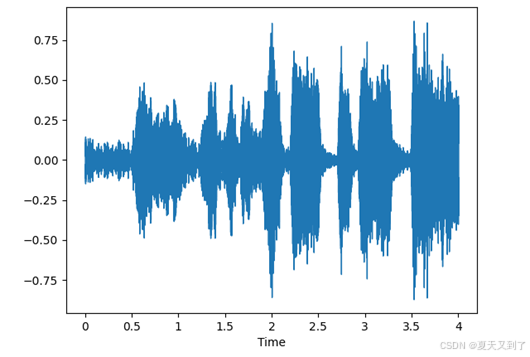
图15-2 音频转换结果
3. 一般频谱图(非MFCC)的可视化展示
频谱图是音频信号频谱的直观表示,前面在3.3.2节中使用短时傅里叶变换完成了一般频谱图的展示,在这里可以使用同样的函数对信号进行处理,代码如下:
audio = lb.stft(audio) # 短时傅里叶变换audio_db = lb.amplitude_to_db(abs(audio)) # 将幅度频谱转换为dB标度频谱。也就是对序列取对数lb.display.specshow(audio_db, sr=sr, x_axis='time', y_axis='hz')plt.colorbar()plt.show()这里首先使用短时傅里叶变换完成了图谱转换,而amplitude_to_db的作用将幅度频谱转换为dB标度频谱。也就是对序列取对数,读者可以使用如下代码对其进行验证,这里不再过多阐述。
arr = [10000,20000]audio_db = librosa.amplitude_to_db(arr)print(audio_db)specshow是用于展示图谱的函数,生成的音频图谱如图15-3所示(颜色越红,表示信息含量越多)。
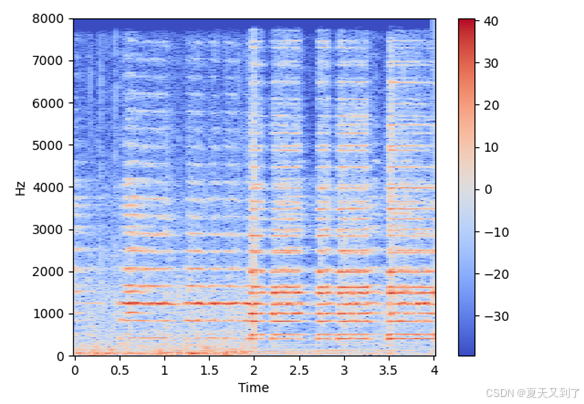
图15-3 特定音频的频谱图(颜色越红,表示信息含量越多)
图15-3是生成的音频频谱图,横坐标是时间的延续,而纵坐标是显示频率(0~10000Hz),注意到图谱的底部信息含量比顶部多,可以对纵坐标进行变换,即对所有的数值取对数。代码如下:
lb.display.specshow(audio_db, sr=sr, x_axis='time', y_axis='log')新的图谱如图15-4所示。
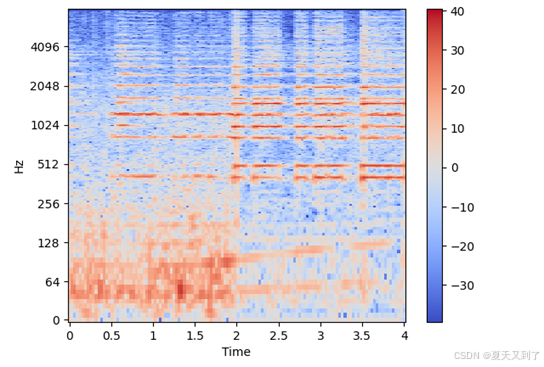
图15-4 取对数处理后的频谱图
可以明显看出,与原始频谱图相比,取对数后的频谱图对信息丰富的部分提供了更为显著的显示。
15.1.2 基于Librosa的音频多特征提取
对于音频特征较为常用的分别是MFCC(梅尔频率倒谱系数)、chroma_stft(色度频率)以及梅尔频谱图,而Librosa库也为我们提供了专门的特征提取方法。下面我们依次对这些特征及其提取方法进行详细讲解。
1. MFCC音频特征
我们首先使用Librosa完成MFCC特征的抽取,代码如下:
import librosa as lbimport matplotlib.pyplot as pltaudio , sr = lb.load("example.wav",sr=16000)melspec = lb.feature.mfcc(y=audio, sr=sr, n_mels=40)lb.display.specshow(melspec, sr=sr, x_axis='time', y_axis='log')plt.colorbar()plt.show()生成的波形图请读者自行查看。
在生成MFCC频谱的基础上,还可以执行特征缩放,使得每个系数维度具有零均值和单位方差:
from sklearn import preprocessingmelspec = preprocessing.scale(melspec, axis=1)请读者自行尝试使用。
2. chroma_stft音频特征
除常用的MFCC外,Librosa还提供了其他一些特征提取函数。其中,librosa.feature.chroma_stft 是Librosa库中的一个函数,用于计算音频信号的基于音高的谱图特征。该函数首先使用短时傅里叶变换(Short-Time Fourier Transform,STFT)将音频信号转换为频谱图,然后计算出每个分带中的基于音高的强度。
具体来说,librosa.feature.chroma_stft函数的输入参数包括音频时间序列和采样率,输出结果是一个二维数组,其中每一行代表一个分带,每一列代表一个时间帧,数组中的值表示该时间帧在该分带中的基于音高的强度。其实现代码如下:
import librosa as lbimport matplotlib.pyplot as pltimport numpy as npaudio , sr = lb.load("example.wav",sr=16000)stft=np.abs(lb.stft(audio))chroma = lb.feature.chroma_stft(S=stft, sr=sr)lb.display.specshow(chroma, sr=sr, x_axis='time', y_axis='log')plt.colorbar()plt.show()请读者自行打印图谱图形。
顺便讲一下,chroma_stft和MFCC都是音频处理中常用的特征提取方法。其中,MFCC是一种基于梅尔倒谱系数的特征,用于描述音频信号的频谱特性;而chroma_stft则是基于音高的谱图特征,用于描述音频信号的时域特性。
3. 梅尔频谱图
librosa.feature.melspectrogram是Librosa库中的一个函数,用于计算音频信号的梅尔频谱图。该函数的输入参数包括音频时间序列y和采样率sr,输出结果是一个二维数组,其中每一行代表一个时间帧,每一列代表一个频率,数组中的值表示该时间帧在该频率中的梅尔频谱强度。实现代码如下:
mel = lb.feature.melspectrogram(y=audio, sr=sr, n_mels=40, fmin=0, fmax=sr//2)mel = lb.power_to_db(mel)lb.display.specshow(mel, sr=sr, x_axis='time', y_axis='log')plt.colorbar()plt.show()梅尔频谱图形请读者自行查看。
梅尔频谱图则是先将音频信号进行分帧,并对每一帧音频信号进行短时傅里叶变换,得到每个时间帧对应的频谱图。接着,对每个频谱图应用梅尔滤波器组进行变换,得到每个频率对应的梅尔功率谱密度。最后,将所有频率对应的梅尔功率谱密度合并成一个二维数组,即为梅尔频谱图。
MFCC和梅尔频谱图都是音频信号处理中常用的特征提取方法。其中,MFCC是一种基于梅尔倒谱系数的特征,用于描述音频信号的频谱特性;而梅尔频谱图则是基于梅尔滤波器组的变换,将音频信号从时域转换到频域,然后计算出每个频率对应的梅尔功率谱密度。

