精简大语言模型:用于定制语言模型的自适应知识蒸馏
Streamlining LLMs: Adaptive Knowledge Distillation for Tailored Language Models
发表:NAACL 2025
机构:德国人工智能研究中心
Abstract
诸如 GPT-4 和 LLaMA-3 等大型语言模型(LLMs)在多个行业展现出变革性的潜力,例如:提升客户服务、革新医疗诊断流程,或在新闻报道中识别危机事件。然而,在部署 LLM 时仍面临诸多挑战,包括训练数据有限、计算成本高,以及在透明性和可解释性方面存在问题。我们的研究聚焦于从 LLM 中蒸馏出紧凑、参数高效的定制语言模型(TLMs),以应对特定领域任务,并实现与 LLM 相当的性能。当前的一些方法(如知识蒸馏、微调和模型并行)虽能提高计算效率,但在效率、适应性和准确性之间尚缺乏一种能够平衡三者的混合策略。我们提出了 ANON —— 一个自适应知识蒸馏框架,它将知识蒸馏与适配器机制相结合,能够在无需依赖标注数据集的情况下,生成计算效率更高的 TLM。ANON 利用交叉熵损失函数从教师模型的输出及其内部表示中转移知识,同时采用自适应提示工程(prompt engineering)与渐进式蒸馏策略(progressive distillation strategy)分阶段地进行知识迁移。我们在危机领域对 ANON 进行了评估,该领域对准确性要求极高且标注数据稀缺。实验结果表明,在生成 TLM 的性能方面,ANON 优于当前主流知识蒸馏方法;同时,在保持准确性的前提下,相较于直接使用 LLM,它在训练与推理过程中的计算成本更低,适合于特定领域的应用场景。
Introduction
近年来,大型语言模型(LLMs)彻底改变了我们与技术交互的方式,成为当前人工智能时代的主导趋势。各行各业正通过应用 LLMs 进行自我革新,应用场景涵盖基于可解释性 LLM 方案的医学诊断(Bisercic 等,2023),金融风险分析与市场建模(Wu 等,2023),以及通过分析新闻文章和社交媒体文本进行的实时危机检测(Saxena 等,2024;Janzen 等,2024)。尽管 LLM 拥有强大的能力,但在将其部署于特定领域任务时仍面临显著挑战。对这类模型进行全面微调需要大量的标注数据集和计算资源,这使得许多组织,尤其是预算有限的组织望而却步。因此,为 LLM 设计有效的模型压缩策略对于在资源受限环境中实现广泛、实用的应用至关重要。
现有针对模型压缩与适配的研究包括知识蒸馏(KD)(Gu 等,2023;Sanh 等,2019)、参数高效微调(PEFT)(Ding 等,2023)和模型剪枝(Fan 等,2021)。这些方法的核心目标是将大型模型转化为更高效的版本,同时尽量不损失性能。KD 将知识从较大的“教师”模型迁移到较小的“学生”模型,从而在保留性能的同时减少计算开销(Dasgupta 等,2023;Hsieh 等,2023;West 等,2022;Ko 等,2024)。PEFT 方法(如 Adapters(Houlsby 等,2019)、BitFit(Zaken 等,2021)和 LoRA(Hu 等,2022))则仅优化模型的一部分参数,实现特定任务的适配,且资源开销极小。同样地,基于提示的调优技术(如 prefix tuning 和 prompt tuning)可将领域特定的信息注入到模型输入中,而无需修改模型架构。然而,这些方法通常是孤立使用,缺乏能够整合它们优势的混合机制,以同时应对内存效率、计算成本、任务性能和数据匮乏之间的权衡。近期工作,如 adapter distillation(Wang 等,2023)和语言通用适配器(Shen 等,2023),展现了方法组合的潜力,但在针对特定领域优化的混合方法方面仍有待进一步探索。
为了解决这些局限性,我们提出了 ANON —— 一个将 KD 与基于适配器的 PEFT 相结合的新型框架,旨在将 LLM 高效蒸馏为适用于特定领域任务的语言模型(TLMs)。ANON 通过交叉熵损失函数进行知识迁移,利用教师模型的输出分布和内部表示来保留高层抽象和领域细节。该框架还使用自适应提示工程技术,通过数据驱动的提示来有效对齐教师与学生模型(Mishra 等,2023)。此外,ANON 还引入了渐进式蒸馏策略,以分阶段的方式从简单任务到复杂任务逐步传递知识,实现更全面的学习。适配器模块轻量、独立训练,其它部分保持冻结,大幅降低了计算成本,使 ANON 成为高效且具扩展性的领域适配解决方案。
我们在危机预警任务中对 ANON 进行了评估,目标是基于 219,292 篇新闻文章构建的语料库,实现潜在危机的早期检测。按照(Saxena 等,2024)提出的实验设计,我们评估了 ANON 在多个教师-学生模型对上的表现,包括 LLaMA-2(Touvron 等,2023)、OPT(Zhang 等,2022)和 GPT-2(Radford 等,2019)。这些评估将 ANON 与现有 KD 方法进行了基准对比。结果表明,ANON 在性能上优于基线方法,同时显著降低了资源消耗。例如,学生模型 LLaMA-27B_ANON 由 LLaMA-2 13B 教师模型蒸馏而来,不仅性能超过了教师模型,其资源消耗也最多降低了 95.24%。这些发现表明,ANON 能够在计算效率与任务性能之间实现良好平衡,是一种适用于资源受限 AI 应用的可扩展方案。
Adaptive knowledge distillation for domain-specific TLMs
我们提出了 ANON——一个自适应知识蒸馏框架,旨在高效地将大型语言模型(LLMs)蒸馏为面向特定任务的领域语言模型(TLMs),如图1所示。
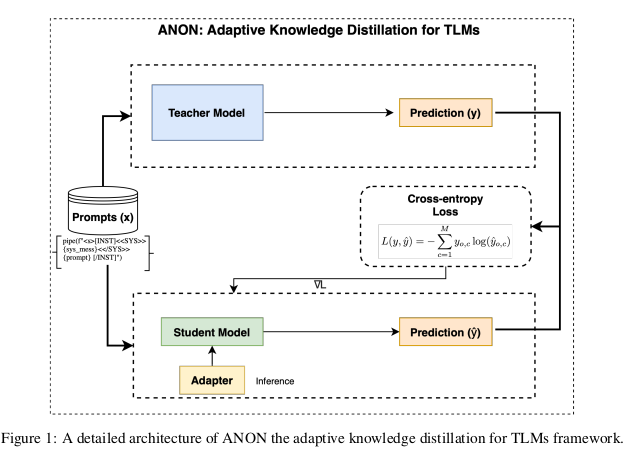
ANON 在学生模型中集成了轻量级的适配器层,从而使蒸馏过程集中于这些新增参数的训练,同时冻结模型的其他结构,实现高效训练。
该框架采用交叉熵损失函数,对齐学生模型的预测与教师模型的输出分布,从而实现知识的精准迁移。
通过集成如 LoRA、QLoRA 和 Series Adapter 等适配器模块(Dettmers 等,2023),ANON 进一步优化了训练效率,在不牺牲模型性能的前提下降低了计算成本。
该框架还采用渐进蒸馏策略,即分阶段进行知识迁移,从简单任务逐步过渡到复杂任务。
这种混合方法生成的学生模型 StudentANON 在显著降低资源需求的同时,达到了与教师模型相当的性能。
最终模型非常适用于医疗诊断、风险管理、客户支持等特定领域,为现实任务提供了可扩展、可部署的解决方案。
Prompt Generation
ANON 利用特定任务的提示词(prompts)来引导教师模型与学生模型之间的知识蒸馏。
受 PromptAid(Mishra 等,2023)的启发,这些提示词遵循一种通用结构:包括可选的系统提示词、必须包含的用户任务说明,以及用于指定机器可读输出格式的响应模板。
提示词会根据具体任务和模型的需求进行定制。
例如,在一个新闻文章分类任务中,可能会使用如下提示词:“请将以下新闻文章分类为以下三类之一:‘风险与预警’、‘警告与建议’、或‘安全无害’。输入:能源部门警告未来几个月将出现短缺和账单飙升。”
这些生成的提示词作为输入同时传递给教师模型和学生模型,从而使它们在相同的任务目标下进行学习。
ANON Workflow
构建计算高效的、面向特定领域任务的语言模型(TLMs),需要在性能与资源限制之间取得平衡。ANON 框架通过自适应知识蒸馏提供了一个全面的解决方案,采用教师-学生结构并结合轻量级适配器。教师模型是一个大型预训练语言模型,如 LLaMA-3.1(405B 或 70B)或 GPT-4,用作丰富、泛化知识的来源。学生模型则是一个更小、更高效的替代方案,如 LLaMA-27B 或 GPT-2,旨在复制教师模型的输出,在减少计算开销的同时保持相当的性能。
蒸馏过程确保学生模型与教师模型的输出概率分布保持一致。这种对齐是通过精心设计的提示词 xxx 来实现的,用以引导两者生成期望的输出。教师模型的预测 yyy 被视为学生模型训练时的“真实标签”。
优化目标使用交叉熵损失函数来形式化表示:

为了进一步降低蒸馏过程的资源消耗,ANON 在学生模型中引入了适配器。这些适配器是可训练的小模块,仅微调模型的特定部分,而冻结其他部分。通过将更新限定于适配器,ANON 显著减少了训练过程中的资源开销,尤其是在大量参数进行梯度计算与误差反向传播时。
这种有针对性的微调策略使学生模型在训练与推理成本大幅降低的同时,仍能获得与教师模型相当的性能。
Implementation and Evaluation
基于所提出的框架(参见图1),我们按照(Saxena 等人,2024;Hassanzadeh 等人,2022)中描述的实验设计,实现了用于危机预警任务的 ANON。
最终,蒸馏得到的 StudentANON 模型能够提供面向特定领域的危机信号,并给出相应的置信度和严重程度等级的预警信息。
Data Collection and Processing
为了对 ANON 进行蒸馏,我们使用了一个包含 219,292 篇新闻文章的开放域危机信号数据集,覆盖 42 种语言。该数据集涉及多种类型的危机,例如 供应链中断、难民迁徙和经济不稳定等。
该数据集通过 关键词扩展技术构建,并借助 Event Registry API<sup>11</sup> 进行检索。
在预处理阶段,执行了标准的文本清洗(例如移除特殊字符和标点符号),并使用了一个 两阶段过滤流程(Saxena 等,2024)。
最终得到的精简数据集包含 137,308 篇文章,占原始语料库的 62%。
我们使用真实世界中的危机新闻数据集来评估 ANON 的性能。Saxena 等(2024)对这些数据集进行了全面的描述性分析,包括其分布和范围等特征。
在本研究中,我们使用了 319 篇由人工标注的文章,这些文章主要围绕 经济衰退和能源危机(例如供应链中断、能源可用性和成本)展开。
这些人工标注的文章作为 模型验证的基准数据。
Training paradigm
蒸馏过程首先通过用于分类任务的提示模板(template 2.1)生成提示(x)。参照 Gu 等人(2023)的方法,我们使用了三组教师-学生模型对:(LLaMA-2 13B, LLaMA-2 7B),(OPT 13B, OPT 1.3B),以及 (GPT-2 1.5B, GPT-2 124M)。这些提示的任务是将新闻文章分类为三类:“风险与警示”、“注意与建议”,以及**“安全与无害”**。
通过 20 条由专家人工标注的样本进行少样本提示(few-shot prompting),以增强教师模型的预测效果。经过调优后,这些提示被输入到教师和学生模型中,以生成分类预测结果 y(教师输出)和 𝑦̂(学生输出)。教师模型的输出 y 被视为蒸馏过程中的“真实标签”。
为了最小化教师和学生模型之间预测概率分布的差异,我们采用了交叉熵损失函数进行优化。
为了进一步提高效率,我们引入了 量化低秩适配器(QLoRA),它将自注意力层进行 4 位量化和低秩分解。
具体来说,权重矩阵被分解为两个较小的矩阵 A 和 B,并由秩参数 r 控制其维度。
在对所有模型进行的实验中,尝试了 r = 4, 8, 32 和 64 四种配置。
最终根据 Hu 等人(2022)的结果,经验性调参表明 r = 64 在压缩率与准确性之间达到了最佳平衡。
此外,我们使用 4-bit NF4 精度,余弦学习率调度器(初始学习率 2e-4,warmup 比例为 0.03),以及带有权重衰减(0.001)和最大梯度范数(0.3)的 32 位 paged AdamW 优化器。
为缓解过拟合,引入了 0.1 的 dropout 比例,并使用 **梯度检查点(gradient checkpointing)**以提高显存利用效率。
这种阶段式的知识转移策略使得 ANON 能够在显著降低计算开销的同时保持较高的准确性,从而非常适合应用于实际的危机监测场景。
4 Results
我们在 (Saxena 等人,2024) 提出的基准数据集上评估了 ANON 的表现,采用的评估指标包括准确率(Accuracy)、F1 分数、敏感性(Sensitivity)和特异性(Specificity)(见表2)。我们的实验比较了教师模型、标准学生模型、基于知识蒸馏(KD)的方法训练的学生模型,以及 ANON 训练的学生模型。
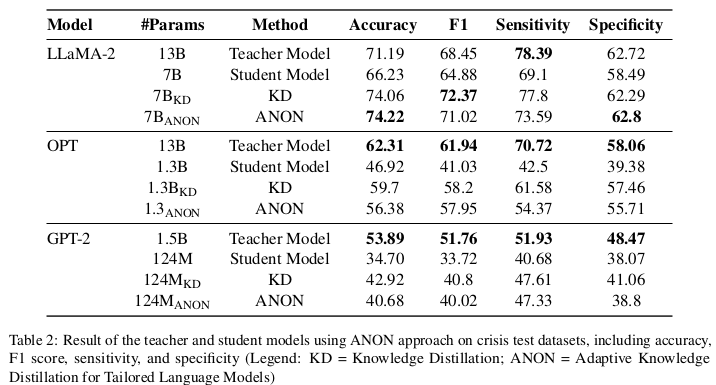
在某些情况下,ANON 的表现优于标准的 KD 方法,甚至超过了教师模型。例如,LLaMA-2 7B ANON 模型的准确率达到了 74.22%,超过了其教师模型(71.19%)和基于 KD 的学生模型(74.06%),显示出更强的泛化能力(Furlanello 等人,2018)。
尽管 OPT 模型的参数量减少了 10 倍,GPT-2 模型的参数减少了 91.7%,ANON 在效率大幅提升的同时,仍保持了与传统 KD 方法相当甚至更优的性能。由于数据集存在类别不平衡,模型的敏感性普遍高于特异性,这凸显了引入偏差缓解策略的重要性。
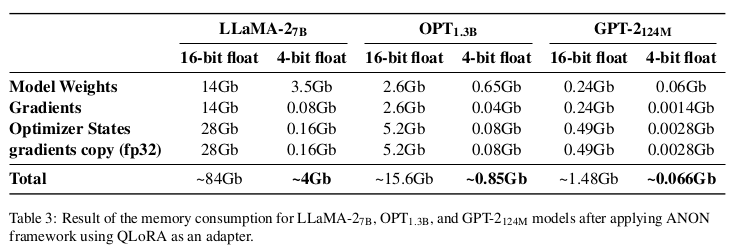
我们还验证了 ANON 在资源消耗方面的表现。表3中的结果显示,为每个学生模型引入适配器模块(adapter modules)后,计算资源需求显著下降。例如,在 LLaMA-2 7B ANON 模型中,从标准 KD 方法转为 ANON 后,内存需求从约 84GB 降至 4GB,减少了 95.24%。这一结果展示了 ANON 在显著降低内存需求的同时,仍能保持可比的性能(参见表2与表3)。
此外,ANON 还将 LLaMA 系列模型中可训练参数数量减少了 99.43%。在 OPT 和 GPT-2 模型系列中,也观察到了类似的效率提升,这进一步证明了 ANON 框架对于不同模型规模和架构的良好适应性。
综上所述,ANON 框架在不牺牲模型性能的前提下,实现了显著的计算资源节省。
Conclusion
在本研究中,我们提出了 ANON——一种用于定制语言模型(TLMs)的自适应知识蒸馏方法。ANON 针对在特定应用场景中训练和部署大型语言模型(LLMs)所面临的训练数据不足与计算资源受限等挑战,提供了解决方案。该方法通过引入适配器(adapters)与知识蒸馏策略,在保持高性能的同时显著提升参数效率,使其在特定领域的应用中表现出色。
ANON 能够有效处理大规模语料库,支持多语言数据处理,而无需承担针对下游任务微调大型模型所需的高昂成本。此外,该方法还解决了在处理高参数量模型时面临的透明性、可解释性以及准确性保持等关键问题。
为验证我们的方法,我们在危机信号任务上使用 QLoRA 适配器对三种不同语言模型家族的教师模型进行了蒸馏实验。实验结果表明,ANON 在准确性和资源消耗方面表现优异,尤其适用于实际的危机信号监测场景。它不仅达到了与教师模型相当甚至更高的性能,同时在某些情况下内存使用量最多降低了 95.24%,可训练参数减少了 99.43%。
我们的框架不仅推动了 LLM 在危机管理领域的落地应用,也为未来在其他领域的相关研究提供了坚实基础。