llamafactory-记录一次消除模型随机性的成功过程
出发点
在使用 LLamafactory 部署生成式模型(如 LLaMA、Qwen 等)时,开发者常会遇到以下问题:
❗️ 即使设置 do_sample=False,模型输出依然存在不可控的随机性
这在 文本分类、事实问答、代码生成 等确定性任务中尤为致命。
本文将从一系列错误中,找到一套成功的解决方案。
部署+调用

我是以上述的方式配置的LLamafactory,文本分类的数据经过lora微调后,使用LLamafactory-cli进行部署,部署使用了vllm,调用方式
generation_config.json
在运行llamafactory-cli api ./data/qwen2.5-7b_lora_inference.yaml时可以看到有从模型配置文件中加载generation_config.json,所以我从这里出发修改了do_sample,基于之前看过的GenerateMinMax,我记得当do_sample=false时,模型也会基于repetition_penalty去做一个修改,所以相应的也修改了这个参数

{"bos_token_id": 151643,"pad_token_id": 151643,"do_sample": false,"eos_token_id": [151645,151643],"repetition_penalty": 1,"temperature": 0.7,"top_p": 0.8,"top_k": 20,"transformers_version": "4.37.0"
}
再次启动时,模型会报以下warning

那我接着做了以下调整,删除了temperature、top_p、top_k
{"bos_token_id": 151643,"pad_token_id": 151643,"do_sample": false,"eos_token_id": [151645,151643],"repetition_penalty": 1,"transformers_version": "4.37.0"
}
可以看到成功加载了,但是没有了do_sample这个配置项了,我测试了一下文本分类这个任务,还是有随机性的,所以没有修改成功。

ChatCompletionRequest
我感觉我的方向错了,所以我开始从LLamafactory-cli这里出发,通过查看src/llamafactory/api/app.py
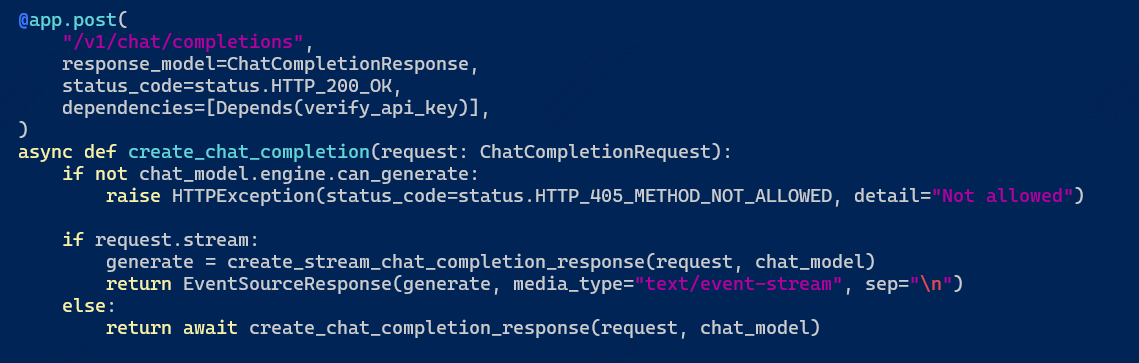
我看到了request中还有stream这个参数,但是我的传入里面并没有这个参数,所以我去查看了src/llamafactory/api/protocol.py
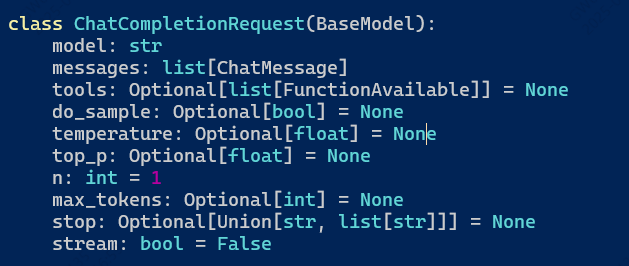
再一次看到了do_sample,默认是None,那是这里的问题吗?
我去调用接口的地方尝试加入这个参数

然后就得到了报错

那我只能把这里取消,然后另找道路,比如直接在定义的地方改
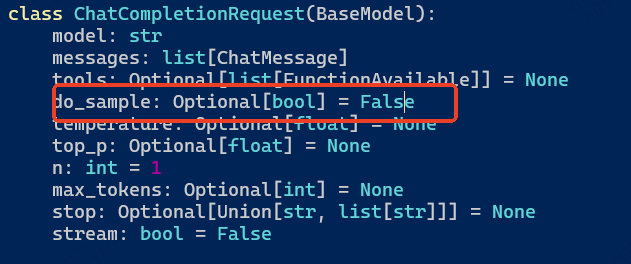
然后发现还是不行,那我想这个参数是在什么地方被用到了呢?是什么时候传入到generate的呢?
通过src/llamafactory/api/app.py中可以看到request传入了src/llamafactory/api/chat.py的函数create_chat_completion_response
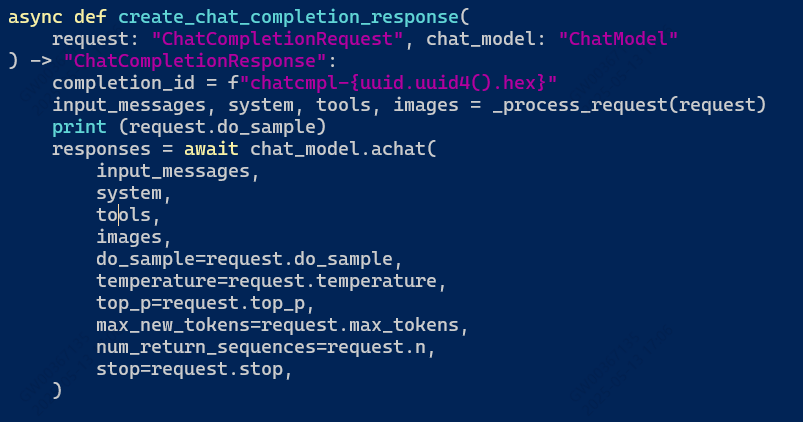
啊,发现do_sample了,那接着找chat_model(src/llamafactory/chat/chat_model.py)
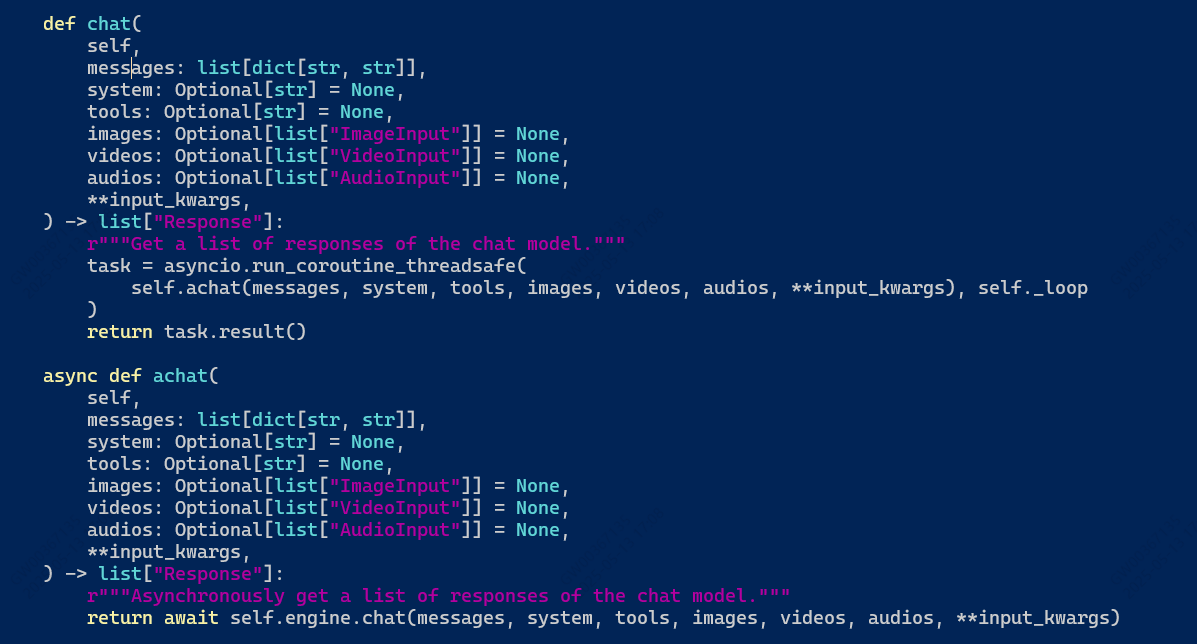
可以看到传入了engine,那我用的vllm,查看src/llamafactory/chat/vllm_engine.py
通过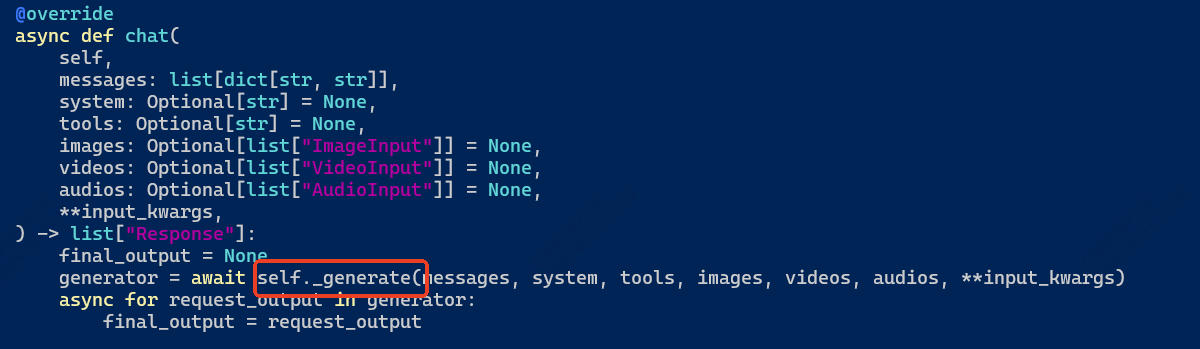
那看一下_generate
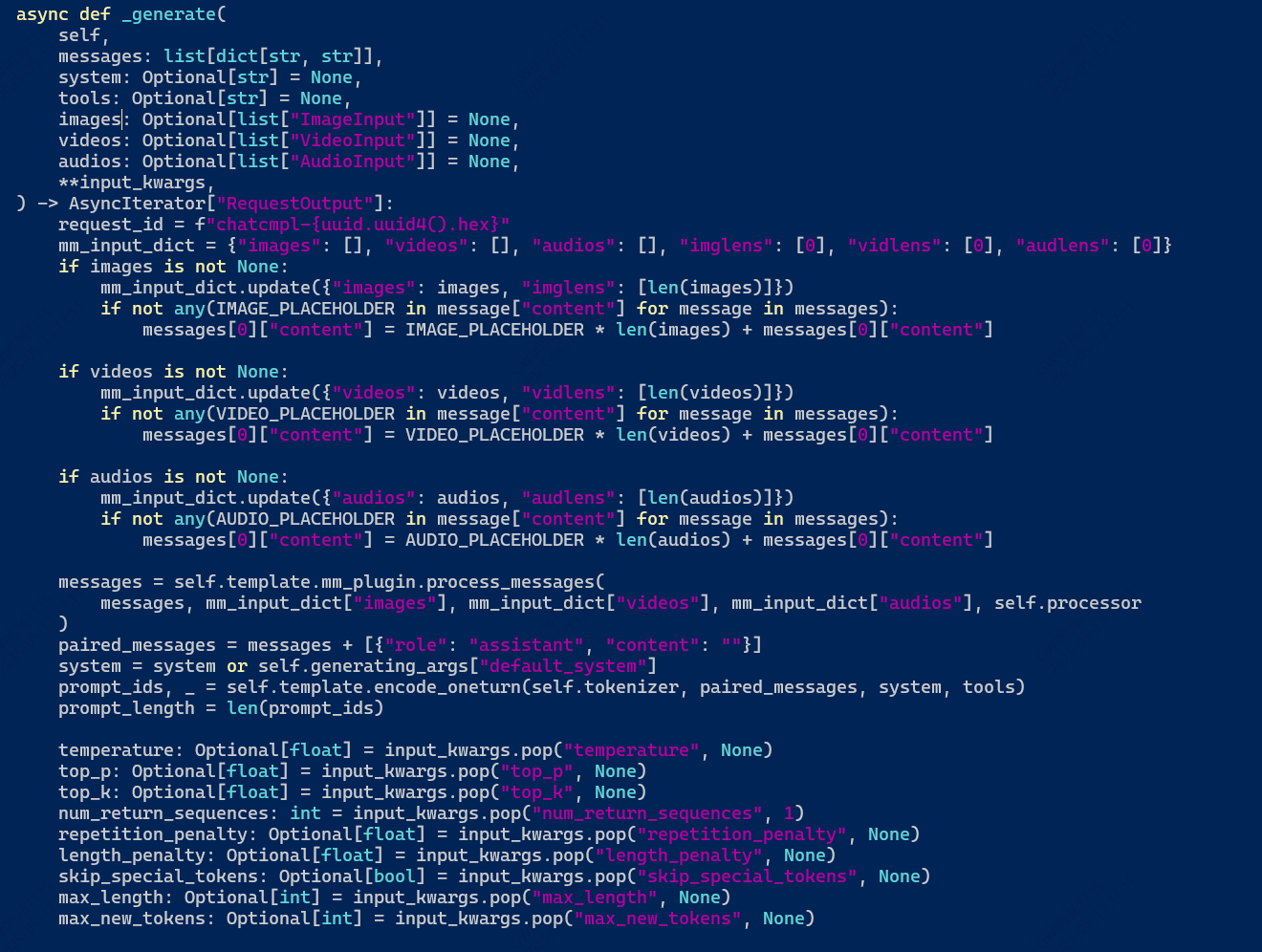
不知道为什么没有do_sample这个参数,坑了。。。
huggingface
那我们去看一下huggingface方式呢src/llamafactory/chat/hf_engine.py
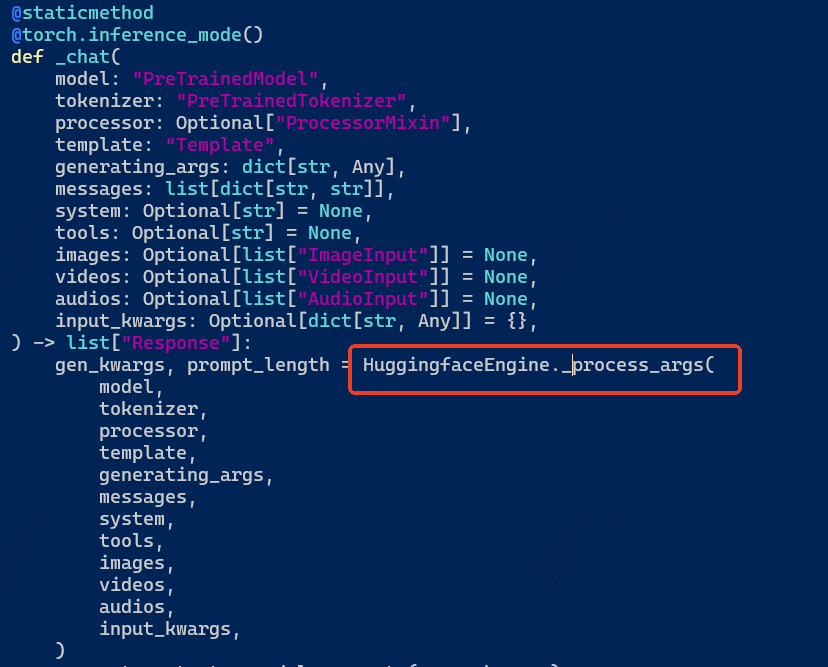
那查看一下_process_args,代码太多了,只截取了一部分
我看到了心心念念的do_sample,那我把推理方式改为这个,重新进行模型推理
结果没有随机性了
那如果把generation_config.json改为原有的影响这个结果吗?
结果是没有影响。
所以目前的结论是需要修改request中的do_sample,而且当前只支持huggingface推理方式