LlamaIndex 第八篇 MilvusVectorStore
本指南演示了如何使用 LlamaIndex 和 Milvus 构建一个检索增强生成(RAG)系统。
RAG 系统将检索系统与生成模型相结合,根据给定的提示生成新的文本。该系统首先使用 Milvus 等向量相似性搜索引擎从语料库中检索相关文档,然后使用生成模型根据检索到的文档生成新的文本。
安装依赖:
pip install llama-index-vector-stores-milvus -i https://mirrors.aliyun.com/pypi/simple/加载数据
准备的数据:
《背影》作者:朱自清我与父亲不相见已二年余了,我最不能忘记的是他的背影。那年冬天,祖母死了,父亲的差使⑴也交卸了,正是祸不单行的日子。我从北京到徐州,打算跟着父亲奔丧⑵回家。
到徐州见着父亲,看见满院狼藉⑶的东西,又想起祖母,不禁簌簌地流下眼泪。父亲说:“事已如此,不必难过,好在天无绝人之路!”回家变卖典质⑷,父亲还了亏空;又借钱办了丧事。这些日子,家中光景很是惨澹⑸,一半为了丧事,一半为了父亲赋闲⑹。
丧事完毕,父亲要到南京谋事,我也要回北京念书,我们便同行。到南京时,有朋友约去游逛,勾留⑺了一日;第二日上午便须渡江到浦口,下午上车北去。父亲因为事忙,本已说定不送我,
叫旅馆里一个熟识的茶房⑻陪我同去。他再三嘱咐茶房,甚是仔细。但他终于不放心,怕茶房不妥帖⑼;颇踌躇⑽了一会。
其实我那年已二十岁,北京已来往过两三次,是没有什么要紧的了。他踌躇了一会,终于决定还是自己送我去。我再三劝他不必去;
他只说:“不要紧,他们去不好!”我们过了江,进了车站。我买票,他忙着照看行李。行李太多了,得向脚夫⑾行些小费才可过去。
他便又忙着和他们讲价钱。我那时真是聪明过分,总觉他说话不大漂亮,非自己插嘴不可,但他终于讲定了价钱;
就送我上车。他给我拣定了靠车门的一张椅子;我将他给我做的紫毛大衣铺好座位。他嘱我路上小心,夜里要警醒些,
不要受凉。又嘱托茶房好好照应我。我心里暗笑他的迂;他们只认得钱,托他们只是白托!而且我这样大年纪的人,
难道还不能料理自己么?我现在想想,我那时真是太聪明了。我说道:“爸爸,你走吧。”他往车外看了看,说:“我买几个橘子去。你就在此地,不要走动。”我看那边月台的栅栏外有几个卖东西的等着顾客。
走到那边月台,须穿过铁道,须跳下去又爬上去。父亲是一个胖子,走过去自然要费事些。
我本来要去的,他不肯,只好让他去。我看见他戴着黑布小帽,穿着黑布大马褂⑿,深青布棉袍,蹒跚⒀地走到铁道边,慢慢探身下去,
尚不大难。可是他穿过铁道,要爬上那边月台,就不容易了。他用两手攀着上面,两脚再向上缩;
他肥胖的身子向左微倾,显出努力的样子。这时我看见他的背影,我的泪很快地流下来了。我赶紧拭干了泪。
怕他看见,也怕别人看见。我再向外看时,他已抱了朱红的橘子往回走了。过铁道时,他先将橘子散放在地上,
自己慢慢爬下,再抱起橘子走。到这边时,我赶紧去搀他。他和我走到车上,将橘子一股脑儿放在我的皮大衣上。
于是扑扑衣上的泥土,心里很轻松似的。过一会儿说:“我走了,到那边来信!”我望着他走出去。他走了几步,
回过头看见我,说:“进去吧,里边没人。”等他的背影混入来来往往的人里,再找不着了,我便进来坐下,我的眼泪又来了。近几年来,父亲和我都是东奔西走,家中光景是一日不如一日。他少年出外谋生,独力支持,
做了许多大事。哪知老境却如此颓唐!他触目伤怀,自然情不能自已。情郁于中,自然要发之于外;
家庭琐屑便往往触他之怒。他待我渐渐不同往日。但最近两年不见,他终于忘却我的不好,只是惦记着我,
惦记着我的儿子。我北来后,他写了一信给我,信中说道:“我身体平安,惟膀子疼痛厉害,举箸⒁提笔,诸多不便,
大约大去之期⒂不远矣。”我读到此处,在晶莹的泪光中,又看见那肥胖的、青布棉袍黑布马褂的背影。唉!我不知何时再能与他相见!from llama_index.core import Settings, SimpleDirectoryReaderfrom my_llms.MyLLMsClients import MyLLMsClientsSettings.llm = MyLLMsClients.deepseek_client()
Settings.embed_model = MyLLMsClients.qwen_embeddings()# 加载数据
documents = SimpleDirectoryReader(input_files=["../data/散文/背影-朱自清.txt"], recursive=True).load_data()print("Document ID:", documents[0].doc_id)创建数据索引
现在我们已经有了一个文档,可以创建索引并插入该文档。对于索引,我们将使用 MilvusVectorStore。
# 创建文档索引
vector_store = MilvusVectorStore(uri="http://192.168.0.116:19530",collection_name="essay_collection",dim=1024,overwrite=True, # 是否覆盖同名的已有集合。默认值为 False。
)storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context
)查询数据
# 创建查询引擎并进行查询
query_engine = index.as_query_engine()
res = query_engine.query("文章的作者是谁?")
print(res)运行结果:
Document ID: 03d81861-1043-4f58-8923-8f03be77d066
2025-05-13 22:16:25,907 [DEBUG][_create_connection]: Created new connection using: 2b0fb6a2181146fa98956805fbf5d9ea (async_milvus_client.py:599)
文章的作者是朱自清。Milvus数据库中的变化
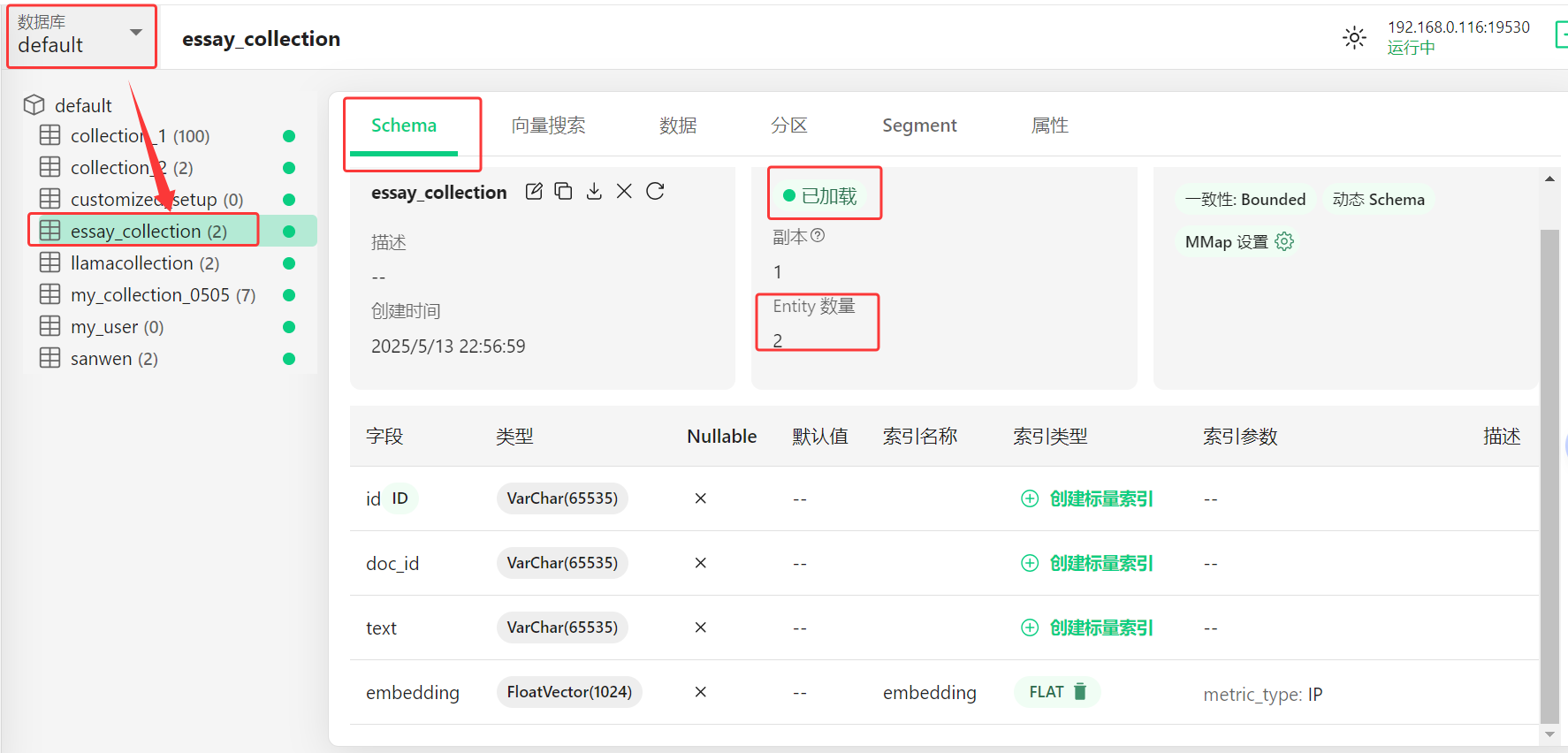
此时,执行代码后,LlamaIndex在Milvus中使用的是默认数据库"default"库,并在此库中创建了集合 essay_collection 。
集合Schema字段说明
- doc_id : document 文档ID
- text: 文档的文本内容
- embedding: 存储的向量,并为向量创建了索引,索引名称:embedding,索引类型:FLAT
从Milvus中查询已有的数据
from llama_index.core import Settings, StorageContext, VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStorefrom my_llms.MyLLMsClients import MyLLMsClientsSettings.llm = MyLLMsClients.deepseek_client()
Settings.embed_model = MyLLMsClients.qwen_embeddings()# 连接Milvus
vector_store = MilvusVectorStore(uri="http://192.168.0.116:19530",collection_name="essay_collection",dim=1024,overwrite=False, # 是否覆盖同名的已有集合。默认值为 False。embedding_field='embedding',
)storage_context = StorageContext.from_defaults(vector_store=vector_store)# 从向量数据库中加载索引
index = VectorStoreIndex.from_vector_store(vector_store, storage_context=storage_context
)#创建查询引擎并进行查询
query_engine = index.as_query_engine()
res = query_engine.query("作者多久没有见到老爹了?")
print(res)2025-05-13 23:28:14,478 [DEBUG][_create_connection]: Created new connection using: c3cbdd7fe28c4a81803a302e8d95862d (async_milvus_client.py:599)
作者已经两年多没有见到父亲了。